지난 시간.....Naive BayesClassifier
arg max
𝑦
𝑃 𝑥1, … , 𝑥 𝑑 𝑦 𝑃(𝑦) = arg max
𝑦
𝑃 𝑥𝑖 𝑦 𝑃(𝑦)
𝑑
𝑖=1
class 𝑦 의 발생 확률과 test set에서 class 𝑦의 label을 가진 데이터의 특성 벡터의
원소 𝑥𝑖 (문서의 예에서는 단어) 가 나올 확률의 곱
ex) (I, love, you)가 spam인지 아닌지 알기 위해서는,
test set에서 spam이 차지하는 비율과
spam으로 labeling 된 문서에서 I와 love와 you가 발생하는 확률을 모두 곱한 것과,
test set에서 ham이 차지하는 비율과
ham으로 labeling 된 문서에서 I와 love와 you가 발생하는 확률을 모두 곱한 것을,
비교한다.
3.
지난 시간 미비했던점 들...
1. Laplacian Smoothing (appendix 참고)
2. MLE / MAP
1
4.
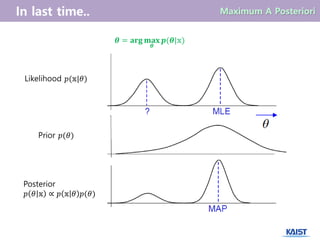
Bayes’ Rule
𝑝 𝜃𝕩 =
𝑝 𝕩 𝜃 𝑝(𝜃)
𝑝 𝕩 𝜃 𝑝(𝜃)
posteriori
(사후 확률)
likelihood
(우도 값)
prior
(사전 확률)
사후 확률 : 관찰 값들이 관찰 된 후에 모수(parameter)의 발생 확률을 구한다.
사전 확률 : 관찰 값들이 관찰 되기 전에 모수의 발생 확률을 구한다.
우도 값 : 모수의 값이 주어졌을 때 관찰 값들이 발생할 확률
5.
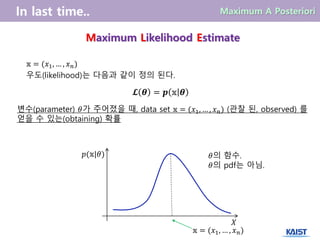
Maximum Likelihood Estimate
𝕩= (𝑥1, … , 𝑥 𝑛)
𝓛 𝜽 = 𝒑 𝕩 𝜽
우도(likelihood)는 다음과 같이 정의 된다.
변수(parameter) 𝜃가 주어졌을 때, data set 𝕩 = (𝑥1, … , 𝑥 𝑛) (관찰 된, observed) 를
얻을 수 있는(obtaining) 확률
𝑝(𝕩|𝜃)
𝑋
𝜃의 함수.
𝜃의 pdf는 아님.
𝕩 = (𝑥1, … , 𝑥 𝑛)
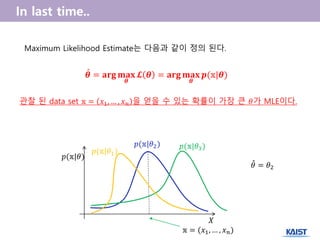
6.
Maximum Likelihood Estimate는다음과 같이 정의 된다.
관찰 된 data set 𝕩 = 𝑥1, … , 𝑥 𝑛 을 얻을 수 있는 확률이 가장 큰 𝜃가 MLE이다.
𝑝(𝕩|𝜃1)
𝑋
𝕩 = (𝑥1, … , 𝑥 𝑛)
𝜽 = 𝐚𝐫𝐠 𝐦𝐚𝐱
𝜽
𝓛 𝜽 = 𝐚𝐫𝐠 𝐦𝐚𝐱
𝜽
𝒑(𝕩|𝜽)̂
𝑝(𝕩|𝜃2) 𝑝(𝕩|𝜃3)
𝑝(𝕩|𝜃)
𝜃 = 𝜃2
̂
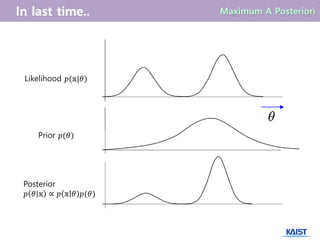
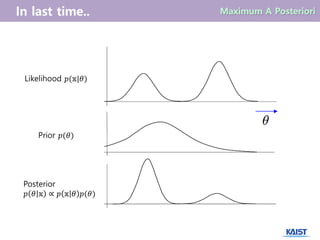
7.
우리가 likelihood function𝑝(𝕩|𝜃)와 prior 𝑝(𝜃)를 알 때, Bayes rule에 의하여
posteriori function의 값을 구할 수 있다.
𝒑 𝜽 𝕩 ∝ 𝒑 𝕩 𝜽 𝒑(𝜽)
Maximum A Posteriori Estimate
𝑝 𝜃 𝕩 =
𝑝 𝕩 𝜃 𝑝(𝜃)
𝑝 𝕩 𝜃 𝑝(𝜃)
posteriori
(사후 확률)
likelihood
(우도 값)
prior
(사전 확률)
나는 큰 신발회사의CEO이다. 많은 지점들을 가지고 있다.
그리고 이번에 새로운 지점을 내고 싶다. 어느 지역에 내야 될까?
내가 새로운 지점을 내고 싶어하는 지역들의 예상 수익만 파악할 수 있으면
큰 도움이 될 것인데!
내가 가지고 있는 자료(data)는 각 지점의 수익(profits)과 각 지점이 있는 지역의
인구수(populations)이다.
해결책! Linear Regression!
이것을 통하여, 새로운 지역의 인구수를 알게 될 경우, 그 지역의 예상 수익을 구
할 수 있다.
Example 1)
13.
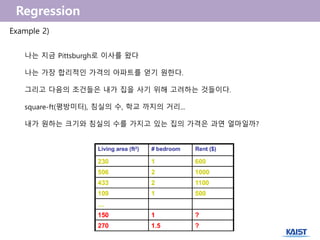
Example 2)
나는 지금Pittsburgh로 이사를 왔다
나는 가장 합리적인 가격의 아파트를 얻기 원한다.
그리고 다음의 조건들은 내가 집을 사기 위해 고려하는 것들이다.
square-ft(평방미터), 침실의 수, 학교 까지의 거리...
내가 원하는 크기와 침실의 수를 가지고 있는 집의 가격은 과연 얼마일까?
14.
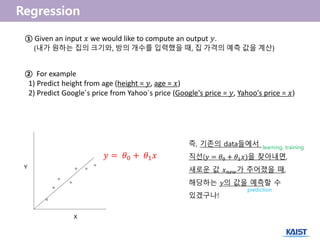
① Given aninput 𝑥 we would like to compute an output 𝑦.
(내가 원하는 집의 크기와, 방의 개수를 입력했을 때, 집 가격의 예측 값을 계산)
② For example
1) Predict height from age (height = 𝑦, age = 𝑥)
2) Predict Google`s price from Yahoo`s price (Google's price = 𝑦, Yahoo's price = 𝑥)
𝑦 = 𝜃0 + 𝜃1 𝑥
즉, 기존의 data들에서
직선(𝑦 = 𝜃0 + 𝜃1 𝑥)을 찾아내면,
새로운 값 𝑥 𝑛𝑒𝑤가 주어졌을 때,
해당하는 𝑦의 값을 예측할 수
있겠구나!
learning, training
prediction
15.
Input : 집의크기(𝑥1), 방의 개수(𝑥2), 학교까지의 거리(𝑥3),.....
(𝑥1, 𝑥2, … , 𝑥 𝑛) : 특성 벡터 feature vector
Output : 집 값(𝑦)
𝒚 = 𝜽 𝟎 + 𝜽 𝟏 𝒙 𝟏 + 𝜽 𝟐 𝒙 𝟐 + ⋯ + 𝜽 𝒏 𝒙 𝒏
training set을 통하여 학습(learning)
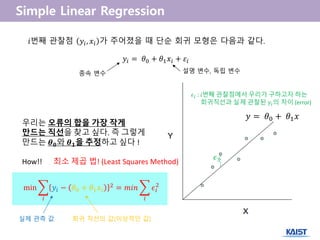
𝑦𝑖 = 𝜃0+ 𝜃1 𝑥𝑖 + 𝜀𝑖
𝑖번째 관찰점 𝑦𝑖, 𝑥𝑖 가 주어졌을 때 단순 회귀 모형은 다음과 같다.
𝜖3
𝜖𝑖 : 𝑖번째 관찰점에서 우리가 구하고자 하는
회귀직선과 실제 관찰된 𝑦𝑖의 차이 (error)
우리는 오류의 합을 가장 작게
만드는 직선을 찾고 싶다. 즉 그렇게
만드는 𝜽 𝟎와 𝜽 𝟏을 추정하고 싶다 !
How!! 최소 제곱 법! (Least Squares Method)
min 𝑦𝑖 − 𝜃0 + 𝜃1 𝑥𝑖
2
𝑖
= 𝑚𝑖𝑛 𝜖𝑖
2
𝑖
𝑦 = 𝜃0 + 𝜃1 𝑥
실제 관측 값 회귀 직선의 값(이상적인 값)
종속 변수 설명 변수, 독립 변수
18.
min 𝑦𝑖 −𝜃0 + 𝜃1 𝑥𝑖
2
𝑖
= min 𝜖𝑖
2
𝑖
실제 관측 값 회귀 직선의 값(이상적인 값)
위의 식을 최대한 만족 시키는 𝜃0, 𝜃1을 추정하는 방법은 무엇일까?
(이러한 𝜃1, 𝜃2를 𝜃1, 𝜃2 라고 하자.)
- Normal Equation
- Steepest Gradient Descent
ˆ ˆ
19.
What is normalequation?
극대 값, 극소 값을 구할 때, 주어진 식을 미분한 후에, 미분한 식을 0으로
만드는 값을 찾는다.
min 𝑦𝑖 − 𝜃0 + 𝜃1 𝑥𝑖
2
𝑖
먼저, 𝜃0에 대하여 미분하자. − 𝑦𝑖 − 𝜃0 + 𝜃1 𝑥𝑖 = 0
𝑖
𝜕
𝜕𝜃0
𝑦𝑖 − 𝜃0 + 𝜃1 𝑥𝑖
2
𝑖
=
다음으로, 𝜃1에 대하여 미분하자. − 𝑦𝑖 − 𝜃0 + 𝜃1 𝑥𝑖 𝑥𝑖 = 0
𝑖
𝜕
𝜕𝜃1
𝑦𝑖 − 𝜃0 + 𝜃1 𝑥𝑖
2
𝑖
=
위 의 두 식을 0으로 만족시키는 𝜃0, 𝜃1를 찾으면 된다. 이처럼 2개의 미지수에 대하여,
2개의 방정식(system)이 있을 때, 우리는 이 system을 normal equation(정규방정식)이라 부른다.
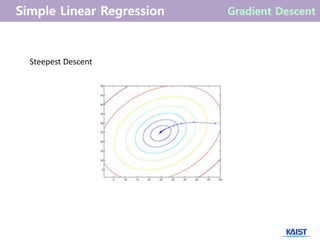
What is GradientDescent?
machine learning에서는 매개 변수(parameter, 선형회귀에서는 𝜃0, 𝜃1)가 수십~
수백 차원의 벡터인 경우가 대부분이다. 또한 목적 함수(선형회귀에서는 Σ𝜖𝑖
2
)가
모든 구간에서 미분 가능하다는 보장이 항상 있는 것도 아니다.
따라서 한 번의 수식 전개로 해를 구할 수 없는 상황이 적지 않게 있다.
이런 경우에는 초기 해에서 시작하여 해를 반복적으로 개선해 나가는 수치적
방법을 사용한다. (미분이 사용 됨)
23.
What is GradientDescent?
초기해 𝛼0 설정
𝑡 = 0
𝛼 𝑡가 만족스럽나?
𝛼 𝑡+1 = 𝑈 𝛼 𝑡
𝑡 = 𝑡 + 1
𝛼 = 𝛼 𝑡
ˆNo
Yes
24.
What is GradientDescent?
Gradient Descent
현재 위치에서 경사가 가장 급하게 하강하는 방향을 찾고,
그 방향으로 약간 이동하여 새로운 위치를 잡는다.
이러한 과정을 반복함으로써 가장 낮은 지점(즉 최저 점)을 찾아 간다.
Gradient Ascent
현재 위치에서 경사가 가장 급하게 상승하는 방향을 찾고,
그 방향으로 약간 이동하여 새로운 위치를 잡는다.
이러한 과정을 반복함으로써 가장 높은 지점(즉 최대 점)을 찾아 간다.
25.
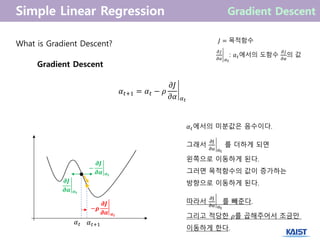
What is GradientDescent?
Gradient Descent
𝛼 𝑡+1 = 𝛼 𝑡 − 𝜌
𝜕𝐽
𝜕𝛼 𝛼 𝑡
𝐽 = 목적함수
𝜕𝐽
𝜕𝛼 𝛼 𝑡
: 𝛼 𝑡에서의 도함수
𝜕𝐽
𝜕𝛼
의 값
𝛼 𝑡 𝛼 𝑡+1
−
𝝏𝑱
𝝏𝜶 𝜶 𝒕
𝝏𝑱
𝝏𝜶 𝜶 𝒕
𝛼 𝑡에서의 미분값은 음수이다.
그래서
𝜕J
𝜕α αt
를 더하게 되면
왼쪽으로 이동하게 된다.
그러면 목적함수의 값이 증가하는
방향으로 이동하게 된다.
따라서
𝜕J
𝜕α αt
를 빼준다.
그리고 적당한 𝜌를 곱해주어서 조금만
이동하게 한다.
−𝝆
𝝏𝑱
𝝏𝜶 𝜶 𝒕
26.
What is GradientDescent?
Gradient Descent
𝛼 𝑡+1 = 𝛼 𝑡 − 𝜌
𝜕𝐽
𝜕𝛼 𝛼 𝑡
Gradient Ascent
𝛼 𝑡+1 = 𝛼 𝑡 + 𝜌
𝜕𝐽
𝜕𝛼 𝛼 𝑡
𝐽 = 목적함수
𝜕𝐽
𝜕𝛼 𝛼 𝑡
: 𝛼 𝑡에서의 도함수
𝜕𝐽
𝜕𝛼
의 값
Gradient Descent, Gradient Ascent는 전형적인 Greedy algorithm이다.
과거 또는 미래를 고려하지 않고 현재 상황에서 가장 유리한 다음 위치를 찾아
Local optimal point로 끝날 가능성을 가진 알고리즘이다.
𝒚 = 𝜽𝟎 + 𝜽 𝟏 𝒙 𝟏 + 𝜽 𝟐 𝒙 𝟐 + ⋯ + 𝜽 𝒏 𝒙 𝒏
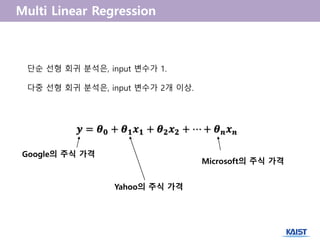
단순 선형 회귀 분석은, input 변수가 1.
다중 선형 회귀 분석은, input 변수가 2개 이상.
Google의 주식 가격
Yahoo의 주식 가격
Microsoft의 주식 가격
34.
𝒚 = 𝜽𝟎 + 𝜽 𝟏 𝒙 𝟏
𝟐 + 𝜽 𝟐 𝒙 𝟐
𝟒 + 𝝐
예를 들어, 아래와 같은 식을 선형으로 생각하여 풀 수 있는가?
물론, input 변수가 polynomial(다항식)의 형태이지만, coefficients 𝜃𝑖가
선형(linear)이므로 선형 회귀 분석의 해법으로 풀 수 있다.
𝚯 = 𝑋 𝑇 𝑋 −1 𝑋 𝑇 𝕪ˆ
𝜃0, 𝜃1, … , 𝜃 𝑛
𝑇
𝒚 = 𝜽𝟎 + 𝜽 𝟏 𝒙 𝟏 + 𝜽 𝟐 𝒙 𝟐 + ⋯ + 𝜽 𝒏 𝒙 𝒏중 회귀 분석
일반 회귀 분석 𝒚 = 𝜽 𝟎 + 𝜽 𝟏 𝒈 𝟏(𝒙 𝟏) + 𝜽 𝟐 𝒈 𝟐(𝒙 𝟐) + ⋯ + 𝜽 𝒏 𝒈 𝒏(𝒙 𝒏)
𝑔𝑗는 𝑥 𝑗
또는
(𝑥−𝜇 𝑗)
2𝜎 𝑗
또는
1
1+exp(−𝑠 𝑗 𝑥)
등의 함수가 될 수 있다.
이것도 마찬가지로 선형 회귀 풀이 방법으로 문제를 풀 수 있다.
[ 자료의 분석]
① 목적 : 집을 팔기 원함. 알맞은 가격을 찾기 원함.
② 고려할 변수(feature) : 집의 크기(in square feet), 침실의 개수, 집 가격
40.
(출처 : http://aimotion.blogspot.kr/2011/10/machine-learning-with-python-linear.html)
③주의사항 : 집의 크기와 침실의 개수의 차이가 크다. 예를 들어, 집의 크기가 4000 square feet인데,
침실의 개수는 3개이다. 즉, 데이터 상 feature들 간 규모의 차이가 크다. 이럴 경우,
feature의 값을 정규화(normalizing)를 해준다. 그래야, Gradient Descent를 수행할 때,
결과값으로 빠르게 수렴하다.
④ 정규화의 방법
- feature의 mean(평균)을 구한 후, feature내의 모든 data의 값에서 mean을 빼준다.
- data에서 mean을 빼 준 값을, 그 data가 속하는 standard deviation(표준 편차)로 나누어 준다. (scaling)
이해가 안 되면, 우리가 고등학교 때 배웠던 정규분포를 표준정규분포로 바꾸어주는 것을 떠올려보자.
표준정규분포를 사용하는 이유 중 하나는, 서로 다른 두 분포, 즉 비교가 불가능하거나 어려운 두 분포를 쉽게
비교할 수 있게 해주는 것이었다.
𝑍 =
𝑋 − 𝜇
𝜎
If 𝑋~(𝜇, 𝜎) then 𝑍~𝑁(1,0)
Laplacian Smoothing
multinomial randomvariable 𝑧 : 𝑧는 1부터 𝑘까지의 값을 가질 수 있다.
우리는 test set으로 𝑚개의 독립인 관찰 값 𝑧 1
, … , 𝑧 𝑚
을 가지고 있다.
우리는 관찰 값을 통해, 𝒑(𝒛 = 𝒊) 를 추정하고 싶다. (𝑖 = 1, … , 𝑘)
추정 값(MLE)은,
𝑝 𝑧 = 𝑗 =
𝐼{𝑧 𝑖
= 𝑗}𝑚
𝑖=1
𝑚
이다. 여기서 𝐼 . 는 지시 함수 이다. 관찰 값 내에서의 빈도수를 사용하여 추정한다.
한 가지 주의 할 것은, 우리가 추정하려는 값은 모집단(population)에서의 모수
𝑝(𝑧 = 𝑖)라는 것이다. 추정하기 위하여 test set(or 표본 집단)을 사용하는 것 뿐이다.
예를 들어, 𝑧(𝑖)
≠ 3 for all 𝑖 = 1, … , 𝑚 이라면, 𝑝 𝑧 = 3 = 0 이 되는 것이다.
이것은, 통계적으로 볼 때, 좋지 않은 생각이다. 단지, 표본 집단에서 보이지
않는 다는 이유로 우리가 추정하고자 하는 모집단의 모수 값을 0으로 한다는 것은
통계적으로 좋지 않은 생각(bad idea)이다. (MLE의 약점)
43.
이것을 극복하기 위해서는,
①분자가 0이 되어서는 안 된다.
② 추정 값의 합이 1이 되어야 한다. 𝑝 𝑧 = 𝑗𝑧 =1 (∵ 확률의 합은 1이 되어야 함)
따라서,
𝒑 𝒛 = 𝒋 =
𝑰 𝒛 𝒊
= 𝒋 + 𝟏𝒎
𝒊=𝟏
𝒎 + 𝒌
이라고 하자.
①의 성립 : test set 내에 𝑗의 값이 없어도, 해당 추정 값은 0이 되지 않는다.
②의 성립 : 𝑧(𝑖)
= 𝑗인 data의 수를 𝑛𝑗라고 하자. 𝑝 𝑧 = 1 =
𝑛1+1
𝑚+𝑘
, … , 𝑝 𝑧 = 𝑘 =
𝑛 𝑘+1
𝑚+𝑘
이다. 각 추정 값을 다 더하게 되면 1이 나온다.
이것이 바로 Laplacian smoothing이다.
𝑧가 될 수 있는 값이 1부터 𝑘까지 균등하게 나올 수 있다는 가정이 추가되었다고
직관적으로 알 수 있다.
1





























![[ 자료의 분석 ]
① 목적 : 집을 팔기 원함. 알맞은 가격을 찾기 원함.
② 고려할 변수(feature) : 집의 크기(in square feet), 침실의 개수, 집 가격](https://image.slidesharecdn.com/03-161011160648/85/03-linear-regression-39-320.jpg)



































![[Probability for machine learning]](https://cdn.slidesharecdn.com/ss_thumbnails/probabilityformachinelearning-180726131331-thumbnail.jpg?width=640&height=640&fit=bounds)
![[신경망기초] 선형회귀분석](https://cdn.slidesharecdn.com/ss_thumbnails/nn07-180318142107-thumbnail.jpg?width=640&height=640&fit=bounds)










![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=640&height=640&fit=bounds)

