언어 모형(Language Model)
자연어생성(Natural Language Generation)의 기반이 되는 모형
예시 :
음성인식, 기계번역, 검색어 자동 완성 등
언어 모형이 하는 일
1. 문장의 확률을 계산
2. 이전 단어 주어질 때, 다음 단어가 나올 확률을 계산
단어들의 조합이 얼마나 적절한지, 또는 해당 문장이 얼마나 적합한지 알려준다!
3.
문장의 확률을 왜계산해야 할까?
예시 1 : 기계 번역
P(나는 버스를 탔다) P(나는 버스를 태운다)
예시 2 : 오타 교정
P(달렸다) P(잘렸다)
성한이가 지각하여 부리나케
예시 3 : 음성 인식
P(희선이가 메론을 먹는다) P(희선이가 메롱을 먹는다)
언어 모델은 보다 적절한 문장을 선택하는 데에 확률을 사용한다
4.
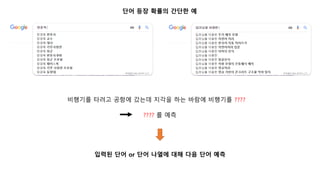
단어 등장 확률의간단한 예
입력된 단어 or 단어 나열에 대해 다음 단어 예측
비행기를 타려고 공항에 갔는데 지각을 하는 바람에 비행기를 ????
???? 를 예측
5.
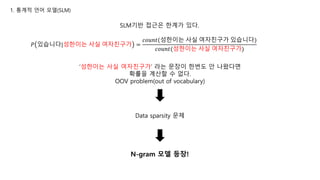
1. 통계적 언어모델(SLM)
많이 봤던 probability의 chain rule 혹은 factorization
성한이는 사실 여자친구가 있습니다.
라는 문장의 확률식을 한번 구해보자
𝑥1
성한이는 사실 여자친구가 있습니다
𝑥2 𝑥3 𝑥4
P(“성한이는 사실 여자친구가 있습니다”) =
P( 성한이는 ) x P( 사실 | 성한이는 ) x P( 여자친구가 | 성한이는 사실 ) x P( 있습니다 | 성한이는 사실 여자친구가 )
6.
𝑃 성한이는 =
𝑐𝑜𝑢𝑛𝑡(성한이는)
𝑐𝑜𝑢𝑛𝑡(𝑐𝑜𝑟𝑝𝑢𝑠𝑑𝑎𝑡𝑎)
𝑃 사실 성한이는 =
𝑐𝑜𝑢𝑛𝑡(성한이는 사실)
𝑐𝑜𝑢𝑛𝑡(성한이는)
𝑃 여자친구가 성한이는 사실 =
𝑐𝑜𝑢𝑛𝑡(성한이는 사실 여자친구가)
𝑐𝑜𝑢𝑛𝑡(성한이는 사실)
Corpus 데이터에서 ‘성한이는 사실 여자친구가’가 100번 나왔는데 그 다음에 있습니다가 나온게 30번 이면
P(있습니다|성한이는 사실 여자친구가) = 0.3
예시
실제 확률은 어떻게 구할까?
P(“성한이는 사실 여자친구가 있습니다”) =
P( 성한이는 ) x P( 사실 | 성한이는 ) x P( 여자친구가 | 성한이는 사실 ) x P( 있습니다 | 성한이는 사실 여자친구가 )
1. 통계적 언어 모델(SLM)
7.
SLM기반 접근은 한계가있다.
𝑃 있습니다|성한이는 사실 여자친구가 =
𝑐𝑜𝑢𝑛𝑡(성한이는 사실 여자친구가 있습니다)
𝑐𝑜𝑢𝑛𝑡(성한이는 사실 여자친구가)
‘성한이는 사실 여자친구가’ 라는 문장이 한번도 안 나왔다면
확률을 계산할 수 없다.
OOV problem(out of vocabulary)
Data sparsity 문제
N-gram 모델 등장!
1. 통계적 언어 모델(SLM)
8.
2. n-gram languagemodel
N-gram 의 concept
𝑃 있습니다|성한이는 사실 여자친구가 ≈ 𝑃(있습니다|여자친구가)
앞 토큰 중 n개만 포함해서 count -> 좀 더 짧은 word sequence를 고려
Unigrams : 성한이는 / 사실 / 여자친구가 / 있습니다
Bigrams : 성한이는 사실 / 사실 여자친구가 / 여자친구가 있습니다
Trigrams : 성한이는 사실 여자친구가 / 사실 여자친구가 있습니다.
4-grams : 성한이는 사실 여자친구가 있습니다
‘성한이는 사실 여자친구가 있습니다’ 보다는
‘여자친구가 있습니다’ 가 corpus data에 있을 가능성이 높기 때문
9.
“성한이가 지금 연애중이라는 것은 사실 거짓말입니다.”좀 더 긴 문장으로
1. Unigram (n=1)
𝑃 𝑥1, 𝑥2, … , 𝑥7 = 𝑃 𝑥0
𝑡=1
7
𝑃(𝑥 𝑡|𝑥 𝑡) = 𝑃(𝑥1)𝑃(𝑥2) ⋯ 𝑃(𝑥7)
1 2 3 4 5 6 7
𝑃 성한이가 지금 연애 중이라는 것은 사실 거짓말입니다. = 𝑃 성한이가 𝑃(지금) ⋯ 𝑃(거짓말입니다)
각 토큰이 독립
2. Trigram (n=3)
𝑃 𝑥1, 𝑥2, … , 𝑥7 = 𝑃 𝑥1, 𝑥2
𝑡=3
7
𝑃(𝑥 𝑡|𝑥 𝑡−2, 𝑥 𝑡−1) = 𝑃 𝑥1, 𝑥2 𝑃 𝑥3 𝑥1, 𝑥2 𝑃 𝑥4 𝑥2, 𝑥3 ⋯ 𝑃(𝑥7|𝑥5, 𝑥6)
𝑃 성한이가 지금 𝑃 연애 성한이가 지금) ⋯ 𝑃(거짓말입니다 | 것은 사실)
2. n-gram language model
10.
2. n-gram languagemodel 𝒙 𝒕
=
𝑐𝑜𝑢𝑛𝑡(성한이가 지금 연애 중이라는 것은 사실)
𝑐𝑜𝑢𝑛𝑡(𝑐𝑜𝑟𝑝𝑢𝑠 𝑑𝑎𝑡𝑎)
=
𝑐𝑜𝑢𝑛𝑡(성한이가 지금 연애 중이라는 것은 사실 거짓말입니다)
𝑐𝑜𝑢𝑛𝑡(𝑐𝑜𝑟𝑝𝑢𝑠 𝑑𝑎𝑡𝑎)
𝑃(거짓말입니다 | 성한이가 지금 연애 중이라는 것은 사실 ) 를 구해보면
=
𝑐𝑜𝑢𝑛𝑡(성한이가 지금 연애 중이라는 것은 사실 거짓말입니다)
𝑐𝑜𝑢𝑛𝑡(성한이가 지금 연애 중이라는 것은 사실)
이 조건부 확률들을 다 구하면 문장의 probability가 계산됨
11.
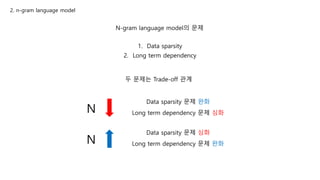
N-gram language model의문제
1. Data sparsity
2. Long term dependency
두 문제는 Trade-off 관계
N
Data sparsity 문제 완화
Long term dependency 문제 심화
N
Data sparsity 문제 심화
Long term dependency 문제 완화
2. n-gram language model
12.
N-gram 모델의 문제점을해결하기 위한 시도들
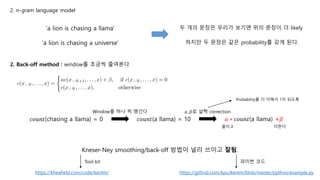
1. smoothing
‘a lion is chasing a llama’ 라는 예시가 있습니다.
𝑃 a lion is chasing a llama = 𝑃(a lion)𝑃 is a lion)𝑃 chasing lion is)𝑃 a is chasing)𝑃 llama chasing a)
취미 : 쫓기 취미 : 가만히 있기
trigram probability 계산
누가봐도 달리기 못해보임
likely likely likely likely =0
Probability가 0 되는 것을 막기 위해 작은 상수를 더해준다.
오 괜찮아 보임
하지만 문제점이 있음
2. n-gram language model
13.
‘a lion ischasing a llama’
‘a lion is chasing a universe’
두 개의 문장은 우리가 보기엔 위의 문장이 더 likely
하지만 두 문장은 같은 probability를 갖게 된다.
2. Back-off method : window를 조금씩 줄여본다
𝑐𝑜𝑢𝑛𝑡(chasing a llama) = 0 𝑐𝑜𝑢𝑛𝑡(a llama) = 10
Window를 하나 씩 땡긴다
𝛼 ∗ 𝑐𝑜𝑢𝑛𝑡(a llama) +𝛽
𝛼, 𝛽로 살짝 correction
Probability를 다 더해서 1이 되도록
줄이고 더한다
Kneser-Ney smoothing/back-off 방법이 널리 쓰이고 잘됨.
https://github.com/kpu/kenlm/blob/master/python/example.py
파이썬 코드
https://kheafield.com/code/kenlm/
Tool kit
2. n-gram language model
14.
N-gram language model의문제
1. Data sparsity -> clear(어느정도는)
2. Long term dependency
하지만 long term dependency 문제는 해결 불가…
Count 기반 방법에서는 두 가지 문제를 동시에 해결할 수 없음.
그래서 등장한
Neural N-gram language model
2. n-gram language model
15.
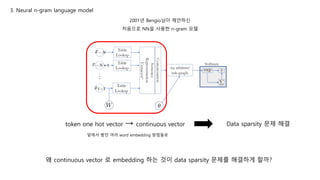
3. Neural n-gramlanguage model
2001년 Bengio님이 제안하신
처음으로 NN을 사용한 n-gram 모델
token one hot vector → continuous vector
앞에서 봤던 여러 word embedding 방법들로
왜 continuous vector 로 embedding 하는 것이 data sparsity 문제를 해결하게 할까?
Data sparsity 문제 해결
16.
3. Neural n-gramlanguage model
𝑐𝑜𝑢𝑛𝑡 chasing a llama = 0
지금까지 우리가 겪은 data sparsity 문제
In training set
𝑐𝑜𝑢𝑛𝑡 chasing a cat ≫ 0
𝑐𝑜𝑢𝑛𝑡 chasing a dog ≫ 0
𝑐𝑜𝑢𝑛𝑡 chasing a deer ≫ 0
𝑃 𝑙𝑙𝑎𝑚𝑎|𝑐ℎ𝑎𝑠𝑖𝑛𝑔 𝑎 = 0
만약 llama와 cat, dog, deer가 유사하다는 것을 모델이 알 수 있다면?
𝑃 𝑐𝑎𝑡|𝑐ℎ𝑎𝑠𝑖𝑛𝑔 𝑎 ≫ 0
𝑃 𝑑𝑜𝑔|𝑐ℎ𝑎𝑠𝑖𝑛𝑔 𝑎 ≫ 0
𝑃 𝑑𝑒𝑒𝑟|𝑐ℎ𝑎𝑠𝑖𝑛𝑔 𝑎 ≫ 0
‘Chasing a llama’의 count가 0 이어도 ‘Chasing a cat’과 유사한 값을 부여할 수 있겠다!
Count 기반의 representation은 유사도 비교 불가
[1,0,…,0] ∙ [0,1,…,0] = 0 (in discrete space)
Continuous representation은 유사도 비교 가능
𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦([19,3,5],[15,10,5]) = ℝ (in continuous space)
17.
3. Neural n-gramlanguage model
3개의 training example이 있다.
three 다음에 groups가 오는 것을 예측해야 하는 상황우리의 task
N-gram model은 확률을 0으로 계산하겠지만
Neural n-gram model은 어떻게 하는지 한번 보자
18.
3. Neural n-gramlanguage model
Continuous vector space
three
[1,0,….0]
어떤
Network
[4,6,7]
three
[4,6,7]
three
softmax target
team
Loss
function
[0,0,1,….0]
three라는 토큰이 들어가면 team에 해당하는 probability가 높게 나오도록 training
Continuous vector space
four
[0,1,….0]
어떤
Network
[5,4,3]
[5,4,3]
softmax target
team
Loss
function
[0,0,1,….0]
four라는 토큰이 들어가면 team에 해당하는 probability가 높게 나오도록 training
four
four
19.
3. Neural n-gramlanguage model
Continuous vector space
three
[1,0,….0]
[4,6,7]
three
four
[0,1,….0]
[5,4,3]
softmax target
team
Loss
function
[0,0,1,….0]
four
이상적으로는 three와 four는 같은 point에 찍히고,
Continuous vector space
three
[1,0,….0]
[4,6,7]
three
four
[0,1,….0]
four
현실적으로는 three와 four는 가까운 point에 찍힌다.
Continuous vector space
three
[1,0,….0]
[4,6,7]
three
four
[0,1,….0]
four
[5,6,7]
같은
Network
20.
3. Neural n-gramlanguage model
Continuous vector space
three
[1,0,….0]
[4,6,7]
three
four
[0,1,….0]
four
[5,6,7]
같은 network
[4,6,7]
three
softmax target
team
Loss
function
[0,0,1,….0]
four
[5,6,7]
Continuous vector space
three
[1,0,….0]
[4,6,7]
three
four
[0,1,….0]
four
[5,6,7]
같은 network
[4,6,7]
three
softmax target
groups
Loss
function
[0,0,0,….1]
four
[5,6,7]
그런데 이때 세 번째 example을 보면 four groups이다
21.
3. Neural n-gramlanguage model
Continuous vector space
three
[1,0,….0]
[4,6,7]
three
four
[0,1,….0]
[5,6,7]
four
같은
network
softmax target
team
Loss
function
[0,0,1,….0]
groups
[0,0,0,….1]
Softmax layer에 team, groups 둘 다 높은 probability가 계산되도록 network learning
three와 four는 continuous space 상에서 유사한 representation을 가지게 되고,
team과 groups에 높은 probability를 부여하는 network를 공유하고 있다.
정리 해보면
22.
3. Neural n-gramlanguage model
three와 four는 continuous space 상에서 유사한 representation을 가지게 되고,
team과 groups에 높은 probability를 부여하는 network를 공유하고 있다.
정리 해보면
three 다음에 groups가 오는 것을 예측해야 하는 상황우리의 task
three groups라는 n-gram이 training example에 없더라도
three라는 input이 들어오면 teams와 groups에 높은 probability가 계산된다.
그래서
23.
3. Neural n-gramlanguage model
이렇게 neural n-gram model로 data sparsity 문제를 해결하였다.
그럼 이제 long term dependency 문제를 해결해보자
long term dependency 문제의 근본적인 원인
앞의 token들을 많이 봐야 함 → N을 매우 늘려야함 → count가 0이 되는 문제가 생김.
↓
neural n-gram 모델로 이것은 해결됨.
오 그럼 N을 엄청나게 늘려볼까??
아키텍처가 매우 커지고 파라미터도 매우 늘어남.
당시(2001년)의 평범한 neural network로는 어렵다…
24.
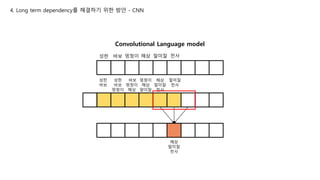
4. Long termdependency를 해결하기 위한 방안 - CNN
성한 바보 멍청이 해삼 말미잘 천사
기존 n-gram은 이렇게 앞에 n-1개만 봤었다.
성한 바보 멍청이 해삼 말미잘 천사
이렇게 앞에 많이 여러 개를 봐야 하는데 평범한 NN으로는 힘들었다
25.
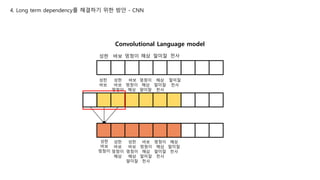
Convolutional Language model
성한바보 멍청이 해삼 말미잘 천사
N을 마구 늘리지 않고도 넓은 범위의 토큰을 볼 수 있는 방법이 있으니
4. Long term dependency를 해결하기 위한 방안 - CNN
요것이 필터
Convolutional Language model
성한바보 멍청이 해삼 말미잘 천사
4. Long term dependency를 해결하기 위한 방안 - CNN
성한
바보
성한
바보
멍청이
바보
멍청이
해삼
멍청이
해삼
말미잘
해삼
말미잘
천사
29.
Convolutional Language model
성한바보 멍청이 해삼 말미잘 천사
4. Long term dependency를 해결하기 위한 방안 - CNN
성한
바보
성한
바보
멍청이
바보
멍청이
해삼
멍청이
해삼
말미잘
해삼
말미잘
천사
말미잘
천사
해삼
말미잘
천사
30.
Convolutional Language model
성한바보 멍청이 해삼 말미잘 천사
4. Long term dependency를 해결하기 위한 방안 - CNN
성한
바보
성한
바보
멍청이
바보
멍청이
해삼
멍청이
해삼
말미잘
해삼
말미잘
천사
말미잘
천사
해삼
말미잘
천사
멍청이
해삼
말미잘
천사
바보
멍청이
해삼
말미잘
천사
성한
바보
멍청이
해삼
말미잘
성한
바보
멍청이
해삼
성한
바보
멍청이
31.
Convolutional Language model
성한바보 멍청이 해삼 말미잘 천사
4. Long term dependency를 해결하기 위한 방안 - CNN
성한
바보
성한
바보
멍청이
바보
멍청이
해삼
멍청이
해삼
말미잘
해삼
말미잘
천사
말미잘
천사
해삼
말미잘
천사
멍청이
해삼
말미잘
천사
바보
멍청이
해삼
말미잘
천사
성한
바보
멍청이
해삼
말미잘
성한
바보
멍청이
해삼
성한
바보
멍청이
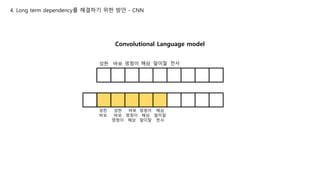
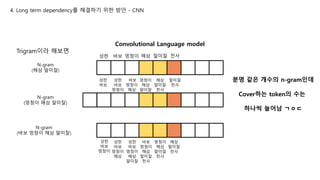
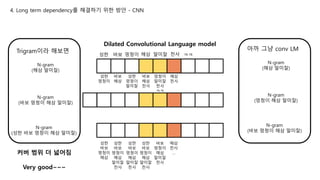
Trigram이라 해보면
N-gram
(해삼 말미잘)
N-gram
(멍청이 해삼 말미잘)
N-gram
(바보 멍청이 해삼 말미잘)
분명 같은 개수의 n-gram인데
Cover하는 token의 수는
하나씩 늘어남 ㄱㅇㄷ
32.
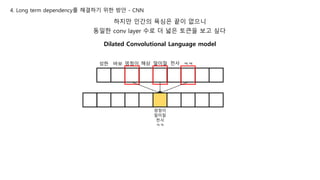
하지만 인간의 욕심은끝이 없으니
동일한 conv layer 수로 더 넓은 토큰을 보고 싶다
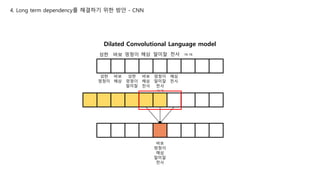
Dilated Convolutional Language model
4. Long term dependency를 해결하기 위한 방안 - CNN
성한 바보 멍청이 해삼 말미잘 천사
멍청이
말미잘
천사
ㅋㅋ
ㅋㅋ
33.
Dilated Convolutional Languagemodel
4. Long term dependency를 해결하기 위한 방안 - CNN
성한 바보 멍청이 해삼 말미잘 천사
멍청이
말미잘
천사
ㅋㅋ
ㅋㅋ
성한
멍청이
말미잘
바보
해삼
천사
바보
해삼
성한
멍청이
바보
멍청이
해삼
말미잘
천사
해삼
천사
4. Long termdependency를 해결하기 위한 방안 - CNN
Cover 범위 넓어진 건 좋은데 문제가 있다
지금까지 language 모델은 항상 target token의 앞 token만 봤었는데
얘는 앞 token+ target token + 뒤 token까지 보고있다.
그래서 target token + 뒤 token은 모델링 과정에서
전부 masking out 한다
뭔가 상상하면 불가능할 것 같지만
masking pattern 찾아내면 쉽게 구현된다고 한다.
현재 유명한 방법들
안드로이드에 내장돼있음
Facebook AI research에서 만든 거 nonlinear function을
gated function 쓴다함
36.
RNN의 기본 컨셉
4.Long term dependency를 해결하기 위한 방안 - RNN
메모리를 가지고 있어서 현재까지 읽는 정보를 저장할 수 있음
문장의 정보를 시간의 순서에 따라 하나의 벡터 representation에 압축
현재 가장 많이 쓰이는 language model
1. 스마트폰 키보드 자동완성
2. Speech generation
3. 검색엔진에서 키워드 제시











![3. Neural n-gram language model
𝑐𝑜𝑢𝑛𝑡 chasing a llama = 0
지금까지 우리가 겪은 data sparsity 문제
In training set
𝑐𝑜𝑢𝑛𝑡 chasing a cat ≫ 0
𝑐𝑜𝑢𝑛𝑡 chasing a dog ≫ 0
𝑐𝑜𝑢𝑛𝑡 chasing a deer ≫ 0
𝑃 𝑙𝑙𝑎𝑚𝑎|𝑐ℎ𝑎𝑠𝑖𝑛𝑔 𝑎 = 0
만약 llama와 cat, dog, deer가 유사하다는 것을 모델이 알 수 있다면?
𝑃 𝑐𝑎𝑡|𝑐ℎ𝑎𝑠𝑖𝑛𝑔 𝑎 ≫ 0
𝑃 𝑑𝑜𝑔|𝑐ℎ𝑎𝑠𝑖𝑛𝑔 𝑎 ≫ 0
𝑃 𝑑𝑒𝑒𝑟|𝑐ℎ𝑎𝑠𝑖𝑛𝑔 𝑎 ≫ 0
‘Chasing a llama’의 count가 0 이어도 ‘Chasing a cat’과 유사한 값을 부여할 수 있겠다!
Count 기반의 representation은 유사도 비교 불가
[1,0,…,0] ∙ [0,1,…,0] = 0 (in discrete space)
Continuous representation은 유사도 비교 가능
𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦([19,3,5],[15,10,5]) = ℝ (in continuous space)](https://image.slidesharecdn.com/nlp-final-2-190407072020/85/Natural-Language-Processing-NLP-basic-2-16-320.jpg)

![3. Neural n-gram language model
Continuous vector space
three
[1,0,….0]
어떤
Network
[4,6,7]
three
[4,6,7]
three
softmax target
team
Loss
function
[0,0,1,….0]
three라는 토큰이 들어가면 team에 해당하는 probability가 높게 나오도록 training
Continuous vector space
four
[0,1,….0]
어떤
Network
[5,4,3]
[5,4,3]
softmax target
team
Loss
function
[0,0,1,….0]
four라는 토큰이 들어가면 team에 해당하는 probability가 높게 나오도록 training
four
four](https://image.slidesharecdn.com/nlp-final-2-190407072020/85/Natural-Language-Processing-NLP-basic-2-18-320.jpg)
![3. Neural n-gram language model
Continuous vector space
three
[1,0,….0]
[4,6,7]
three
four
[0,1,….0]
[5,4,3]
softmax target
team
Loss
function
[0,0,1,….0]
four
이상적으로는 three와 four는 같은 point에 찍히고,
Continuous vector space
three
[1,0,….0]
[4,6,7]
three
four
[0,1,….0]
four
현실적으로는 three와 four는 가까운 point에 찍힌다.
Continuous vector space
three
[1,0,….0]
[4,6,7]
three
four
[0,1,….0]
four
[5,6,7]
같은
Network](https://image.slidesharecdn.com/nlp-final-2-190407072020/85/Natural-Language-Processing-NLP-basic-2-19-320.jpg)
![3. Neural n-gram language model
Continuous vector space
three
[1,0,….0]
[4,6,7]
three
four
[0,1,….0]
four
[5,6,7]
같은 network
[4,6,7]
three
softmax target
team
Loss
function
[0,0,1,….0]
four
[5,6,7]
Continuous vector space
three
[1,0,….0]
[4,6,7]
three
four
[0,1,….0]
four
[5,6,7]
같은 network
[4,6,7]
three
softmax target
groups
Loss
function
[0,0,0,….1]
four
[5,6,7]
그런데 이때 세 번째 example을 보면 four groups이다](https://image.slidesharecdn.com/nlp-final-2-190407072020/85/Natural-Language-Processing-NLP-basic-2-20-320.jpg)
![3. Neural n-gram language model
Continuous vector space
three
[1,0,….0]
[4,6,7]
three
four
[0,1,….0]
[5,6,7]
four
같은
network
softmax target
team
Loss
function
[0,0,1,….0]
groups
[0,0,0,….1]
Softmax layer에 team, groups 둘 다 높은 probability가 계산되도록 network learning
three와 four는 continuous space 상에서 유사한 representation을 가지게 되고,
team과 groups에 높은 probability를 부여하는 network를 공유하고 있다.
정리 해보면](https://image.slidesharecdn.com/nlp-final-2-190407072020/85/Natural-Language-Processing-NLP-basic-2-21-320.jpg)









![[study] character aware neural language models](https://cdn.slidesharecdn.com/ss_thumbnails/181114characterawareneurallanguagemodels-190321063423-thumbnail.jpg?width=640&height=640&fit=bounds)












![[싸이그램즈 2018] 텍스트 데이터 전처리로 시작하는 NLP](https://cdn.slidesharecdn.com/ss_thumbnails/psygramsnlp101-180704045500-thumbnail.jpg?width=640&height=640&fit=bounds)






























