“In this chapter,we present several of the specific kinds of generative models
That can be built and trained using the techniques presented in chapters 16–19.”
Ch 16 Structured Probabilistic Models for Deep Learning
Ch 17 Monte Carlo Methods
Ch 18 Confronting the Partition Function
Ch 19 Approximate Inference
Ch 20 Deep Generative Models
20.1 Boltzmann Machines
20.2 Restricted Boltzmann Machines
20.3 Deep Belief Networks
20.4 Deep Boltzmann Machines
20.5 Boltzmann Machines for Real-Valued Data
20.6 Convolutional Boltzmann Machines
20.7 Boltzmann Machines for Structured or Sequential Outputs
20.8 Other Boltzmann Machines
15.
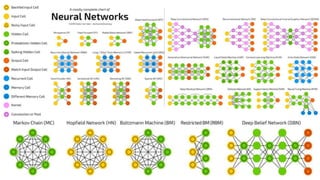
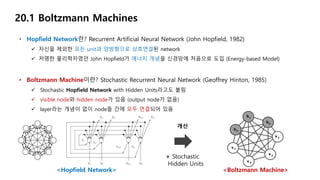
• Hopfield Network란?Recurrent Artificial Neural Network (John Hopfield, 1982)
자신을 제외한 모든 unit과 양방향으로 상호연결된 network
저명한 물리학자였던 John Hopfield가 에너지 개념을 신경망에 처음으로 도입 (Energy-based Model)
• Boltzmann Machine이란? Stochastic Recurrent Neural Network (Geoffrey Hinton, 1985)
Stochastic Hopfield Network with Hidden Units라고도 불림
visible node와 hidden node가 있음 (output node가 없음)
layer라는 개념이 없이 node들 간에 모두 연결되어 있음
20.1 Boltzmann Machines
<Hopfield Network> <Boltzmann Machine>
+ Stochastic
Hidden Units
개선
16.
20.1 Boltzmann Machines
•Boltzmann Machine이란? Stochastic Recurrent Neural Network (Geoffrey Hinton, 1985)
Stochastic Hopfield Network with Hidden Units라고도 불림
visible node와 hidden node가 있음 (output node가 없음)
layer라는 개념이 없이 node들 간에 모두 연결되어 있음
주어진 input data는 fixed 되어 있기 때문에,
사실상 visible node 사이의 연결은 의미 없는 것 아닌가?
(visible node 사이의 weight를 학습할 필요가 있는가?)
Boltzmann Machine이 다른 알고리즘과 근본적으로 다른 것은
input data를 그대로 쓰는게 아니라, data를 generate한다는 것
Boltzmann Machine 입장에서는 visible node와 hidden node를 구분하지 않음
우리에게만 구분되는 것이지, Boltzmann Machine은 node들을 하나의 시스템으로 봄
“visible node들이 서로 연결되어 있는 이유가 뭘까?”
17.
20.1 Boltzmann Machines
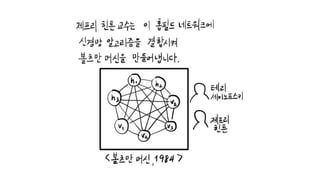
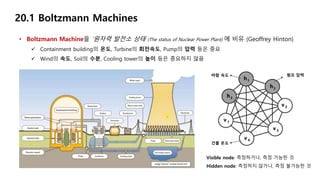
•Boltzmann Machine을 ‘원자력 발전소 상태 (The status of Nuclear Power Plant) 에 비유 (Geoffrey Hinton)
Containment building의 온도, Turbine의 회전속도, Pump의 압력 등은 중요
Wind의 속도, Soil의 수분, Cooling tower의 높이 등은 중요하지 않음
Visible node: 측정하거나, 측정 가능한 것
Hidden node: 측정하지 않거나, 측정 불가능한 것
건물 온도
바람 속도 펌프 압력
18.
20.1 Boltzmann Machines
•Boltzmann Machine을 ‘원자력 발전소 상태 (The status of Nuclear Power Plant) 에 비유 (Geoffrey Hinton)
Boltzmann Machine의 visible node에 우리가 가진 training data를 넣어주면,
system의 weight들을 조정하는 데 ‘도움’을 줌 (MLE: Maximum Likelihood Estimation)
학습이 진행되면, 점점 our system을 닮아가게(resemble) 되고, 세상에 존재하는
어떤 원자력 발전소가 아니라, 우리가 넣은(feeding) training data로부터 학습
된 our 원자력 발전소가 됨
학습이 완료되면, Boltzmann Machine은 node들 사이의 interaction이나
constraint 등을 이해하게 되고, 학습된 weight을 통해 시스템의 다양한 state를
generate 할 수 있음 (원자력 발전소 상태가 정상 or 비정상인지 모니터링 가능)
Deterministic deep learning model이 아니라 Stochastic deep learning model
인 이유 (더 나아가, Generative deep learning model)
건물 온도
바람 속도 펌프 압력
<원자력 발전소>
자세한 수식 설명
19.
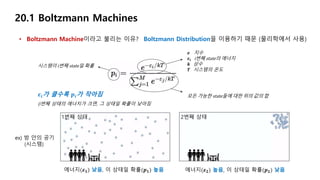
• Boltzmann Machine이라고불리는 이유?
20.1 Boltzmann Machines
𝒆 지수
𝜺𝒊 i번째 state의 에너지
𝒌 상수
𝑻 시스템의 온도
시스템이 i번째 state일 확률
모든 가능한 state들에 대한 위의 값의 합𝜺𝒊가 클수록 𝒑𝒊가 작아짐
(i번째 상태의 에너지가 크면, 그 상태일 확률이 낮아짐
ex) 방 안의 공기
(시스템)
에너지(𝜺 𝟏) 낮음, 이 상태일 확률(𝒑 𝟏) 높음 에너지(𝜺 𝟐) 높음, 이 상태일 확률(𝒑 𝟐) 낮음
1번째 상태 2번째 상태
Boltzmann Distribution을 이용하기 때문 (물리학에서 사용)
20.
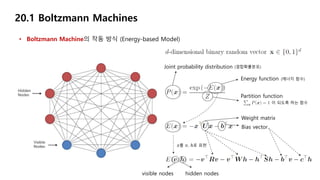
• Boltzmann Machine의작동 방식 (Energy-based Model)
20.1 Boltzmann Machines
Partition function
이 되도록 하는 함수
Energy function (에너지 함수)
Joint probability distribution (결합확률분포)
Weight matrix
Bias vector
𝑥를 𝑣, ℎ로 표현
visible nodes hidden nodes
20.2 Restricted BoltzmannMachines
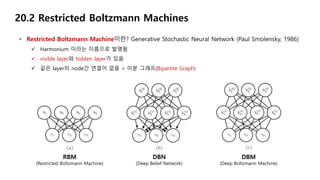
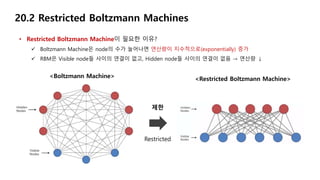
• Restricted Boltzmann Machine이 필요한 이유?
Boltzmann Machine은 node의 수가 늘어나면 연산량이 지수적으로(exponentially) 증가
RBM은 Visible node들 사이의 연결이 없고, Hidden node들 사이의 연결이 없음 → 연산량 ↓
<Boltzmann Machine> <Restricted Boltzmann Machine>
Restricted
제한
23.
20.2 Restricted BoltzmannMachines
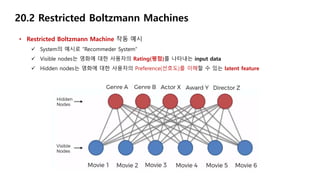
• Restricted Boltzmann Machine 작동 예시
System의 예시로 “Recommeder System”
Visible nodes는 영화에 대한 사용자의 Rating(평점)를 나타내는 input data
Hidden nodes는 영화에 대한 사용자의 Preference(선호도)를 이해할 수 있는 latent feature
24.
20.2 Restricted BoltzmannMachines
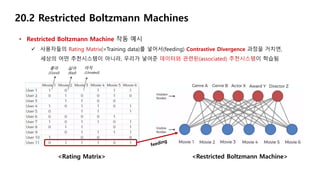
• Restricted Boltzmann Machine 작동 예시
사용자들의 Rating Matrix(=Training data)를 넣어서(feeding) Contrastive Divergence 과정을 거치면,
세상의 어떤 추천시스템이 아니라, 우리가 넣어준 데이터와 관련된(associated) 추천시스템이 학습됨
<Rating Matrix> <Restricted Boltzmann Machine>
좋아
(Good)
싫어
(Bad)
아직
(Unrated)
25.
20.2 Restricted BoltzmannMachines
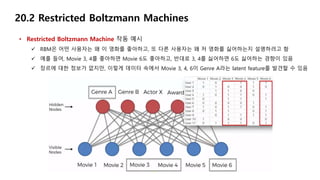
• Restricted Boltzmann Machine 작동 예시
RBM은 어떤 사용자는 왜 이 영화를 좋아하고, 또 다른 사용자는 왜 저 영화를 싫어하는지 설명하려고 함
예를 들어, Movie 3, 4를 좋아하면 Movie 6도 좋아하고, 반대로 3, 4를 싫어하면 6도 싫어하는 경향이 있음
장르에 대한 정보가 없지만, 이렇게 데이터 속에서 Movie 3, 4, 6이 Genre A라는 latent feature를 발견할 수 있음
20.2 Restricted BoltzmannMachines
• Restricted Boltzmann Machine 작동 예시
RBM이 학습이 완료된 상태에서, 새로운 사용자의 평점 데이터 [0, , 1, 0, 1, ]를 입력으로 넣으면
평점이 비어 있는 영화들에 대해서 어떤 결과를 보일까?
29.
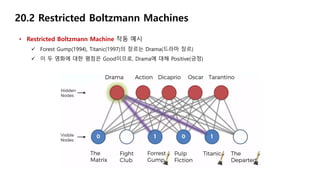
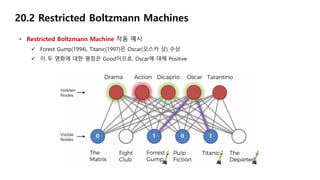
20.2 Restricted BoltzmannMachines
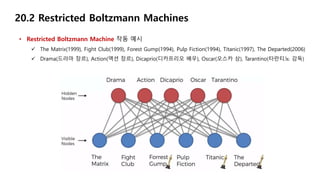
• Restricted Boltzmann Machine 작동 예시
Forest Gump(1994), Titanic(1997)의 장르는 Drama(드라마 장르)
이 두 영화에 대한 평점은 Good이므로, Drama에 대해 Positive(긍정)
30.
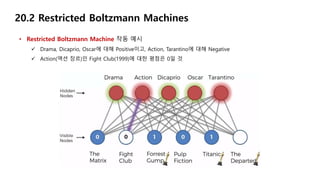
20.2 Restricted BoltzmannMachines
• Restricted Boltzmann Machine 작동 예시
The Matrix(1999), Pulp Fiction(1994)의 장르는 Action(액션 장르)
이 두 영화에 대한 평점은 Bad이므로, Action에 대해 Negative
31.
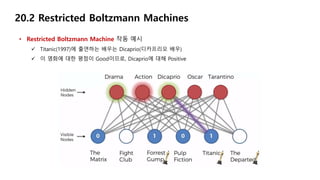
20.2 Restricted BoltzmannMachines
• Restricted Boltzmann Machine 작동 예시
Titanic(1997)에 출연하는 배우는 Dicaprio(디카프리오 배우)
이 영화에 대한 평점이 Good이므로, Dicaprio에 대해 Positive
32.
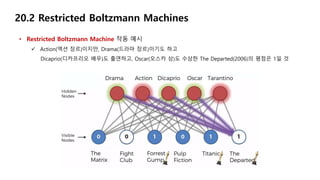
20.2 Restricted BoltzmannMachines
• Restricted Boltzmann Machine 작동 예시
Forest Gump(1994), Titanic(1997)은 Oscar(오스카 상) 수상
이 두 영화에 대한 평점은 Good이므로, Oscar에 대해 Positive
33.
20.2 Restricted BoltzmannMachines
• Restricted Boltzmann Machine 작동 예시
Pulp Fiction(1994)의 감독은 Tarantino(타란티노 감독)
이 영화에 대한 평점은 Bad이므로, Tarantino에 대해 Negative
34.
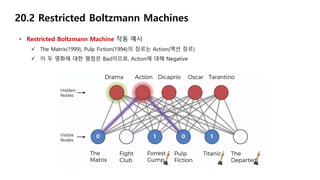
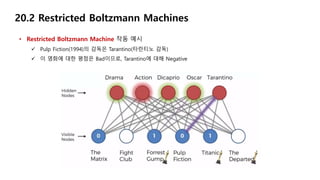
20.2 Restricted BoltzmannMachines
• Restricted Boltzmann Machine 작동 예시
Drama, Dicaprio, Oscar에 대해 Positive이고, Action, Tarantino에 대해 Negative
Action(액션 장르)인 Fight Club(1999)에 대한 평점은 0일 것
35.
20.2 Restricted BoltzmannMachines
• Restricted Boltzmann Machine 작동 예시
Action(액션 장르)이지만, Drama(드라마 장르)이기도 하고
Dicaprio(디카프리오 배우)도 출연하고, Oscar(오스카 상)도 수상한 The Departed(2006)의 평점은 1일 것
Partition function
이 되도록하는 함수
Energy function (에너지 함수)
Joint probability distribution (결합확률분포)
Weight matrix
Bias vector
𝑥를 𝑣, ℎ로 표현
visible nodes hidden nodes
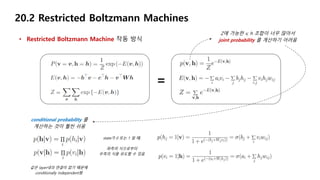
20.2 Restricted Boltzmann Machines
• Restricted Boltzmann Machine 작동 방식
<Boltzmann Machine> <Restricted Boltzmann Machine>
1. Joint probability distribution
2. Energy function
3. Partition function
38.
Z에 가능한 v,h 조합이 너무 많아서
joint probability 를 계산하기 어려움
20.2 Restricted Boltzmann Machines
• Restricted Boltzmann Machine 작동 방식
=
conditional probability 를
계산하는 것이 훨씬 쉬움
같은 layer내의 연결이 없기 때문에
conditionally independent함
state가 0 또는 1 일 때,
좌측의 식으로부터
우측의 식을 유도할 수 있음
39.
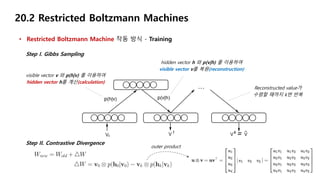
20.2 Restricted BoltzmannMachines
• Restricted Boltzmann Machine 작동 방식 - Training
Step I. Gibbs Sampling
visible vector v 와 p(h|v) 를 이용하여
hidden vector h를 계산(calculation)
hidden vector h 와 p(v|h) 를 이용하여
visible vector v를 복원(reconstruction)
Reconstructed value가
수렴할 때까지 k번 반복
Step II. Contrastive Divergence
outer product
40.
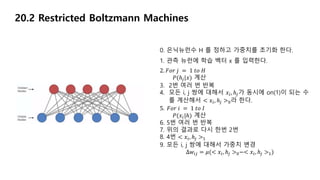
20.2 Restricted BoltzmannMachines
0. 은닉뉴런수 H 를 정하고 가중치를 초기화 한다.
1. 관측 뉴런에 학습 벡터 x 를 입력한다.
2. 𝐹𝑜𝑟 𝑗 = 1 𝑡𝑜 𝐻
𝑃(ℎ𝑗|𝑥) 계산
3. 2번 여러 번 반복
4. 모든 i, j 쌍에 대해서 𝑥𝑖, ℎ𝑗가 동시에 on(1)이 되는 수
를 계산해서 < 𝑥𝑖, ℎ𝑗 >0라 한다.
5. 𝐹𝑜𝑟 𝑖 = 1 𝑡𝑜 𝐼
𝑃(𝑥𝑖|ℎ) 계산
6. 5번 여러 번 반복
7. 위의 결과로 다시 한번 2번
8. 4번 < 𝑥𝑖, ℎ𝑗 >1
9. 모든 i, j 쌍에 대해서 가중치 변경
∆𝑤𝑖𝑗 = 𝜇(< 𝑥𝑖, ℎ𝑗 >0−< 𝑥𝑖, ℎ𝑗 >1)
41.
+ 추가 GibbsSampling
3개의 확률변수의 결합확률분포 p(x1,x2,x3)p(x1,x2,x3)로부터 1개의 표본을 얻으려고 할 때 깁스 샘플링의 절차는
다음과 같습니다.
(1) 임의의 표본 X0=(x01,x02,x03)을 선택한다.
(2) 모든 변수에 대해 변수 하나만을 변경하여 새로운 표본 X1을 뽑는다.
실제 사용시에는 처음 수집한 표본 X0은 버리고 X1만 쓰게 됩니다. (2)를 자세하게 쓰면 다음과 같습니다.
(ㄱ) 현재 주어진 표본 X0의 두번째, 세번째 변수 x02, x03를 고정시킨다.
(ㄴ) 첫번째 기존 변수 x01를 대체할 새로운 값 x11을 다음과 같은 확률로 뽑는다. p(x11|x02,x03)
(ㄷ) 첫번째 변수 x11, 세번째 변수 x03 를 고정시킨다.
(ㄹ) 두번째 기존 변수 x02를 대체할 새로운 값 x12을 다음과 같은 확률로 새로 뽑는다. p(x12|x11,x03)
(ㅁ) 첫번째 변수 x11, 두번째 변수 x12를 고정시킨다.
(ㅅ) 세번째 기존 변수 x03를 대체할 새로운 값 x13을 다음과 같은 확률로 새로 뽑는다. p(x13|x11,x12)
(ㅇ) 최종적으로 구한 X1은 다음과 같다. X1=(x11,x12,x13)
42.
+ 추가 ContrastiveDivergence
Contrastive Divergence 알고리즘을 한 마디로 요약하면:
p(v,h)p(v,h)를 계산하는 MCMC (Gibbs Sampling)의 step을 converge할 때 까지 돌리는 것이 아니라, 한
번만 돌려서 p(v,h)p(v,h)를 approximate하고, 그 값을 사용하여 ∑v,hp(v,h)vihj∑v,hp(v,h)vihj을 계산해
gradient의 approximation 값을 구한다.
어차피 정확하게 converge한 distribution이나, 중간에 멈춘 distribution이나 대략의 방향성은 공유할
것이다. 그렇기 때문에 완벽한 gradient 대신 Gibbs sampling을 중간에 멈추고 그 approximation 값을
update에 사용하자.
출처 : http://sanghyukchun.github.io/75/
43.
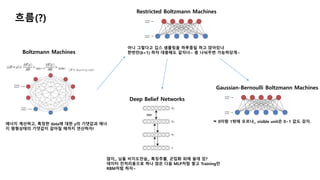
흐름(?)
Boltzmann Machines
에너지 계산하고,특정한 data에 대한 y의 기댓값과 에너
지 평형상태의 기댓값이 같아질 때까지 연산하자!
Restricted Boltzmann Machines
아니 그렇다고 깁스 샘플링을 하루종일 하고 앉아있냐
한번만(k=1) 하자 대충해도 같자너~ 층 나눠주면 가능하당게~
Gaussian-Bernoulli Boltzmann Machines
ㅋ 0이랑 1밖에 모르냐,, visible unit은 0~1 값도 갖자.
Deep Belief Networks
않이,, 님들 비지도잔슴,, 특징추출, 군집화 외에 쓸데 있?
데이터 전처리용으로 하나 얹은 다음 MLP처럼 쌓고 Training만
RBM처럼 하자~
44.
QnA
• AutoEncoder와 RBM차이?
- 오토인코더는 피처를 축소하는 심플한 개념이고, RBM은 확률분포에 기반하여 visible 변수들과 hidden 변수
들간에 어떤 상관관계가 있고 어떻게 상호작용하는지를 파악하는 개념. 오토인코더가 직관적일 뿐 아니라 구현
하기도 더 쉽고 파라메터가 더 적어서 튜닝하기가 쉽다. 대신 RBM은 generative 모델이기 때문에 오토인코더와
는 달리 찾아낸 확률분포로부터 새로운 데이터를 생성할 수 있다. 파라메터가 많은만큼 더욱 유연하다.
• Autoencoder와 RBM은 여전히 많이 쓰이는가?
- 그렇다. 다만 CNN과 RNN이 워낙 핫해서 묻히는것 뿐 (2015년 답변)
• RBM vs Autoencoder
- 성능은 그때그때 다름. 또한 두개를 같이 쓸 수도 있음
참고
- https://khanrc.tistory.com/entry/Autoencoder-vs-RBM-vs-CNN
- https://www.quora.com/Are-RBM-autoencoders-still-in-use-in-current-deep-learning-projects
















![20.2 Restricted Boltzmann Machines
• Restricted Boltzmann Machine 작동 예시
RBM이 학습이 완료된 상태에서, 새로운 사용자의 평점 데이터 [0, , 1, 0, 1, ]를 입력으로 넣으면
평점이 비어 있는 영화들에 대해서 어떤 결과를 보일까?](https://image.slidesharecdn.com/deepgenerativemodelsv4-190519132832/85/Chapter-20-Deep-generative-models-28-320.jpg)













![[DL輪読会]GENESIS: Generative Scene Inference and Sampling with Object-Centric L...](https://cdn.slidesharecdn.com/ss_thumbnails/20191206genesis-191206004127-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)










![ujava.org workshop : Deep Learning [2015-03-08]](https://cdn.slidesharecdn.com/ss_thumbnails/ujava-150316035315-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[한글] Tutorial: Sparse variational dropout](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialsparsevariationaldropout-190728122300-thumbnail.jpg?width=640&height=640&fit=bounds)

![[264] large scale deep-learning_on_spark](https://cdn.slidesharecdn.com/ss_thumbnails/246large-scaledeeplearningonspark-150915055051-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






















