Download as PDF, PPTX

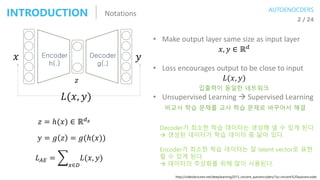
![Autoencoder in WikipediaFOUR KEYWORDS 1 / 5
[KEYWORDS]
Unsupervised learning
Representation learning
= Efficient coding learning
Dimensionality reduction
Generative model learning
INTRODUCTION](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-2-320.jpg)
![Nonlinear dimensionality reductionFOUR KEYWORDS 2 / 5
[KEYWORDS]
Unsupervised learning
Nonlinear Dimensionality reduction
= Representation learning
= Efficient coding learning
= Feature extraction
= Manifold learning
Generative model learning
INTRODUCTION](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-3-320.jpg)
![Representation learningFOUR KEYWORDS 3 / 5
[KEYWORDS]
Unsupervised learning
Nonlinear Dimensionality reduction
= Representation learning
= Efficient coding learning
= Feature extraction
= Manifold learning
Generative model learning
http://videolectures.net/kdd2014_bengio_deep_learning/
INTRODUCTION](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-4-320.jpg)
![ML density estimationFOUR KEYWORDS 4 / 5
[KEYWORDS]
Unsupervised learning
Nonlinear Dimensionality reduction
= Representation learning
= Efficient coding learning
= Feature extraction
= Manifold learning
Generative model learning
ML density estimationhttp://www.iangoodfellow.com/slides/2016-12-04-NIPS.pdf
INTRODUCTION](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-5-320.jpg)
![5 / 5
[4 MAIN KEYWORDS]
1. Unsupervised learning
2. Manifold learning
3. Generative model learning
4. ML density estimation
오토인코더를 학습할 때:
학습 방법은 비교사 학습 방법을 따르며,
Loss는 negative ML로 해석된다.
학습된 오토인코더에서:
인코더는 차원 축소 역할을 수행하며,
디코더는 생성 모델의 역할을 수행한다.
SummaryFOUR KEYWORDS INTRODUCTION
Unsupervised learning
ML density estimation
Manifold learning
Generative model learning
Encoder DecoderInput Output](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-6-320.jpg)




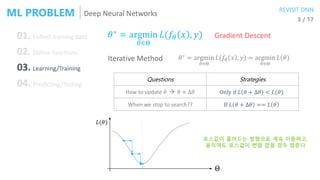


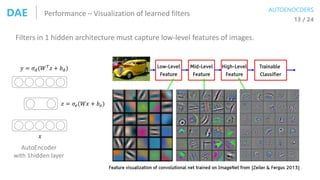
![Deep Neural Networks
6 / 17
01. Collect training data
02. Define functions
03. Learning/Training
04. Predicting/Testing
𝜃∗ = argmin
𝜃∈Θ
𝐿(𝑓𝜃 𝑥 , 𝑦) Gradient Descent + Backpropagation
DB LOSS
𝒟
DNN
𝐿(𝜃 𝑘, 𝒟)𝜃 𝑘 = 𝑤 𝑘, 𝑏 𝑘
𝜃 𝑘+1 = 𝜃 𝑘 − 𝜂𝛻𝐿 𝜃 𝑘, 𝒟
𝑤 𝑘+1
𝑙
= 𝑤 𝑘
𝑙
− 𝜂𝛻 𝑤 𝑘
𝑙 𝐿 𝜃 𝑘, 𝒟
𝑏 𝑘+1
𝑙
= 𝑏 𝑘
𝑙
− 𝜂𝛻𝑏 𝑘
𝑙 𝐿 𝜃 𝑘, 𝒟
특정 레이어에서
파라미터 갱신식
𝛿 𝐿 = 𝛻𝑎 𝐶⨀𝜎′ 𝑧 𝐿
• 𝐶 : Cost (Loss)
• 𝑎 : final output of DNN
• 𝜎(∙) : activation function
1. Error at the output layer
𝛿 𝑙
= 𝜎′
𝑧 𝑙
⨀ 𝑤 𝑙+1 𝑇
𝛿 𝑙+1
2. Error relationship between two adjacent layers
3. Gradient of C in terms of bias
4. Gradient of C in terms of weight
𝛻𝑏 𝑙 𝐶 = 𝛿 𝑙
𝛻 𝑊 𝑙 𝐶 = 𝛿 𝑙 𝑎 𝑙−1 𝑇
http://neuralnetworksanddeeplearning.com/chap2.html
ML PROBLEM
[ Backpropagation Algorithm ]
REVISIT DNN
로스함수의 미분값이 딥뉴럴넷 학습에서 제일 중요!!](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-14-320.jpg)




![View-Point II : Maximum Likelihood
11 / 17
01. Collect training data 입력
데이터
출력
정보
𝑥
모델
𝑦𝑥 = {𝑥1, 𝑥2, … , 𝑥 𝑁}
02. Define functions
𝑓𝜃 ∙
• Output : 𝑓𝜃 𝑥
• Loss : − log 𝑝(𝑦|𝑓𝜃 𝑥 ) 모델 종류
𝑝(𝑦|𝑓𝜃 𝑥 )
정해진 확률분포에서
출력이 나올 확률
03. Learning/Training
Find the optimal parameter
𝜃∗ = argmin
𝜃
[− log 𝑝(𝑦|𝑓𝜃 𝑥 ) ]
04. Predicting/Testing
Compute optimal function output
𝑦𝑛𝑒𝑤~𝑝(𝑦|𝑓𝜃∗ 𝑥 𝑛𝑒𝑤 )
주어진 데이터를 제일 잘
설명하는 모델 찾기
고정 입력, 고정/다른 출력
𝑦 = {𝑦1, 𝑦2, … , 𝑦 𝑁}
𝒟 = 𝑥1, 𝑦1 , 𝑥2, 𝑦2 … 𝑥 𝑁, 𝑦 𝑁
예측
Back to Machine Learning Problem
LOSS FUNCTION REVISIT DNN
𝑦
𝑓𝜃1
𝑥
𝑓𝜃2
𝑥
𝑝 𝑦 𝑓𝜃12 𝑥 < 𝑝 𝑦 𝑓𝜃1
𝑥](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-19-320.jpg)















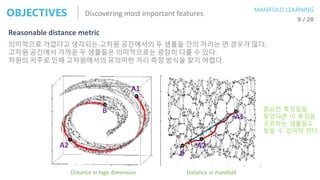


































![Latent Variable ModelGENERATIVE MODEL VAE
2 / 49
𝑧 𝑥Generator
gθ(.)
Latent Variable Target Data
Latent variable can be seen as a set of control
parameters for target data (generated data)
For MNIST example, our model can be trained to
generate image which match a digit value z randomly
sampled from the set [0, ..., 9].
그래서, p(z)는 샘플링 하기 용이해야 편하다.
𝑧~𝑝(𝑧)
𝑥 = 𝑔 𝜃(𝑧)
Random variable
Random variable
𝑔 𝜃(∙) Deterministic function
parameterized by θ
𝑝 𝑥 𝑔 𝜃(𝑧) = 𝑝 𝜃 𝑥 𝑧
We are aiming maximize the probability of each x in the training set,
under the entire generative process, according to:
න 𝑝 𝑥 𝑔 𝜃 𝑧 𝑝(𝑧)𝑑𝑧 = 𝑝(𝑥)](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-74-320.jpg)


![ELBO : Evidence LowerBOundVARIATIONAL INFERENCE 5 / 49
VAE
앞 슬라이드에서 Solution2가 가능하게 하는 방법 중 하나는 z를 정규분포에서 샘플링하는 것보다 x와
유의미하게 유사한 샘플이 나올 수 있는 확률분포 𝑝(𝑧|𝑥)로 부터 샘플링하면 된다. 그러나 𝑝(𝑧|𝑥) 가 무엇인지
알지 못하므로, 우리가 알고 있는 확률분포 중 하나를 택해서 (𝑞 𝜙(𝑧|𝑥)) 그것의 파라미터값을 (𝜆) 조정하여
𝑝(𝑧|𝑥) 와 유사하게 만들어 본다. (Variational Inference)
https://www.slideshare.net/haezoom/variational-autoencoder-understanding-variational-autoencoder-from-various-perspectives
http://shakirm.com/papers/VITutorial.pdf
𝑝 𝑧|𝑥 ≈ 𝑞 𝜙 𝑧|𝑥 ~𝑧 𝑥Generator
gθ(.)
Latent Variable Target Data
One possible solution : sampling 𝑧 from 𝑝(𝑧|𝑥)
[ Variational Inference ]](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-77-320.jpg)
![ELBO : Evidence LowerBOundVARIATIONAL INFERENCE 6 / 49
VAE
[ Jensen’s Inequality ]
For concave functions f(.)
f(E[x])≥E[f(x)]log 𝑝 𝑥 = log න 𝑝 𝑥|𝑧 𝑝(𝑧)𝑑𝑧 ≥ න log 𝑝 𝑥|𝑧 𝑝(𝑧)𝑑𝑧
f(.) = log(.) is concave
log 𝑝 𝑥 = log න 𝑝 𝑥|𝑧
𝑝(𝑧)
𝑞 𝜙(𝑧|𝑥)
𝑞 𝜙(𝑧|𝑥)𝑑𝑧 ≥ න log 𝑝 𝑥|𝑧
𝑝(𝑧)
𝑞 𝜙(𝑧|𝑥)
𝑞 𝜙(𝑧|𝑥)𝑑𝑧
log 𝑝 𝑥 ≥ න log 𝑝 𝑥|𝑧 𝑞 𝜙(𝑧|𝑥)𝑑𝑧 − න log
𝑞 𝜙(𝑧|𝑥)
𝑝 𝑧
𝑞 𝜙(𝑧|𝑥)𝑑𝑧
Variational lower bound
Evidence lower bound (ELBO)
= 𝔼 𝑞 𝜙 𝑧|𝑥 log 𝑝 𝑥|𝑧 − 𝐾𝐿 𝑞 𝜙 𝑧|𝑥 |𝑝 𝑧
Relationship among 𝑝 𝑥 , 𝑝 𝑧 𝑥 , 𝑞 𝜙 𝑧|𝑥 : Derivation 1
←
←Variational inference
𝐸𝐿𝐵𝑂( 𝜙)
ELBO를 최대화하는 𝜙∗
값을 찾으면 log 𝑝 𝑥 = 𝔼 𝑞 𝜙∗ 𝑧|𝑥 log 𝑝 𝑥|𝑧 − 𝐾𝐿 𝑞 𝜙∗ 𝑧|𝑥 |𝑝 𝑧 이다.](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-78-320.jpg)





![RegularizationLOSS FUNCTION 12 / 49
𝑞 𝜙 𝑧|𝑥𝑖 ~𝑁(𝜇𝑖, 𝜎𝑖
2
𝐼)
Assumption 1
[Encoder : approximation class]
multivariate gaussian distribution with a diagonal covariance
𝑝(𝑧) ~𝑁(0, 𝐼)
Assumption 2
[prior] multivariate normal distribution
VAE
𝐿𝑖 𝜙, 𝜃, 𝑥𝑖 = −𝔼 𝑞 𝜙 𝑧|𝑥 𝑖
log 𝑥𝑖|𝑔 𝜃(𝑧) + 𝐾𝐿 𝑞 𝜙 𝑧|𝑥𝑖 |𝑝 𝑧
Regularization
Assumptions
𝑥𝑖 𝑞 𝜙 𝑧|𝑥𝑖
𝜇𝑖
𝜎𝑖](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-84-320.jpg)



![Reconstruction errorLOSS FUNCTION 16 / 49
VAE
Assumption
Reconstruction Error
𝔼 𝑞 𝜙 𝑧|𝑥 𝑖
log 𝑝 𝜃 𝑥𝑖|𝑧 = න log 𝑝 𝜃 𝑥𝑖|𝑧 𝑞 𝜙 𝑧|𝑥𝑖 𝑑𝑧 ≈
1
𝐿
𝑧 𝑖,𝑙
log 𝑝 𝜃 𝑥𝑖|𝑧 𝑖,𝑙
≈ log 𝑝 𝜃 𝑥𝑖|𝑧 𝑖
Monte-carlo
technique
L=1
𝑝𝑖𝑔 𝜃(∙)𝑧 𝑖
Assumption 3-1
[Decoder, likelihood]
multivariate bernoulli or gaussain distribution
log 𝑝 𝜃 𝑥𝑖|𝑧 𝑖 = log ෑ
𝑗=1
𝐷
𝑝 𝜃 𝑥𝑖,𝑗|𝑧 𝑖 =
𝑗=1
𝐷
log 𝑝 𝜃 𝑥𝑖,𝑗|𝑧 𝑖
𝐷
=
𝑗=1
𝐷
log 𝑝𝑖,𝑗
𝑥 𝑖,𝑗
1 − 𝑝𝑖,𝑗
1−𝑥 𝑖,𝑗
← 𝑝𝑖,𝑗 ≗ 𝑛𝑒𝑡𝑤𝑜𝑟𝑘 𝑜𝑢𝑡𝑝𝑢𝑡
=
𝑗=1
𝐷
𝑥𝑖,𝑗 log 𝑝𝑖,𝑗 + (1 − 𝑥𝑖,𝑗) log 1 − 𝑝𝑖,𝑗 ← Cross entropy
𝑝 𝜃 𝑥𝑖|𝑧 𝑖
~𝐵𝑒𝑟𝑛𝑜𝑢𝑙𝑙𝑖(𝑝𝑖)
𝐿𝑖 𝜙, 𝜃, 𝑥𝑖 = −𝔼 𝑞 𝜙 𝑧|𝑥 𝑖
log 𝑥𝑖|𝑔 𝜃(𝑧) + 𝐾𝐿 𝑞 𝜙 𝑧|𝑥𝑖 |𝑝 𝑧](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-88-320.jpg)
![Reconstruction errorLOSS FUNCTION 17 / 49
VAE
Assumption
Reconstruction Error
𝔼 𝑞 𝜙 𝑧|𝑥 𝑖
log 𝑝 𝜃 𝑥𝑖|𝑧 ≈ log 𝑝 𝜃 𝑥𝑖|𝑧 𝑖
𝜎𝑖
𝑔 𝜃(∙)𝑧 𝑖
Assumption 3-2
[Decoder, likelihood]
multivariate bernoulli or gaussain distribution
𝐷
← Squared Error
𝜇𝑖
𝐷
log 𝑝 𝜃 𝑥𝑖|𝑧 𝑖 = log 𝑁(𝑥𝑖; 𝜇𝑖, 𝜎𝑖
2
𝐼)
= −
𝑗=1
𝐷 1
2
log 𝜎𝑖,𝑗
2
+
𝑥𝑖,𝑗 − 𝜇𝑖,𝑗
2
2𝜎𝑖,𝑗
2
For gaussain distribution with identity covariance
log 𝑝 𝜃 𝑥𝑖|𝑧 𝑖 ∝ −
𝑗=1
𝐷
𝑥𝑖,𝑗 − 𝜇𝑖,𝑗
2
𝐿𝑖 𝜙, 𝜃, 𝑥𝑖 = −𝔼 𝑞 𝜙 𝑧|𝑥 𝑖
log 𝑥𝑖|𝑔 𝜃(𝑧) + 𝐾𝐿 𝑞 𝜙 𝑧|𝑥𝑖 |𝑝 𝑧](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-89-320.jpg)











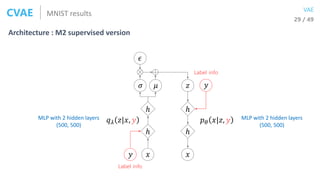


![32 / 49
VAE
Handwriting styles obtained by fixing the class label and varying z |z| = 2
y=[1,0,0,0,0,0,0,0,0,0] y=[0,1,0,0,0,0,0,0,0,0] y=[0,0,1,0,0,0,0,0,0,0] y=[0,0,0,1,0,0,0,0,0,0] y=[0,0,0,0,1,0,0,0,0,0]
y=[0,0,0,0,0,0,1,0,0,0]y=[0,0,0,0,0,1,0,0,0,0] y=[0,0,0,0,0,0,0,0,1,0]y=[0,0,0,0,0,0,0,1,0,0] y=[0,0,0,0,0,0,0,0,0,1]
MNIST resultsCVAE
https://github.com/hwalsuklee/tensorflow-mnist-CVAE](https://image.slidesharecdn.com/aes171113-180510014736/85/slide-104-320.jpg)










































The document discusses autoencoders as a method for unsupervised learning, focusing on their role in nonlinear dimensionality reduction, representation learning, and generative model learning. It covers various autoencoder types including denoising and variational autoencoders, and provides insights into training methods and loss functions, particularly emphasizing the maximum likelihood perspective. It also touches upon applications of autoencoders such as retrieval, generation, and regression.
















![[DL輪読会]Encoder-Decoder with Atrous Separable Convolution for Semantic Image S...](https://cdn.slidesharecdn.com/ss_thumbnails/deeplabv3-180309001425-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)











![[PR12] understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/pr12understandingdeeplearningrequiresrethinkinggeneralization-180121135850-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Pycon 2015] 오늘 당장 딥러닝 실험하기 제출용](https://cdn.slidesharecdn.com/ss_thumbnails/pycon2015-150913033231-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2A4]DeepLearningAtNAVER](https://cdn.slidesharecdn.com/ss_thumbnails/2a4deeplearningatnaver-140929210707-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







































