Variational이라는 단어로는 아무것도 안떠오릅니다.
그래서, '꿩 대신 닭'이라고 표현해 봤습니다.
초반 독자적인 그림을 통해 개념잡기가 쉬워요.
설명부분은 초록색으로 표시했습니다.
확률변수(random variable)부터 막히면, 아래 블로그 글을 읽어 보세요.
https://blog.naver.com/nonezerok/221428251262
17
𝑝(𝑧|𝑥) 𝑞(𝑧|𝑥)
이런 모양인지조차도 모르는 분포
모양은 이런데,
좌우 위치와 홀쭉인지 뚱뚱인지 아직 정해지지 않은 분포
이 둘의 차이는 어떻게 계산하나?
𝜇 𝜎
이 둘을 조정해서 왼쪽 분포와
그나마 유사하게 만들어 줄 수 있다.
KL divergence 라는 식이 있다.
(두 분포의 차이를 계산하는 식)
이 식은 엔트로피 항으로 이루어 진다.
엔트로피는 정보량의 평균이다.
정보량은 뉴스(확률사건)의 가치를 계산하는 식
KL divergence 식을 손실함수로 사용하면 된다!
KL-divergence
23
두 확률 분포의어떤 차이
두 분포의 차이를 어떤 식으로 계산하면 좋을까?
credit: https://wiseodd.github.io/techblog/2016/12/21/forward-reverse-kl/
24.
Variational Inference
𝑝 𝑧|𝑥
𝑞𝑧|𝑥
구하기 어렵다.
꿩 대신 닭
변이
우리가 알고 있는 쉬운 분포; 정규분포로 대치하자.
𝑝 𝑧|𝑥 ≈ 𝑞 𝑧|𝑥
조건:
KL 최소화
min KL 𝑞 𝑧|𝑥 ||𝑝 𝑧|𝑥
24
Posterior 구하기
대체(변이) 사후확률 구함
𝑞 𝑧|𝑥
Reverse KL을 선호
VI : biased, low variance
MC: unbiased, high variance
28
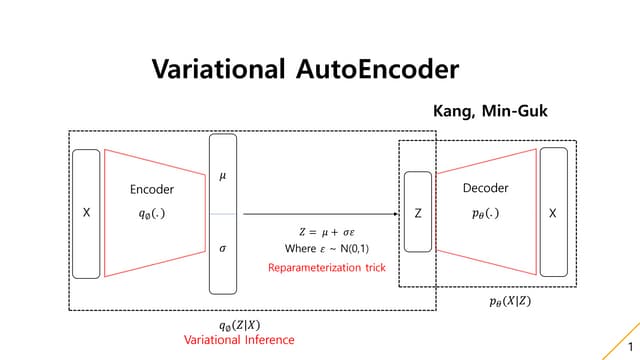
Z
X
𝑝(𝑥|𝑧) 𝑞(𝑧|𝑥)
𝑞 ∶𝑥 → 𝑧
𝑝 ∶ 𝑧 → 𝑥
𝑞(𝑧|𝑥)
𝑥
𝑧
𝑝(𝑥|𝑧) ො
𝑥
−𝐸𝑞 𝑧|𝑥 𝑙𝑜𝑔 𝑝 𝑥|𝑧 + 𝐾𝐿 𝑞 𝑧|𝑥 ||𝑝 𝑧
deterministic
function
= neural network
을 도입
그냥 신경망;
일반적인 복원 에러를 로스로 사용
Cross Entropy Loss
Loss for a given 𝑥:
≈ 𝑝(𝑧|𝑥)
추가 학습
59
hidden codelearns
to represent the style of the image
• Conditional VAE
• 𝛽 −VAE
• Adversarial Autoencoder
• VQ-VAE
https://arxiv.org/pdf/1511.05644.pdf

















![선수지식
𝑝 𝑥, 𝑦 = 𝑝 𝑥 𝑝 𝑦|𝑥 = 𝑝 𝑦 𝑝(𝑥|𝑦)
𝑝 𝑥 =
𝑦
𝑝 𝑥, 𝑦
𝐸 𝑋 =
𝑥
𝑝 𝑥 𝑥 𝐸 𝑓 𝑋 =
𝑥
𝑝 𝑥 𝑓 𝑥
18
𝐸𝑝(𝑥)[𝑋]
joint pdf, marginal pdf, conditional pdf
random variable, 𝑋
𝑝 𝑋 = 𝑥 , 𝑝𝑋 𝑥 , 𝑝(𝑥)](https://image.slidesharecdn.com/20200712notevae20221018-slideshare-230111040459-a48847c2/85/Variational-Autoencoder-VAE-18-320.jpg)















































![[DL輪読会]Reinforcement Learning with Deep Energy-Based Policies](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170406-170407002545-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Non-Autoregressive Machine Translation with Latent Alignments](https://cdn.slidesharecdn.com/ss_thumbnails/20200522matsudatefinal-200529045007-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Ridge-i 論文よみかい] Wasserstein auto encoder](https://cdn.slidesharecdn.com/ss_thumbnails/wassersteinauto-encoder-181006055019-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[한글] Tutorial: Sparse variational dropout](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialsparsevariationaldropout-190728122300-thumbnail.jpg?width=640&height=640&fit=bounds)











![[PRML 3.1~3.2] Linear Regression / Bias-Variance Decomposition](https://cdn.slidesharecdn.com/ss_thumbnails/bayesianlinearregressionpart1-170117134816-thumbnail.jpg?width=640&height=640&fit=bounds)



![[확률통계]04모수추정](https://cdn.slidesharecdn.com/ss_thumbnails/statistics4-190131081748-thumbnail.jpg?width=640&height=640&fit=bounds)



![[신경망기초] 신경망학습](https://cdn.slidesharecdn.com/ss_thumbnails/3-180604140208-thumbnail.jpg?width=640&height=640&fit=bounds)
![[신경망기초]오류역전파알고리즘구현](https://cdn.slidesharecdn.com/ss_thumbnails/nn-190319093725-thumbnail.jpg?width=640&height=640&fit=bounds)










