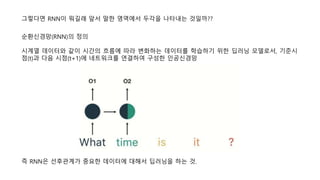
그렇다면 RNN이 뭐길래앞서 말한 영역에서 두각을 나타내는 것일까??
즉 RNN은 선후관계가 중요한 데이터에 대해서 딥러닝을 하는 것.
순환신경망(RNN)의 정의
시계열 데이터와 같이 시간의 흐름에 따라 변화하는 데이터를 학습하기 위한 딥러닝 모델로서, 기준시
점(t)과 다음 시점(t+1)에 네트워크를 연결하여 구성한 인공신경망
5.
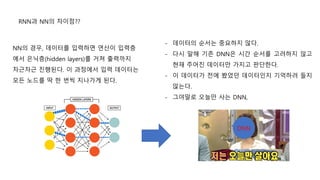
- 데이터의 순서는중요하지 않다.
- 다시 말해 기존 DNN은 시간 순서를 고려하지 않고
현재 주어진 데이터만 가지고 판단한다.
- 이 데이터가 전에 봤었던 데이터인지 기억하려 들지
않는다.
- 그야말로 오늘만 사는 DNN,
NN의 경우, 데이터를 입력하면 연산이 입력층
에서 은닉층(hidden layers)를 거쳐 출력까지
차근차근 진행된다. 이 과정에서 입력 데이터는
모든 노드를 딱 한 번씩 지나가게 된다.
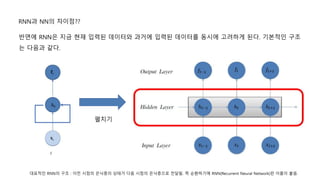
RNN과 NN의 차이점??
DNN
6.
펼치기
RNN과 NN의 차이점??
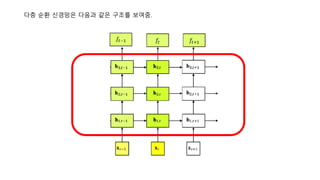
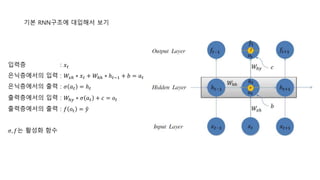
대표적인RNN의 구조 : 이전 시점의 은닉층의 상태가 다음 시점의 은닉층으로 전달됨. 즉 순환하기에 RNN(Recurrent Neural Network)란 이름이 붙음.
반면에 RNN은 지금 현재 입력된 데이터와 과거에 입력된 데이터를 동시에 고려하게 된다. 기본적인 구조
는 다음과 같다.
RNN의 기본적인 계산
입력층: 𝑥 𝑡
은닉층에서의 입력 : 𝑊𝑥ℎ ∗ 𝑥 𝑡 + 𝑊ℎℎ ∗ ℎ 𝑡−1 + 𝑏 = 𝑎 𝑡
은닉층에서의 출력 : 𝜎 𝑎 𝑡 = ℎ 𝑡
출력층에서의 입력 : 𝑊ℎ𝑦 ∗ 𝜎 𝑎 𝑡 + 𝑐 = 𝑜 𝑡
출력층에서의 출력 : 𝑓(𝑜 𝑡)
𝜎, 𝑓는 활성화 함수
10.
기본 RNN구조에 대입해서보기
입력층 : 𝑥 𝑡
은닉층에서의 입력 : 𝑊𝑥ℎ ∗ 𝑥 𝑡 + 𝑊ℎℎ ∗ ℎ 𝑡−1 + 𝑏 = 𝑎 𝑡
은닉층에서의 출력 : 𝜎 𝑎 𝑡 = ℎ 𝑡
출력층에서의 입력 : 𝑊ℎ𝑦 ∗ 𝜎 𝑎 𝑡 + 𝑐 = 𝑜𝑡
출력층에서의 출력 : 𝑓 𝑜𝑡 = 𝑦
𝜎, 𝑓는 활성화 함수
11.
한글자 씩 입력해서Hello라는 단어를 예측하는 예시
처음에 h[1,0,0,0]이라는 입력으로
e[0,1,0,0]이라는 출력을 예측하는
방향으로 학습이 진행됨.
그 다음 l[0,0,1,0]과 o[0,0,0,1]에 대해서
도 마찬가지로 학습이 진행됨.
12.
이러한 RNN은 특징이한가지가 있는데, 매개변수를 공유한다는 것.
즉 입력값으로 𝑥 𝑡−1을 넣든, 𝑥 𝑡+4를 넣든 가중치행렬 𝑊𝑥ℎ는 같은 것을 사용한다.
마찬가지로 ℎ 𝑡에서 ℎ 𝑡+1로 넘어갈 때나, ℎ 𝑡+17에서 ℎ 𝑡+18로 넘어갈 때, 똑같은 𝑊ℎℎ를 사용한다.
이는 다른 매개변수에도 마찬가지이다.
이러한 특징으로 인해 학습의 속도는 빠르게 증가하지만, 손실을 최소로 하는
매개변수를 발견하는 과정에 있어서는 최적화가 다소 어려울 수 있다는 점이 있다.
RNN의 특징
13.
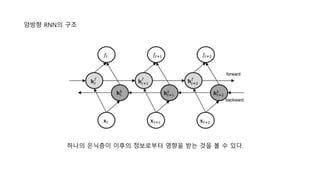
양방향 RNN
이전의 정보들을활용하는 RNN자체로도 좋은 성능을 기대할 수 있지만, 이후의 정보를 사용하여
더 좋은 결과를 기대할 수 있다.
Ex) ‘푸른 하늘에 _____ 이 떠있다’ 라는 문장에서 가운데 빈칸에 들어갈 단어를 예측할 때,
‘푸른’, ‘하늘’ 이라는 정보로 구름을 예측할 수도 있지만, 이후의 정보인 ‘떠있다’를 통해서 보다
정확하게 구름이라는 단어를 예측할 수 있다.
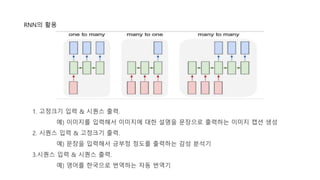
RNN의 활용
1. 고정크기입력 & 시퀀스 출력.
예) 이미지를 입력해서 이미지에 대한 설명을 문장으로 출력하는 이미지 캡션 생성
2. 시퀀스 입력 & 고정크기 출력.
예) 문장을 입력해서 긍부정 정도를 출력하는 감성 분석기
3.시퀀스 입력 & 시퀀스 출력.
예) 영어를 한국으로 번역하는 자동 번역기
16.
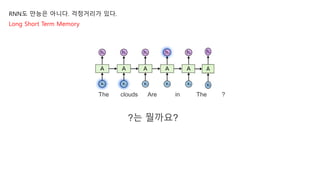
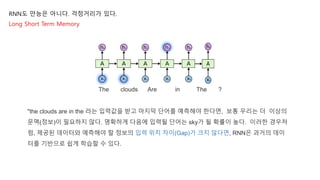
RNN도 만능은 아니다.걱정거리가 있다.
Long Short Term Memory
The clouds Are in The ?
?는 뭘까요?
17.
RNN도 만능은 아니다.걱정거리가 있다.
Long Short Term Memory
"the clouds are in the 라는 입력값을 받고 마지막 단어를 예측해야 한다면, 보통 우리는 더 이상의
문맥(정보)이 필요하지 않다. 명확하게 다음에 입력될 단어는 sky가 될 확률이 높다. 이러한 경우처
럼, 제공된 데이터와 예측해야 할 정보의 입력 위치 차이(Gap)가 크지 않다면, RNN은 과거의 데이
터를 기반으로 쉽게 학습할 수 있다.
The clouds Are in The ?
18.
RNN도 만능은 아니다.걱정거리가 있다.
Long Short Term Memory
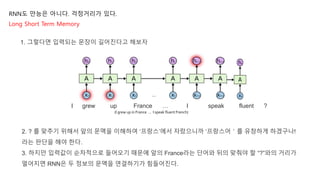
2. ? 를 맞추기 위해서 앞의 문맥을 이해하여 ‘프랑스’에서 자랐으니까 ‘프랑스어'를 유창하게 하겠구나!
라는 판단을 해야 한다.
3. 하지만 입력값이 순차적으로 들어오기 때문에 앞의 France라는 단어와 뒤의 맞춰야 할 “?”와의 거리가
멀어지면 RNN은 두 정보의 문맥을 연결하기가 힘들어진다.
grew up France … I speak fluent ?
(I grew up in France ... I speak fluent French)
1. 그렇다면 입력되는 문장이 길어진다고 해보자
I
19.
RNN도 만능은 아니다.걱정거리가 있다.
Long Short Term Memory
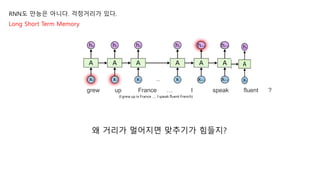
grew up France … I speak fluent ?
(I grew up in France ... I speak fluent French)
왜 거리가 멀어지면 맞추기가 힘들지?
20.
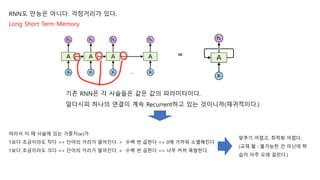
RNN도 만능은 아니다.걱정거리가 있다.
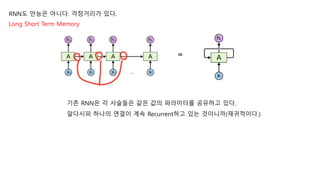
기존 RNN은 각 사슬들은 같은 값의 파라미터를 공유하고 있다.
알다시피 하나의 연결이 계속 Recurrent하고 있는 것이니까(재귀적이다.)
Long Short Term Memory
21.
RNN도 만능은 아니다.걱정거리가 있다.
Long Short Term Memory
따라서 이 때 사슬에 있는 가중치(𝑤)가
1보다 조금이라도 작다 => 단어의 거리가 멀어진다. = 수백 번 곱한다 => 0에 가까워 소멸해진다
1보다 조금이라도 크다 => 단어의 거리가 멀어진다. = 수백 번 곱한다 => 너무 커져 폭발한다.
맞추기 어렵고, 최적화 어렵다.
(교재 왈 : 불가능한 건 아닌데 학
습이 아주 오래 걸린다.)
기존 RNN은 각 사슬들은 같은 값의 파라미터이다.
알다시피 하나의 연결이 계속 Recurrent하고 있는 것이니까(재귀적이다.)
22.
RNN도 만능은 아니다.걱정거리가 있다.
Long Short Term Memory
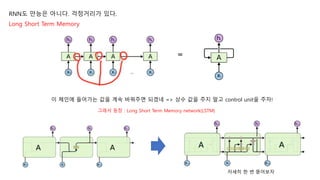
이 체인에 들어가는 값을 계속 바꿔주면 되겠네 => 상수 값을 주지 말고 control unit을 주자!
그래서 등장 : Long Short Term Memory network(LSTM)
자세히 한 번 뜯어보자
23.
RNN도 만능은 아니다.걱정거리가 있다.
Long Short Term Memory network
정확히 말하면 LSTM말고도 다른 방법으로 해결할 수도 있기는 합니다.
10.8 반향 반대 신경망
10.9 누출 단위 및 여러 다중 시간 축적 전략
But 저자가 10.10의 LSTM을 이야기하면서
“이 책을 쓰는 현재, 실제 응용에 쓰이는 가장 효과적인 순차열 모형은 LSTM이다. “ 라고 밝혔습니다.
따라서 10.8과 10.9를 생략하고 10.10의 LSTM으로 넘어가는 것을 밝힙니다.
24.
Long Short TermMemory
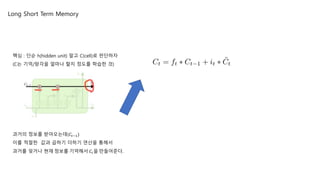
핵심 : 단순 h(hidden unit) 말고 C(cell)로 판단하자
(C는 기억/망각을 얼마나 할지 정도를 학습한 것)
25.
Long Short TermMemory
과거의 정보를 받아오는데(𝐶𝑡−1)
이를 적절한 값과 곱하기 더하기 연산을 통해서
과거를 잊거나 현재 정보를 기억해서 𝐶𝑡을 만들어준다.
핵심 : 단순 h(hidden unit) 말고 C(cell)로 판단하자
(C는 기억/망각을 얼마나 할지 정도를 학습한 것)
26.
Long Short TermMemory
핵심 : 단순 h(hidden unit) 말고 C(cell)로 판단하자
(C는 기억/망각 정도를 학습한 것)
과거의 정보를 받아오는데(𝐶𝑡−1)
이를 적절한 값과 곱하기 더하기 연산을 통해서
과거를 잊거나 현재 정보를 기억해서 𝐶𝑡을 만들어준다.
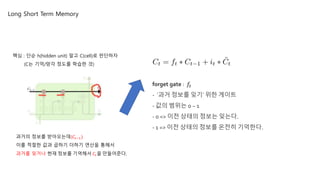
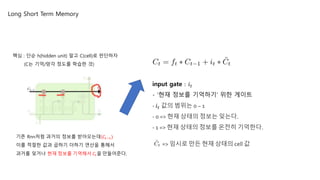
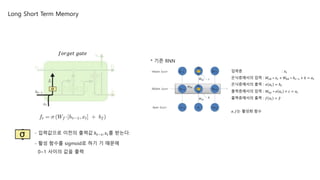
forget gate : 𝑓𝑡
- ‘과거 정보를 잊기’ 위한 게이트
- 값의 범위는 0 ~ 1
- 0 => 이전 상태의 정보는 잊는다.
- 1 => 이전 상태의 정보를 온전히 기억한다.
27.
Long Short TermMemory
핵심 : 단순 h(hidden unit) 말고 C(cell)로 판단하자
(C는 기억/망각 정도를 학습한 것)
기존 Rnn처럼 과거의 정보를 받아오는데(𝐶𝑡−1)
이를 적절한 값과 곱하기 더하기 연산을 통해서
과거를 잊거나 현재 정보를 기억해서 𝐶𝑡을 만들어준다.
input gate : 𝑖 𝑡
- ‘현재 정보를 기억하기’ 위한 게이트
- 𝑖 𝑡 값의 범위는 0 ~ 1
- 0 => 현재 상태의 정보는 잊는다.
- 1 => 현재 상태의 정보를 온전히 기억한다.
=> 임시로 만든 현재 상태의 cell 값
28.
Long Short TermMemory
- 활성 함수를 sigmoid로 하기 기 때문에
0~1 사이의 값을 출력
𝑓𝑜𝑟𝑔𝑒𝑡 𝑔𝑎𝑡𝑒
* 기존 RNN
- 입력값으로 이전의 출력값 ℎ 𝑡−1, 𝑥𝑡를 받는다.
입력층 : 𝑥𝑡
은닉층에서의 입력 : 𝑊𝑥ℎ ∗ 𝑥𝑡 + 𝑊ℎℎ ∗ ℎ 𝑡−1 + 𝑏 = 𝑎 𝑡
은닉층에서의 출력 : 𝜎 𝑎 𝑡 = ℎ 𝑡
출력층에서의 입력 : 𝑊ℎ𝑦 ∗ 𝜎 𝑎 𝑡 + 𝑐 = 𝑜𝑡
출력층에서의 출력 : 𝑓 𝑜𝑡 = 𝑦
𝜎, 𝑓는 활성화 함수
29.
Long Short TermMemory
i𝑛𝑝𝑢𝑡 𝑔𝑎𝑡𝑒
(임시로 만든 현재 상태의 cell 값)
왜 서만 tanh를 쓰냐?
1. Gate들은 업데이트를 위한 것이라 0~1사이 값을
출력해야 해서 시그모이드
2. tanh가 좋다고 합니다.
30.
Long Short TermMemory
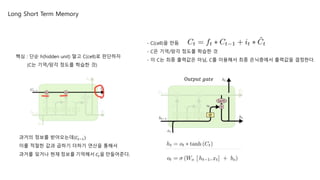
O𝑢𝑡𝑝𝑢𝑡 𝑔𝑎𝑡𝑒
- C(cell)을 만듬
- C은 기억/망각 정도를 학습한 것
- 이 C는 최종 출력값은 아님, C를 이용해서 최종 은닉층에서 출력값을 결정한다.
핵심 : 단순 h(hidden unit) 말고 C(cell)로 판단하자
(C는 기억/망각 정도를 학습한 것)
과거의 정보를 받아오는데(𝐶𝑡−1)
이를 적절한 값과 곱하기 더하기 연산을 통해서
과거를 잊거나 현재 정보를 기억해서 𝐶𝑡을 만들어준다.
31.
지금까지 LSTM은 굉장히평범한 LSTM
모든 LSTM이 위와 동일한 구조는 x (그래도…비슷비슷하기는 해요)
Long Short Term Memory
정리
32.
지금까지 LSTM은 굉장히평범한 LSTM
모든 LSTM이 위와 동일한 구조는 x (그래도…비슷비슷하기는 해요)
Long Short Term Memory
33.
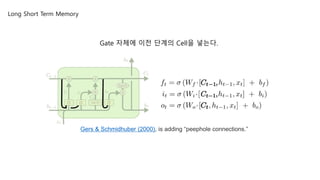
Gate 자체에 이전단계의 Cell을 넣는다.
Long Short Term Memory
Gers & Schmidhuber (2000), is adding “peephole connections.”
34.
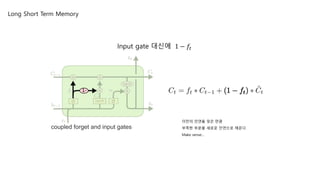
Input gate 대신에1 − 𝑓𝑡
이전의 인연을 잊은 만큼
부족한 부분을 새로운 인연으로 채운다.
Make sense…
Long Short Term Memory
coupled forget and input gates
35.
Long Short TermMemory
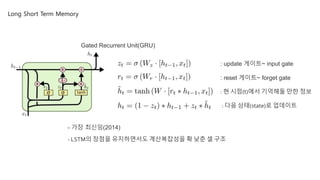
Gated Recurrent Unit(GRU)
- 가장 최신임(2014)
- LSTM의 장점을 유지하면서도 계산복잡성을 확 낮춘 셀 구조
: update 게이트~ input gate
: reset 게이트~ forget gate
: 현 시점(t)에서 기억해둘 만한 정보
: 다음 상태(state)로 업데이트
36.
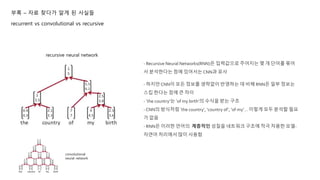
부록 – 자료찾다가 알게 된 사실들
recurrent vs convolutional vs recursive
recurrent neural network
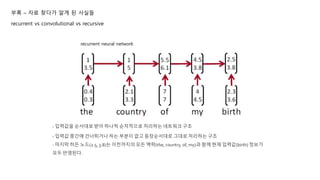
- 입력값을 순서대로 받아 하나씩 순차적으로 처리하는 네트워크 구조
- 입력값 중간에 건너뛰거나 하는 부분이 없고 등장순서대로 그대로 처리하는 구조
- 마지막 히든 노드(2.5, 3.8)는 이전까지의 모든 맥락(the, country, of, my)과 함께 현재 입력값(birth) 정보가
모두 반영된다.
37.
부록 – 자료찾다가 알게 된 사실들
recurrent vs convolutional vs recursive
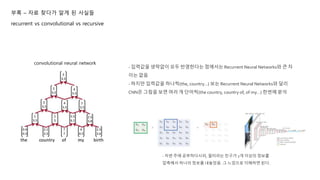
convolutional neural network
- 입력값을 생략없이 모두 반영한다는 점에서는 Recurrent Neural Networks와 큰 차
이는 없음
- 하지만 입력값을 하나씩(the, country…) 보는 Recurrent Neural Networks와 달리
CNN은 그림을 보면 여러 개 단어씩(the country, country of, of my…) 한번에 분석
- 저번 주에 공부하다시피, 필터라는 친구가 2개 이상의 정보를
압축해서 하나의 정보를 내놓았음. 그 느낌으로 이해하면 된다.
38.
부록 – 자료찾다가 알게 된 사실들
recurrent vs convolutional vs recursive
recursive neural network
- 하지만 CNN이 모든 정보를 생략없이 반영하는 데 비해 RNN은 일부 정보는
스킵 한다는 점에 큰 차이
- ‘the country’는 ‘of my birth’의 수식을 받는 구조
- CNN의 방식처럼 ‘the country’, ‘country of’, ‘of my’… 이렇게 모두 분석할 필요
가 없음
- RNN은 이러한 언어의 계층적인 성질을 네트워크 구조에 적극 차용한 모델-
자연어 처리에서 많이 사용함
- Recursive Neural Networks(RNN)은 입력값으로 주어지는 몇 개 단어를 묶어
서 분석한다는 점에 있어서는CNN과 유사
convolutional
neural network
39.
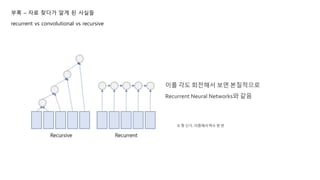
부록 – 자료찾다가 알게 된 사실들
recurrent vs convolutional vs recursive
- 사실 Recurrent Neural Networks는 Recursive Neural
Networks의 특수 케이스
- 만약 Recursive Neural Networks가 모든 정보를 순서대로
빠짐없이 반영한다고 하면 왼쪽 그림 같은 구조
40.
이를 각도 회전해서보면 본질적으로
Recurrent Neural Networks와 같음
부록 – 자료 찾다가 알게 된 사실들
recurrent vs convolutional vs recursive
오 짱 신기..이쯤에서 박수 한 번
41.
부록 – 자료찾다가 알게 된 사실들
convolutional + recursive
기존 cnn -> 사진이 들어오면 => 요것이 무엇인가? 분류
42.
부록 – 자료찾다가 알게 된 사실들
convolutional + recursive
시계열 데이터 인식은 한 개의 데이터에 label하는 게 아니라 연속적인 label 예측이 필요
일반적인 데이터 인식과 다르게 시계열 이미지 데이터를 인식하고 싶다.
CNN + RNN 을 하자! => CRNN
43.
부록 – 자료찾다가 알게 된 사실들
convolutional + recursive
문맥에 따른 손글씨 단어, 문장 인식
악보 문맥 인식에서 높은 성능을 보인다고 함
#25 Hidden unit이라는 것도 있는데 이제는 cell이라는 것도 있다.
곱하기랑 더하기가 보이죠? 이게 뭐냐면 기존의 것, Ct-1것이랑 Ct를 적절히 섞어줄 거예요
옛날거랑 현재 거랑 적절히 섞어주는 거 => 하나의 long term memory라 할 것이야.
그걸 누가 하냐? Cell이 한다.
#27 Hidden unit이라는 것도 있는데 이제는 cell이라는 것도 있다.
곱하기랑 더하기가 보이죠? 이게 뭐냐면 기존의 것, Ct-1것이랑 Ct를 적절히 섞어줄 거예요
옛날거랑 현재 거랑 적절히 섞어줘서 long term memory를 만든다. 긴 시간동안 기억하는 메모리를 만든다.
그걸 누가 하냐? Cell이 한다.
#28 Output gates는 얼마나 밖으로 표출할지
이모두가 0에서 1사이
결과적으로 기존의 심플한 rnn에 비해서 히든 유닛 대신에 cell이라는 것을 만듬
이 cell은 롱텀 메모리를 기억한다
적절한 t-1과 t를 조합해서 이 output을 만든다.
기억할지 말지도 데이터에 의해서 학습되고 학습된다는 건 gate가 학습된다.
#29 인풋 x(t)와 이전의 메모리 h(t-1)
W[x,h]+b = W_x*x + W_h*h + b 를 간략히 표현한 것입니다.
Ht => short term memory 그때그 순간의 결과 값이라고 보면 되려나
#30 Tanh는 새로운 셀 스테이트에 더해질 수 있는 새로운 후보 값을 만들어낸다고 봐도 괜찮을 것 같다.
#38 저번주는 rgb코드 였는데 이번에는 the country of my birth라는 시퀀스 데이터…저 구조를 보고 입력 데이터는 너무 신경쓰지 마시길






![한글자 씩 입력해서 Hello라는 단어를 예측하는 예시
처음에 h[1,0,0,0]이라는 입력으로
e[0,1,0,0]이라는 출력을 예측하는
방향으로 학습이 진행됨.
그 다음 l[0,0,1,0]과 o[0,0,0,1]에 대해서
도 마찬가지로 학습이 진행됨.](https://image.slidesharecdn.com/chapter10sequencemodelingrecurrentandrecursivenets-190312114942/85/Chapter-10-sequence-modeling-recurrent-and-recursive-nets-11-320.jpg)


































![[NDC2017] 딥러닝으로 게임 콘텐츠 제작하기 - VAE를 이용한 콘텐츠 생성 기법 연구 사례](https://cdn.slidesharecdn.com/ss_thumbnails/v072-170426075401-thumbnail.jpg?width=640&height=640&fit=bounds)






![[기초개념] Recurrent Neural Network (RNN) 소개](https://cdn.slidesharecdn.com/ss_thumbnails/agistpurnndkim190430-190430140949-thumbnail.jpg?width=640&height=640&fit=bounds)









![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)



























