비구조적 모형화의 문제점
밀도추정,잡음제거, 결측값 대체, 표본추출등 데이터 전체의 분포를 이해해야하는 task 들이 있다.
하지만 이 때 수 천, 또는 수 백만개의 확률변수에 관한 분포를 모형화하는것은 계산측면이나 통계측면에서나 쉬운일이 아님.
32 X 32 RGB 픽셀 이미지를 가정할 때, 0과 1의 값만 가질수 있다고 가정해도
23072
10800
가지의 경우를 계산해야한다.
이는 우주에 존재하는 원자수 추정값 보다 많다!!
이를 일반화하면, 가질수 있는 값이 k가지인 서로 다른 변수 n 개로 이루어진
확률변수 x를 모형화 할때, 무려 가지의 경우를 고려해야 한다는 것이다.
𝑘 𝑛
3.
비구조적 모형화의 문제점
이러한참조표 기반 접근방식의 문제점은 변수들의 모든 가능한 부분집합 사이의 모든 가능한 종류의 상호작용을 나타내려 한다는 것이다.
실제로 우리가 마주치는 확률분포들은 그보다 훨씬 단순하다. 일반적으로 변수는 간접적으로만 다른 변수들과 상호작용한다.
확률분포를 표현할 때, 필요한 Parameter의 숫자를 줄이는것!
앨리스 캐럴밥
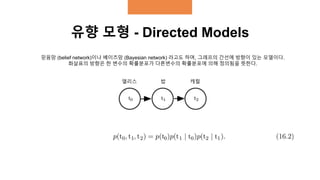
𝑝(𝑡0, 𝑡1, 𝑡2) = 𝑝(𝑡0)𝑝(𝑡1|𝑡0)𝑝(𝑡2|𝑡0, 𝑡1)
4.
그래프를 이용한 모형구조의서술
그래프를 이용해서 확률변수들 사이의 상호작용을 나타낸다.
각 노드는 확률변수를 나타내고, 각 간선은 변수들 사이의 직접적인 상호작용을 나타낸다.
노드 노드
간선
5.
왜 이 짓을하는가?
복습) 베이즈 정리
𝑝(𝐴|𝐵) =
𝑝(𝐴, 𝐵)
𝑝(𝐵)
𝑝(𝐴, 𝐵) = 𝑝(𝐴|𝐵)𝑝(𝐵)
이때 A와 B가 독립이면
𝑝(𝐴, 𝐵) = 𝑝(𝐴)𝑝(𝐵)𝑝(𝐴|𝐵) = 𝑝(𝐴)
유향 모형 -Directed Models
믿음망 (belief network)이나 베이즈망 (Bayesian network) 라고도 하며, 그래프의 간선에 방향이 있는 모델이다.
화살표의 방향은 한 변수의 확률분포가 다른변수의 확률분포에 의해 정의됨을 뜻한다.
앨리스 캐럴밥
9.
유향 모형 -Directed Models
비구조적 모형화에 비해 구조적 모형화의 장점을 살펴보기위해 비용을 조사해보자.
완주시간을 0분에서 10분까지 6초단위 구간들로 나눌경우, t_0, t_1, t_2 는 각각 100가지 이산적인 값을 가질 수 있다.
이를 하나의 참조표로 계산할 경우 999,999개의 값을 저장해야 한다 (자유도 때문에 1 빠짐)
그 대신, 조건부 확률분포만 담은 표를 만든다면,
t_0 는 99가지, t_0가 주어졌을때 t_1의 분포는 9,900개의 값이 필요하고, t_1이 주어졌을때 t_2의 분포 역시 9,900개의 값이 필요하므로
총 19,899개의 값만 담으면 된다. 따라서 유향그래프모형을 사용할 때 매개변수가 50분의 1 이하로 줄어든다.
10.
유향 모형 -Directed Models
𝑝(𝑎, 𝑏, 𝑐, 𝑑, 𝑒) = 𝑝(𝑎)𝑝(𝑏|𝑎)𝑝(𝑐|𝑎, 𝑏)𝑝(𝑑|𝑏)𝑝(𝑒|𝑐)
joint probability를 그냥 구하려면 모든 변수간의 관계를 나타내야 하지만,
식을 factorize한 결과, 그만큼의 정보가 없어도 충분히 구할 수 있음을 알 수 있다.
11.
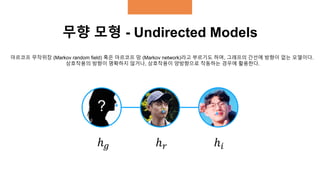
무향 모형 -Undirected Models
마르코프 무작위장 (Markov random field) 혹은 마르코프 망 (Markov network)라고 부르기도 하며, 그래프의 간선에 방향이 없는 모델이다.
상호작용의 방향이 명확하지 않거나, 상호작용이 양방향으로 작동하는 경우에 활용한다.
?
ℎ 𝑟 ℎ𝑖ℎ 𝑔
12.
무향 모형 -Undirected Models
무향모델은 Clique와 factor를 활용하여 공식으로 표현한다.
Clique는 노드의 집합을 의미하며, non-negative function인 factor와 관계한다.
𝑝(𝑎, 𝑏, 𝑐, 𝑑, 𝑒) =
1
𝑍
𝜙 𝑎,𝑏(𝑎, 𝑏)𝜙 𝑏,𝑐(𝑏, 𝑐)𝜙 𝑎,𝑑(𝑎, 𝑑)𝜙 𝑏,𝑒(𝑏, 𝑒)𝜙 𝑒,𝑓(𝑒, 𝑓)
분배함수 - ThePartition Function
이 p tilde x 들의 합은 어떤 함수의 결과이지만 이것을 바로 확률로 해석할 수는 없다. 때문에 정규화 상수 Z를 활용하는데
만약 파이 함수들이 고정되었을때는 Z를 상수라고 할 수 있지만, 파이함수에 매개변수들이 있다면 Z는 그 매개변수들의 함수가 된다.
이 정규화 함수 Z를 분배함수라고 한다.
16.
에너지 기반 모형- Energy Based Models
무향모형의 p tilde x 들은 0보다 크다는 가정에 기초한다.(뇌피셜 - 확률과의 연결고리를 만들기 위해)
이 가정을 만족시키기 위해 에너지 기반모형을 활용하기도 한다. (알아보니 거의 다 이런 구조인 듯 하다)
여기서 E(x)를 에너지 함수라고 하고, 지수함수는 언제나 양수이므로 p tilde x는 언제나 양수가 된다.
따라서 이렇게 구성하게 되면 어떤 함수도 에너지 함수로 사용할 수 있으며 그 덕분에 학습이 좀 더 간단해진다
더 자세한 내용은 20장 볼츠만 머신에서 만나보도록 하자..!!
17.
분리와 종속 분리(D-분리)
그래프 모형에서, 변수간의 직접 상호작용은 간선으로 표현된다. 그러나 간접적으로 상호작용하는 변수들의 관계를 파악해야할 때도 많이 있다.
간접상호작용 중에는 다른변수의 관측에 의해 활성화 혹은 비활성화 되는 것들이 있다.
무향 모델에서는 조건부 독립관계를 간단하게 식별할 수 있다.
조건부 독립이 성립할 경우 분리(Separation)라고 부른다.
비 관측 변수로만 이루어진 경로를 ‘활성(active) 경로’라고 하고,
관측 변수가 포함된 경로를 ‘비활성(inactive) 경로’ 라고 한다.
(a) - 확률변수 a 와 b 사이의 경로는 활성경로이다. a와 b는 분리되지 않았다.
(b) - 확률변수 a 와 b 사이의 유일한 경로인 s가 관측되었다.
비활성 경로가 되었으므로 a와 b는 c가 주어졌을때 분리되었다고 할 수 있다.
18.
분리와 종속 분리(D-분리)
b에 들어간 음영은 이 변수가 관측되었다는 의미.
이 경우, a와 c, d와 c의 경로는 차단된다. 이 때, 분리되었다고 한다. (독립)
b가 관측됨으로써 a와 d사이의 한 경로도 차단되지만 둘 사이에는 다른 활성경로 존재
따라서 a와 d는 b가 관측된다 하여도 분리되지 않음. (종속)
19.
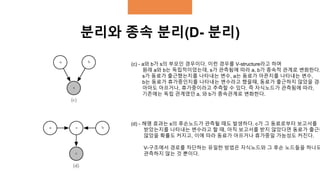
분리와 종속 분리(D-분리)
(a)- 확률변수 a 와 b 사이의 모든 가능한 길이 2의 활성경로들. 이런 경로는
s가 관측되면 차단된다.
(b) - 변수 a와 b가 하나의 공통원인 s로 연결되어 있다.
s가 주어진 지역에 태풍이 지나가고 있는지를 나타내는 여부이고,
a와 b는 그 지역의 기상관측소에서 측정한 풍속이라고 할 때,
s, 태풍이 왔다는것을 알게된다면,
a지역의 풍속이 느리다고 해도, b 지역의 풍속이 높을것이라는 기대는 바뀌지 않는
즉, a와 b는 독립이다.그러나 s가 관측되지 않은 상태에서는 활성 종속관계이다.
20.
분리와 종속 분리(D-분리)
(c) - a와 b가 s의 부모인 경우이다. 이런 경우를 V-structure라고 하며
원래 a와 b는 독립적이었는데, s가 관측됨에 따라 a, b가 종속적 관계로 변화한다.
s가 동료가 출근했는지를 나타내는 변수, a는 동료가 아픈지를 나타내는 변수,
b는 동료가 휴가중인지를 나타내는 변수라고 했을때, 동료가 출근하지 않았을 경우
아마도 아프거나, 휴가중이라고 추측할 수 있다. 즉 자식노드가 관측됨에 따라,
기존에는 독립 관계였던 a, 와 b가 종속관계로 변화한다.
(d) - 해명 효과는 s의 후손노드가 관측될 때도 발생하다. c가 그 동료로부터 보고서를
받았는지를 나타내는 변수라고 할 때, 아직 보고서를 받지 않았다면 동료가 출근하
않았을 확률도 커지고, 이에 따라 동료가 아프거나 휴가중일 가능성도 커진다.
V-구조에서 경로를 차단하는 유일한 방법은 자식노드와 그 후손 노드들을 하나도
관측하지 않는 것 뿐이다.
21.
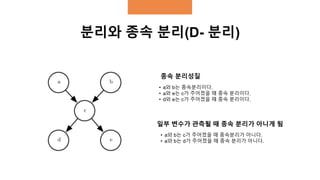
분리와 종속 분리(D-분리)
• a와 b는 종속분리이다.
• a와 e는 c가 주어졌을 때 종속 분리이다.
• d와 e는 c가 주어졌을 때 종속 분리이다.
• a와 b는 c가 주어졌을 때 종속분리가 아니다.
• a와 b는 d가 주어졌을 때 종속 분리가 아니다.
종속 분리성질
일부 변수가 관측될 때 종속 분리가 아니게 됨
22.
인수그래프 - FactorGraphs
무향모형의 그래프는 때때로 중의적이다. 이런 중의적인 표현을 해결하기 위해 인수그래프를 활용한다.
#4 예를들어 세명으로 이루어진 계주 완주 시간을 모형화 한다고하자. 캐럴의 시간은 앨리스의 완주시간과 간접적으로만 의존한다. 밥의 완주시간을 이미 알고 있다면, 앨리스의 완주시간을 안다고 해서 캐럴의 완주시간을 더 잘 추정할 수 있는것은 아니다.
#12 예를 들어, 성한이가 감기에 걸렸는지의 여부와 성한이의 숨겨진 여자친구가 감기에 걸렸는지의 여부, 그리고 연준이가 감기에 걸렸는지의 여부에 해당하는 세 이진변수에 관한 분포를 모형화 한다고 해보자.
이 경우, 성한이의 숨겨진 여자친구의 존재를 연준이는 모르므로 둘 사이에 감기가 옮을 가능성은 없다.
둘둘이는 감기를 옮길수 있지만 여자친구와 연준이가 서로 모르는 사이라는 가정하에, 성한이를 통해서 간접적으로 만 감기를 옮길수 있다.
이 예에서 성한이가 숨겨진 여자친구에게 감기를 옮길 확률은 여자친구가 성한이에게 감기를 옮길 확률과 같다. 즉 두 사건사이에는 뚜렷한 방향이 존재하지 않는다. 그러므로 무향모형으로 나타내는것이 적절하다.
#13 Clique는 파벌 이라고 번역이 되어있고, factor는 그 파벌내의 변수들의 친화도를 나타내는 함수이다.