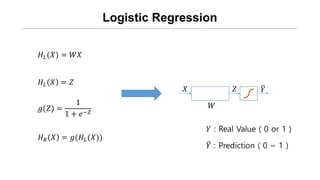
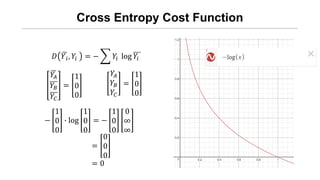
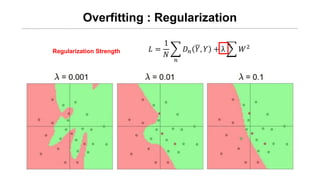
Logistic Cost VSCross Entropy
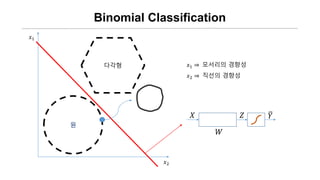
binomial classification 의 경우
각각 오직 2가지 경우의 Real
Data와 H(x) 값이 나올 수 있다.
0
1
1
0
위 행렬은 다음과 같이 표현 할 수 있다.
𝐻(𝑥)
1 − 𝐻(𝑥)
𝐻 𝑥 , 𝑦
0
1
𝑦
1 − 𝑦
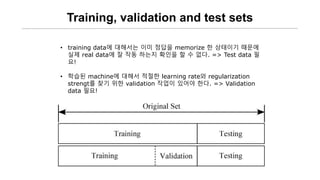
Training, validation andtest sets
• training data에 대해서는 이미 정답을 memorize 한 상태이기 때문에
실제 real data에 잘 작동 하는지 확인을 할 수 없다. => Test data 필
요!
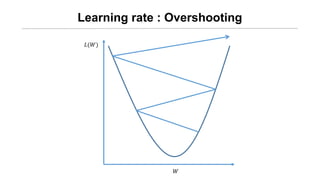
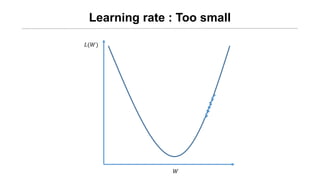
• 학습된 machine에 대해서 적절한 learning rate와 regularization
strengt를 찾기 위한 validation 작업이 있어야 한다. => Validation
data 필요!
#20 도박을 할 때 확률 값을 기반으로 값을 맞춘다고 하자
동전 던지기의 경우 H, T 0.5 0.5 이므로 확률 데이터를 기반으로 답을 맞추는 의미가 없다. => 엔트로피 1
특정 동전의 경우 H, T 0.8, 0.2 이라고 할 때 이 확률 데이터를 기반으로 H를 선택하면 답을 맞출 확률이 높아진다. => 엔트로피가 작아진다.
즉 모든 확률의 값이 똑같을 때 엔트로피는 가장 높고 특정 데이터에 확률이 치중 되어 있을 때 엔트로피는 작아진다.




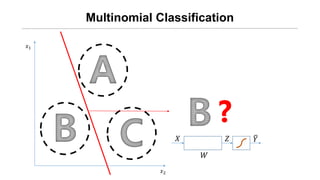
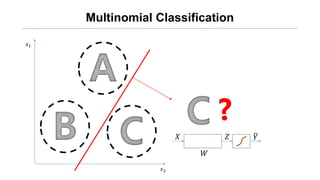
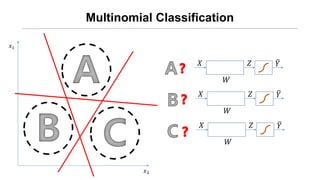
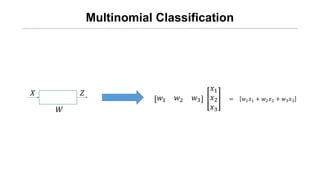
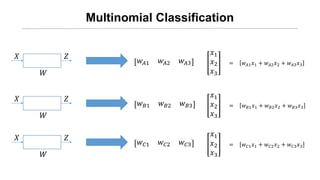
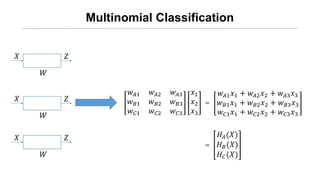
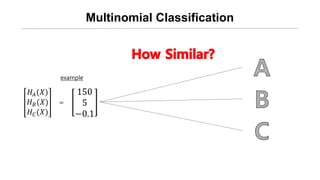

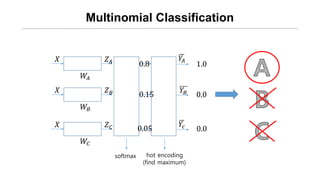



























![[신경망기초] 소프트맥스회귀분석](https://cdn.slidesharecdn.com/ss_thumbnails/nn09-180318142813-thumbnail.jpg?width=640&height=640&fit=bounds)






![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)









