Intro
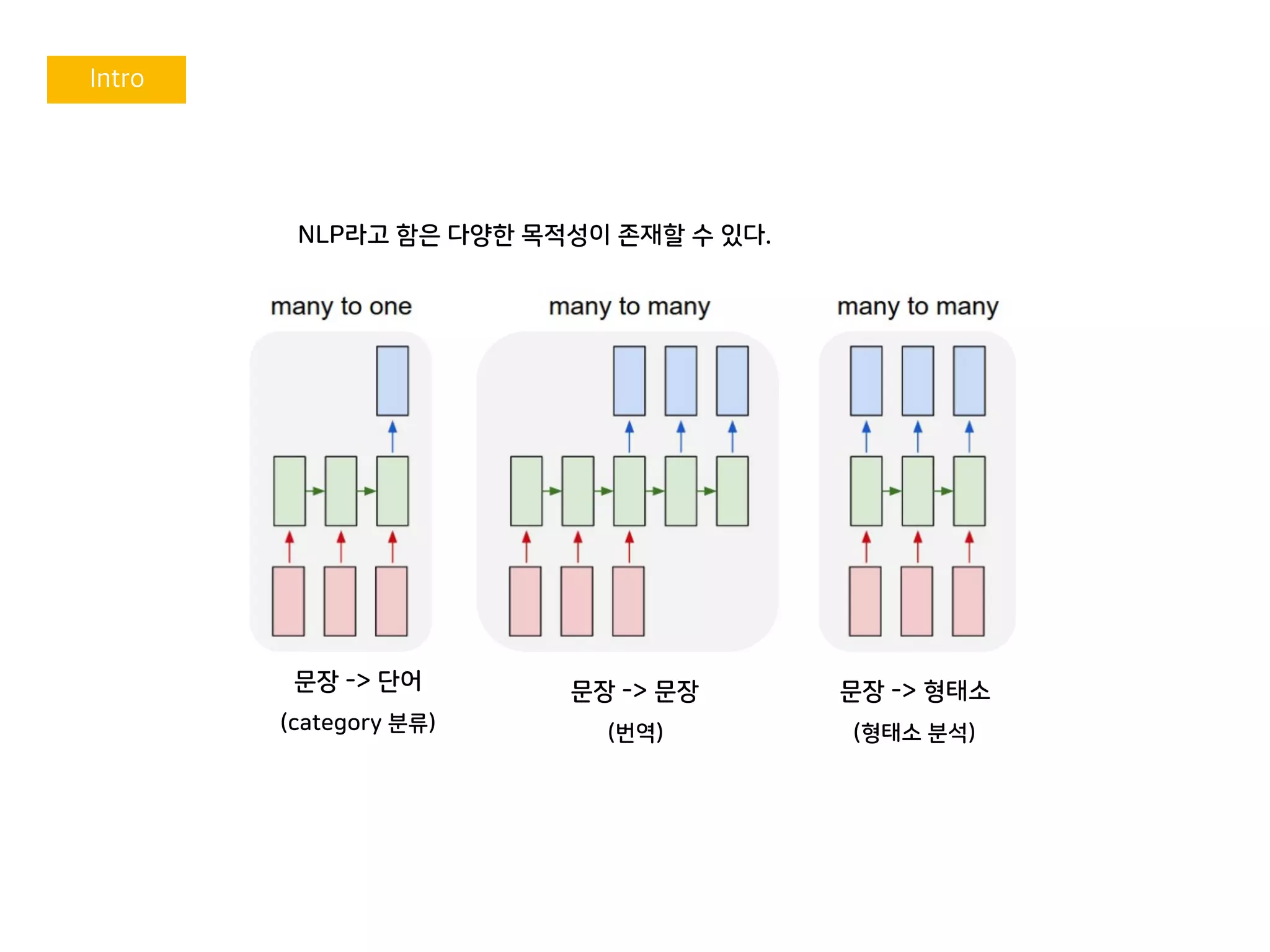
NLP라고 함은 다양한목적성이 존재할 수 있다.
문장 -> 문장
(번역)
문장 -> 형태소
(형태소 분석)
문장 -> 단어
(category 분류)
3.
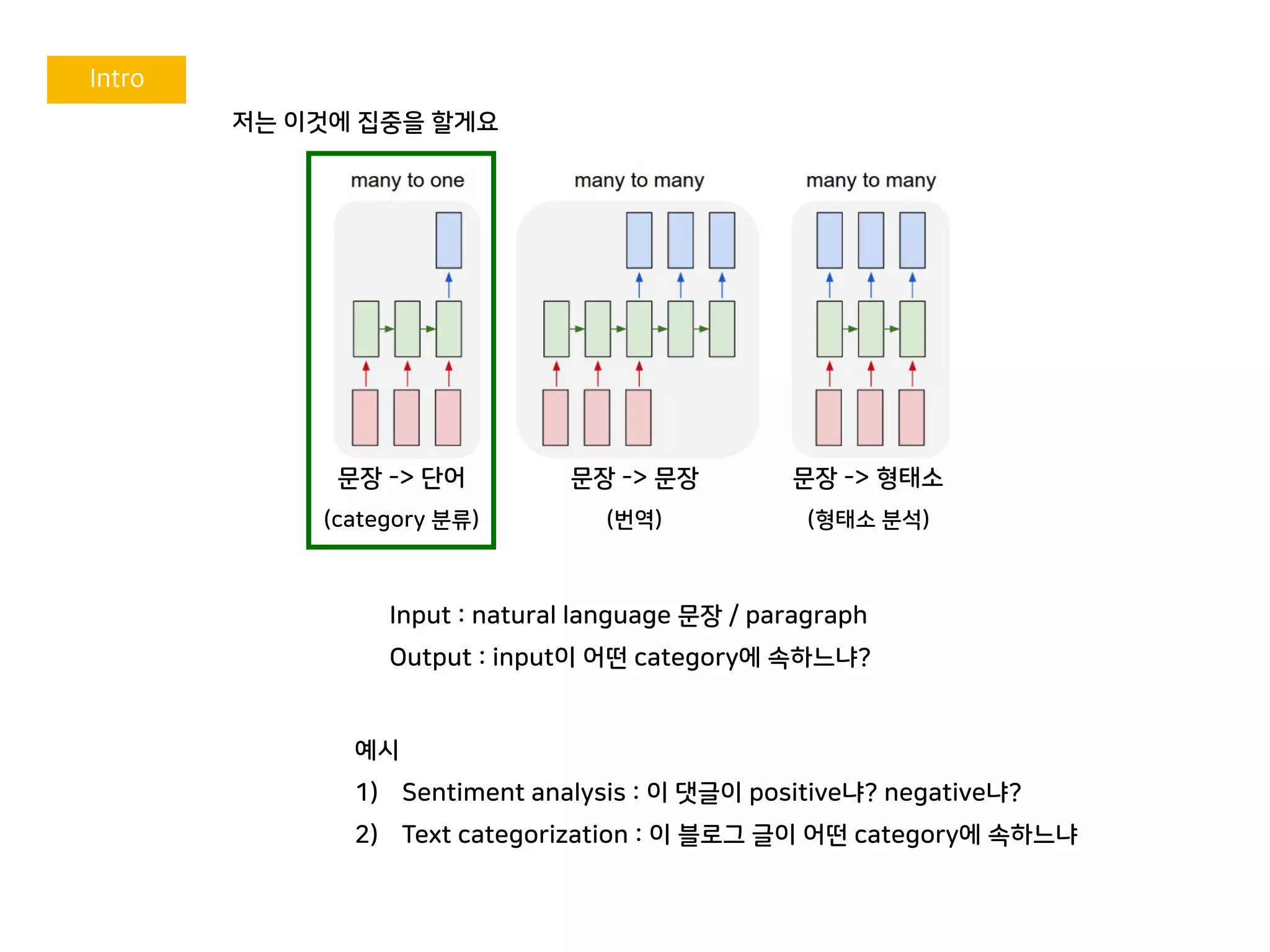
저는 이것에 집중을할게요
문장 -> 문장
(번역)
문장 -> 형태소
(형태소 분석)
문장 -> 단어
(category 분류)
Input : natural language 문장 / paragraph
Output : input이 어떤 category에 속하느냐?
예시
1) Sentiment analysis : 이 댓글이 positive냐? negative냐?
2) Text categorization : 이 블로그 글이 어떤 category에 속하느냐
Intro
4.
Q. NL 분석을하려는데 문장을 어떻게 데이터로 표현하지?
1) image, 음성 데이터 => 숫자로 명확하게 표현할 수 있지만…텍스트는?
2) 개랑 늑대는 실체는 비슷한데(생물학적으로) 언어로 표현하면 개라는 것과 늑대는 너무 다르잖아
우리가 인지하고 있는 유사하다는 정보를 데이터로 어떻게 표현하지?
How to represent a sentence
5.
1. 문장을 일단끊어보자. 이 단위를 token이라 한다.
2. token을 단어로 보든 품사로 모든 그건 자유롭게 생각
Ex)
(류성한,과, 인연준,은, 서로, 친구, 입니다.)
(류성한과, 인연준은, 서로, 친구,입니다.)
3. 이미 사람들이 만들어둔 Tokenizer library 중에서 어떤 걸 쓰느냐에 따라 조금씩 달라짐
How to represent a sentence
Q. NL 분석을 하려는데 문장을 어떻게 데이터로 표현하지?
6.
How to representa sentence
Step 1
One-hot coding
류성한 => (1,0,0,0,0)
인연준 => (0,1,0,0,0)
서로 => (0,0,1,0,0)
친구 => (0,0,0,1,0)
입니다 => (0,0,0,0,1)
Ex (류성한과, 인연준은, 서로, 친구,입니다.)
Q. 이 token을 어떻게 숫자로 바꾸지?
7.
How to representa sentence
Step 1
One-hot coding Ex (류성한과, 인연준은, 서로, 친구,입니다.)
류성한 => (1,0,0,0,0)
인연준 => (0,1,0,0,0)
서로 => (0,0,1,0,0)
친구 => (0,0,0,1,0)
입니다 => (0,0,0,0,1)
지금은 (류성한, 인연준)사이의 거리와 (류성한, 입니다) 사이의 거리가 동일함
내재적인 meaning을 살리기 위한 Up grade가 필요하다.
Q. 이 token을 어떻게 숫자로 바꾸지?
8.
How to representa sentence
Step 1
One-hot coding Ex (류성한과, 인연준은, 서로, 친구,입니다.)
류성한 => (1,0,0,0,0)
인연준 => (0,1,0,0,0)
서로 => (0,0,1,0,0)
친구 => (0,0,0,1,0)
입니다 => (0,0,0,0,1)
지금은 (류성한, 인연준)사이의 거리와 (류성한, 입니다) 사이의 거리가 동일함
내재적인 meaning을 살리기 위한 UPgrade가 필요하다.
유의미한 새로운 vector로 바꿔보자!(word embedding이라고 함)
Q. 이 token을 어떻게 숫자로 바꾸지?
9.
How to representa sentence
__ 외나무다리 __ 앞 뒤에는 어떤 단어? ‘원수는’과 ‘-에서’일 가능성이 높다.
1. Word2Vec은 ‘외나무다리’가 ‘-에서’, ‘원수는’와 어떤 연관이 있다고 학습한다.
2. 중심에 있는 단어로 주변 단어를 예측하는걸 목적으로 학습
3. 학습 방법을 좀 더 자세히 보자
Step 2
Embedding의 방법론 중 하나인 Word2Vec의 컨셉, 2013년에 나옴
* Word2Vec에는 Skip-Gram방식과 CBOW(Continuous Bag of Words) 방식이 있다.
CBOW는 주변 단어로 중심 단어를 맞추는 방식이다.
앞서 설명한 것(중심 단어로 주변 단어 예측)은 Skip-Gram 방식이다. 요즘은 전부 skip-gram사용
Q. 이 token을 어떻게 숫자로 바꾸지?
(비슷한 위치에 등장 하는 단어들은 그 의미도 유사할 것이라는 전제가 깔려 있다.)
10.
How to representa sentence
Step 2
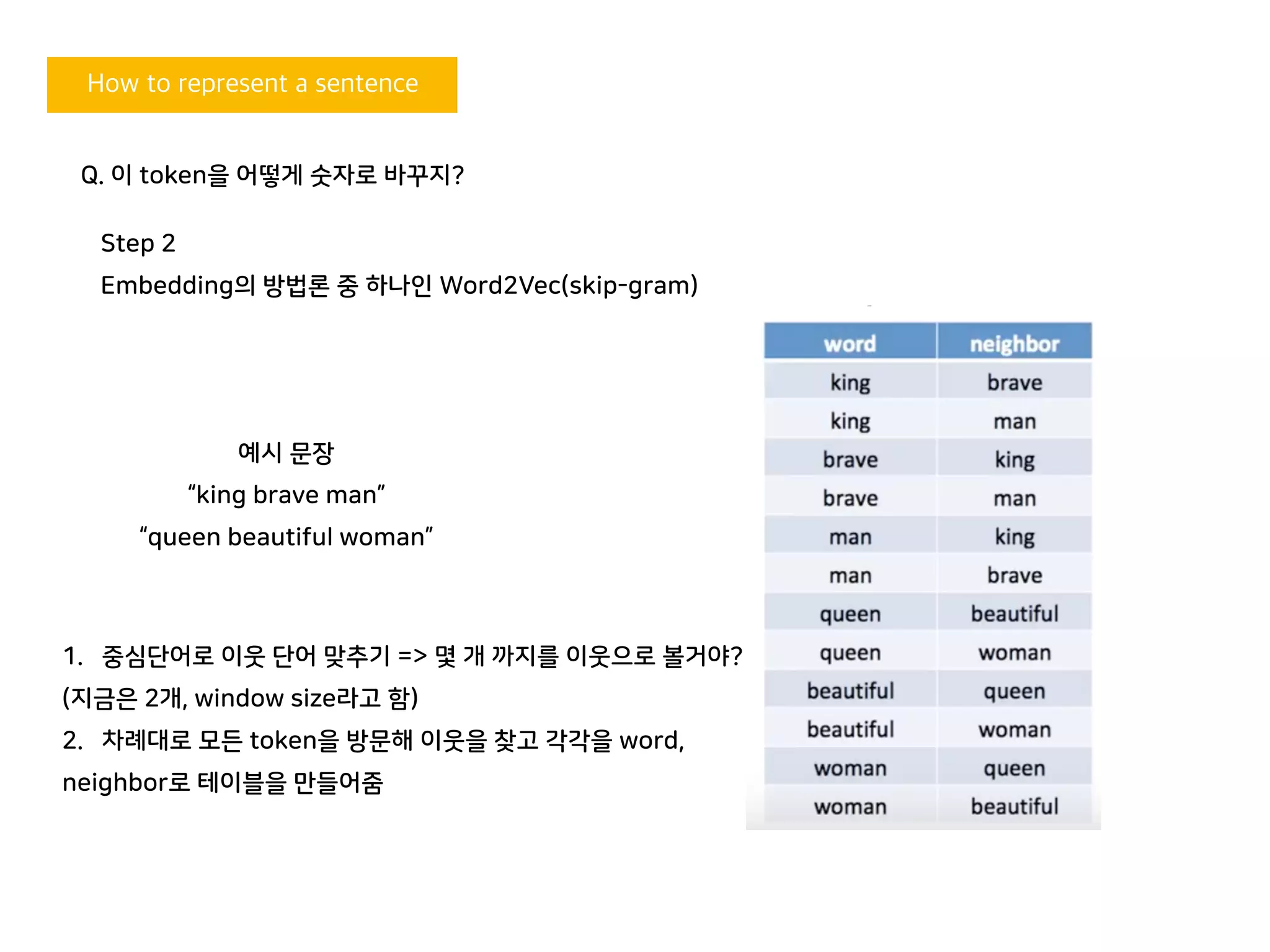
Embedding의 방법론 중 하나인 Word2Vec(skip-gram)
Q. 이 token을 어떻게 숫자로 바꾸지?
예시 문장
“king brave man”
“queen beautiful woman”
1. 중심단어로 이웃 단어 맞추기 => 몇 개 까지를 이웃으로 볼거야?
(지금은 2개, window size라고 함)
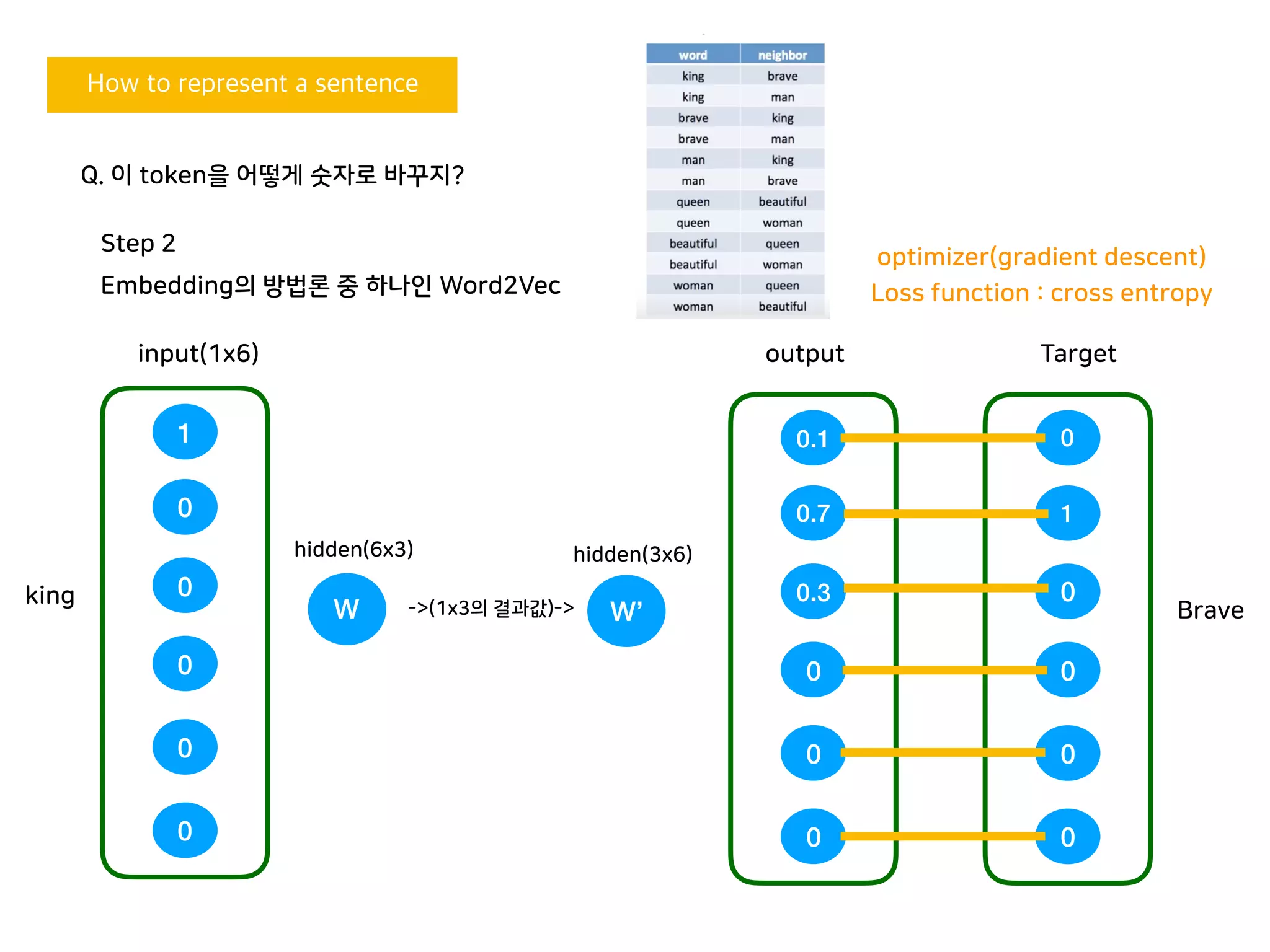
2. 차례대로 모든 token을 방문해 이웃을 찾고 각각을 word,
neighbor로 테이블을 만들어줌
11.
How to representa sentence
Step 2
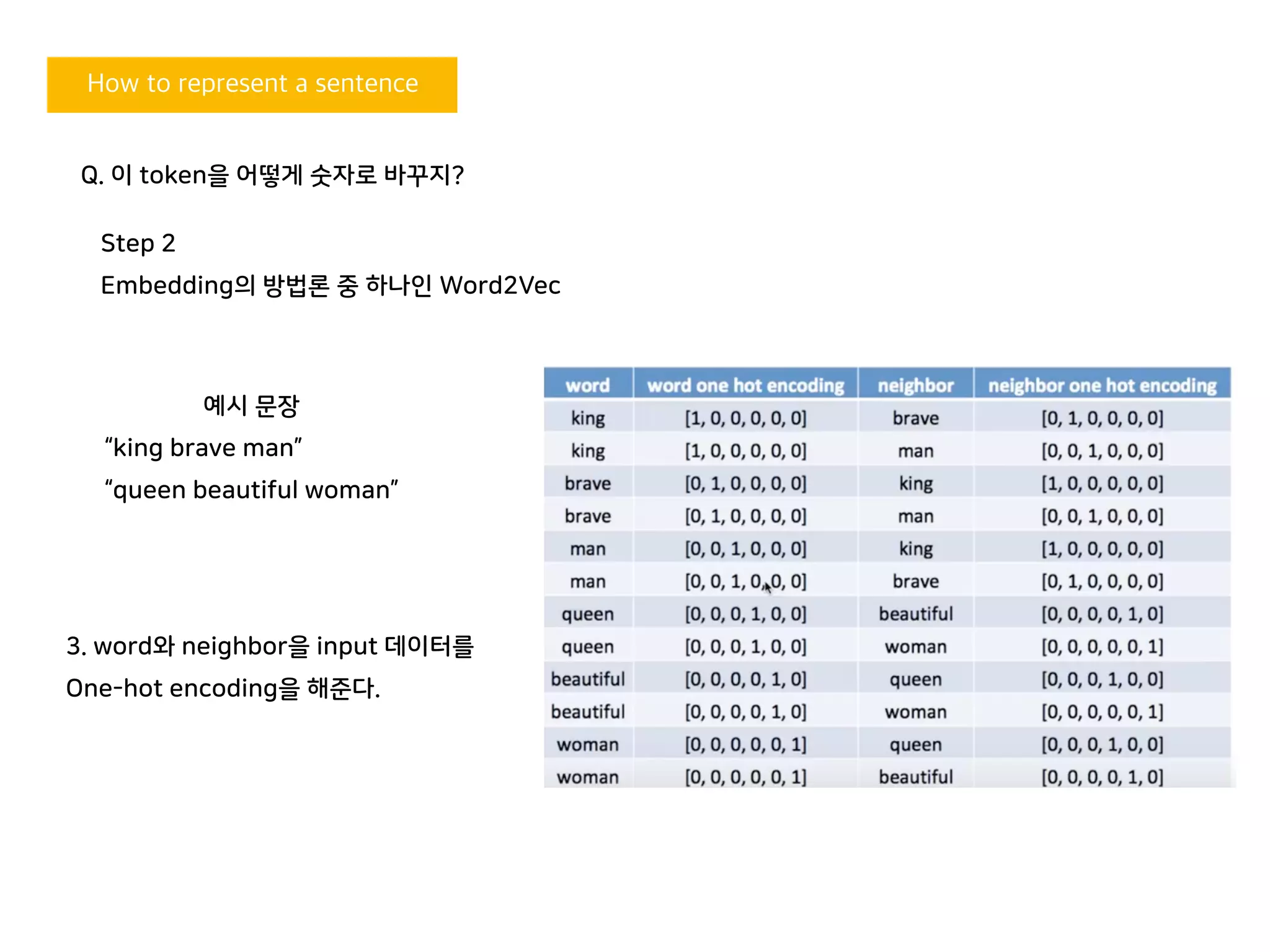
Embedding의 방법론 중 하나인 Word2Vec
Q. 이 token을 어떻게 숫자로 바꾸지?
예시 문장
“king brave man”
“queen beautiful woman”
3. word와 neighbor을 input 데이터를
One-hot encoding을 해준다.
12.
How to representa sentence
Step 2
Embedding의 방법론 중 하나인 Word2Vec
Q. 이 token을 어떻게 숫자로 바꾸지?
예시 문장
“king brave man”
“queen beautiful woman”
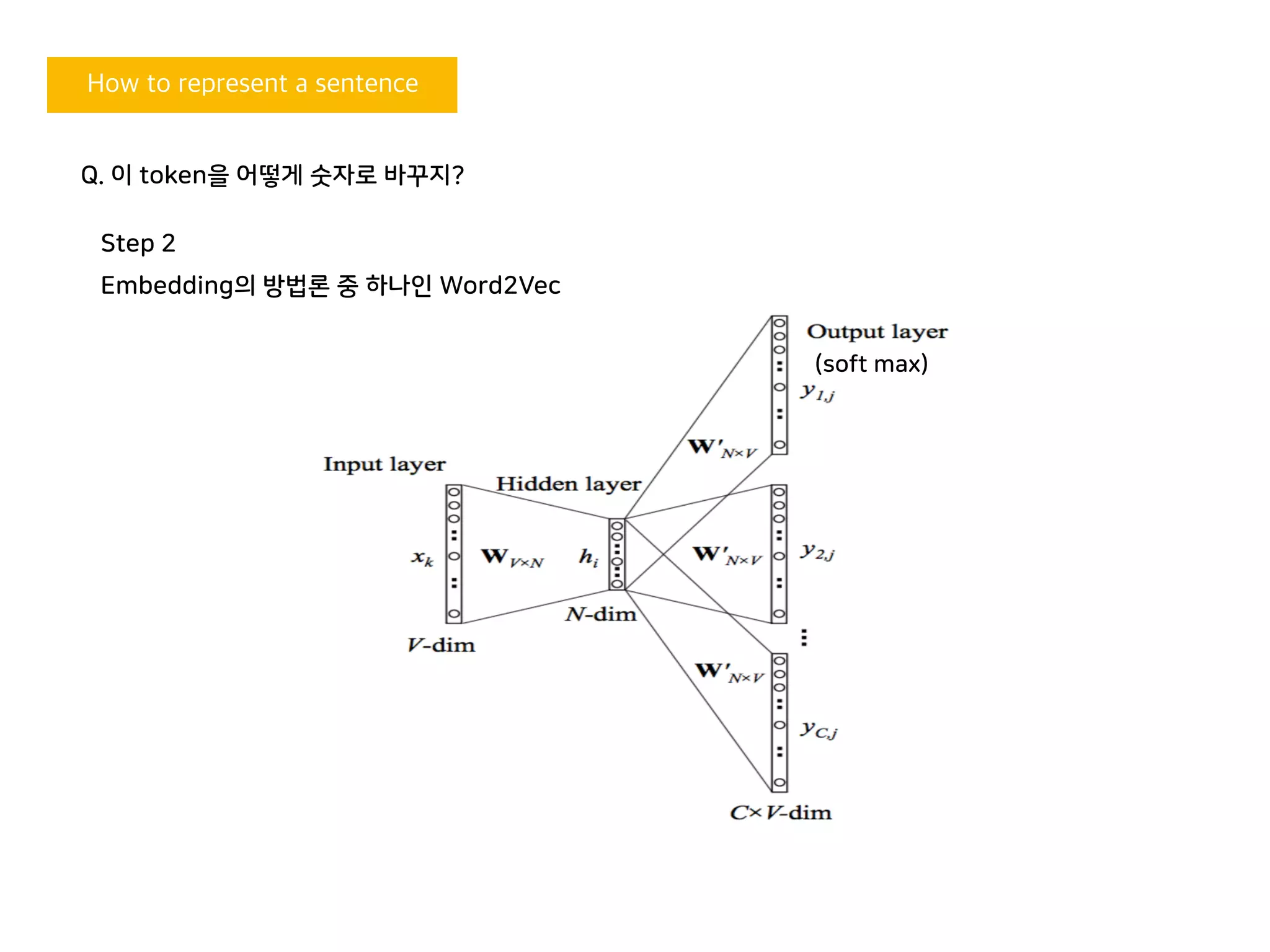
4. 각각을 input과 target(y) 데이터로 하는
Word2vec 뉴럴넷을 만든다. 어떤 식으로 학습이 되는가?
3. word와 neighbor을 input 데이터를
One-hot encoding을 해준다.
13.
How to representa sentence
Step 2
Embedding의 방법론 중 하나인 Word2Vec
Q. 이 token을 어떻게 숫자로 바꾸지?
(soft max)
14.
How to representa sentence
Step 2
Embedding의 방법론 중 하나인 Word2Vec
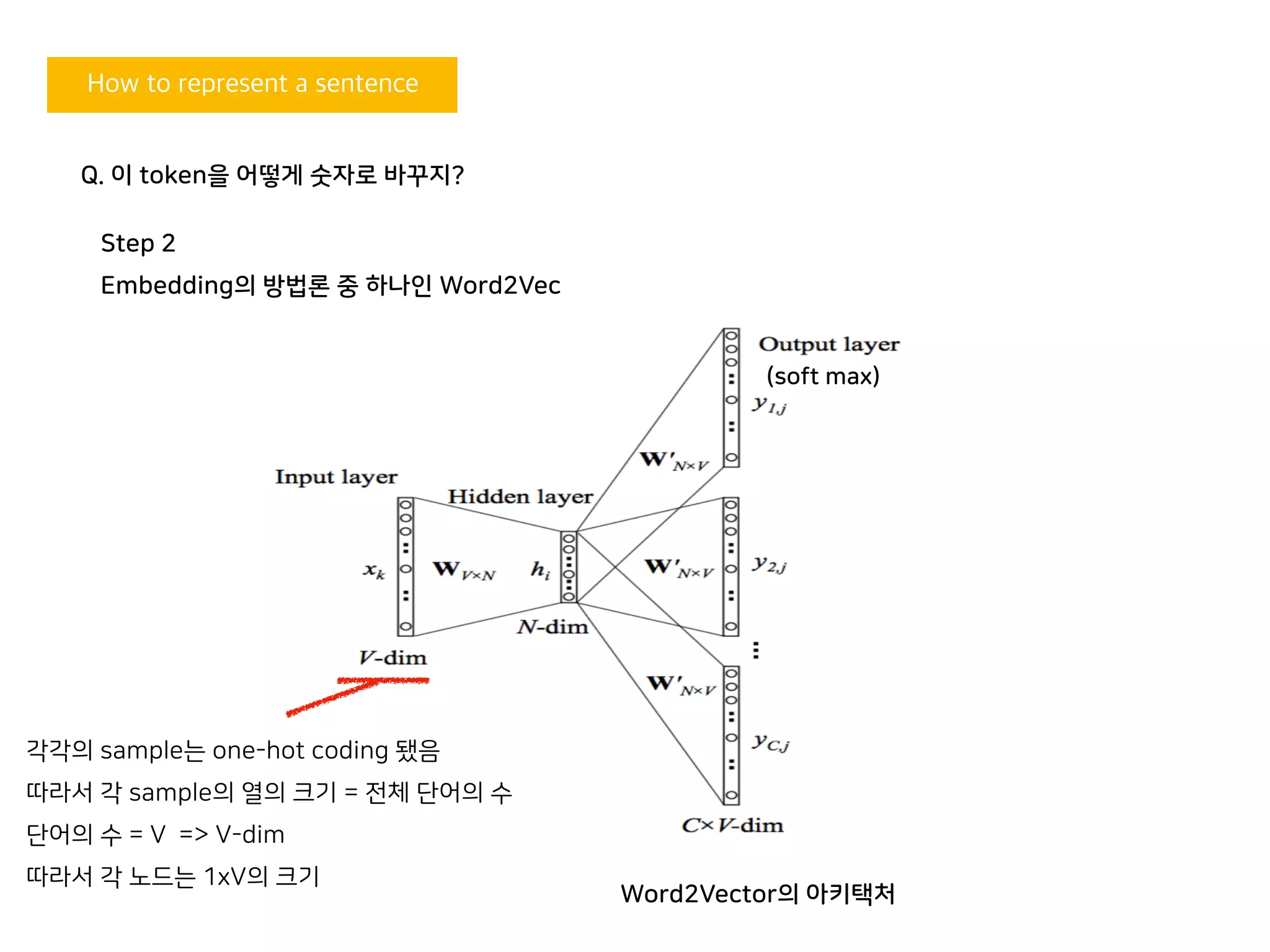
각각의 sample는 one-hot coding 됐음
따라서 각 sample의 열의 크기 = 전체 단어의 수
단어의 수 = V => V-dim
따라서 각 노드는 1xV의 크기
Q. 이 token을 어떻게 숫자로 바꾸지?
Word2Vector의 아키택처
(soft max)
15.
How to representa sentence
Step 2
Embedding의 방법론 중 하나인 Word2Vec
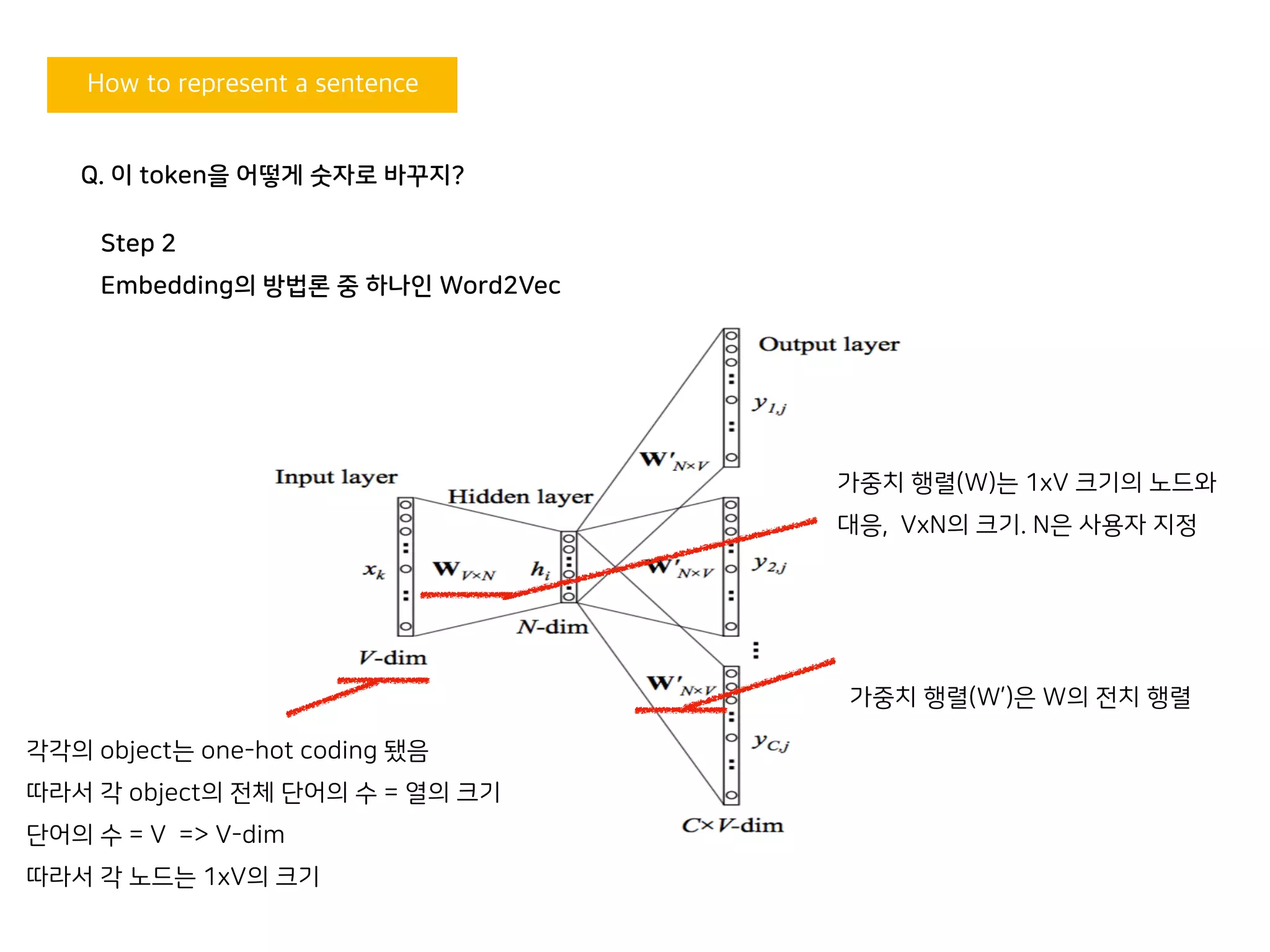
각각의 object는 one-hot coding 됐음
따라서 각 object의 전체 단어의 수 = 열의 크기
단어의 수 = V => V-dim
따라서 각 노드는 1xV의 크기
가중치 행렬(W)는 1xV 크기의 노드와
대응, VxN의 크기. N은 사용자 지정
가중치 행렬(W’)은 W의 전치 행렬
Q. 이 token을 어떻게 숫자로 바꾸지?
16.
How to representa sentence
Step 2
Embedding의 방법론 중 하나인 Word2Vec
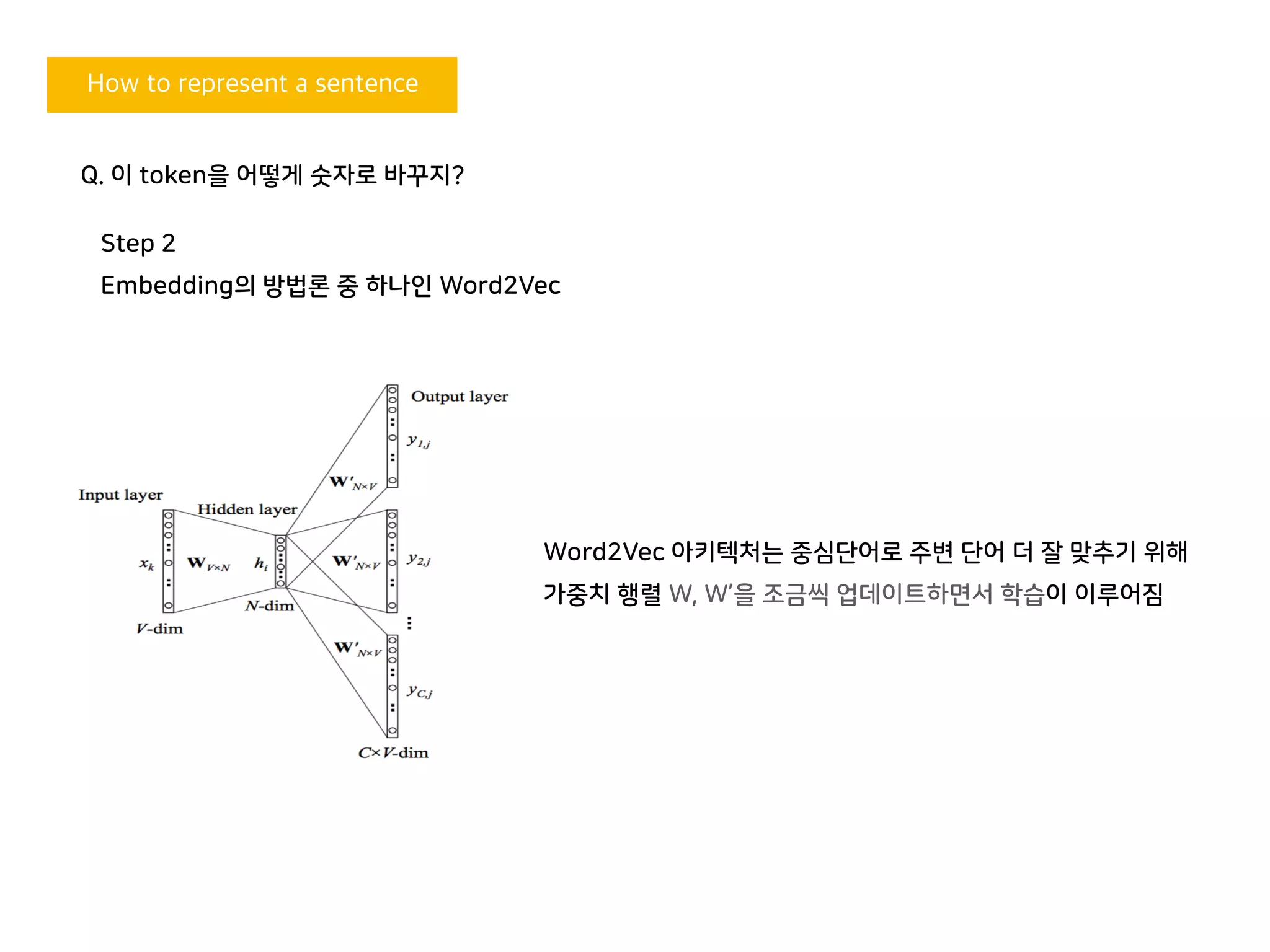
Word2Vec 아키텍처는 중심단어로 주변 단어 더 잘 맞추기 위해
가중치 행렬 W, W’을 조금씩 업데이트하면서 학습이 이루어짐
Q. 이 token을 어떻게 숫자로 바꾸지?
17.
How to representa sentence
Step 2
Embedding의 방법론 중 하나인 Word2Vec
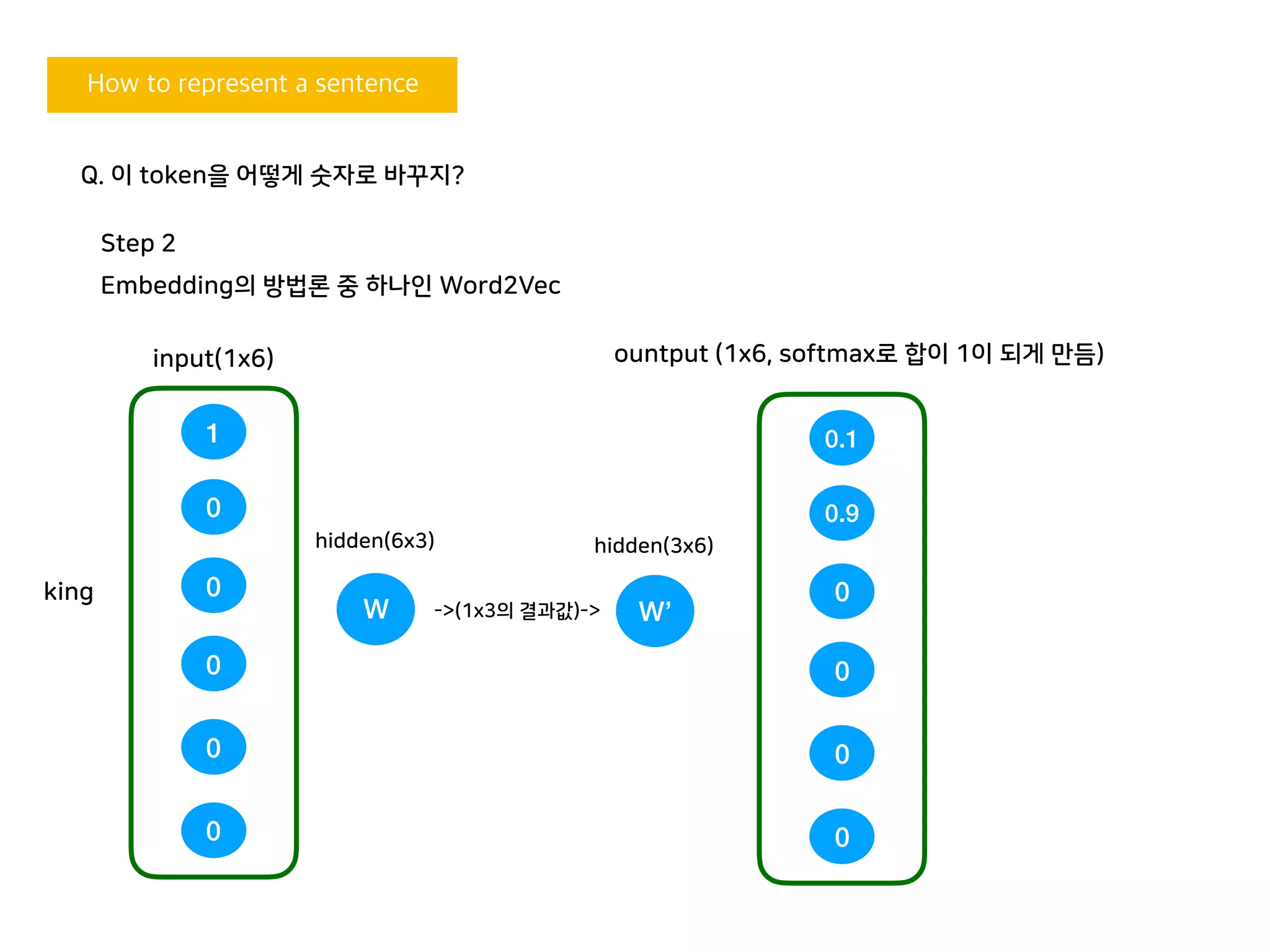
Q. 이 token을 어떻게 숫자로 바꾸지?
1
0
0
0
0
0
king
W
hidden(6x3)
W’
hidden(3x6)
0.1
0.9
0
0
0
0
ountput (1x6, softmax로 합이 1이 되게 만듬)input(1x6)
->(1x3의 결과값)->
18.
How to representa sentence
Step 2
Embedding의 방법론 중 하나인 Word2Vec
Q. 이 token을 어떻게 숫자로 바꾸지?
1
0
0
0
0
0
king
W W’
0.1
0.7
0.3
0
0
0
outputinput(1x6)
0
1
0
0
0
0
Target
Brave
Loss function : cross entropy
optimizer(gradient descent)
hidden(6x3) hidden(3x6)
->(1x3의 결과값)->
19.
How to representa sentence
Step 2
Embedding의 방법론 중 하나인 Word2Vec
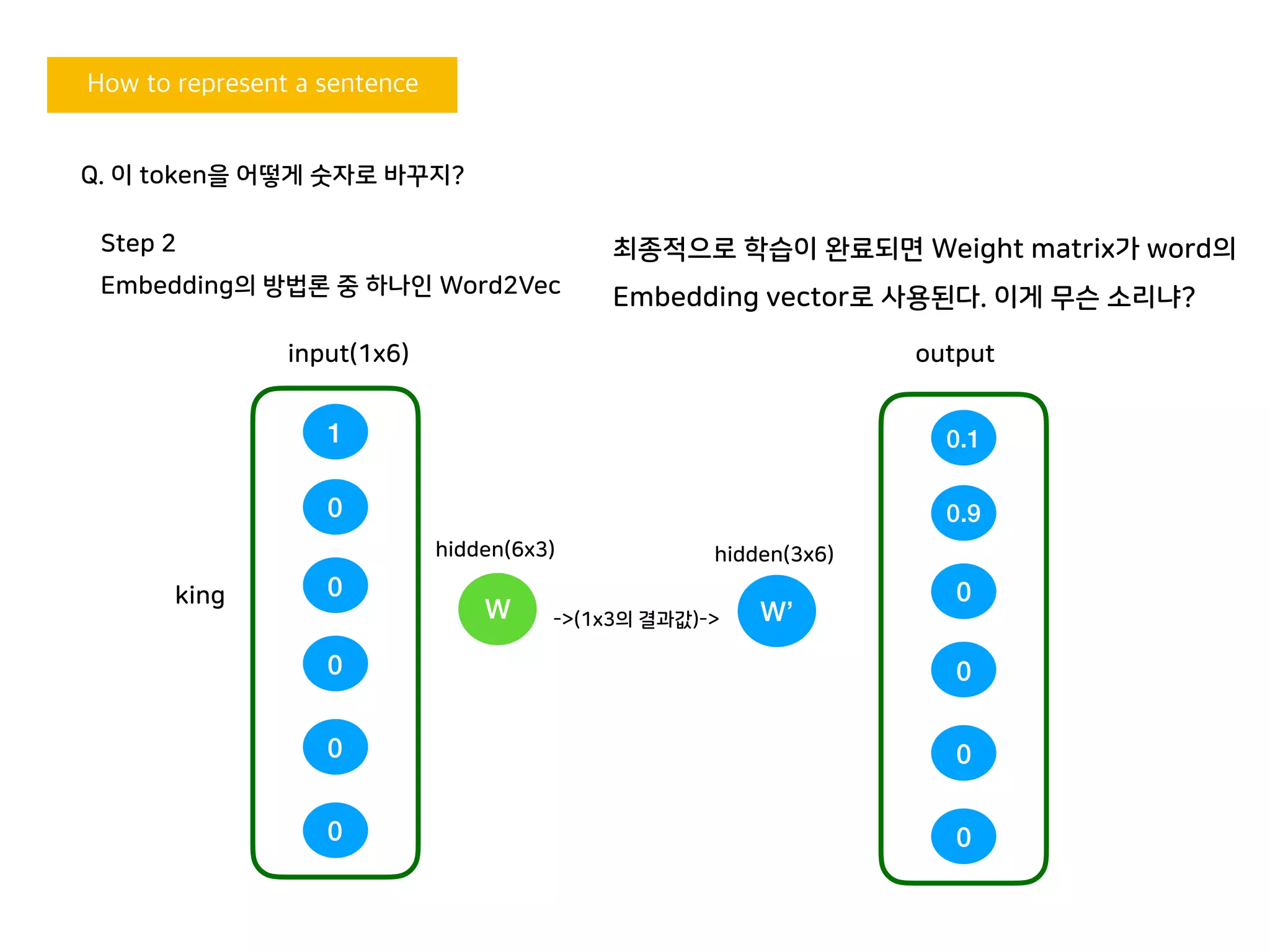
Q. 이 token을 어떻게 숫자로 바꾸지?
1
0
0
0
0
0
king
W W’
0.1
0.9
0
0
0
0
outputinput(1x6)
hidden(6x3) hidden(3x6)
->(1x3의 결과값)->
최종적으로 학습이 완료되면 Weight matrix가 word의
Embedding vector로 사용된다. 이게 무슨 소리냐?
20.
Q. 이 token을어떻게 숫자로 바꾸지?
How to represent a sentence
Step 2
Embedding의 방법론 중 하나인 Word2Vec
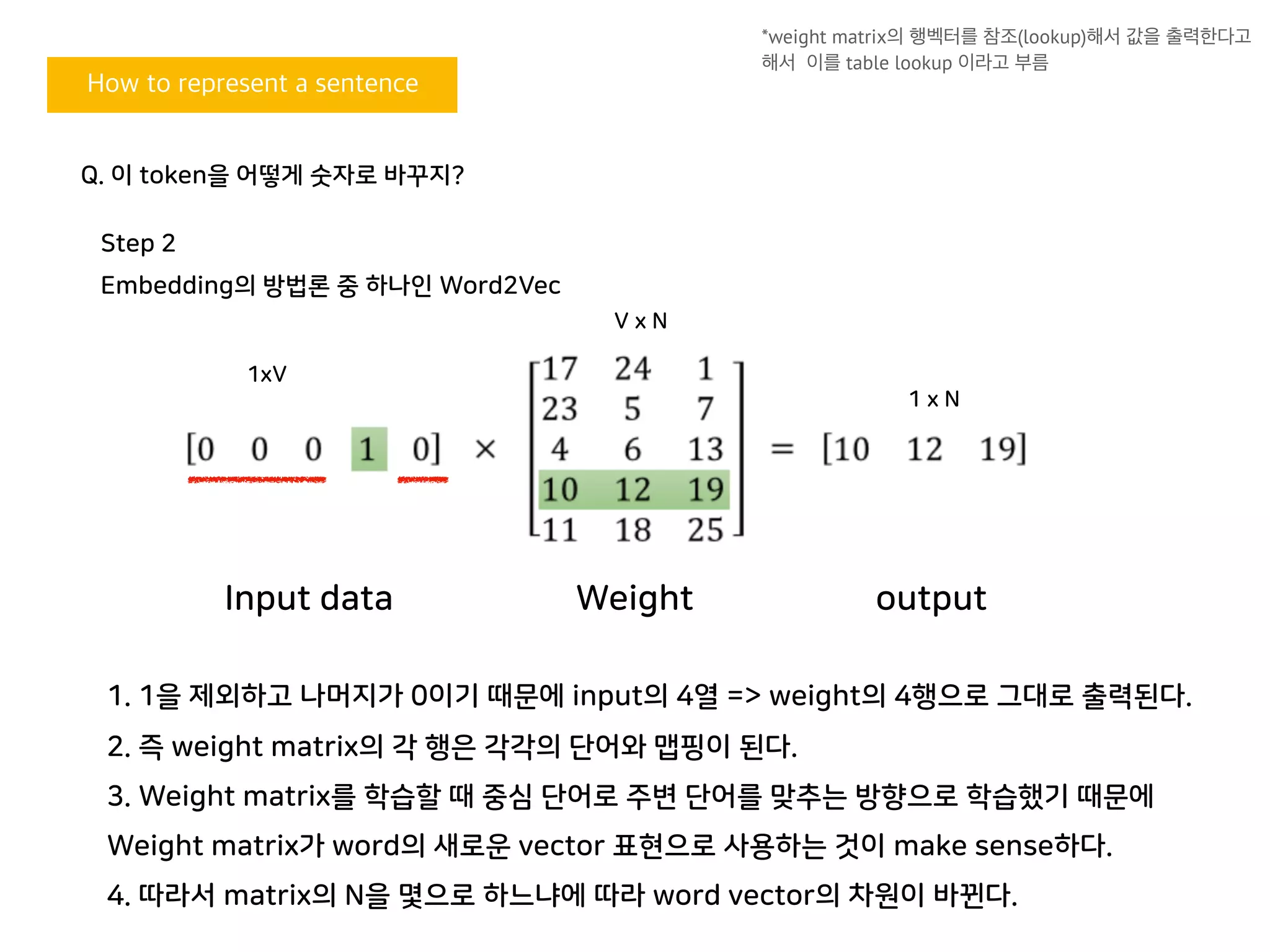
Input data Weight output
1. 1을 제외하고 나머지가 0이기 때문에 input의 4열 => weight의 4행으로 그대로 출력된다.
2. 즉 weight matrix의 각 행은 각각의 단어와 맵핑이 된다.
3. Weight matrix를 학습할 때 중심 단어로 주변 단어를 맞추는 방향으로 학습했기 때문에
Weight matrix가 word의 새로운 vector 표현으로 사용하는 것이 make sense하다.
4. 따라서 matrix의 N을 몇으로 하느냐에 따라 word vector의 차원이 바뀐다.
*weight matrix의 행벡터를 참조(lookup)해서 값을 출력한다고
해서 이를 table lookup 이라고 부름
1xV
V x N
1 x N
21.
Q. 궁금했던 것
1.한 가지 단어가 하나의 의미만을 갖는 게 아니다.
그런데 하나의 벡터로 표현을 해도 괜찮은 것인가?
How to represent a sentence
배에 타서, 나는 배를 먹었다.
- 타는 배든 먹는 배든 one-hot encoding은 동일, 학습할 때 output이 다를 뿐
- ‘배’라는 단어와 이웃을 보면서 가까이 있으면 유의미 하다고 학습되고 최종적으로 어떤 벡터(좌표)로 찍히는 것.
- 그 점 혼자만의 위치가 중요한 것이 아니라 주변 단어는 어디에 위치하냐가 중요하다.
- 학습을 하면서 최종적으로 ‘타서’와 ‘먹었다’라는 것이 ‘배’라는 단어와 가까운 위치에 있으며
- ‘타서’와 먹었다’는 멀게 찍히면서 그런 다의어가 해결된다고 함 (= 학습하면서 자동으로 다의어도 해결됨)
22.
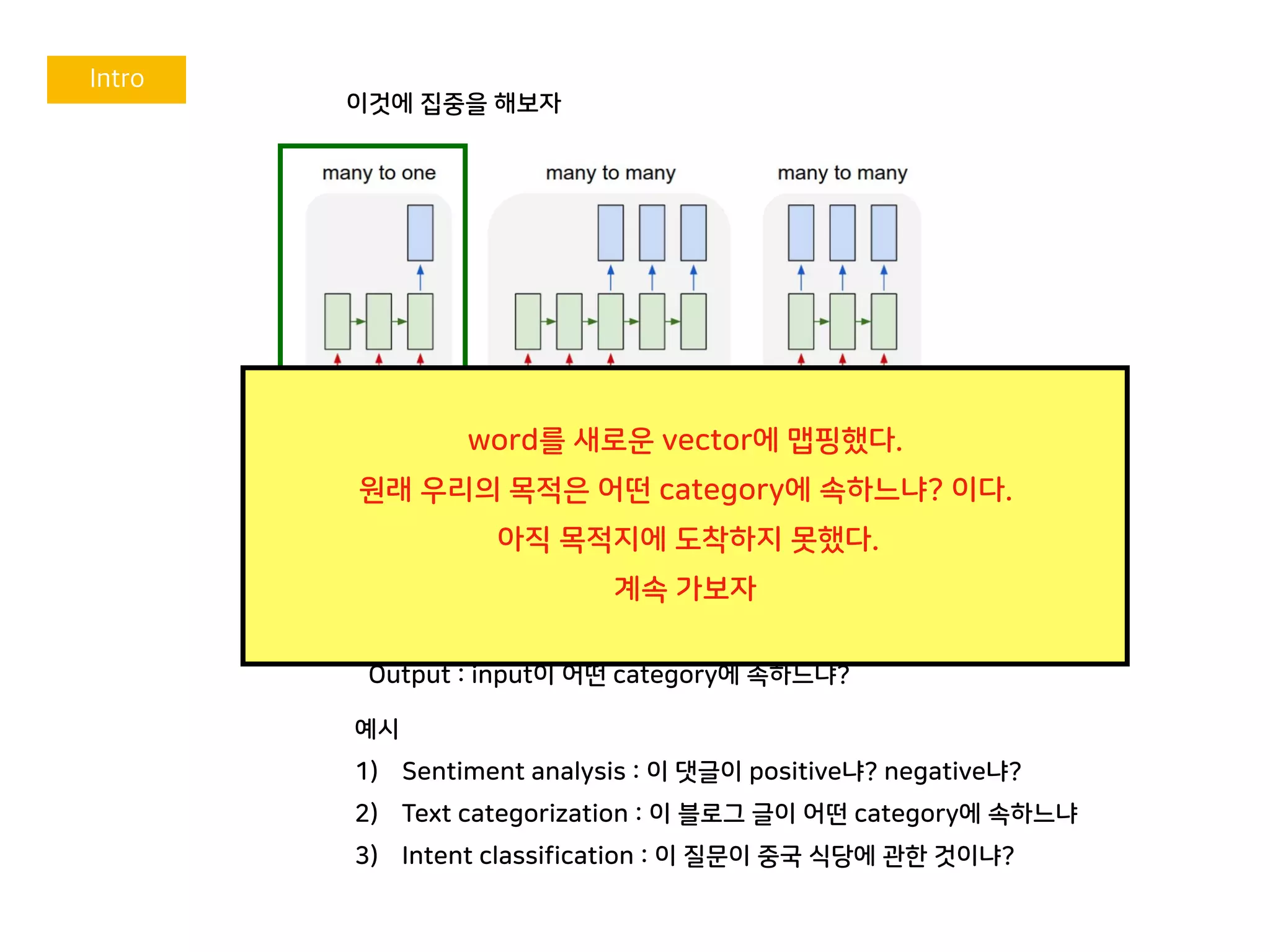
이것에 집중을 해보자
문장-> 문장 문장 -> 형태소문장 -> 단어
Input : natural language 문장 / paragraph
Output : input이 어떤 category에 속하느냐?
예시
1) Sentiment analysis : 이 댓글이 positive냐? negative냐?
2) Text categorization : 이 블로그 글이 어떤 category에 속하느냐
3) Intent classification : 이 질문이 중국 식당에 관한 것이냐?
Intro
word를 새로운 vector에 맵핑했다.
원래 우리의 목적은 어떤 category에 속하느냐? 이다.
아직 목적지에 도착하지 못했다.
계속 가보자
23.
How to representa sentence
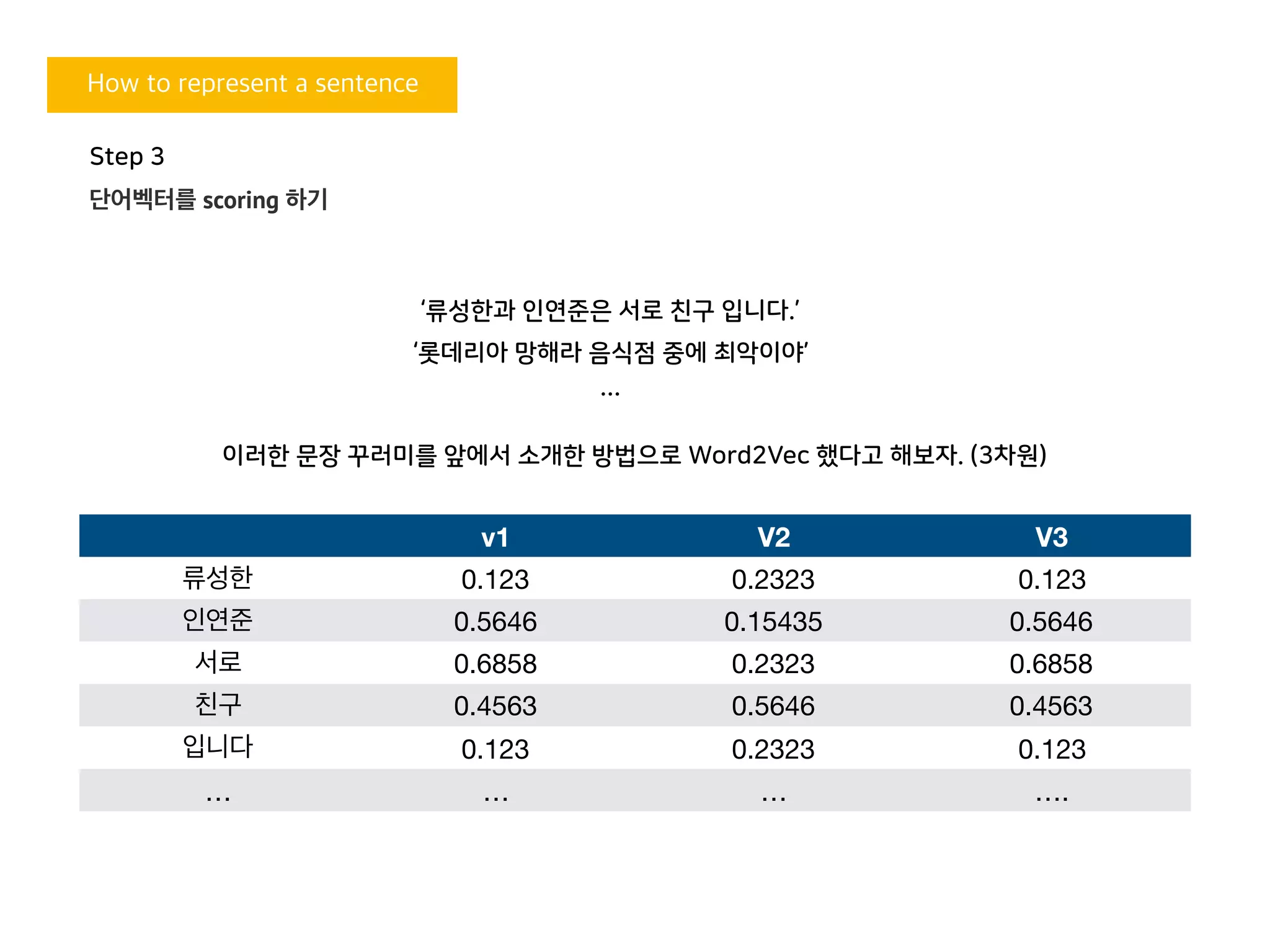
v1 V2 V3
류성한 0.123 0.2323 0.123
인연준 0.5646 0.15435 0.5646
서로 0.6858 0.2323 0.6858
친구 0.4563 0.5646 0.4563
입니다 0.123 0.2323 0.123
… … … ….
‘류성한과 인연준은 서로 친구 입니다.’
‘롯데리아 망해라 음식점 중에 최악이야’
…
이러한 문장 꾸러미를 앞에서 소개한 방법으로 Word2Vec 했다고 해보자. (3차원)
Step 3
단어벡터를 scoring 하기
24.
How to representa sentence
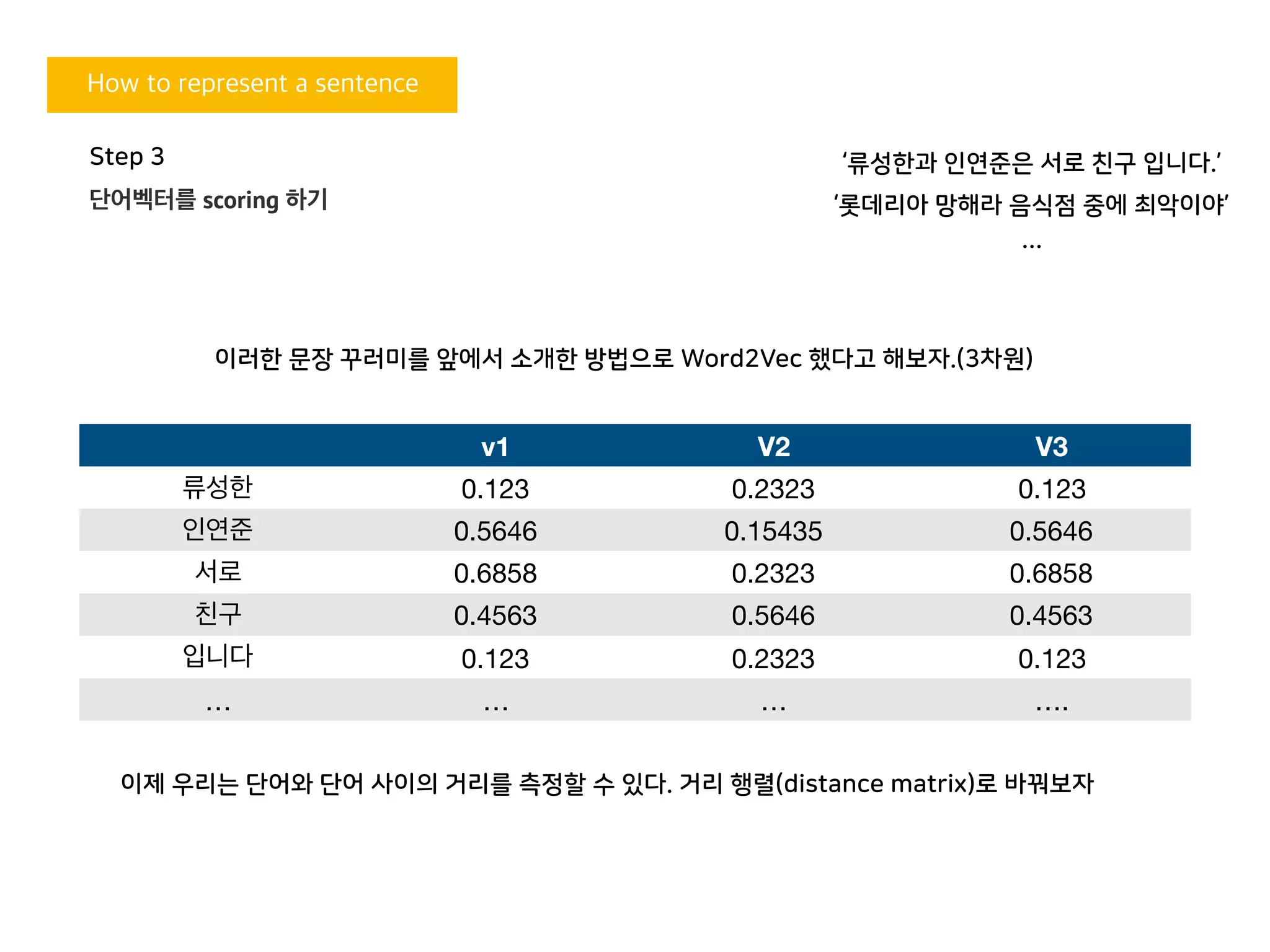
v1 V2 V3
류성한 0.123 0.2323 0.123
인연준 0.5646 0.15435 0.5646
서로 0.6858 0.2323 0.6858
친구 0.4563 0.5646 0.4563
입니다 0.123 0.2323 0.123
… … … ….
‘류성한과 인연준은 서로 친구 입니다.’
‘롯데리아 망해라 음식점 중에 최악이야’
…
이러한 문장 꾸러미를 앞에서 소개한 방법으로 Word2Vec 했다고 해보자.(3차원)
이제 우리는 단어와 단어 사이의 거리를 측정할 수 있다. 거리 행렬(distance matrix)로 바꿔보자
Step 3
단어벡터를 scoring 하기
25.
How to representa sentence
Step 3
단어벡터를 scoring 하기
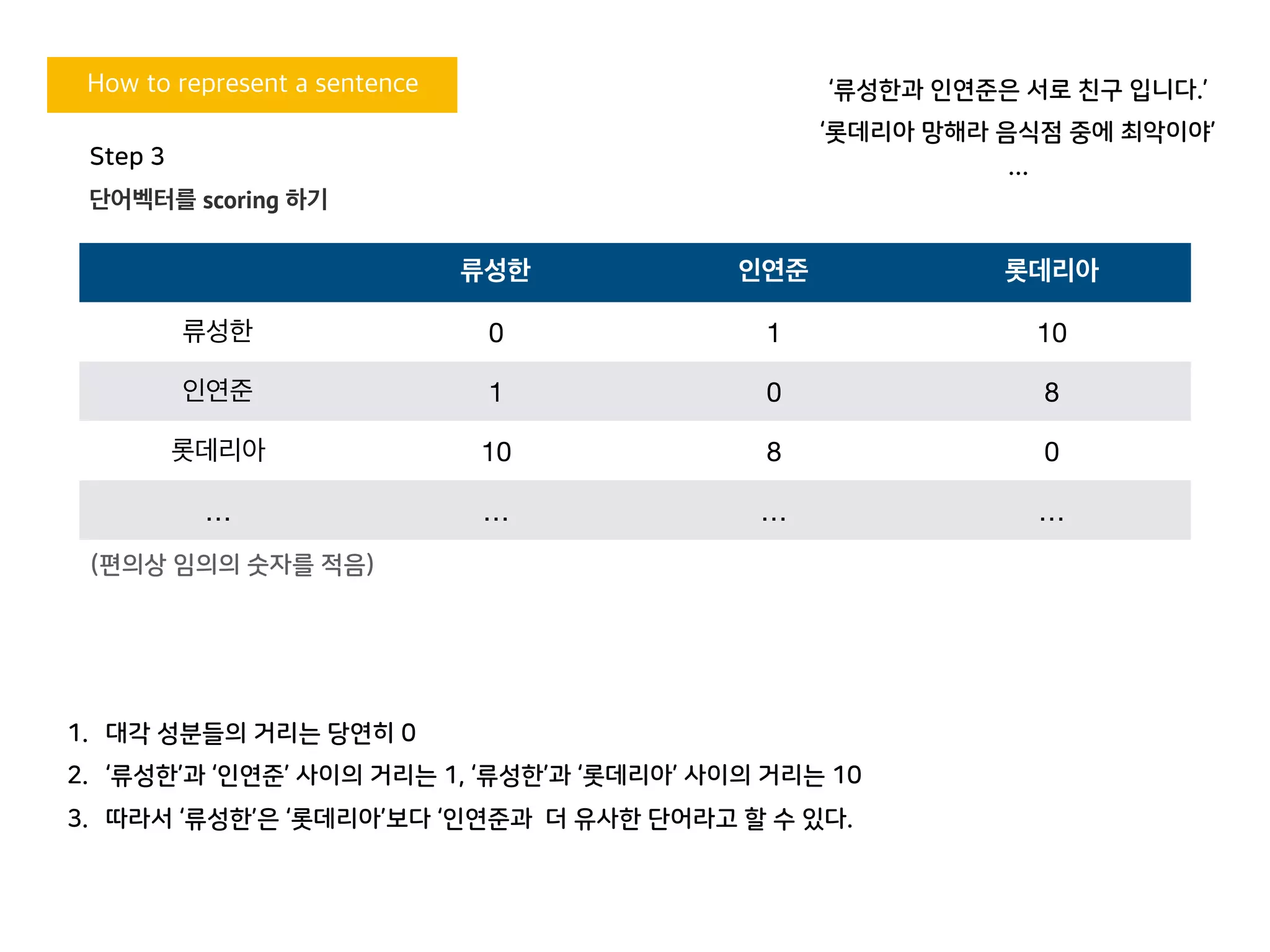
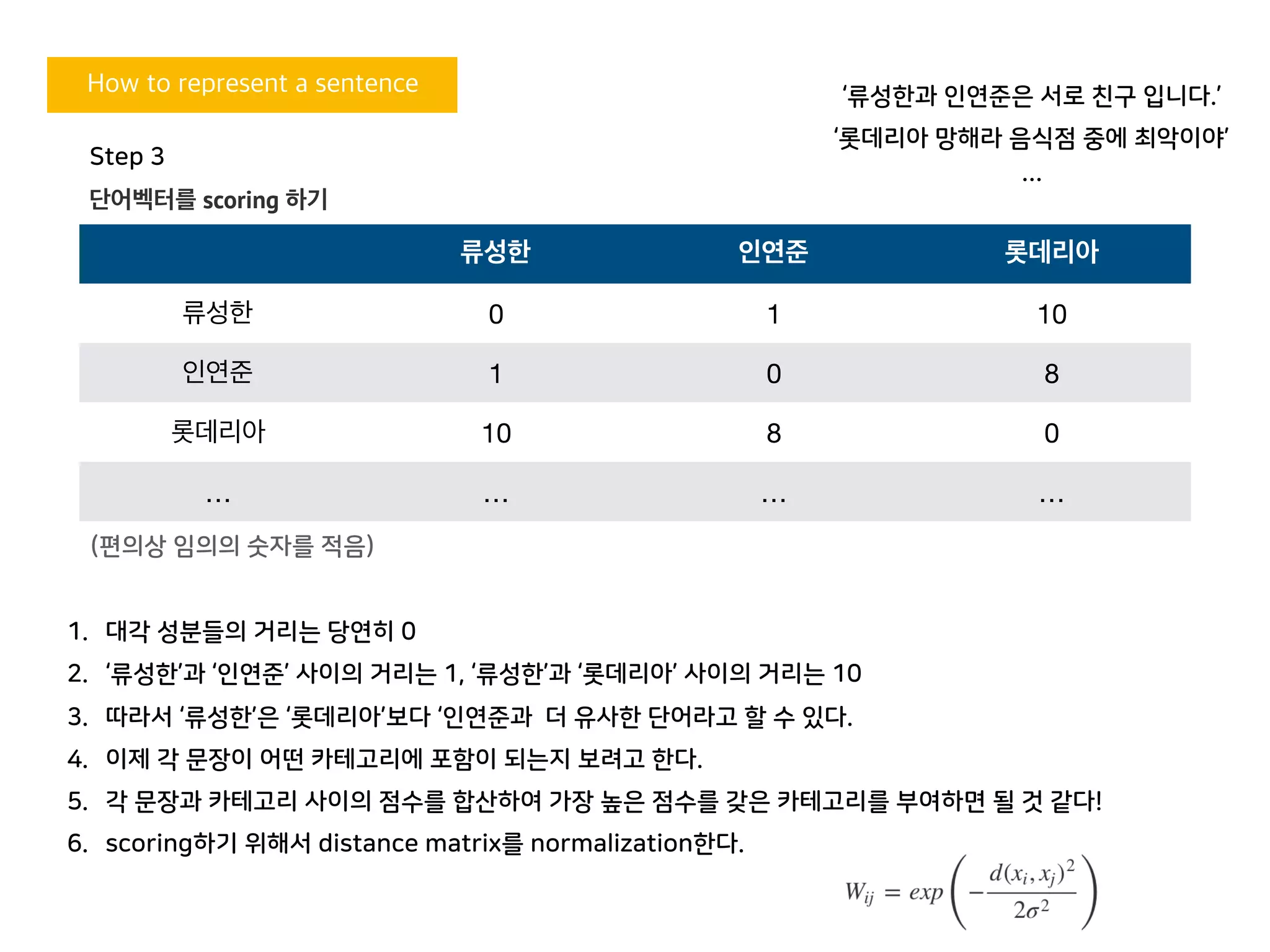
류성한 인연준 롯데리아
류성한 0 1 10
인연준 1 0 8
롯데리아 10 8 0
… … … …
‘류성한과 인연준은 서로 친구 입니다.’
‘롯데리아 망해라 음식점 중에 최악이야’
…
(편의상 임의의 숫자를 적음)
1. 대각 성분들의 거리는 당연히 0
2. ‘류성한’과 ‘인연준’ 사이의 거리는 1, ‘류성한’과 ‘롯데리아’ 사이의 거리는 10
3. 따라서 ‘류성한’은 ‘롯데리아’보다 ‘인연준과 더 유사한 단어라고 할 수 있다.
26.
How to representa sentence
Step 3
단어벡터를 scoring 하기
류성한 인연준 롯데리아
류성한 0 1 10
인연준 1 0 8
롯데리아 10 8 0
… … … …
‘류성한과 인연준은 서로 친구 입니다.’
‘롯데리아 망해라 음식점 중에 최악이야’
…
(편의상 임의의 숫자를 적음)
1. 대각 성분들의 거리는 당연히 0
2. ‘류성한’과 ‘인연준’ 사이의 거리는 1, ‘류성한’과 ‘롯데리아’ 사이의 거리는 10
3. 따라서 ‘류성한’은 ‘롯데리아’보다 ‘인연준과 더 유사한 단어라고 할 수 있다.
4. 이제 각 문장이 어떤 카테고리에 포함이 되는지 보려고 한다.
5. 각 문장과 카테고리 사이의 점수를 합산하여 가장 높은 점수를 갖은 카테고리를 부여하면 될 것 같다!
6. scoring하기 위해서 distance matrix를 normalization한다.
27.
How to representa sentence
Step 3
단어벡터를 scoring 하기
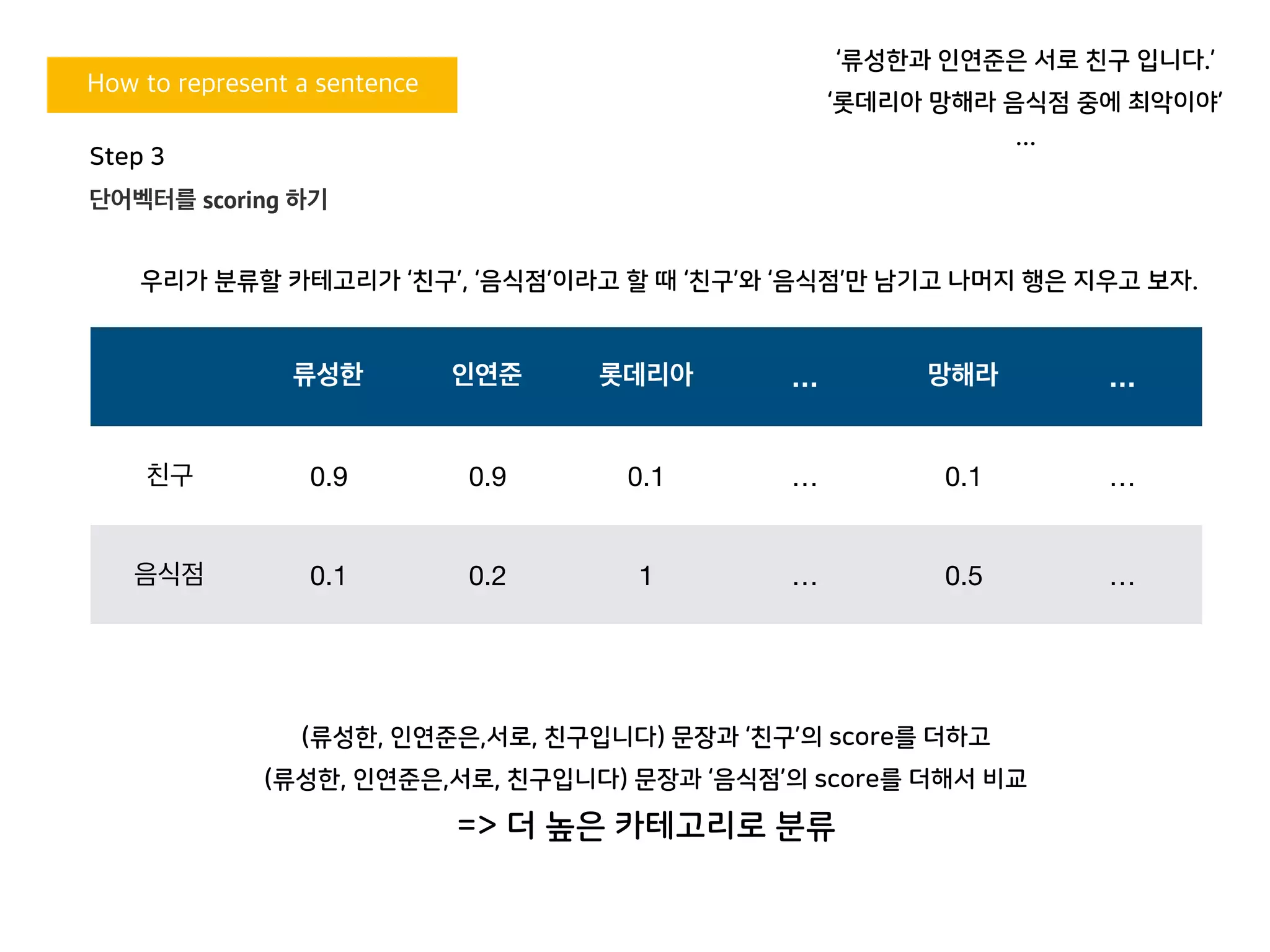
류성한 인연준 롯데리아 … 망해라 …
친구 0.9 0.9 0.1 … 0.1 …
음식점 0.1 0.2 1 … 0.5 …
‘류성한과 인연준은 서로 친구 입니다.’
‘롯데리아 망해라 음식점 중에 최악이야’
…
(류성한, 인연준은,서로, 친구입니다) 문장과 ‘친구’의 score를 더하고
(류성한, 인연준은,서로, 친구입니다) 문장과 ‘음식점’의 score를 더해서 비교
=> 더 높은 카테고리로 분류
우리가 분류할 카테고리가 ‘친구’, ‘음식점’이라고 할 때 ‘친구’와 ‘음식점’만 남기고 나머지 행은 지우고 보자.
28.
How to representa sentence
Question
내가 정하고 싶은 카테고리가 우리의 문장속에 없어서
학습이 되지 않았더라면 카테고리 분류를 하지 못하는 것인가?
그럴 때는 어떻게 하지?
≂ 카테고리 키워드에 해당하는 단어가 아니더라도 어찌됐든 새로운 단어가 나타나면?
1. 새로운 단어를 쓰는 문장을 input data로 추가해서 다시 트레이닝 하는 수밖에..
2. 같은 의미인데 다른 형태를 가진게 있다면 적절한 form으로 바꿔 준다. (ex. We're -> we are)
몇 가지 사항들
29.
How to representa sentence
Question
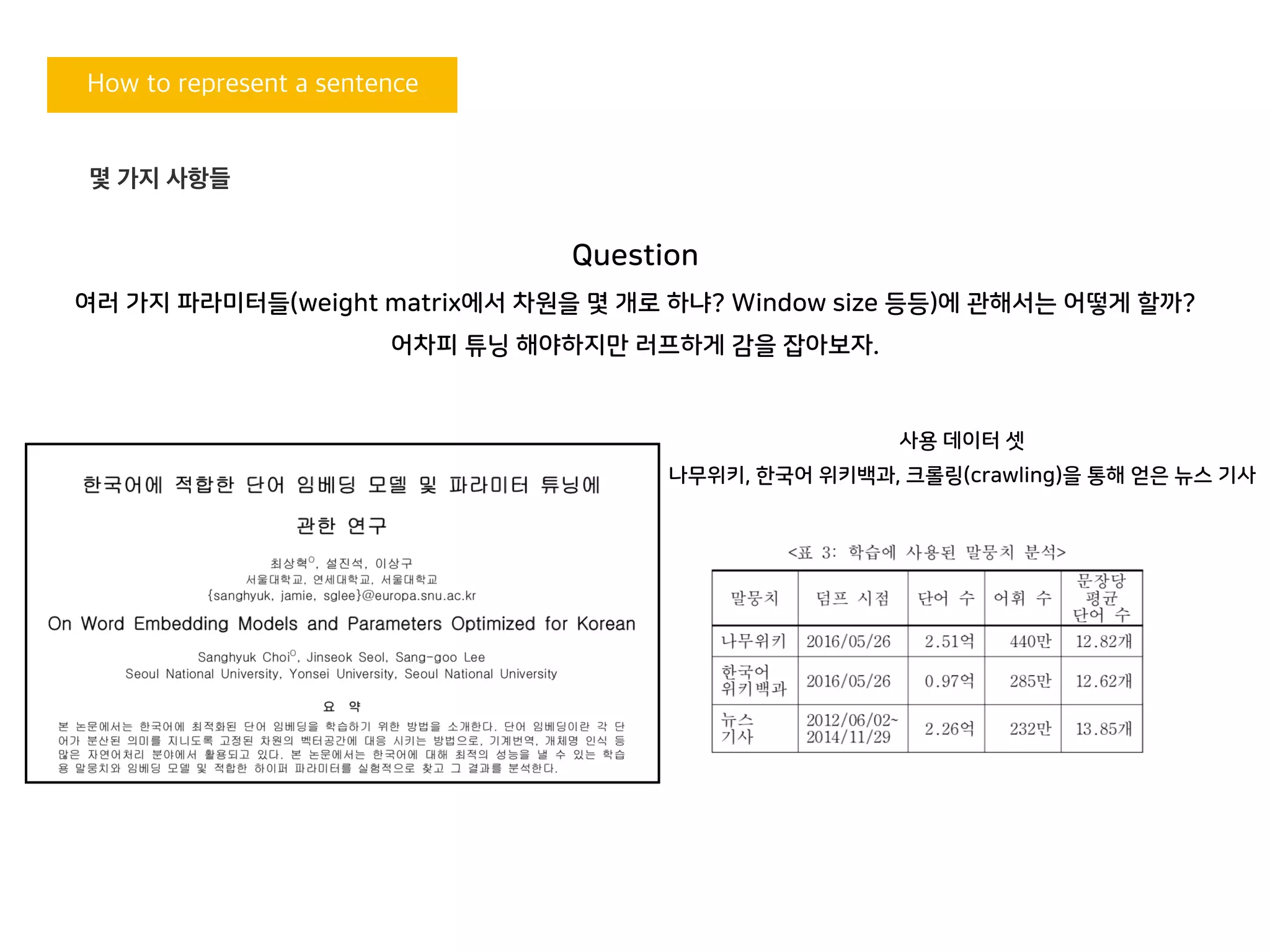
여러 가지 파라미터들(weight matrix에서 차원을 몇 개로 하냐? Window size 등등)에 관해서는 어떻게 할까?
어차피 튜닝 해야하지만 러프하게 감을 잡아보자.
몇 가지 사항들
사용 데이터 셋
나무위키, 한국어 위키백과, 크롤링(crawling)을 통해 얻은 뉴스 기사
30.
How to representa sentence
몇 가지 사항들
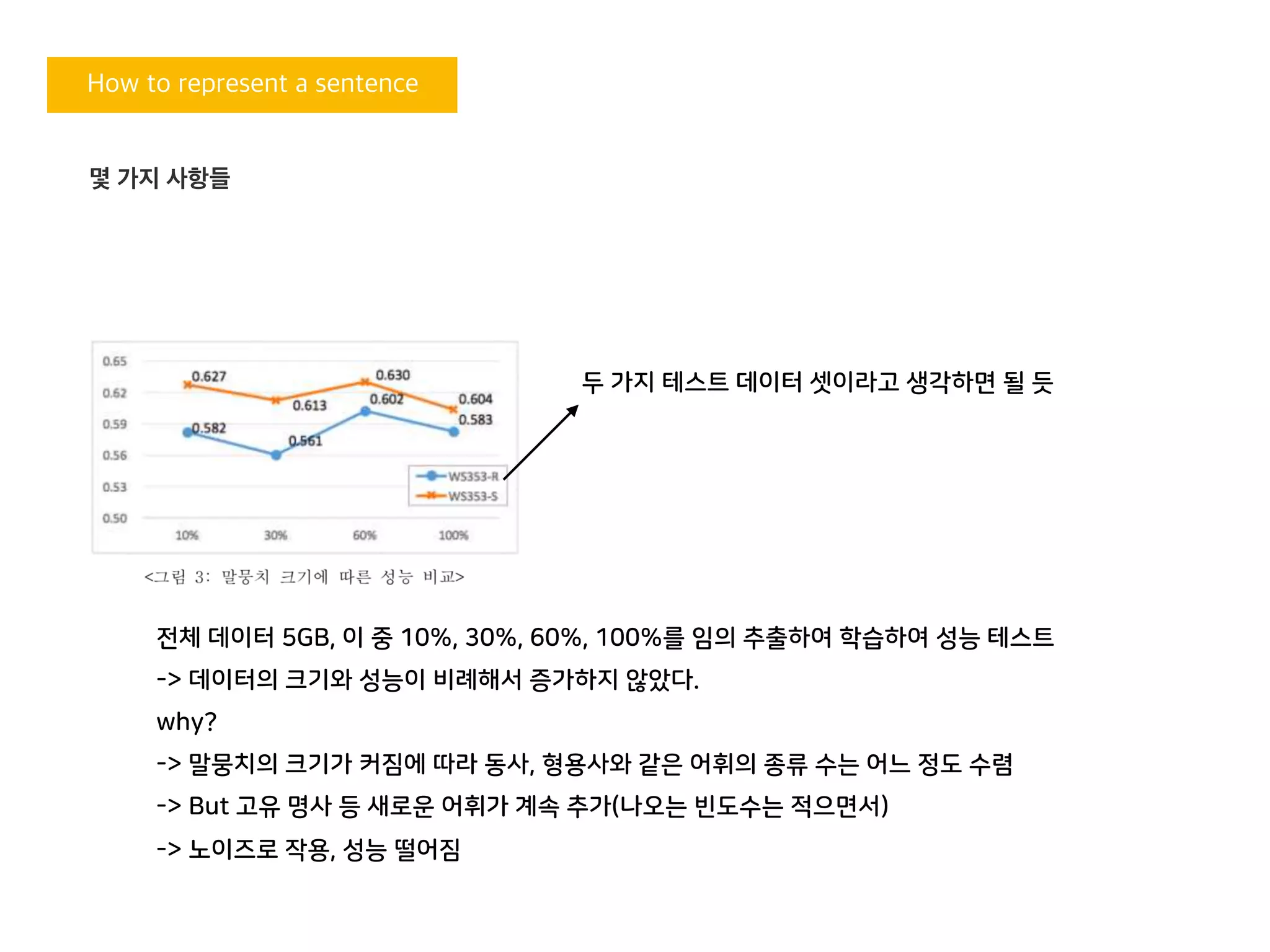
두 가지 테스트 데이터 셋이라고 생각하면 될 듯
전체 데이터 5GB, 이 중 10%, 30%, 60%, 100%를 임의 추출하여 학습하여 성능 테스트
-> 데이터의 크기와 성능이 비례해서 증가하지 않았다.
why?
-> 말뭉치의 크기가 커짐에 따라 동사, 형용사와 같은 어휘의 종류 수는 어느 정도 수렴
-> But 고유 명사 등 새로운 어휘가 계속 추가(나오는 빈도수는 적으면서)
-> 노이즈로 작용, 성능 떨어짐
31.
How to representa sentence
몇 가지 사항들
* Word2Vec에는 Skip-Gram방식과 CBOW(Continuous Bag of Words) 방식이 있다. CBOW는 주변 단어로 중심 단어를 맞추는 방식이다.
앞서 설명한 것(중심 단어로 주변 단어 예측)은 Skip-Gram 방식이다. 요즘은 전부 skip-gram사용
논문 왈 : 영어는 skip-gram이 더 좋은 걸로 알려졌는데 한국어는 막 차이나지는 않네;;
32.
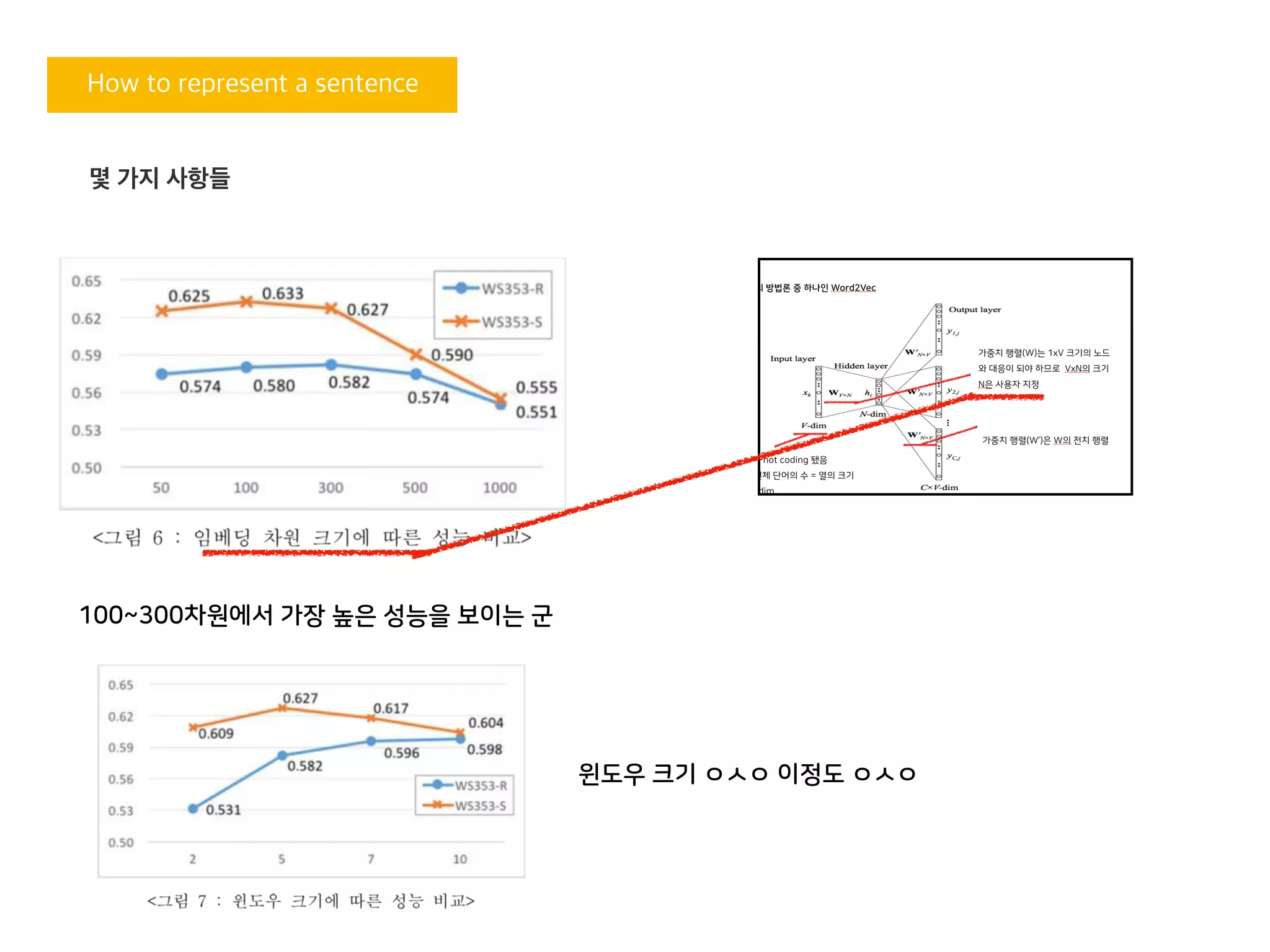
How to representa sentence
몇 가지 사항들
100~300차원에서 가장 높은 성능을 보이는 군
윈도우 크기 ㅇㅅㅇ 이정도 ㅇㅅㅇ
33.
How to representa sentence
그런데
이 방법이 최선 인가?
처음으로 키노트로 피피티를 만들어서 신난 류성한
34.
How to representa sentence
2. Convolutional Networks [2015]
일반적으로 쓰이는 CNN 구조임. 들어가는 input data를 Word2Vector 값을 넣어준 것만 다르다.
그런데 논문에서 여기서 추가적인 작업을 해봄
35.
How to representa sentence
1. Non-static : word2vector까지 학습 시킨다.
2. Static : 개소리하지마라 word2vector는 고정된 값이다.
3. Multichannel : 둘의 결과를 짬뽕해보겠다.
2. Convolutional Networks [2015]
36.
How to representa sentence
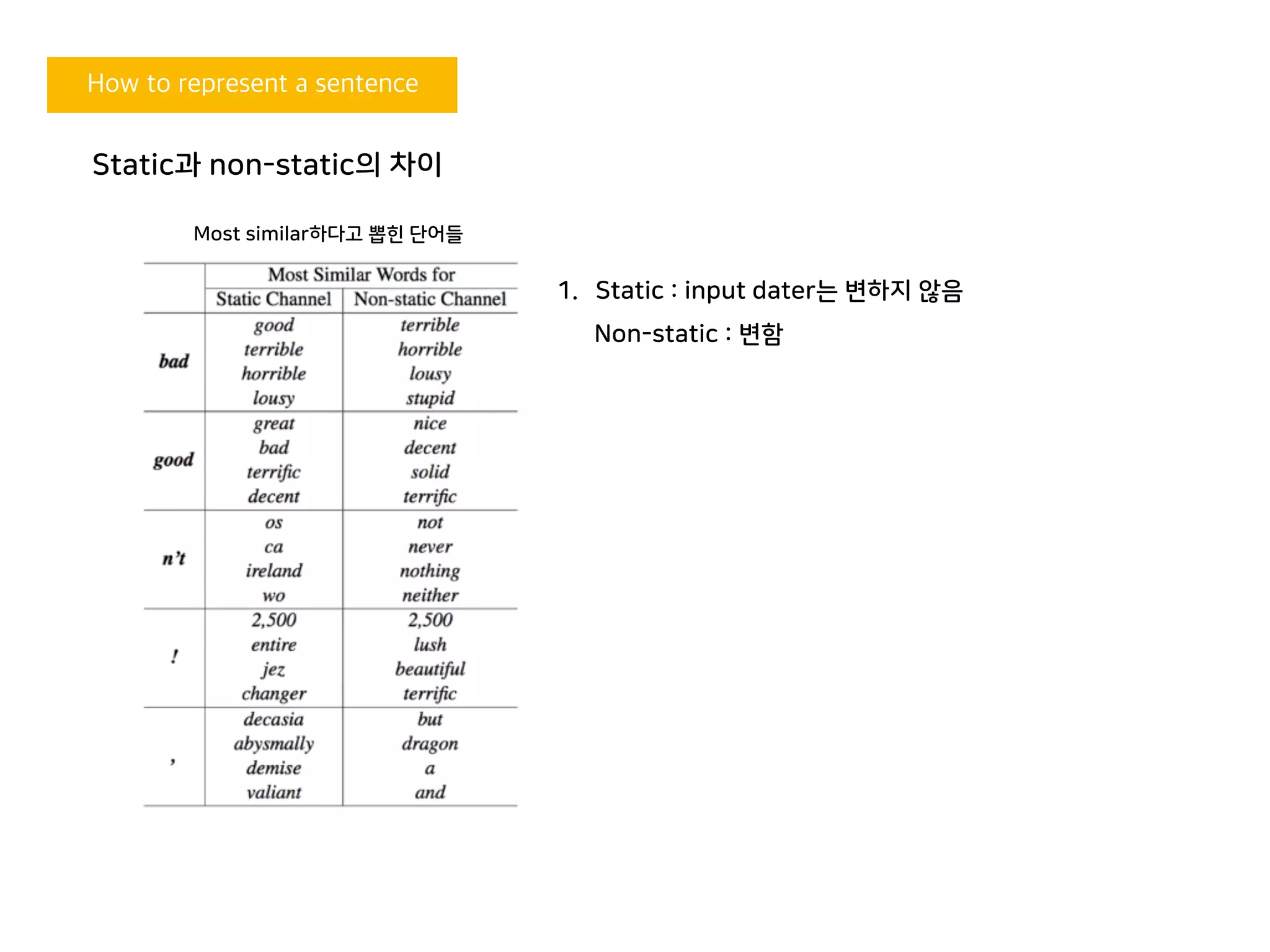
Static과 non-static의 차이
Most similar하다고 뽑힌 단어들
1. Static : input dater는 변하지 않음
Non-static : 변함
37.
How to representa sentence
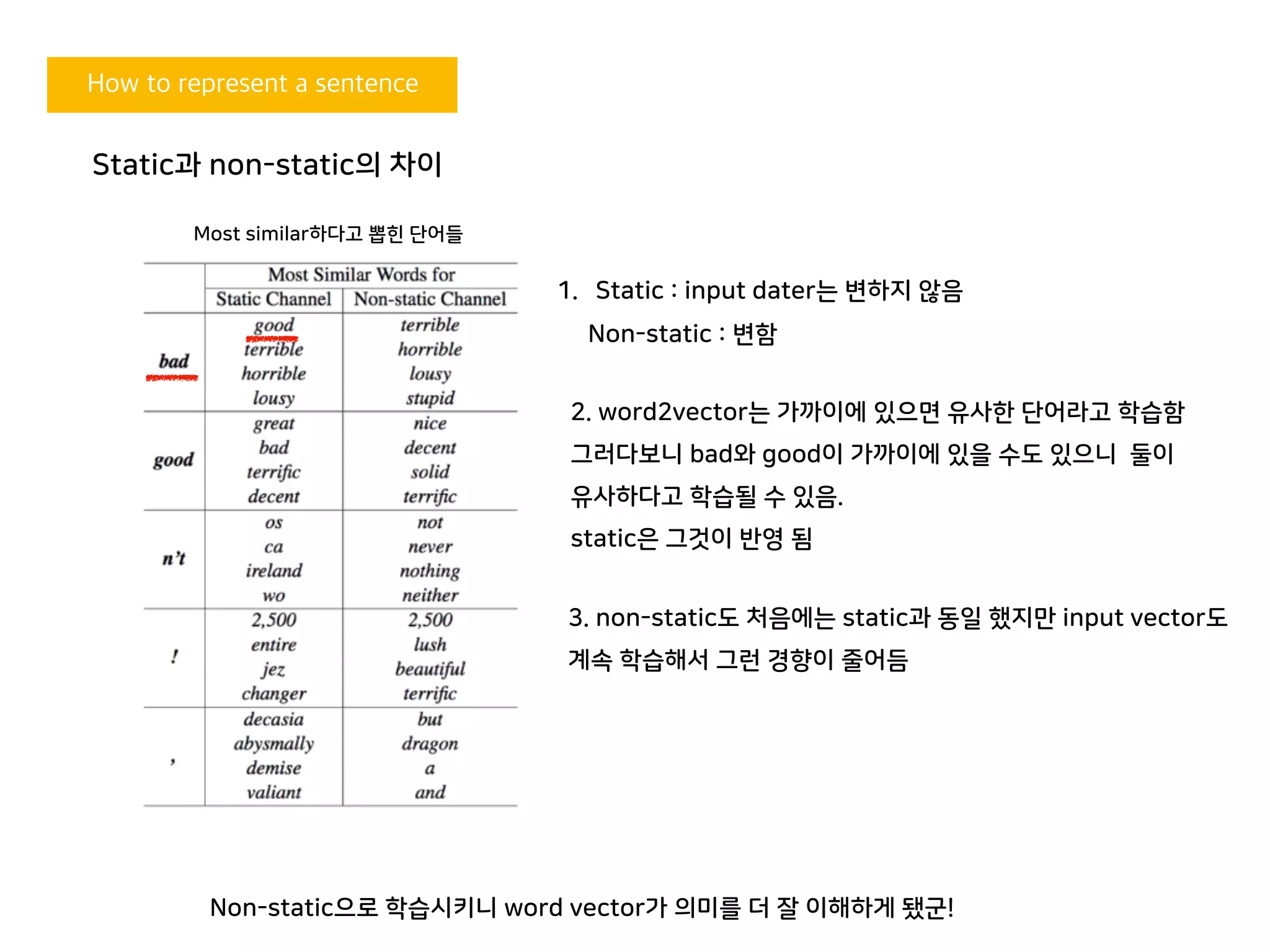
Static과 non-static의 차이
Non-static으로 학습시키니 word vector가 의미를 더 잘 이해하게 됐군!
2. word2vector는 가까이에 있으면 유사한 단어라고 학습함
그러다보니 bad와 good이 가까이에 있을 수도 있으니 둘이
유사하다고 학습될 수 있음.
static은 그것이 반영 됨
Most similar하다고 뽑힌 단어들
1. Static : input dater는 변하지 않음
Non-static : 변함
3. non-static도 처음에는 static과 동일 했지만 input vector도
계속 학습해서 그런 경향이 줄어듬
38.
How to representa sentence
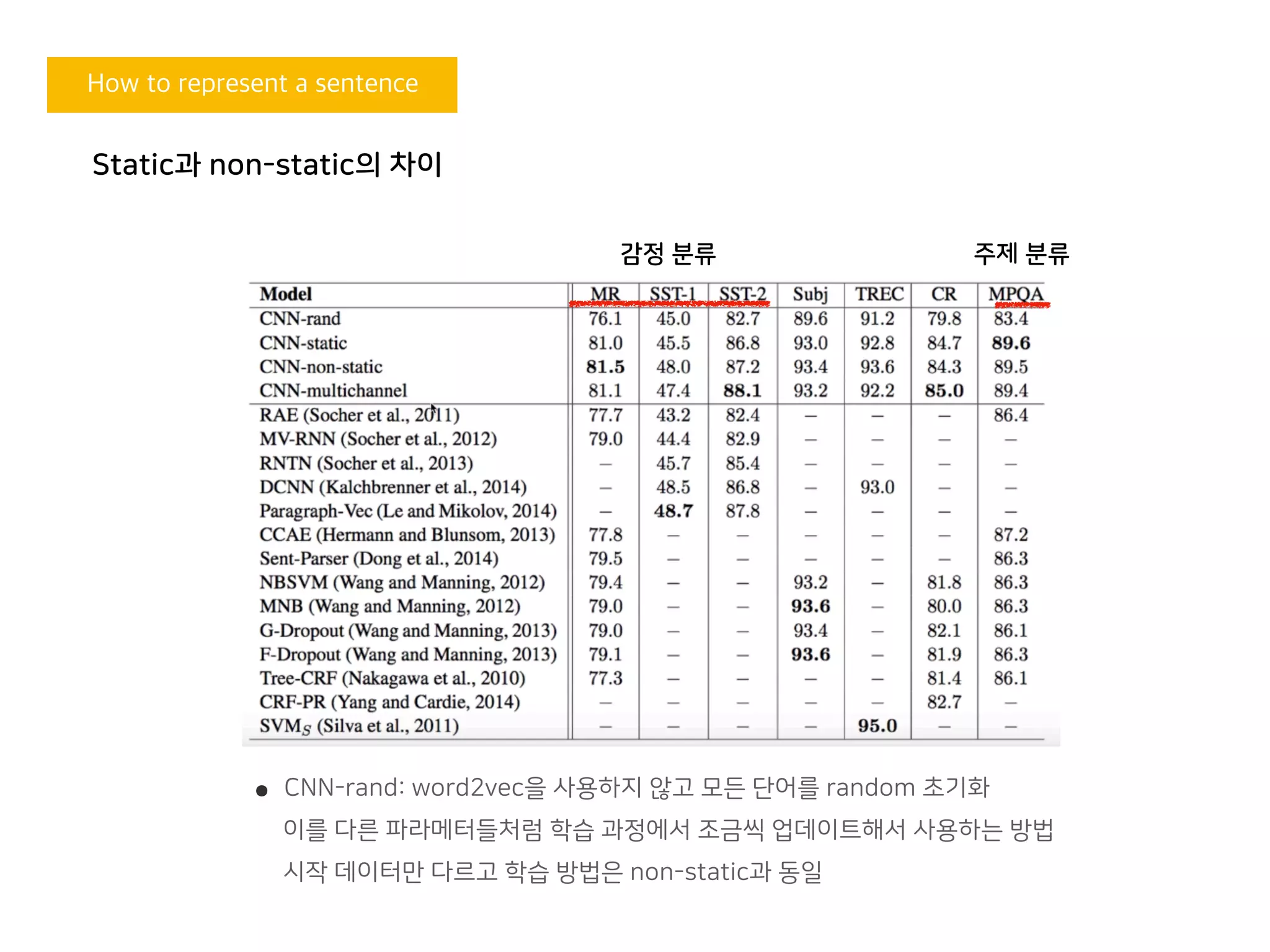
Static과 non-static의 차이
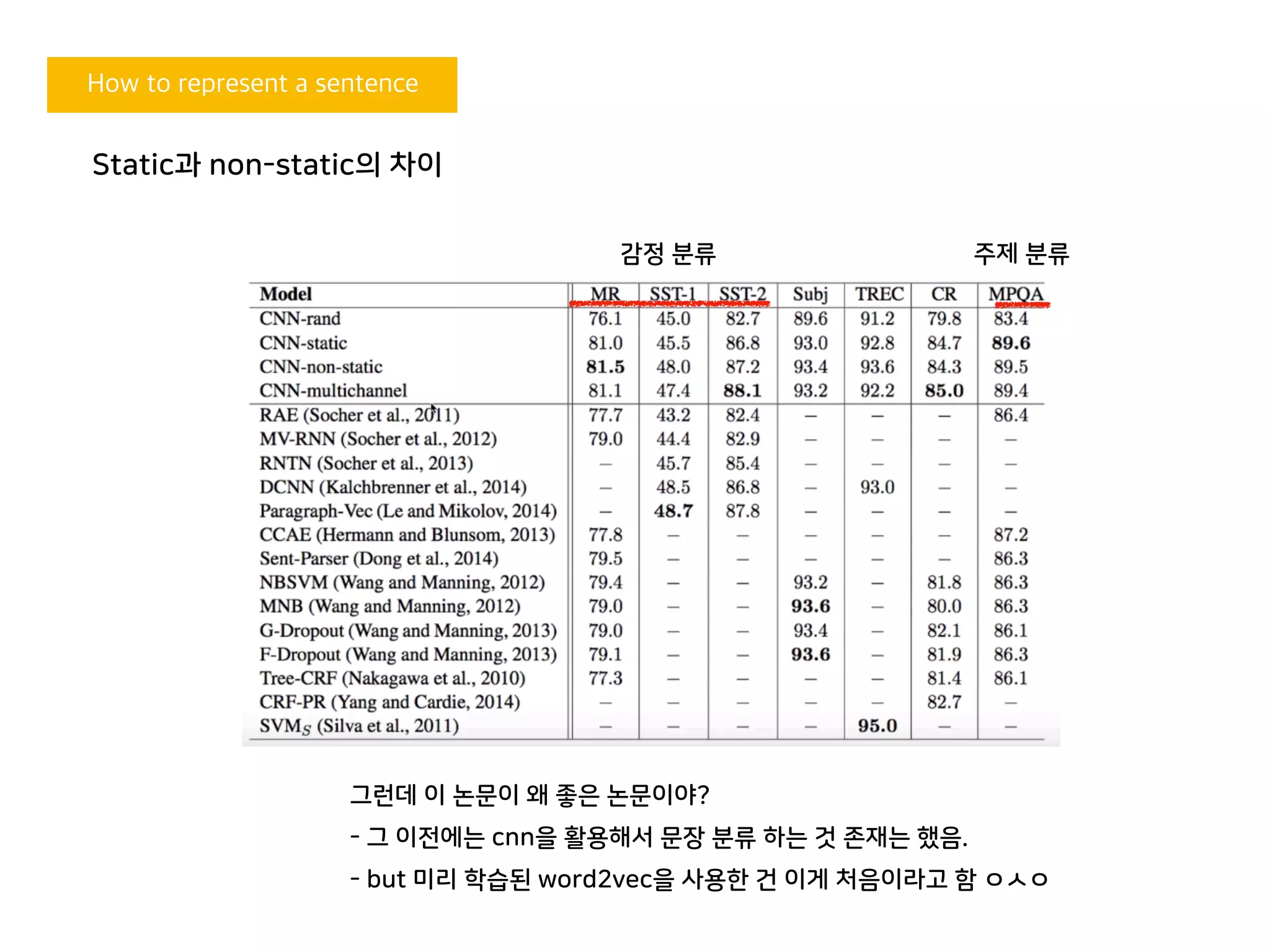
감정 분류 주제 분류
• CNN-rand: word2vec을 사용하지 않고 모든 단어를 random 초기화
이를 다른 파라메터들처럼 학습 과정에서 조금씩 업데이트해서 사용하는 방법
시작 데이터만 다르고 학습 방법은 non-static과 동일
39.
How to representa sentence
Static과 non-static의 차이
감정 분류 주제 분류
그런데 이 논문이 왜 좋은 논문이야?
- 그 이전에는 cnn을 활용해서 문장 분류 하는 것 존재는 했음.
- but 미리 학습된 word2vec을 사용한 건 이게 처음이라고 함 ㅇㅅㅇ
40.
How to representa sentence
단점 : 아주 멀리 떨어져 있는 단어 사이에 유의미한 관계가 있을 때는?
- layer를 계속 쌓다보면 그 관계 또한 포착할 수 있겠다!
- 하지만 언제까지! 얼마나 쌓아! 어렵 ㅋ
- 다른 방법 없나? => self-attention! (2017년)이라는 게 또 나옴
- 계속 발전하는 nlp
2. Convolutional Networks [2015]
성한 연준












![How to represent a sentence
2. Convolutional Networks [2015]
일반적으로 쓰이는 CNN 구조임. 들어가는 input data를 Word2Vector 값을 넣어준 것만 다르다.
그런데 논문에서 여기서 추가적인 작업을 해봄](https://image.slidesharecdn.com/nlp-final-190407061120/75/Natural-Language-Processing-NLP-Basic-34-2048.jpg)
![How to represent a sentence
1. Non-static : word2vector까지 학습 시킨다.
2. Static : 개소리하지마라 word2vector는 고정된 값이다.
3. Multichannel : 둘의 결과를 짬뽕해보겠다.
2. Convolutional Networks [2015]](https://image.slidesharecdn.com/nlp-final-190407061120/75/Natural-Language-Processing-NLP-Basic-35-2048.jpg)
![How to represent a sentence
단점 : 아주 멀리 떨어져 있는 단어 사이에 유의미한 관계가 있을 때는?
- layer를 계속 쌓다보면 그 관계 또한 포착할 수 있겠다!
- 하지만 언제까지! 얼마나 쌓아! 어렵 ㅋ
- 다른 방법 없나? => self-attention! (2017년)이라는 게 또 나옴
- 계속 발전하는 nlp
2. Convolutional Networks [2015]
성한 연준](https://image.slidesharecdn.com/nlp-final-190407061120/75/Natural-Language-Processing-NLP-Basic-40-2048.jpg)


![[싸이그램즈 2018] 텍스트 데이터 전처리로 시작하는 NLP](https://cdn.slidesharecdn.com/ss_thumbnails/psygramsnlp101-180704045500-thumbnail.jpg?width=640&height=640&fit=bounds)





![[F2]자연어처리를 위한 기계학습 소개](https://cdn.slidesharecdn.com/ss_thumbnails/f2-120919022113-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[study] character aware neural language models](https://cdn.slidesharecdn.com/ss_thumbnails/181114characterawareneurallanguagemodels-190321063423-thumbnail.jpg?width=640&height=640&fit=bounds)



















