Probability for Machinelearning
MinGuk Kang
July 18, 2018
first287@naver.com
사진: https://medium.com/@startuphackers/building-a-deep-learning-neural-network-startup-7032932e09c 1
4
1. Maximum LikelihoodEstimation
1. Likelihood 란?
사진: https://wikidocs.net/9088
동전을 던지는 Bernoulli 시행을 예로 들면,
Probability 𝐩(𝐦 ; 𝒏, 𝒑) 는 시행할 횟수(n)과 성공확률 (p)가 모수(Parameter)로 주어지고, 성공 횟수(m)가
Random Variable일 때, 사건이 일어날 가능성이고,
Likelihood 𝓛(𝒑 |𝒏, 𝒎) 는 성공한 횟수(m)와 시행한 횟수(n)가 모수(Parameter)로 주어지고,
성공할 확률이 Random Variable일 때, 이러한 사건이 일어날 가능성을 일컬는다.
5.
5
1. Maximum LikelihoodEstimation
2. Maximum Likelihood Estimation 란?
최대우도추정이란 모수(Parameter)가 미지의 𝜃인 확률분포에서 뽑은 표본(관측치)𝑥들을 바탕으로 𝜃를 추정하는 기법입니다.
여기에서 우도(Likelihood)란 이미 주어진 표본 𝑥들에 비추어 봤을 때 모집단의 모수 𝜃에 대한 추정이 그럴듯한 정도를 가르키는데,
우도 ℒ 𝜃 𝑥 는 𝜃가 전제되었을 때 표본 𝑥가 등장할 확률인 𝑝(𝑥|𝜃)에 비례한다.
https://ratsgo.github.io/statistics/2017/09/23/MLE/
6.
6
1. Maximum LikelihoodEstimation
최대우도추정이란 모수(Parameter)가 미지의 𝜃인 확률분포에서 뽑은 표본(관측치)𝑥들을 바탕으로 𝜃를 추정하는 기법입니다.
여기에서 우도(Likelihood)란 이미 주어진 표본 𝑥들에 비추어 봤을 때 모집단의 모수 𝜃에 대한 추정이 그럴듯한 정도를 가르키는데,
우도 ℒ 𝜃 𝑥 는 𝜃가 전제되었을 때 표본 𝑥가 등장할 확률인 𝑝(𝑥|𝜃)에 비례한다.
→ 우도에 관한 식을 세운 후, 미분 또는 Gradient Descent Algorithm을 사용하여 최대 우도를 만드는 Parameter를 찾아준다.
2. Maximum Likelihood Estimation 란?
https://ratsgo.github.io/statistics/2017/09/23/MLE/
7.
7
최대우도추정이란 모수(Parameter)가 미지의𝜃인 확률분포에서 뽑은 표본(관측치)𝑥들을 바탕으로 𝜃를 추정하는 기법입니다.
여기에서 우도(Likelihood)란 이미 주어진 표본 𝑥들에 비추어 봤을 때 모집단의 모수 𝜃에 대한 추정이 그럴듯한 정도를 가르키는데,
우도 ℒ 𝜃 𝑥 는 𝜃가 전제되었을 때 표본 𝑥가 등장할 확률인 𝑝(𝑥|𝜃)에 비례한다.
→ 우도에 관한 식을 세운 후, 미분 또는 Gradient Descent Algorithm을 사용하여 최대 우도를 만드는 Parameter를 찾아준다.
Equation : 𝜃∗
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝜃 𝐿 𝜃
∴
𝜕𝐿 𝜃
𝜕𝜃
= 0 인 𝜃를 찾아주면 𝜃∗
가 된다.
1. Maximum Likelihood Estimation
2. Maximum Likelihood Estimation 란?
https://ratsgo.github.io/statistics/2017/09/23/MLE/
9
2. Maximum APosteriori Estimation
1. Maximum A Posteriori Estimation 이란?
Bayes’s Theorem 은 다음과 같다.
𝑝 𝑦 𝑥 =
𝑝(𝑥|𝑦) × 𝑝(𝑦)
𝑝(𝑥)
Posterior =
Likelihood × Prior
Normalization Term
10.
10
1. Maximum APosteriori Estimation 이란?
2. Maximum A Posteriori Estimation
Bayes’s Theorem 은 다음과 같다.
𝑝 𝑦 𝑥 =
𝑝(𝑥|𝑦) × 𝑝(𝑦)
𝑝(𝑥)
Posterior =
Likelihood × Prior
Normalization Term
위의 베이즈 공식을 이용하여 우도를 사후확률로 바꾸어,
사후확률이 최댓값을 가지게 되는 Parameter를 찾는 방법을 MAP라고 한다.
11.
11
2. Maximum APosteriori Estimation
2. MLE vs MAP
MLE의 경우, 모수(Parameter)를 결정하기 위해 사전정보(Prior)를 사용하지 않는다.
따라서 새로운 정보에 대한 일반화 성능이 좋지 못하다.
MAP의 경우, 모수(Parameter)를 결정하기 위해 사전정보(Prior)를 사용한다.
따라서 새로운 정보에 대한 일반화 성능이 좋지만, 잘못된 사전정보를 사용할 시 MLE보다 나쁜 결과를 얻을 수 도 있다.
13
3. Naïve BayesClassifier
1. Naïve Bayes Classifier
총 10개의 Label을 가진 필기체 분류(MNIST) 문제를 해결해야 한다고 생각하면 Function Approximation관점에서 다음과 같이 요약 가능하다.
𝑓∗
= 𝑎𝑟𝑔𝑚𝑖𝑛 𝑓 𝑝(𝑓 𝑋 ≠ 𝑌)
하지만, 적절한 라벨을 찾는다는 관점에서는 아래와 같은 수식으로 요약가능하다.
𝑌∗
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝑘∈{0,1,2,…9} 𝑝(𝑌𝑘|𝑋)
14.
14
3. Naïve BayesClassifier
1. Naïve Bayes Classifier
𝑌∗
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝑘∈{0,1,2,…,9} 𝑝 𝑌𝑘 𝑋
위의 식을 계산하기 위해 Bayes Theorem을 적용하면, 𝑌∗
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝑘∈{0,1,2,…9} 𝑝 𝑋 𝑌𝑘 × 𝑝 𝑌𝑘 이다.
MNIST 데이터의 경우 768차원의 데이터이므로, 위의 식은 아래와 같이 정리할 수 있다.
𝑌∗
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝑘∈{0,1,2,…9} 𝑝 𝑋1 = 𝑥1, 𝑋2 = 𝑥2, 𝑋3 = 𝑥3, … , 𝑋768 = 𝑥768 𝑌𝑘 × 𝑝 𝑌𝑘
15.
15
3. Naïve BayesClassifier
1. Naïve Bayes Classifier
𝑌∗
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝑘∈{0,1,2,…9} 𝑝 𝑋1 = 𝑥1, 𝑋2 = 𝑥2, 𝑋3 = 𝑥3, … , 𝑋768 = 𝑥768 𝑌𝑘 × 𝑝 𝑌𝑘
위의 식은 Intractable하기에 계산을 편하게 만들어 줄 필요가 있다.
따라서, 비록 정확하지는 않겠지만 순진하게(Naïve) 위 식에 Conditional Independence Assumption를 적용하여 정리하면 다음과 같다.
𝑌∗
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝑘∈{0,1,2,…9} 𝑖=1
768
𝑝(𝑋𝑖|𝑌𝑘) × 𝑝 𝑌𝑘
마지막으로 곱셈항을 더욱 효율적으로 다루기 위해 log를 씌워주면 다음과 같고 이를 Naïve Bayes Classifier라고 한다.
𝑌∗
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝑘∈{0,1,2,…9} 𝑖=1
768
log(𝑝(𝑋𝑖|𝑌𝑘) × 𝑝 𝑌𝑘 ) ∙∙∙ Naïve Bayes Classifier
17
4. Logistic Regression
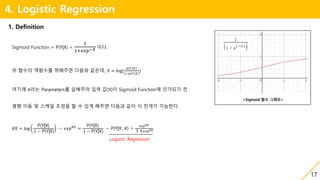
1.Definition
Sigmoid Function = P(Y|X) =
1
1+𝑒𝑥𝑝−𝑋 이다.
위 함수의 역함수를 취해주면 다음와 같은데, 𝑋 = log(
𝑝(𝑌|𝑋)
1−𝑝(𝑌|𝑋)
)
여기에 𝜃라는 Parameters를 곱해주어 입력 값(X)이 Sigmoid Function에 인가되기 전
평행 이동 및 스케일 조정을 할 수 있게 해주면 다음과 같이 식 전개가 가능한다.
𝜃𝑋 = log
P(Y|X)
1 − P(Y|X)
→ 𝑒𝑥𝑝 𝜃𝑋
=
P(Y|X)
1 − P(Y|X)
→ P(Y|X; 𝜃) =
𝑒𝑥𝑝 𝜃𝑋
1 + 𝑒𝑥𝑝 𝜃𝑋
<Sigmoid 함수 그래프>
Logistic Regression








































































![[Pr12] deep anomaly detection using geometric transformations](https://cdn.slidesharecdn.com/ss_thumbnails/pr12deepanomalydetectionusinggeometrictransformations-190317140121-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pr12] self supervised gan](https://cdn.slidesharecdn.com/ss_thumbnails/pr12selfsupervisedgan-190119162617-thumbnail.jpg?width=640&height=640&fit=bounds)





