Download to read offline






![Chapel Tasking API (chpl-tasks.h)
8
[9 Sync functions]
chpl_sync_lock();
chpl_sync_unlock();
chpl_sync_waitFullAndLock();
chpl_sync_waitEmptyAndLock();
chpl_sync_markAndSignalFull();
chpl_sync_markAndSignalEmpty();
chpl_sync_isFull();
chpl_sync_initAux();
chpl_sync_destroyAux();
[23 Tasking functions]
chpl_task_init();
chpl_task_exit();
chpl_task_createCommTask();
chpl_task_callMain();
chpl_task_addToTaskList();
chpl_task_executeTasksInList();
chpl_task_taskCallFTable();
chpl_task_startMovedTask();
chpl_task_getSubloc();
chpl_task_setSubloc();
[23 Tasking functions (Cont’d)]
chpl_task_getRequestedSubloc();
chpl_task_getId() ;
chpl_task_yield();
chpl_task_sleep();
chpl_task_getSerial();
chpl_task_setSerial();
chpl_task_getPrvData();
chpl_task_getMaxPar();
chpl_task_getNumSublocales();
chpl_task_getCallStackSize();
chpl_task_getNumQueuedTasks();
chpl_task_getNumRunningTasks();
chpl_task_getNumBlockedTasks();
[5 Threading functions]
chpl_task_getNumThreads();
chpl_task_getNumIdleThreads();
chpl_task_getenvNumThreadsPerLocale();
chpl_task_getEnvCallStackSize();
chpl_task_getDefaultCallStackSize();](https://image.slidesharecdn.com/ahayashi20171112-180226234728/75/Chapel-on-X-Exploring-Tasking-Runtimes-for-PGAS-Languages-8-2048.jpg)








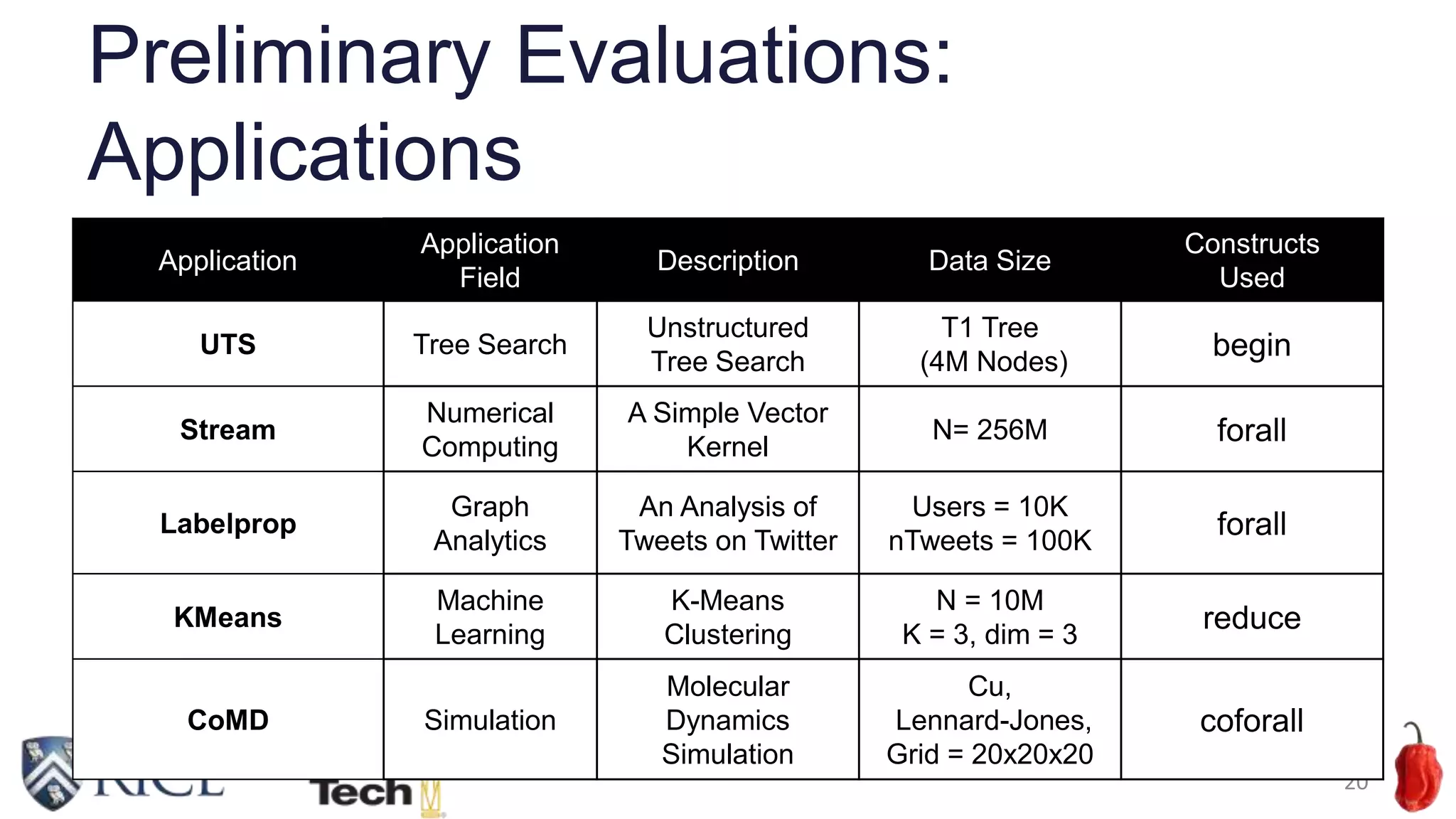
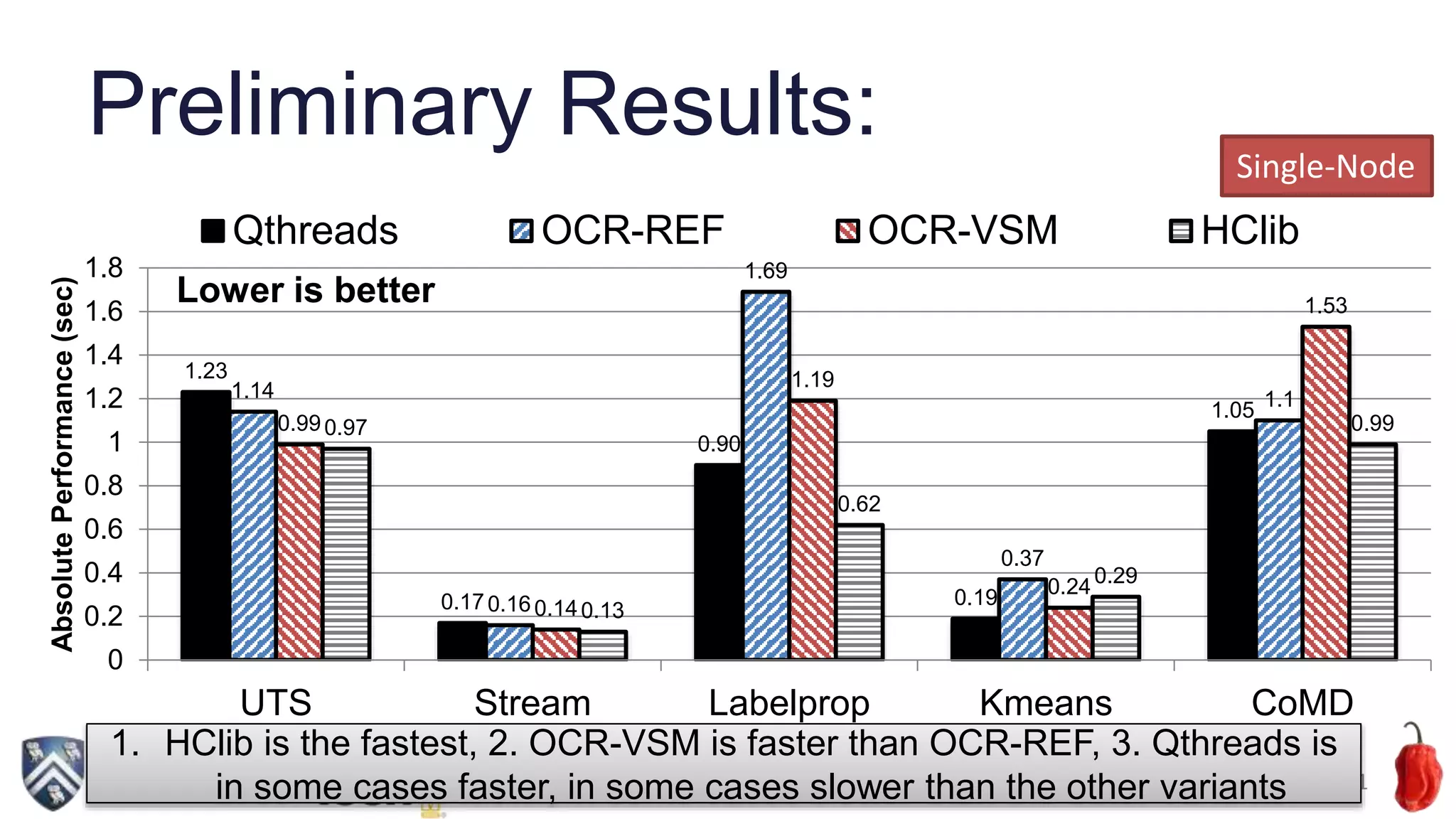
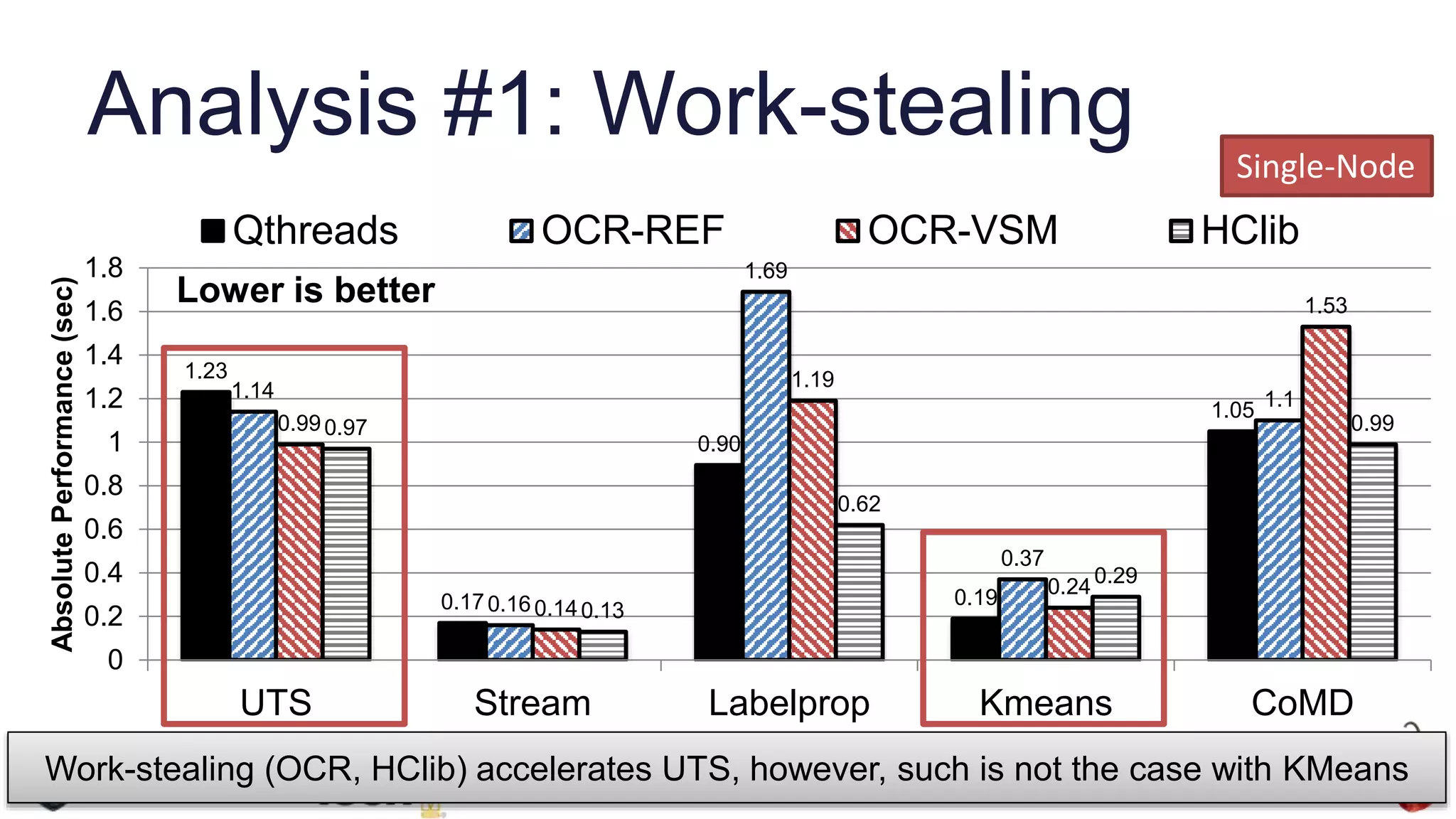
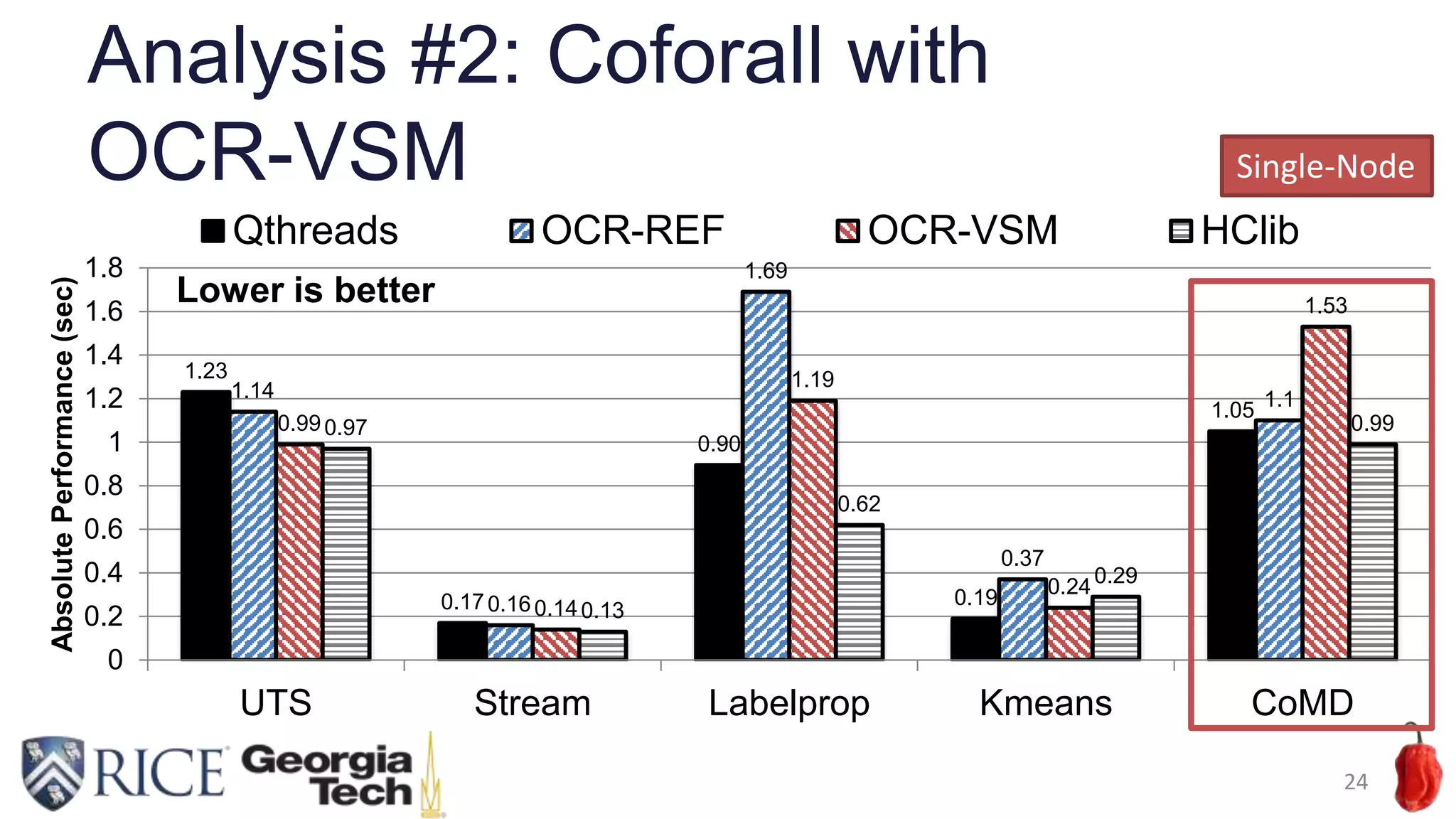
![Detailed analysis with “perf” (UTS)
[UTS OCR]
15.34% uts-deq.ocr.out uts-deq.ocr.out [.]
sha1_compile
13.87% uts-deq.ocr.out uts-deq.ocr.out [.]
create_tree_chpl
12.28% uts-deq.ocr.out libc-2.12.so [.]
_int_free
11.29% uts-deq.ocr.out libc-2.12.so [.]
malloc
8.27% uts-deq.ocr.out uts-deq.ocr.out [.]
chpl_user_main
6.88% uts-deq.ocr.out libm-2.12.so [.]
__ieee754_log
6.41% uts-deq.ocr.out libc-2.12.so [.]
_int_malloc
4.77% uts-deq.ocr.out uts-deq.ocr.out [.]
remove3 23
[UTS Qthreads]
25.71% uts-deq.qthread uts-deq.qthreads.out [.] qt_scheduler_get_thread
14.09% uts-deq.qthread uts-deq.qthreads.out [.] sha1_compile
10.16% uts-deq.qthread libc-2.12.so [.] _int_free
9.34% uts-deq.qthread libc-2.12.so [.] malloc
6.87% uts-deq.qthread uts-deq.qthreads.out [.] create_tree_chpl
5.60% uts-deq.qthread libc-2.12.so [.] _int_malloc
5.49% uts-deq.qthread libm-2.12.so [.] __ieee754_log
Qthreads: the scheduler is the bottleneck
The default qthreads scheduler in Chapel (nemesis) does not perform work-stealking
OCR: the main computation is the bottleneck thanks. to work stealing
The percentage of collected samples in functions with “perf” command](https://image.slidesharecdn.com/ahayashi20171112-180226234728/75/Chapel-on-X-Exploring-Tasking-Runtimes-for-PGAS-Languages-23-2048.jpg)
![27
• Standard lock-based implementations
• chpl_sync_waitFullAndLock / chpl_sync_waitEmptyAndLock:
• Based on general lock (chpl_sync_lock) and state flag
• chpl_sync_markAndSignalFull / chpl_sync_markAndSignalEmpty
• Based on general unlock (chpl_sync_unlock) and state flag
• Efficient lock support using spin-lock
• Extension of ticket lock approach [1,2]
• Two-step inter-task coordinations
1. Fast p-2-p synchronizations based on busy-wait (with timeout)
2. Sleep-and-awake synchronizations for context switching
[1] Algorithms for Scalable Synchronization on Shared Memory Multiprocessors. J. Mellor-Crummey and M. Scott. ACM Transactions on
Computer Systems, 9(1):21–65, February 1991.
[2] Design, Verification and Applications of a New Read-Write Lock Algorithm. Jun Shirako, Nick Vrvilo, Eric G. Mercer, Vivek Sarkar. 24th
ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), June 2012.
Optimized Sync Variable Implementation in HClib](https://image.slidesharecdn.com/ahayashi20171112-180226234728/75/Chapel-on-X-Exploring-Tasking-Runtimes-for-PGAS-Languages-27-2048.jpg)


The document discusses the exploration of dynamic tasking runtimes for PGAS languages, particularly focusing on Chapel's tasking constructs and the potential integration of alternative runtimes like Open Community Runtime (OCR) and Habanero-C/C++. It evaluates various tasking and synchronization functions provided in Chapel, comparing their performance with existing runtimes through application tests. The findings indicate that while HCLib generally outperforms other runtimes, there are scenarios where differences in performance become evident, influencing the choice of runtime based on specific application needs.













































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)