Download to read offline


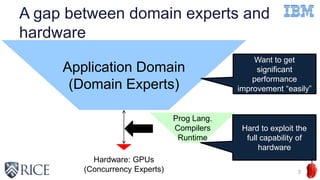
![Directive-based Accelerator
Programming Models
High-level abstraction of GPU parallelism
OpenACC
OpenMP 4.0/4.5 target
5
#pragma omp target map(tofrom: C[0:N]) map(to: B[0:N], A[0:N])
#pragma omp teams num_teams(N/1024) thread_limit(1024)
#pragma omp distribute parallel for
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}](https://image.slidesharecdn.com/ahayashi20161114-161206175642/85/Exploring-Compiler-Optimization-Opportunities-for-the-OpenMP-4-x-Accelerator-Model-on-a-POWER8-GPU-Platform-5-320.jpg)


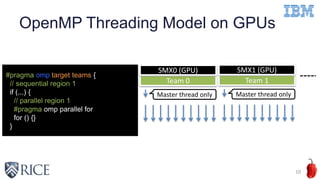

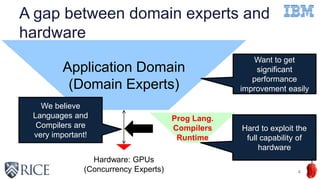
![Optimization Example:
Simplifying State Machine Execution on GPUs
12
What programmers can do
Use “combined” directives if possible
What compilers can do
Remove state machine execution if possible
IBM XL compiler performs such an optimization
#pragma omp target teams distributed parallel for …
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}](https://image.slidesharecdn.com/ahayashi20161114-161206175642/85/Exploring-Compiler-Optimization-Opportunities-for-the-OpenMP-4-x-Accelerator-Model-on-a-POWER8-GPU-Platform-12-320.jpg)

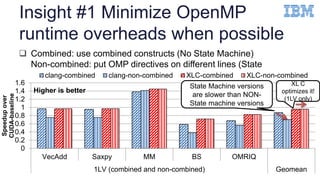
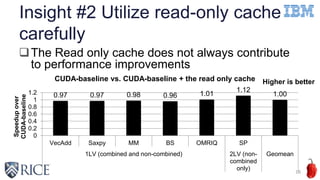
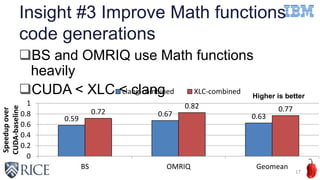
![Insight #3 Improve Math functions
code generations (Cont’d)
18
#pragma omp target distributed parallel for
for (int i = 0; i < N; i++) {
float T = exp(randArray[i]);
call[i] = (float)log(randArray[i])/T;
}
Synthetic Benchmark
CUDA clang xlc
515 us 933 us 922 us
libdevice.bcMath API
721 us when
using expf and
logf manually
Math API is better
than libdevice
exp (double) expf(float) exp(double) expf(float)
log(double) logf(float) log(double) log(double)](https://image.slidesharecdn.com/ahayashi20161114-161206175642/85/Exploring-Compiler-Optimization-Opportunities-for-the-OpenMP-4-x-Accelerator-Model-on-a-POWER8-GPU-Platform-18-320.jpg)

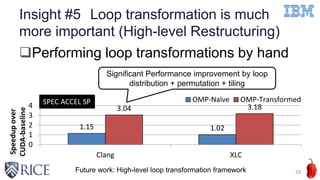
![Insight #5 Loop transformation is much
more important (Parameter tuning)
21
…
for (int k = 0; k < N; k++) {
sum += A[i*N+k] * B[k*N+threadIdx.x];
}
Matrix Multiplication
unrolling factor = 2
L2 Hit (92.02%)
A[0][0]
* B[0][0]
A[0][0]
* B[0][1]
A[0][0]
* B[0][2]
threadID 0 threadID 1 threadID 2
A[0][1]
* B[1][0]
A[0][1]
* B[1][1]
A[0][1]
* B[1][2]
2 stride + 2 offset access simultaneously
unrolling factor = 8
L2 Hit (14.46%).
A[0][0]
* B[0][0]
A[0][0]
* B[0][1]
A[0][0]
* B[0][2]
threadID 0 threadID 1 threadID 2
A[0][1]
* B[1][0]
A[0][1]
* B[1][1]
A[0][1]
* B[1][2]
A[0][2]
* B[2][0]
A[0][2]
* B[2][0]
A[0][2]
* B[2][2]8 stride + 8 offset access simultaneously
1.41x](https://image.slidesharecdn.com/ahayashi20161114-161206175642/85/Exploring-Compiler-Optimization-Opportunities-for-the-OpenMP-4-x-Accelerator-Model-on-a-POWER8-GPU-Platform-21-320.jpg)

![On Going & Future work
Minimizing OpenMP runtime overhead
The latest versions of clang and XL C no longer generate state machine
Plan to performance evaluation & analysis again
High-level loop transformations for OpenMP programs
For better memory coalescing and the read-only cache/shared memory
exploitation
High-level Restructuring: Loop permutation, loop fusion, loop distribution, loop
tiling,
Turning parameters: Tile size, Unrolling factor
Using the polyhedral model + DL Model [SC’14]
Taking additional information from users [PACT’15]
Automatic Device Selection [PACT’15, PPPJ’15]
23](https://image.slidesharecdn.com/ahayashi20161114-161206175642/85/Exploring-Compiler-Optimization-Opportunities-for-the-OpenMP-4-x-Accelerator-Model-on-a-POWER8-GPU-Platform-23-320.jpg)


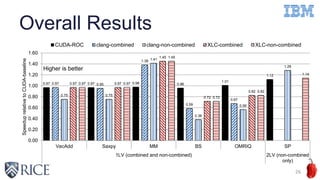

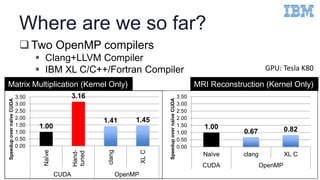
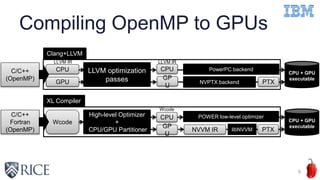
The document discusses optimizing OpenMP 4.x accelerator model performance for Power8+GPU platforms, highlighting the challenges in bridging the gap between application domain experts and hardware capabilities. It presents insights on minimizing runtime overheads, utilizing read-only cache effectively, and enhancing mathematical function generation, while emphasizing the importance of high-level loop transformations. The paper aims to explore compiler optimizations through detailed performance analyses and proposes future directions for research in high-level restructuring of OpenMP programs.














































































