Downloaded 14 times




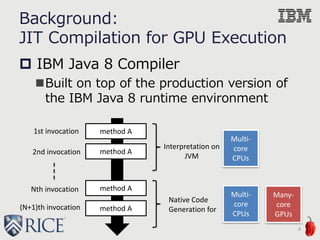
![0e+00 4e+07 8e+07
0.00.20.40.60.81.0
The dynamic number of IR instructions
KernelExecutionTime(msec)
NVIDIA Tesla K40 GPU
IBM POWER8 CPU
Related Work:
Linear regression
Regression based cost estimation
[1,2] is specific to an application
7
App 1) BlackScholes
[1] Leung et al. Automatic Parallelization for Graphics Processing Units (PPPJ’09)
[2] Kerr et al. Modeling GPU-CPU Workloads and Systems (GPGPU-3)
ExecutionTime(msec)
0e+00 4e+07 8e+07
01234
The dynamic number of IR instructions
KernelExecutionTime(msec)
NVIDIA Tesla K40 GPU
IBM POWER8 CPU
ExecutionTime(msec) App 2) Vector Addition
CPU
GPU
GPU
CPU](https://image.slidesharecdn.com/ahayashi20150909-150909190732-lva1-app6892/85/Machine-Learning-based-Performance-Heuristics-for-Runtime-CPU-GPU-Selection-7-320.jpg)


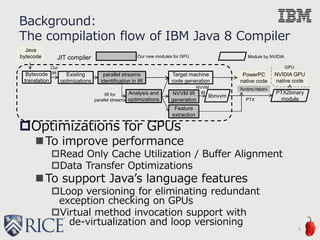
![Features of program
that may affect performance (Cont’d)
The dynamic number of Array
Accesses
Coalesced Access (a[i]) (aligned access)
Offset Access (a[i+c])
Stride Access (a[c*i])
Other Access (a[b[i]])
Data Transfer Size
H2D Transfer Size
D2H Transfer Size
11
0 5 10 15 20 25 30
050100150200
c : offset or stride size
Bandwidth(GB/s)
●
● ● ●
● ● ● ● ● ● ● ● ● ● ● ●
●
● ● ●
●
● ● ● ● ● ● ● ● ● ● ●
●
●
Offset : array[i+c]
Stride : array[c*i]](https://image.slidesharecdn.com/ahayashi20150909-150909190732-lva1-app6892/85/Machine-Learning-based-Performance-Heuristics-for-Runtime-CPU-GPU-Selection-11-320.jpg)
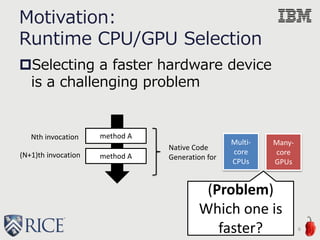
![An example of feature vector
12
{
"title" :"MRIQ.runGPULambda()V",
"lineNo" :114,
"features" :{
"range": 32768,
"IRs" :{
"Memory": 89128, "Arithmetic": 61447, "Math": 6144,
"Branch": 3074, "Other": 58384
},
"Array Accesses" :{
"Coalesced": 9218, "Offset": 0,
"Stride": 0, "Other": 12288 },
"H2D Transfer" :
[131088,131088,131088,12304,12304,12304,12304,16,16],
"D2H Transfer" :
[131072,131072,0,0,0,0,0,0,0,0]
},
}](https://image.slidesharecdn.com/ahayashi20150909-150909190732-lva1-app6892/85/Machine-Learning-based-Performance-Heuristics-for-Runtime-CPU-GPU-Selection-12-320.jpg)




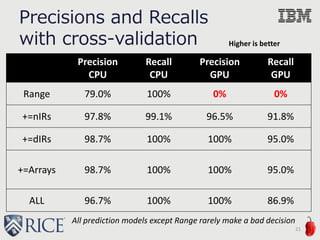

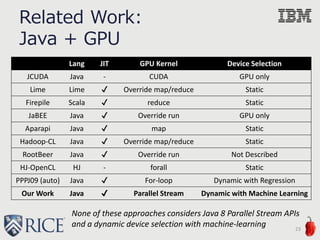



This document discusses the development of machine-learning-based performance heuristics for selecting between CPU and GPU during runtime in Java 8 applications. It highlights the use of supervised machine learning, particularly support vector machines, to create a binary prediction model that can determine the faster processing hardware based on various program features. The study presents results indicating up to 99% accuracy in predicting the optimal hardware choice, alongside considerations for future enhancements in performance heuristics.















































































