Downloaded 54 times







![What is Sparkling Shell?
Standard spark-shell
Launch H2O extension
export MASTER=“local-cluster[3,2,1024]”
!
spark-shell
JAR containing
H2O code
Spark Master
address
—jars shaded.jar
—conf spark.extensions=org.apache.spark.executor.H2OPlatformExtension
Name of H2O extension
provided by JAR](https://image.slidesharecdn.com/20140930sparklingwaterhandson-141002230721-phpapp01/75/2014-09-30_sparkling_water_hands_on-13-2048.jpg)
![…more on launching…
‣ By default single JVM, multi-threaded (export
MASTER=local[*]) or
‣ export MASTER=“local-cluster[3,2,1024]” to launch
an embedded Spark cluster or
‣ Launch standalone Spark cluster via
sbin/launch-spark-cloud.sh
and export MASTER=“spark://localhost:7077”](https://image.slidesharecdn.com/20140930sparklingwaterhandson-141002230721-phpapp01/75/2014-09-30_sparkling_water_hands_on-14-2048.jpg)




![Use Spark API
// H2O Context provide useful implicits for conversions
val h2oContext = new H2OContext(sc)
import h2oContext._
// Create RDD wrapper around DataFrame
val airlinesTable : RDD[Airlines] = toRDD[Airlines](airlinesData)
airlinesTable.count
// And use Spark RDD API directly
val flightsOnlyToSF = airlinesTable.filter(
f =
f.Dest==Some(SFO) || f.Dest==Some(SJC) || f.Dest==Some(OAK) )
flightsOnlyToSF.count](https://image.slidesharecdn.com/20140930sparklingwaterhandson-141002230721-phpapp01/75/2014-09-30_sparkling_water_hands_on-21-2048.jpg)



.collect
.map ( _.result.getOrElse(NaN) )](https://image.slidesharecdn.com/20140930sparklingwaterhandson-141002230721-phpapp01/75/2014-09-30_sparkling_water_hands_on-24-2048.jpg)


![Using App Extensions
val conf = new SparkConf()
.setAppName(“Sparkling H2O Example”)
// Setup expected size of H2O cloud
conf.set(“spark.h2o.cluster.size”,h2oWorkers)
!
// Add H2O extension
conf.addExtension[H2OPlatformExtension]
!
// Create Spark Context
val sc = new SparkContext(sc)](https://image.slidesharecdn.com/20140930sparklingwaterhandson-141002230721-phpapp01/75/2014-09-30_sparkling_water_hands_on-27-2048.jpg)

![You can participate!
Epic PUBDEV-21aka Sparkling Water
PUBDEV-23 Test HDFS reader
PUBDEV-26 Implement toSchemaRDD
PUBDEV-27 Boolean transfers
PUBDEV-31 Support toRDD[ X : Numeric]
PUBDEV-32/33 Mesos/YARN support](https://image.slidesharecdn.com/20140930sparklingwaterhandson-141002230721-phpapp01/75/2014-09-30_sparkling_water_hands_on-29-2048.jpg)



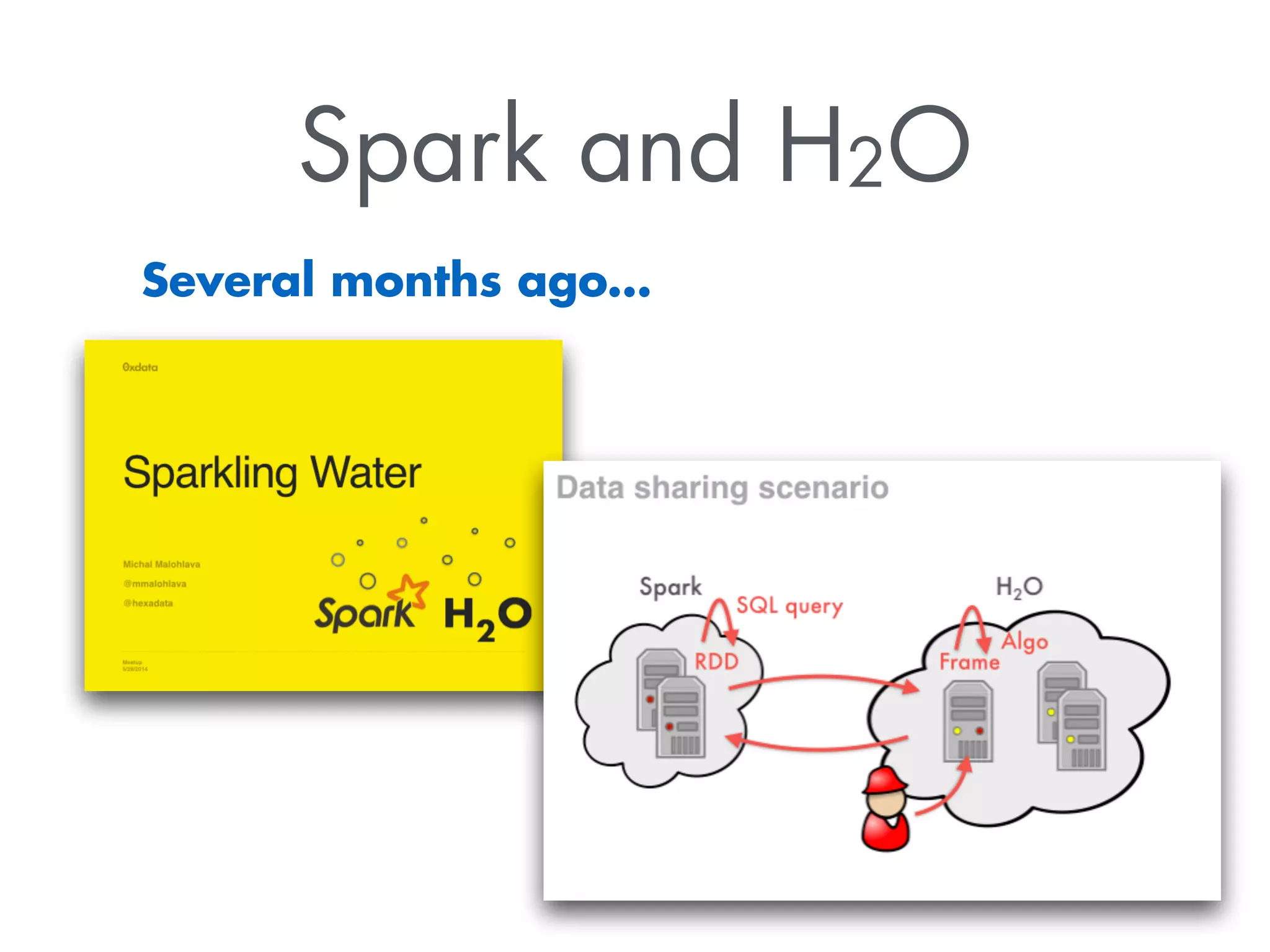
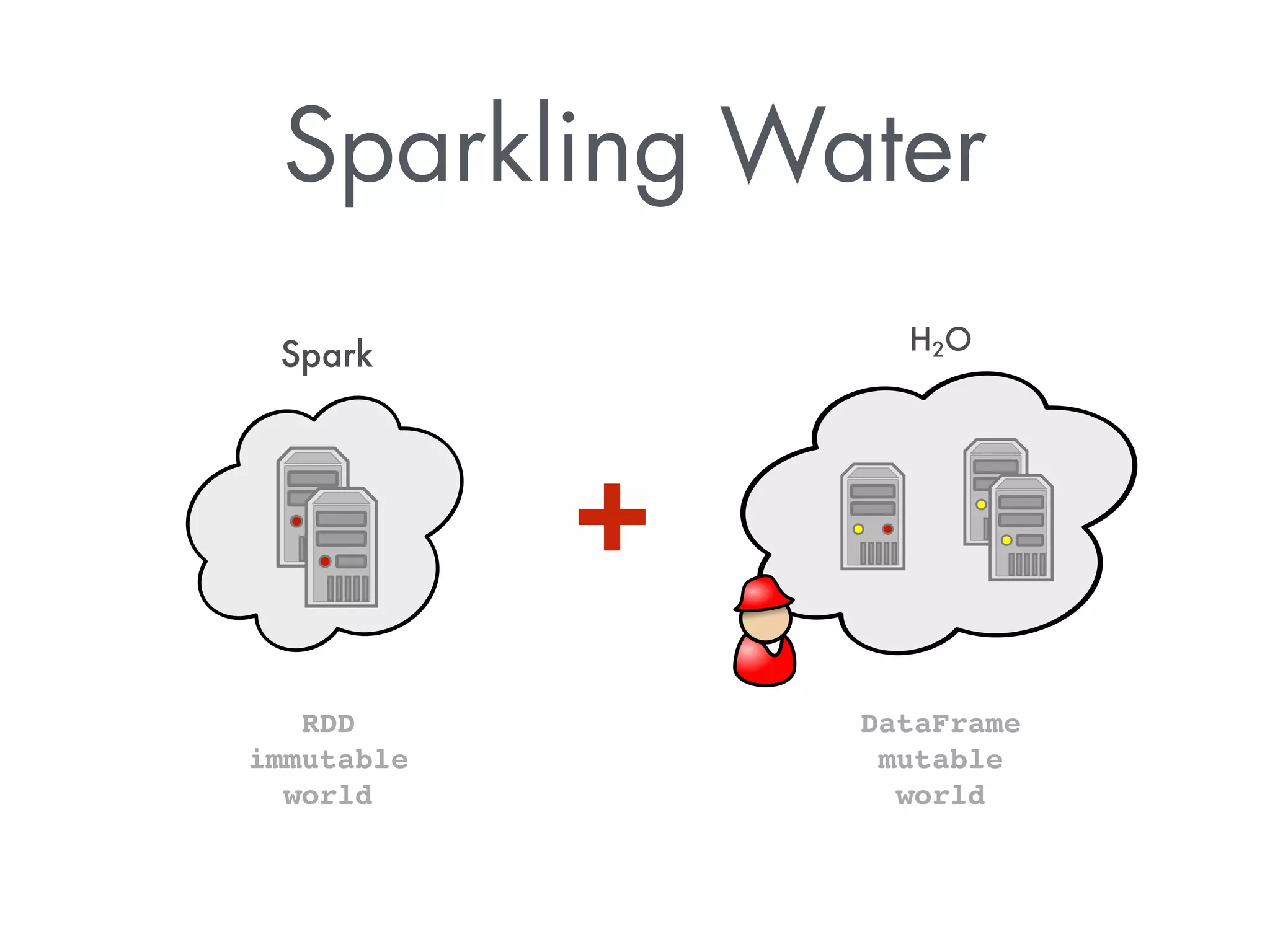
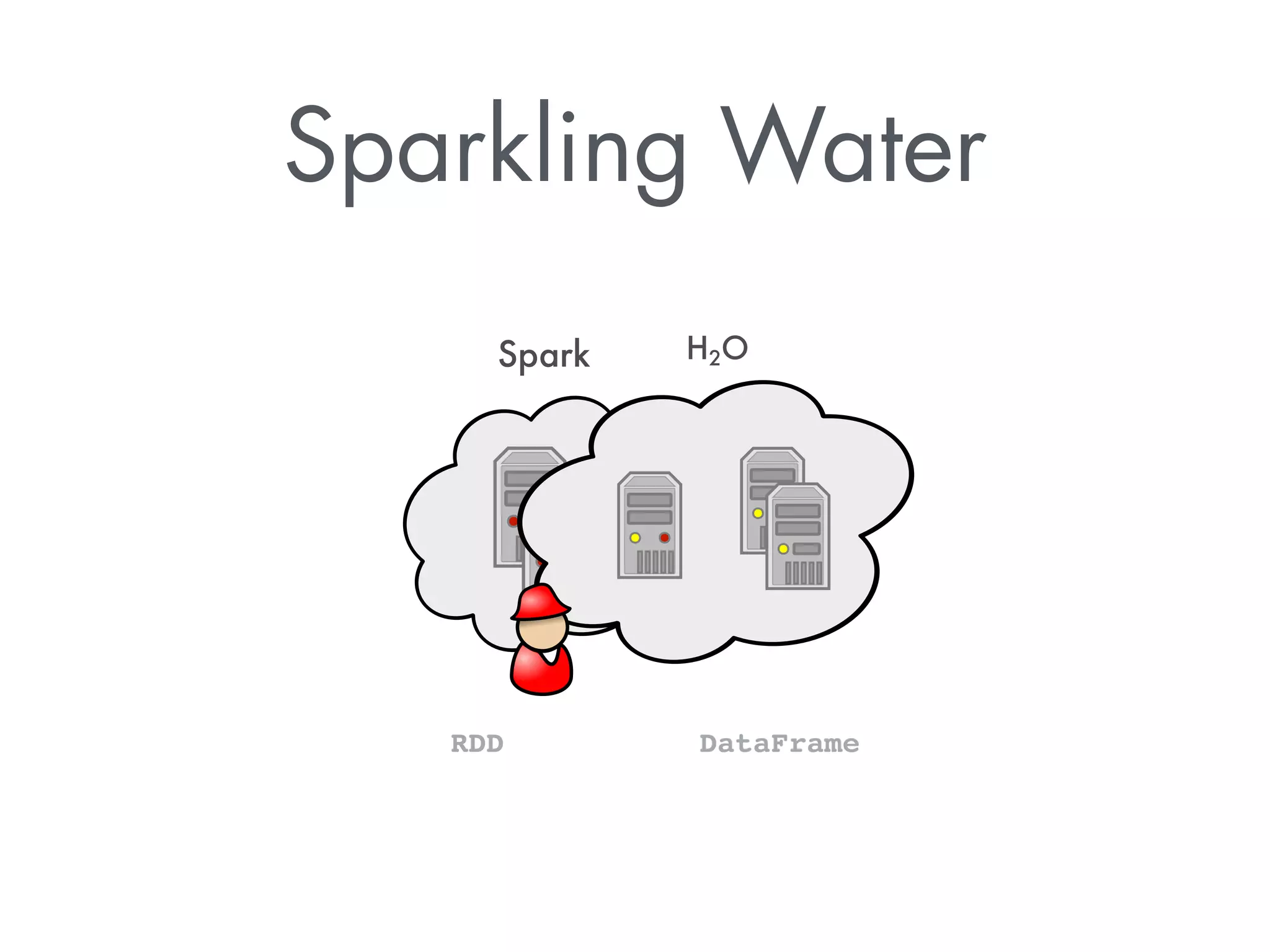
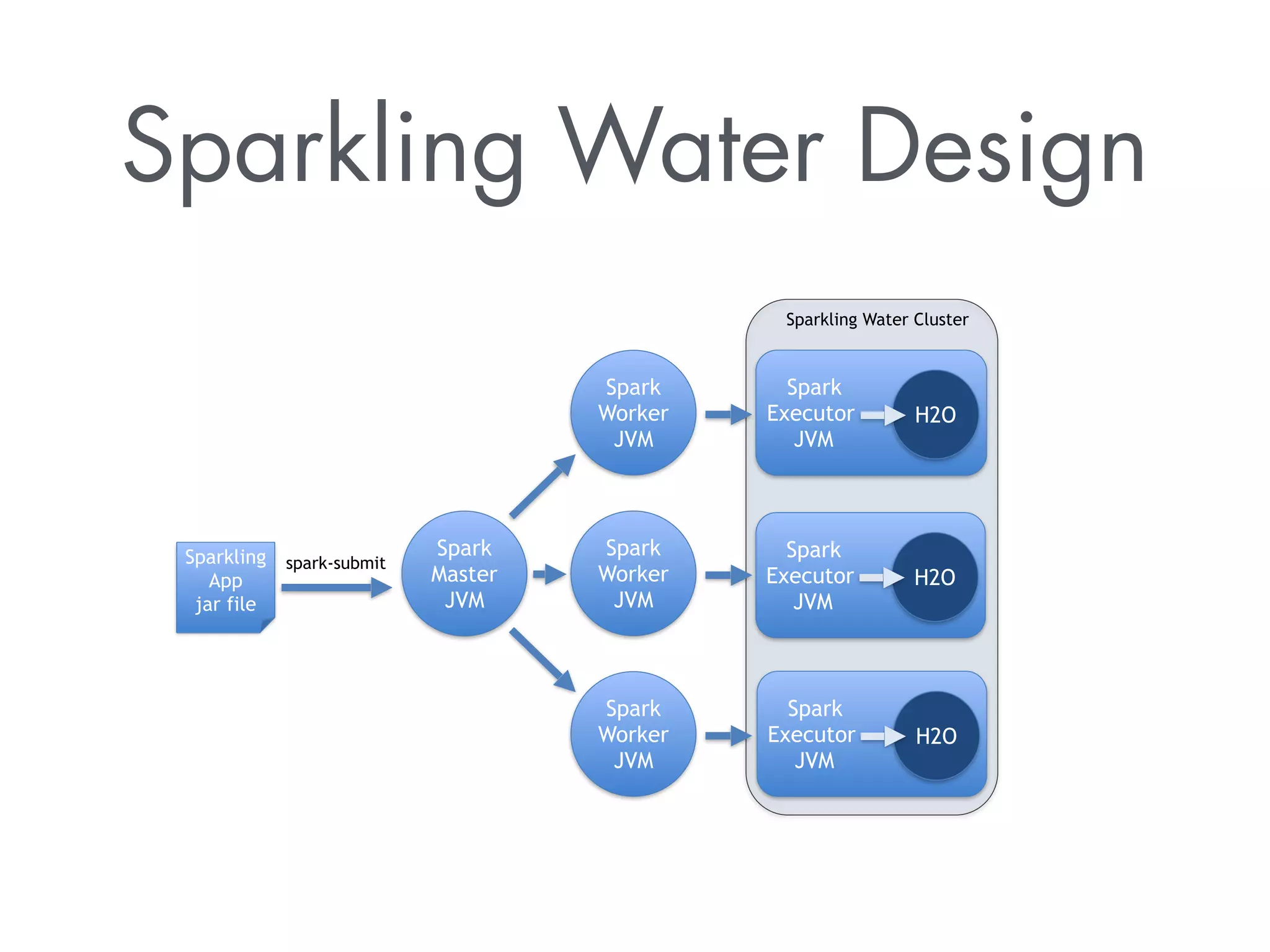
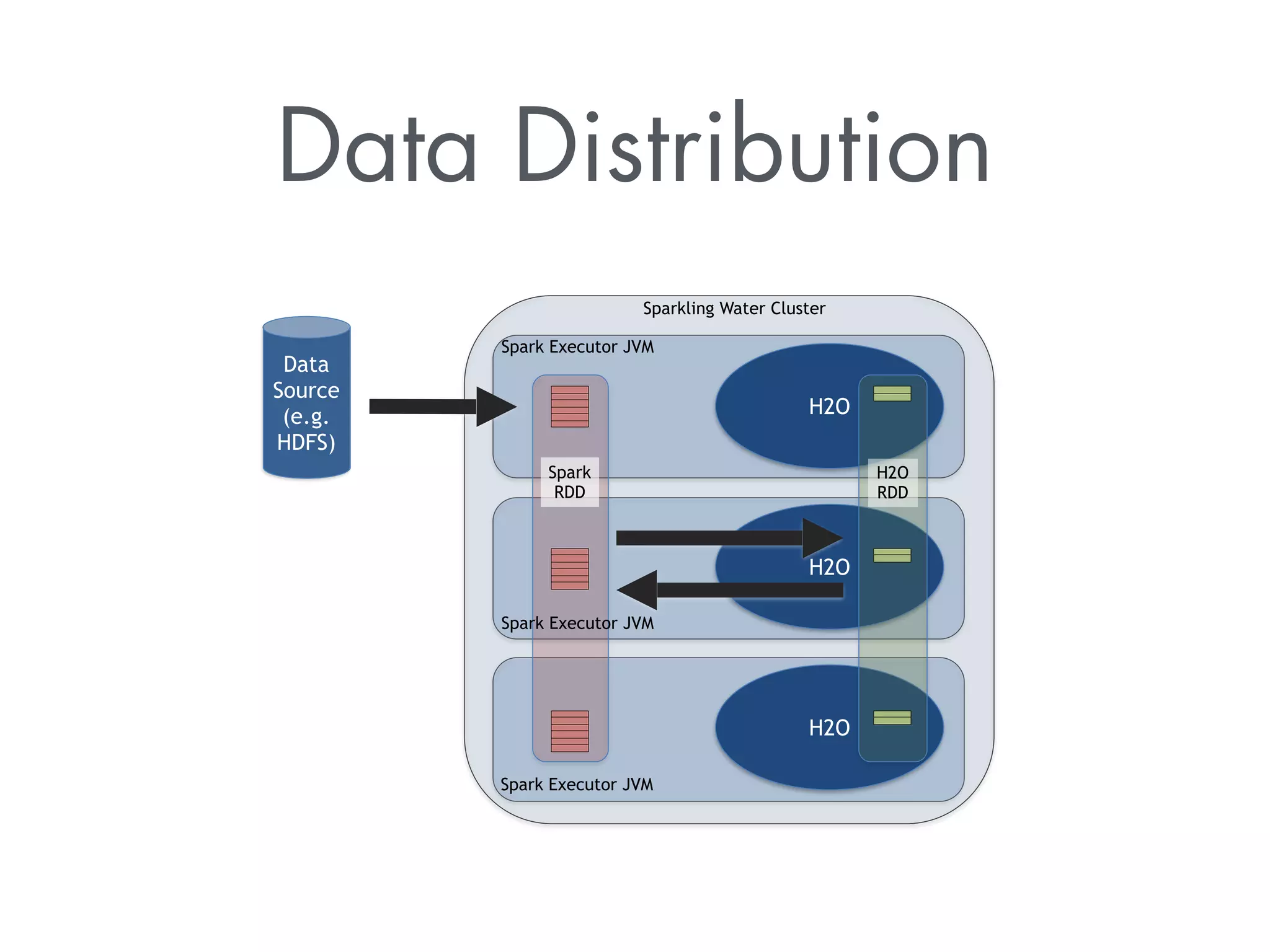
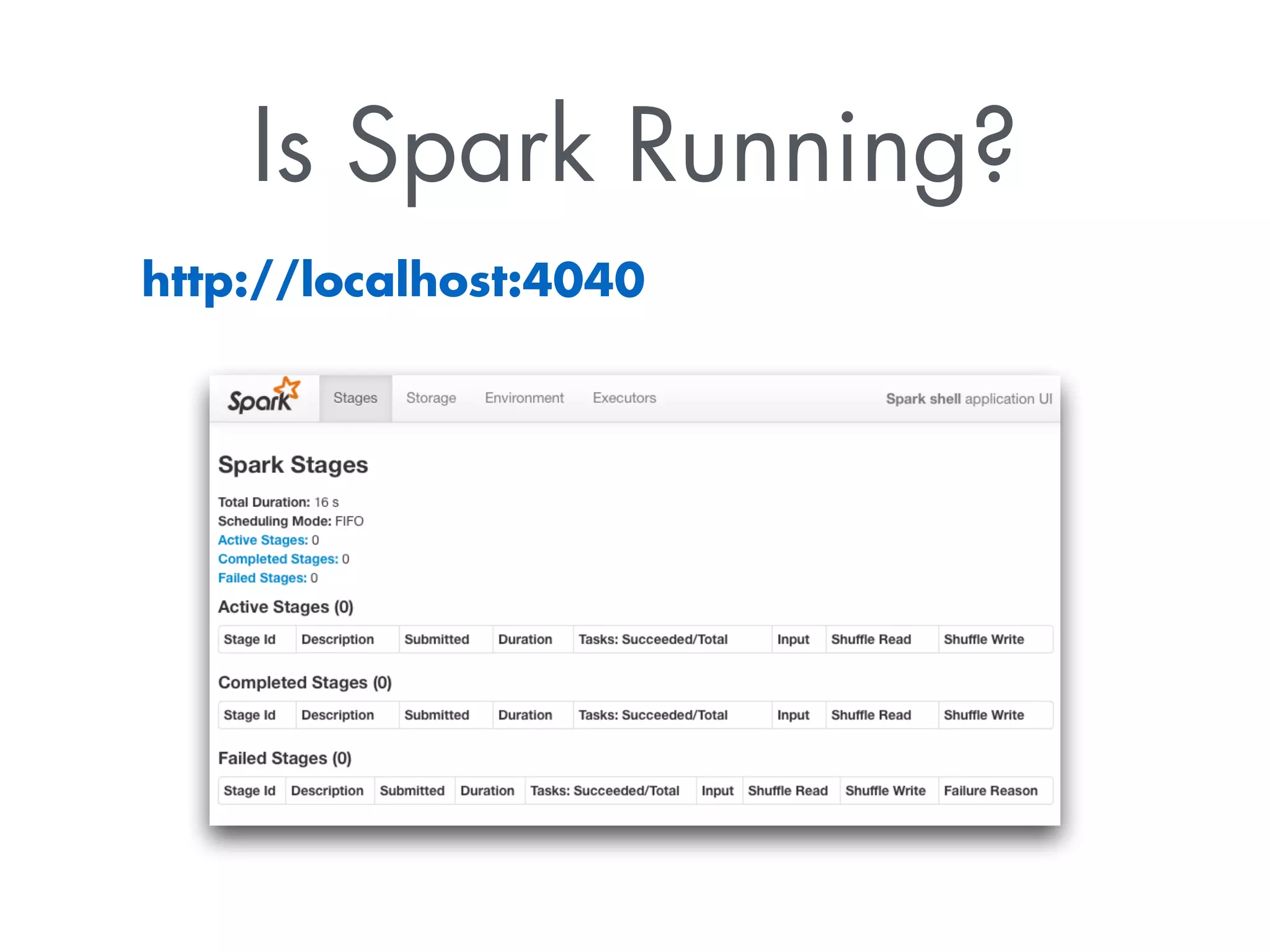
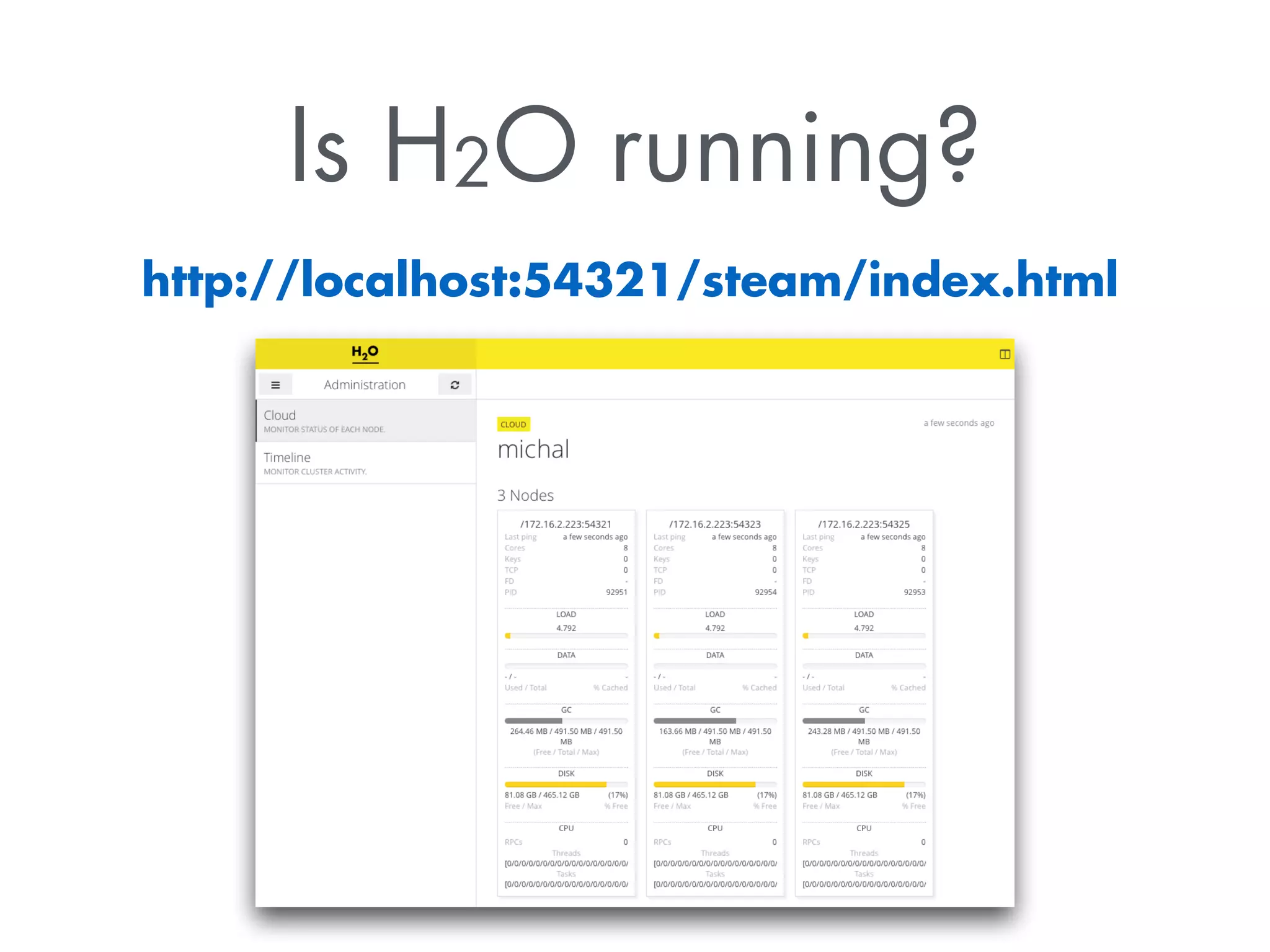
The document discusses Sparkling Water, a tool that integrates H2O with Apache Spark for efficient data analysis and machine learning. It provides an overview of the installation process, leveraging Spark APIs, and running deep learning models on distributed data. The document also highlights configurations for Spark, usage examples, and resources for further learning.

























































































![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

