Downloaded 135 times


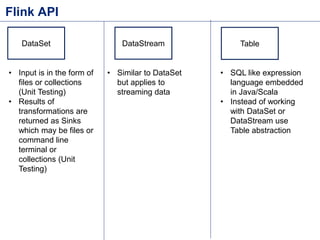

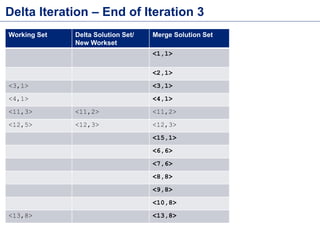
![Flink DataSet API – Word Count
public class WordCount {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = getLines(env); //Create DataSet from lines in file
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0) //Group by first element of the Tuple
.aggregate(Aggregations.SUM, 1);
wordCounts.print();//Execute the WordCount job
}
/*FlatMap implantation which converts each line to many <Word,1> pairs*/
public static class LineSplitter implements
FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
Source Code -
https://github.com/sameeraxiomine/FlinkMeetup/blob/master/src/main/java/org/a
pache/flink/examples/WordCount.java](https://image.slidesharecdn.com/flinkbatchanditerationsv2-151119035329-lva1-app6892/85/Flink-Batch-Processing-and-Iterations-4-320.jpg)
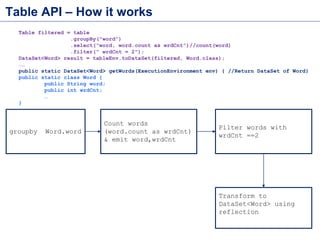
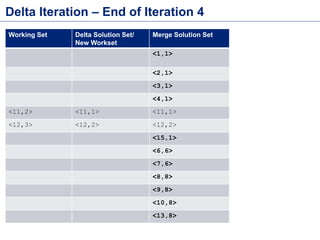
![Flink Batch API (Table API)
public class WordCountUsingTableAPI {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment
.getExecutionEnvironment();
TableEnvironment tableEnv = new TableEnvironment();
DataSet<Word> words = getWords(env);
Table table = tableEnv.fromDataSet(words);
Table filtered = table
.groupBy("word")
.select("word.count as wrdCnt, word")
.filter(" wrdCnt = 2");
DataSet<Word> result = tableEnv.toDataSet(filtered, Word.class);
result.print();
}
public static DataSet<Word> getWords(ExecutionEnvironment env) { //Return DataSet of Word}
public static class Word {
public String word;
public int wrdCnt;
public Word(String word, int wrdCnt) {
this.word = word; this.wrdCnt = wrdCnt;
}
public Word() {} // empty constructor to satisfy POJO requirements
@Override
public String toString() {
return "Word [word=" + word + ", count=" + wrdCnt + "]";
}
}
}
Source Code -
https://github.com/sameeraxiomine/FlinkMeetup/blob/master/src/main/java/org/apach
e/flink/examples/WordCountUsingTableAPI.java](https://image.slidesharecdn.com/flinkbatchanditerationsv2-151119035329-lva1-app6892/85/Flink-Batch-Processing-and-Iterations-5-320.jpg)



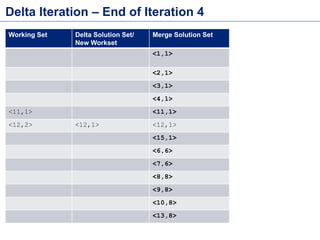
![Bulk Iteration – Source Code
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//First create an initial dataset
IterativeDataSet<Tuple2<Long, Long>> initial = getData(env)
.iterate(MAX_ITERATIONS);
//Register Aggregator and Convergence Criterion Class
initial.registerAggregationConvergenceCriterion("total", new LongSumAggregator(),
new VerifyIfMaxConvergence());
//Iterate
DataSet<Tuple2<Long, Long>> iteration = initial.map(
new RichMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>>() {
private LongSumAggregator agg = null;
@Override
public void open(Configuration parameters) {
this.agg = this.getIterationRuntimeContext().getIterationAggregator("total");
}
@Override
public Tuple2<Long, Long> map(Tuple2<Long, Long> input) throws Exception {
long incrementF1 = input.f1 + 1;
Tuple2<Long, Long> out = new Tuple2<>(input.f0, incrementF1);
this.agg.aggregate(out.f1);
return out;
}
});
DataSet<Tuple2<Long, Long>> finalDs = initial.closeWith(iteration); //Close Iteration
finalDs.print(); //Consume output
}
public static class VerifyIfMaxConvergence implements ConvergenceCriterion<LongValue>{
@Override
public boolean isConverged(int iteration, LongValue value) {
return (value.getValue()>AdderBulkIterations.ABSOLUTE_MAX);
}
}](https://image.slidesharecdn.com/flinkbatchanditerationsv2-151119035329-lva1-app6892/85/Flink-Batch-Processing-and-Iterations-17-320.jpg)


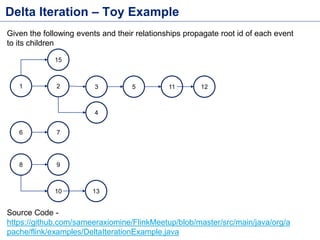
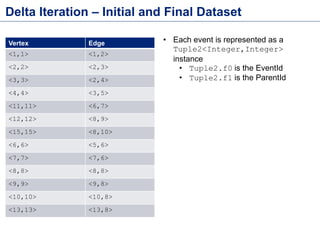
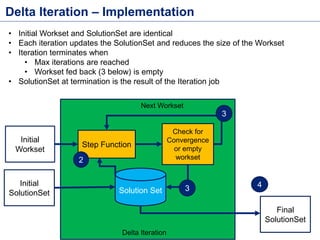
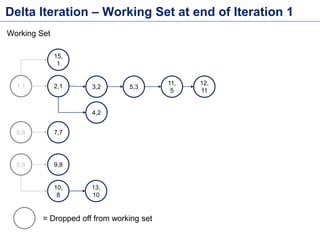
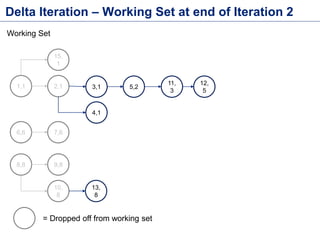
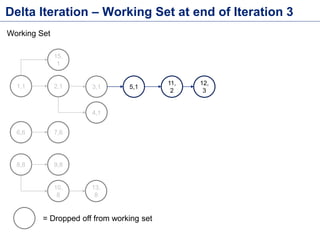
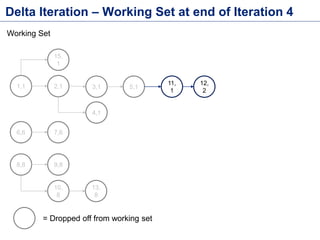
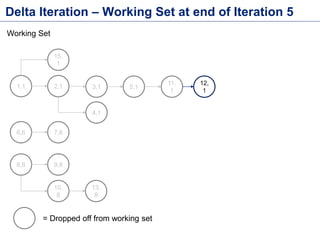
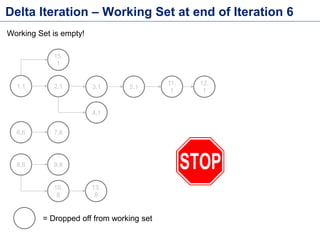


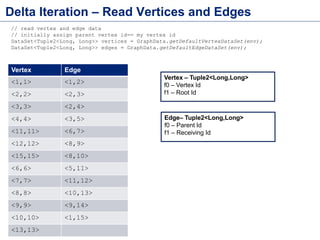
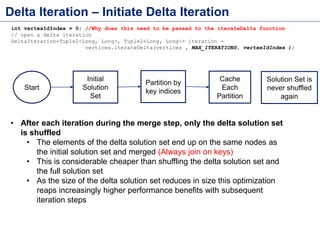
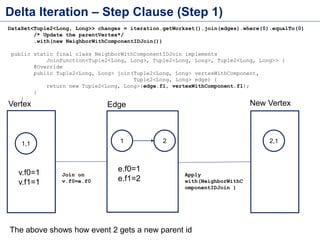
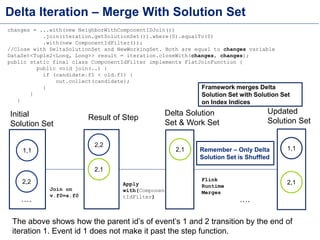
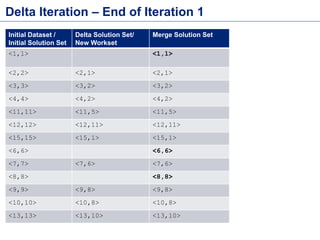
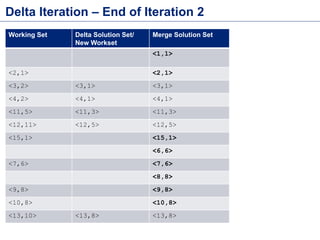
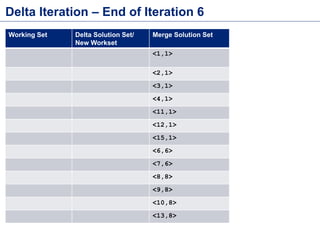

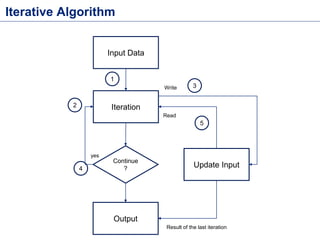
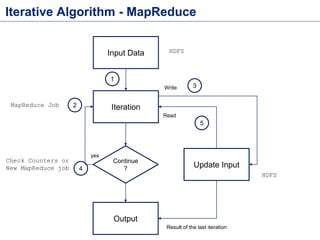
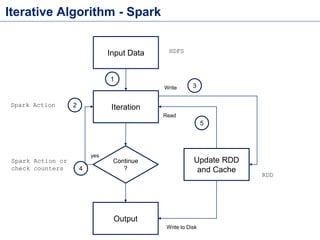
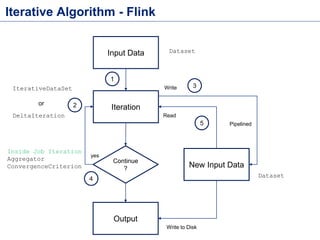
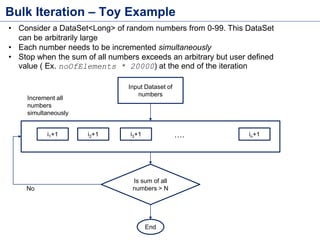
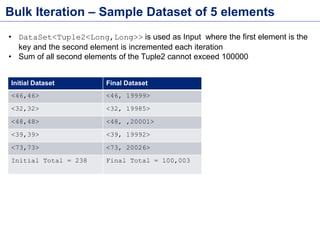
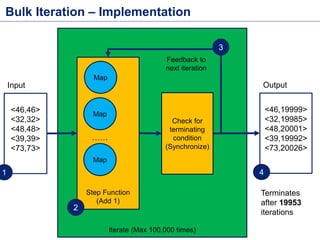
This document discusses batch processing using Apache Flink. It provides code examples of using Flink's DataSet and Table APIs to perform batch word count jobs. It also covers iterative algorithms in Flink, including how Flink handles bulk and delta iterations more efficiently than other frameworks like Spark and MapReduce. Delta iterations are optimized by only processing changes between iterations to reduce the working data set size over time.
































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)


