Download to read offline








![Continuation style
ss::future<> consensus::stop() {
return _event_manager.stop()
.then([this] { return _append_requests_buffer.stop(); })
.then([this] { return _batcher.stop(); })
.then([this] { return _bg.close(); })
.then([this] {
if (likely(!_snapshot_writer)) {
return ss::now();
}
return _snapshot_writer->close().then(
[this] { _snapshot_writer.reset(); });
});
}](https://image.slidesharecdn.com/copyoftravisdownsp99conf2023slidetemplate-240625212132-67340265/85/Adventures-in-Thread-per-Core-Async-with-Redpanda-and-Seastar-8-320.jpg)


![New vs old
ss::future<> consensus::stop() {
…
co_await _event_manager.stop();
co_await _append_requests_buffer.stop();
co_await _batcher.stop();
_op_lock.broken();
co_await _bg.close();
if (unlikely(_snapshot_writer)) {
co_await _snapshot_writer->close();
_snapshot_writer.reset();
}
}
ss::future<> consensus::stop() {
…
return _event_manager.stop()
.then([this] { return
_append_requests_buffer.stop(); })
.then([this] { return _batcher.stop(); })
.then([this] { return _bg.close(); })
.then([this] {
if (likely(!_snapshot_writer)) {
return ss::now();
}
return _snapshot_writer->close().then(
[this] { _snapshot_writer.reset(); });
});](https://image.slidesharecdn.com/copyoftravisdownsp99conf2023slidetemplate-240625212132-67340265/85/Adventures-in-Thread-per-Core-Async-with-Redpanda-and-Seastar-11-320.jpg)








 mutable {
if (decoder.accept(c)) {
return ss::make_ready_future<result_type>
(decoder.result());
}
return cont_recurse(s, decoder);
});
}](https://image.slidesharecdn.com/copyoftravisdownsp99conf2023slidetemplate-240625212132-67340265/85/Adventures-in-Thread-per-Core-Async-with-Redpanda-and-Seastar-20-320.jpg)

 mutable {
if (decoder.accept(c)) {
return decoder.result_as_future();
}
return cont_tricky(s, decoder);
});
}](https://image.slidesharecdn.com/copyoftravisdownsp99conf2023slidetemplate-240625212132-67340265/85/Adventures-in-Thread-per-Core-Async-with-Redpanda-and-Seastar-23-320.jpg)

![Sync with async fallback
So how should we really do this?
Use sync with async fallback.
Peek at 5 bytes, fallback if not available.
Fallback must in own method!
auto decode_fallback(iobuf_reader& s) {
auto [buf, filled] = s.peek<5>();
if (filled) {
auto result = decode_u32(buf.data());
s.skip(result.second);
return ss::make_ready_future(result);
}
return coro_decode(s);
}](https://image.slidesharecdn.com/copyoftravisdownsp99conf2023slidetemplate-240625212132-67340265/85/Adventures-in-Thread-per-Core-Async-with-Redpanda-and-Seastar-25-320.jpg)









![Coroutines and lifetimes: example 1
ss::future<std::error_code> metadata::mark_clean(model::offset clean_offset) {
auto builder = batch_start();
builder.mark_clean(clean_offset);
return builder.replicate();
// … builder falls out of scope here, the returned future still references it
}
// Imagine replicate() might generate a future that captures this
ss::future<> batch_builder::replicate() {
return something.then([this]{
// update some member variable here
});
}
36](https://image.slidesharecdn.com/copyoftravisdownsp99conf2023slidetemplate-240625212132-67340265/85/Adventures-in-Thread-per-Core-Async-with-Redpanda-and-Seastar-36-320.jpg)







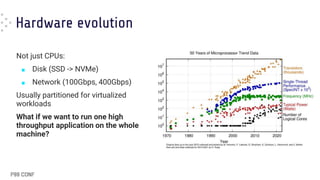











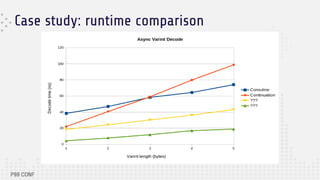
The document discusses the architecture and performance of Redpanda, a streaming storage engine built on Seastar, emphasizing its thread-per-core model and shared-nothing architecture. It highlights the use of C++20 coroutines for asynchronous programming, including performance implications and comparisons with synchronous methods. The content provides insights into trade-offs and best practices for achieving high throughput and low latency in software development with a focus on async programming.



























![php[world] 2016 - You Don’t Need Node.js - Async Programming in PHP](https://cdn.slidesharecdn.com/ss_thumbnails/phpworld2016-youdontneednode-161118143948-thumbnail.jpg?width=640&height=640&fit=bounds)




















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















