



![Window WordCount: main Method
4
public static void main(String[] args) throws Exception {
// set up the execution environment
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Integer>> counts = env
// read stream of words from socket
.socketTextStream("localhost", 9999)
// split up the lines in tuples containing: (word,1)
.flatMap(new Splitter())
// group by the tuple field "0"
.groupBy(0)
// keep the last 5 minute of data
.window(Time.of(5, TimeUnit.MINUTES))
//sum up tuple field "1"
.sum(1);
// print result in command line
counts.print();
// execute program
env.execute("Socket Incremental WordCount Example");
}](https://image.slidesharecdn.com/flinkstreambasics-151019145955-lva1-app6891/85/Apache-Flink-Training-DataStream-API-Part-1-Basic-4-320.jpg)
![Stream Execution Environment
5
public static void main(String[] args) throws Exception {
// set up the execution environment
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Integer>> counts = env
// read stream of words from socket
.socketTextStream("localhost", 9999)
// split up the lines in tuples containing: (word,1)
.flatMap(new Splitter())
// group by the tuple field "0"
.groupBy(0)
// keep the last 5 minute of data
.window(Time.of(5, TimeUnit.MINUTES))
//sum up tuple field "1"
.sum(1);
// print result in command line
counts.print();
// execute program
env.execute("Socket Incremental WordCount Example");
}](https://image.slidesharecdn.com/flinkstreambasics-151019145955-lva1-app6891/85/Apache-Flink-Training-DataStream-API-Part-1-Basic-5-320.jpg)
![Data Sources
6
public static void main(String[] args) throws Exception {
// set up the execution environment
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Integer>> counts = env
// read stream of words from socket
.socketTextStream("localhost", 9999)
// split up the lines in tuples containing: (word,1)
.flatMap(new Splitter())
// group by the tuple field "0"
.groupBy(0)
// keep the last 5 minute of data
.window(Time.of(5, TimeUnit.MINUTES))
//sum up tuple field "1"
.sum(1);
// print result in command line
counts.print();
// execute program
env.execute("Socket Incremental WordCount Example");
}](https://image.slidesharecdn.com/flinkstreambasics-151019145955-lva1-app6891/85/Apache-Flink-Training-DataStream-API-Part-1-Basic-6-320.jpg)
![Data types
7
public static void main(String[] args) throws Exception {
// set up the execution environment
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Integer>> counts = env
// read stream of words from socket
.socketTextStream("localhost", 9999)
// split up the lines in tuples containing: (word,1)
.flatMap(new Splitter())
// group by the tuple field "0"
.groupBy(0)
// keep the last 5 minute of data
.window(Time.of(5, TimeUnit.MINUTES))
//sum up tuple field "1"
.sum(1);
// print result in command line
counts.print();
// execute program
env.execute("Socket Incremental WordCount Example");
}](https://image.slidesharecdn.com/flinkstreambasics-151019145955-lva1-app6891/85/Apache-Flink-Training-DataStream-API-Part-1-Basic-7-320.jpg)
![Transformations
8
public static void main(String[] args) throws Exception {
// set up the execution environment
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Integer>> counts = env
// read stream of words from socket
.socketTextStream("localhost", 9999)
// split up the lines in tuples containing: (word,1)
.flatMap(new Splitter())
// group by the tuple field "0"
.groupBy(0)
// keep the last 5 minute of data
.window(Time.of(5, TimeUnit.MINUTES))
//sum up tuple field "1"
.sum(1);
// print result in command line
counts.print();
// execute program
env.execute("Socket Incremental WordCount Example");
}](https://image.slidesharecdn.com/flinkstreambasics-151019145955-lva1-app6891/85/Apache-Flink-Training-DataStream-API-Part-1-Basic-8-320.jpg)
![User functions
9
public static void main(String[] args) throws Exception {
// set up the execution environment
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Integer>> counts = env
// read stream of words from socket
.socketTextStream("localhost", 9999)
// split up the lines in tuples containing: (word,1)
.flatMap(new Splitter())
// group by the tuple field "0"
.groupBy(0)
// keep the last 5 minute of data
.window(Time.of(5, TimeUnit.MINUTES))
//sum up tuple field "1"
.sum(1);
// print result in command line
counts.print();
// execute program
env.execute("Socket Incremental WordCount Example");
}](https://image.slidesharecdn.com/flinkstreambasics-151019145955-lva1-app6891/85/Apache-Flink-Training-DataStream-API-Part-1-Basic-9-320.jpg)
![DataSinks
10
public static void main(String[] args) throws Exception {
// set up the execution environment
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Integer>> counts = env
// read stream of words from socket
.socketTextStream("localhost", 9999)
// split up the lines in tuples containing: (word,1)
.flatMap(new Splitter())
// group by the tuple field "0"
.groupBy(0)
// keep the last 5 minute of data
.window(Time.of(5, TimeUnit.MINUTES))
//sum up tuple field "1"
.sum(1);
// print result in command line
counts.print();
// execute program
env.execute("Socket Incremental WordCount Example");
}](https://image.slidesharecdn.com/flinkstreambasics-151019145955-lva1-app6891/85/Apache-Flink-Training-DataStream-API-Part-1-Basic-10-320.jpg)
![Execute!
11
public static void main(String[] args) throws Exception {
// set up the execution environment
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Integer>> counts = env
// read stream of words from socket
.socketTextStream("localhost", 9999)
// split up the lines in tuples containing: (word,1)
.flatMap(new Splitter())
// group by the tuple field "0"
.groupBy(0)
// keep the last 5 minute of data
.window(Time.of(5, TimeUnit.MINUTES))
//sum up tuple field "1"
.sum(1);
// print result in command line
counts.print();
// execute program
env.execute("Socket Incremental WordCount Example");
}](https://image.slidesharecdn.com/flinkstreambasics-151019145955-lva1-app6891/85/Apache-Flink-Training-DataStream-API-Part-1-Basic-11-320.jpg)
![Window WordCount: FlatMap
public static class Splitter
implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value,
Collector<Tuple2<String, Integer>> out)
throws Exception {
// normalize and split the line
String[] tokens = value.toLowerCase().split("W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(
new Tuple2<String, Integer>(token, 1));
}
}
}
}
12](https://image.slidesharecdn.com/flinkstreambasics-151019145955-lva1-app6891/85/Apache-Flink-Training-DataStream-API-Part-1-Basic-12-320.jpg)
![WordCount: Map: Interface
13
public static class Splitter
implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value,
Collector<Tuple2<String, Integer>> out)
throws Exception {
// normalize and split the line
String[] tokens = value.toLowerCase().split("W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(
new Tuple2<String, Integer>(token, 1));
}
}
}
}](https://image.slidesharecdn.com/flinkstreambasics-151019145955-lva1-app6891/85/Apache-Flink-Training-DataStream-API-Part-1-Basic-13-320.jpg)
![WordCount: Map: Types
14
public static class Splitter
implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value,
Collector<Tuple2<String, Integer>> out)
throws Exception {
// normalize and split the line
String[] tokens = value.toLowerCase().split("W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(
new Tuple2<String, Integer>(token, 1));
}
}
}
}](https://image.slidesharecdn.com/flinkstreambasics-151019145955-lva1-app6891/85/Apache-Flink-Training-DataStream-API-Part-1-Basic-14-320.jpg)
![WordCount: Map: Collector
15
public static class Splitter
implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value,
Collector<Tuple2<String, Integer>> out)
throws Exception {
// normalize and split the line
String[] tokens = value.toLowerCase().split("W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(
new Tuple2<String, Integer>(token, 1));
}
}
}
}](https://image.slidesharecdn.com/flinkstreambasics-151019145955-lva1-app6891/85/Apache-Flink-Training-DataStream-API-Part-1-Basic-15-320.jpg)





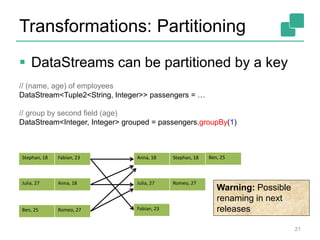
















The document provides an overview of Apache Flink's DataStream API for stream processing. It discusses key concepts like stream execution environments, data types (including tuples), transformations (such as map, filter, grouping), data sources (files, sockets, collections), sinks, and fault tolerance through checkpointing. The document also contains examples of a WordCount application using the DataStream API in Java.











































































































