

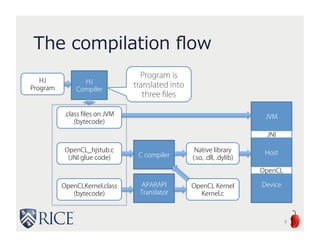
![OpenCL Kernel
JNI
OpenCL
APIs
JNI
Motivation:
GPU Execution From Java
JNIEXPORT void JNICALL_Java_Test (…) {
void ∗aptr = (env)−>GetPrimitiveArrayCritical(arrays , 0);
...
/∗ Create Buffer ∗/
Aobj = clCreateBuffer(context, …);
/∗ Host to Device Communication ∗/
clEnqueueWriteBuffer(queue, Aobj, …);
/∗ Kernel Compilation ∗/
/* Kernel Invocation */
…
(env)−>ReleasePrimitiveArrayCritical(arrays, aptr, 0);
__kernel
void run(…) {
int gid = …;
A[gid] = …;
}
Utilizing GPU from Java adds non-trivial
amount of work
3](https://image.slidesharecdn.com/akihiro-140528151928-phpapp01/85/Speculative-Execution-of-Parallel-Programs-with-Precise-Exception-Semantics-on-GPUs-3-320.jpg)
![Computation Body
RootBeer
API
Related Work:
RootBeer
Still requires special API invocation in
addition to computation body
4
int[][] arrays = new int[N][M];
int[] result = new int[N];
... arrays initialization ...
List<Kernel> jobs =
new ArrayList<Kernel>();
for(int i = 0; i < N; i++) {
jobs.add(
new ArraySumKernel(
arrays[i], result, i)
);
}
Rootbeer rootbeer = new Rootbeer();
rootbeer.runAll(jobs);
class ArraySumKernel
implements Kernel {
private int[] source;
private int[] ret;
private int index;
public void gpuMethod() {
int sum = 0;
for(int i = 0; i< N; i++) {
sum += source[i];
}
ret[index] = sum;
}
}](https://image.slidesharecdn.com/akihiro-140528151928-phpapp01/85/Speculative-Execution-of-Parallel-Programs-with-Precise-Exception-Semantics-on-GPUs-4-320.jpg)



![HJ OpenCL
Implementation
HJ-OpenCL Example
→Programmers can utlize OpenCL by just replacing for with fora
8
public class ArraySum {
public static void main(String[] args) {
int[] base = new int[N*M];
int[] result = new int[N];
int[.] arrays = new arrayView(base, 0, [0:N-1,0:M-1]);
... initialization ...
boolean isSafe = ...;
forall(point [i] : [0:N-1]) {
result[i] = 0;
for(int j=0; j<M; j++) {
result[i] += arrays[i,j];
}
}
}
}](https://image.slidesharecdn.com/akihiro-140528151928-phpapp01/85/Speculative-Execution-of-Parallel-Programs-with-Precise-Exception-Semantics-on-GPUs-8-320.jpg)


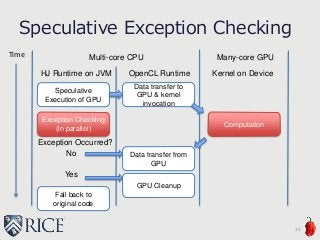
![Basic Idea:
Non-Speculative Exception Checking
12
Exception
Checking
(in parallel)
Multicore-CPU GPU
Non-Speculative
Exception
Checking
Code
boolean excpFlag = false;
/* (1) Exception Checking Code on JVM */
try {
forall (point [i]:[0:N-1]) {
… = A[i];
}
} catch (Exception e) {
excpFlag = true;
}
/* (2) JNI Call */
if (!excpFlag) {
openCL_Kernel();
} else{
// Original Implementation on JVM
forall() {}
}
Host to device
Data Transfer
Computation
Device to host
Data Transfer
No Exception
Time
Same as
original Forall
except
ArrayStore](https://image.slidesharecdn.com/akihiro-140528151928-phpapp01/85/Speculative-Execution-of-Parallel-Programs-with-Precise-Exception-Semantics-on-GPUs-12-320.jpg)
![Proposed Idea:
Speculative Exception Checking
13
Exception
Checking
(in parallel)
Multicore-CPU GPU
Speculative
Exception
Checking
Code
boolean excpFlag = false;
/* JNI Call 1*/
openCL_Kernel1();
/* (2) Exception Checking Code on JVM */
try {
forall (point [i]:[0:N-1]) {
… = A[i];
}
} catch (Exception e) {
excpFlag = true;
}
/* (2) JNI Call */
openCL_Kernel2(excpFlag);
if (excpFlag) {
// Original Implementation on JVM
forall() {}
}
Host to device
Data Transfer
Computation
Device to host
Data Transfer
No Exception
Time
Same as
original Forall
except
ArrayStore](https://image.slidesharecdn.com/akihiro-140528151928-phpapp01/85/Speculative-Execution-of-Parallel-Programs-with-Precise-Exception-Semantics-on-GPUs-13-320.jpg)

![The exception checking code
optimization algorithm
Key Idea
Delete statements which do not derive
array subscripts and denominator of
division statement by considering control
flow
15
i = …;
X = …;
Y = …;
… = A[i] + X;
… = B[i] / Y;
Before
i = …;
X = …;
Y = …;
… = A[i] + X;
… = B[i] / Y;
After](https://image.slidesharecdn.com/akihiro-140528151928-phpapp01/85/Speculative-Execution-of-Parallel-Programs-with-Precise-Exception-Semantics-on-GPUs-15-320.jpg)
![Exception Checking Code
Optimization Example
forall (point [i]:[0:N-1]) {
A[Index[i]] = B[i] + C[i];
}
// IR
$i2 = Index[i];
$i3 = B[i];
$i4 = C[i];
$i5 = $i3 + $i4;
A[$i2] = $i5;
// IR
$i2 = Index[i];
$i3 = B[i];
$i4 = C[i];
$i5 = $i3 + $i4;
dummy = A[$i2]
mark
// IR
$i2 = Index[i];
$i3 = B[i];
$i4 = C[i];
delete
dummy = A[$i2]
// IR
$i2 = Index[i];
$i3 = B[i];
$i4 = C[i];
dummy = A[$i2]
Dummy read
Optimized Code
16](https://image.slidesharecdn.com/akihiro-140528151928-phpapp01/85/Speculative-Execution-of-Parallel-Programs-with-Precise-Exception-Semantics-on-GPUs-16-320.jpg)







![next construct (cont’d)
33
forall (point [i]:[0:n-1]) {
method1(i);
// synchronization point 1
next;
method2(i);
// synchronization point 2
next;
}
Thread0
method1(0);
Thread1
method1(1);
WAIT
method2(0); method2(1);
WAIT](https://image.slidesharecdn.com/akihiro-140528151928-phpapp01/85/Speculative-Execution-of-Parallel-Programs-with-Precise-Exception-Semantics-on-GPUs-33-320.jpg)
![“ArrayView” for Supporting
Contiguous Multidimensional
array
HJ ArrayView is backed by one-dimensional Java Array
Enables reduction of data transfer between
host and device
Java Array
A[i][j]
HJ Array View
A[i, j]
0
1
2
0
0
1
2
0 1
0 1 2 3
A[0][1]
A[0,1]
34](https://image.slidesharecdn.com/akihiro-140528151928-phpapp01/85/Speculative-Execution-of-Parallel-Programs-with-Precise-Exception-Semantics-on-GPUs-34-320.jpg)

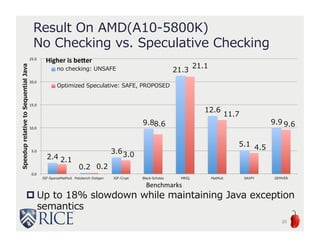
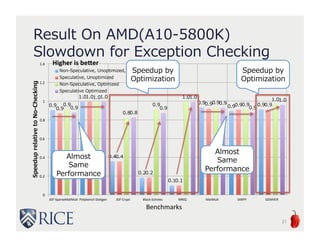
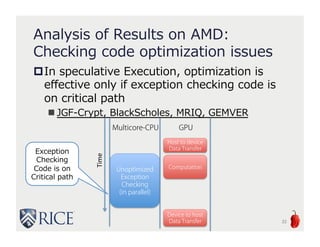
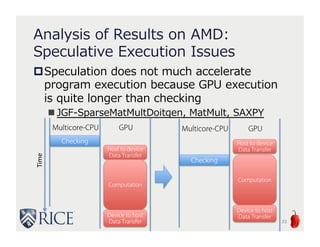
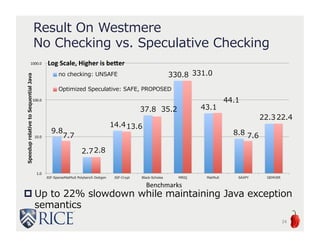
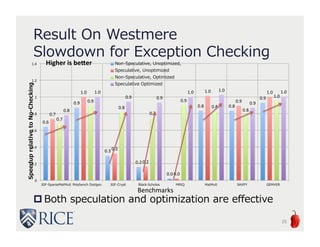
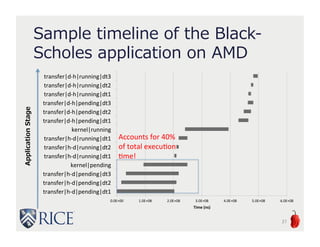
The document presents an approach to leveraging OpenCL for GPU programming within a Java environment through the use of Habanero Java (HJ) and automatic kernel generation. It emphasizes the importance of maintaining precise exception semantics during parallel execution and introduces speculative exception checking as a method to optimize execution times. Experimental results indicate significant performance improvements, with speedups of up to 21x on AMD hardware and 330x on NVIDIA GPUs while handling exceptions correctly.




![[嵌入式系統] MCS-51 實驗 - 使用 IAR (3)](https://cdn.slidesharecdn.com/ss_thumbnails/mcs51iarpart3-150613071723-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[ZigBee 嵌入式系統] ZigBee 應用實作 - 使用 TI Z-Stack Firmware](https://cdn.slidesharecdn.com/ss_thumbnails/zigbeeappimplementation-150613072040-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[嵌入式系統] MCS-51 實驗 - 使用 IAR (2)](https://cdn.slidesharecdn.com/ss_thumbnails/mcs51iarpart2-150613071717-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




































































