

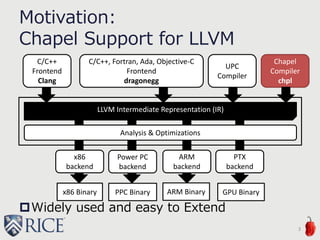




![Address Space 100 generation
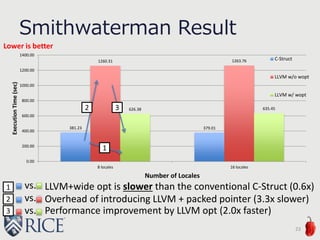
in Chapel
Address space 100 = possibly-remote
(our convention)
Constructs which generate address space 100
Array Load/Store (Except Local constructs)
Distributed Array
var d = {1..128} dmapped Block(boundingBox={1..128});
var A: [d] int;
Object and Field Load/ Store
class circle { var radius: real; … }
var c1 = new circle(radius=1.0);
On statement
var loc0: int;
on Locales[1] { loc0 = …; }
Ref intent
proc habanero(ref v: int): void { v = …; }
10
Except remote value
forwarding optimization](https://image.slidesharecdn.com/akihiro-140528152443-phpapp02/85/LLVM-Optimizations-for-PGAS-Programs-Case-Study-LLVM-Wide-Optimization-in-Chapel-10-320.jpg)





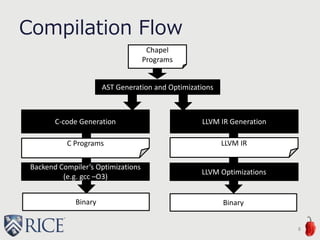
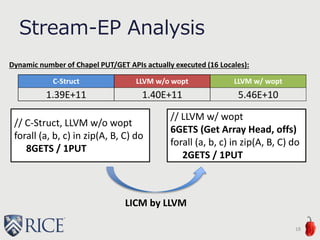
![Stream-EP
From HPCC benchmark
Array Size: 2^30
16
coforall loc in Locales do on loc {
// per each locale
var A, B, C: [D] real(64);
forall (a, b, c) in zip(A, B, C) do
a = b + alpha * c;
}](https://image.slidesharecdn.com/akihiro-140528152443-phpapp02/85/LLVM-Optimizations-for-PGAS-Programs-Case-Study-LLVM-Wide-Optimization-in-Chapel-16-320.jpg)
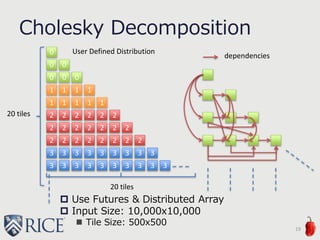


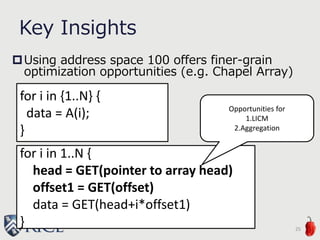

![Future Work
Evaluate other applications
Regular applications
Irregular applications
Possibly-Remote to Definitely-Local
transformation by compiler
PIR in LLVM
27
local { A(i) = … } // hint by programmmer
… = A(i); // Definitely Local
on Locales[1] { // hint by programmer
var A: [D] int; // Definitely Local](https://image.slidesharecdn.com/akihiro-140528152443-phpapp02/85/LLVM-Optimizations-for-PGAS-Programs-Case-Study-LLVM-Wide-Optimization-in-Chapel-27-320.jpg)


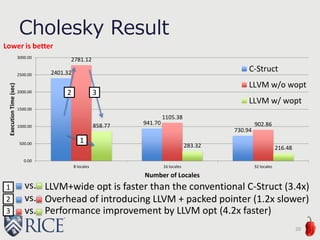
![// modules/internal/DefaultRectangular.chpl
class DefaultRectangularArr: BaseArr {
...
var dom : DefaultRectangularDom(rank=rank, idxType=idxType,
stridable=stridable); /* domain */
var off: rank*idxType; /* per-dimension offset (n-based-> 0-based) */
var blk: rank*idxType; /* per-dimension multiplier */
var str: rank*chpl__signedType(idxType); /* per-dimimension stride */
var origin: idxType; /* used for optimization */
var factoredOffs: idxType; /* used for calculating shiftedData */
var data : _ddata(eltType); /* pointer to an actual data */
var shiftedData : _ddata(eltType); /* shifted pointer to an actual data */
var noinit: bool = false;
...
Chapel Array Structure
30
// chpl_module.bc (with LLVM code generation)
%chpl_DefaultRectangularArr_int64_t_1_int64_t_F_object = type
{ %chpl_BaseArr_object, %chpl_DefaultRectangularDom_1_int64_t_F_object*, [1 x i64], [1 x i64], [1 x
i64], i64, i64, i64*, i64*, i8 }](https://image.slidesharecdn.com/akihiro-140528152443-phpapp02/85/LLVM-Optimizations-for-PGAS-Programs-Case-Study-LLVM-Wide-Optimization-in-Chapel-30-320.jpg)



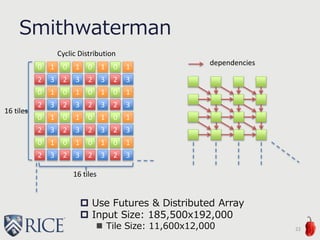
![define internal fastcc void @habanero(%chpl_DefaultRectangularArr_int64_t_1_int64_t_F_object addrspace(100)* %A) #9 {
entry:
// possibly remote access
1: %0 = getelementptr inbounds %chpl_DefaultRectangularArr_int64_t_1_int64_t_F_object addrspace(100)* %A, i64 0,
i32 3, i64 0
2: %agg.tmp = alloca i8, i32 48, align 1
3: %agg.cast = bitcast i64 addrspace(100)* %0 to i8 addrspace(100)*
4: call void @llvm.memcpy.p0i8.p100i8.i64(i8* %agg.tmp, i8 addrspace(100)* %agg.cast, i64 48, i32 0, i1 false)
5: %agg.tmp.cast = bitcast i8* %agg.tmp to i64*
6: %1 = load i64* %agg.tmp.cast, align 1
7: %2 = getelementptr inbounds %chpl_DefaultRectangularArr_int64_t_1_int64_t_F_object addrspace(100)* %A, i64 0,
i32 8
8: %agg.tmp.ptr.i = ptrtoint i64 addrspace(100)* addrspace(100)* %2 to i64
9: %agg.tmp.oldb.i = ptrtoint i64 addrspace(100)* %0 to i64
10:%agg.tmp.newb.i = ptrtoint i8* %agg.tmp to i64
11:%agg.tmp.diff = sub i64 %agg.tmp.ptr.i, %agg.tmp.oldb.i
12:%agg.tmp.sum = add i64 %agg.tmp.newb.i, %agg.tmp.diff
13:%agg.tmp.cast10 = inttoptr i64 %agg.tmp.sum to i64 addrspace(100)**
14:%3 = load i64 addrspace(100)** %agg.tmp.cast10, align 1
15:%4 = getelementptr inbounds i64 addrspace(100)* %3, i64 %1
16:store i64 0, i64 addrspace(100)* %4, align 8, !tbaa !0
…
Example2: Generated LLVM IR
34
%0 = A->blk
%2 = A->shiftedData
Sequence of load are merged by aggregation pass
%1 = A-
>blk[0]
Buffer for
aggregation
Offset for getting
A->shifted Data in
buffer
Get pointer of
A(1)
Store 0
memcpy](https://image.slidesharecdn.com/akihiro-140528152443-phpapp02/85/LLVM-Optimizations-for-PGAS-Programs-Case-Study-LLVM-Wide-Optimization-in-Chapel-34-320.jpg)

This document summarizes research on LLVM optimizations for PGAS (Partitioned Global Address Space) programs like Chapel. It discusses generating LLVM IR from Chapel to enable optimizations like LICM (Loop Invariant Code Motion). Evaluations show LLVM optimizations remove many communication operations and improve performance for some applications vs. C code generation. However, LLVM constraints and wide pointer overhead hurt performance for other applications. Future work includes more applications, possibly-remote to definitely-local transformations, and parallel intermediate representations in LLVM.



![CETH for XDP [Linux Meetup Santa Clara | July 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/ceth5overview1-160801192921-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[COSCUP 2021] LLVM Project: The Good, The Bad, and The Ugly](https://cdn.slidesharecdn.com/ss_thumbnails/coscup2021-llvm-210731054723-thumbnail.jpg?width=640&height=640&fit=bounds)












































