Downloaded 38 times











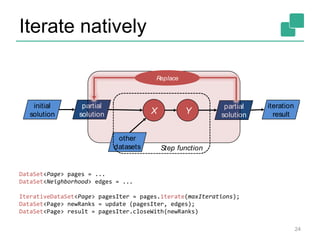
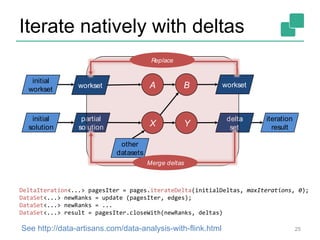
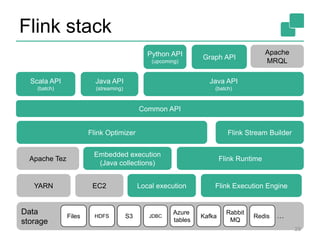
![DataSet<String>
Think of it as a PCollection<String>, or a
Spark RDD[String]
With a major difference: it can be
produced/recovered in several ways
• … like a Java collection
• … like an RDD
• … perhaps it is never fully materialized (because
the program does not need it to)
• … implicitly updated in an iteration
And this is transparent to the user
15](https://image.slidesharecdn.com/flinkinternalsweb-141119101714-conversion-gate02/85/Flink-internals-web-15-320.jpg)





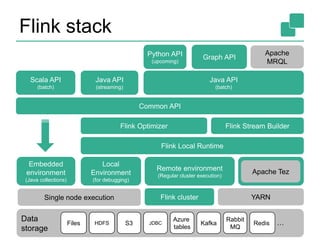

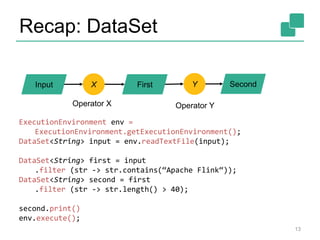
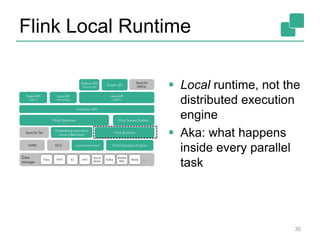
![Two execution plans
34
GroupRed
sort
Combine
Map DataSource
Filter
DataSource
orders.tbl
lineitem.tbl
Join
Hybrid Hash
buildHT probe
broadcast forward
Map DataSource
Filter
DataSource
orders.tbl
lineitem.tbl
Join
Hybrid Hash
buildHT probe
hash-part [0] hash-part [0]
hash-part [0,1]
GroupRed
sort
Best plan forward
depends on
relative sizes
of input files](https://image.slidesharecdn.com/flinkinternalsweb-141119101714-conversion-gate02/85/Flink-internals-web-34-320.jpg)




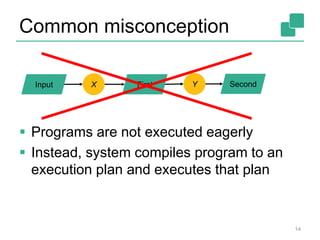
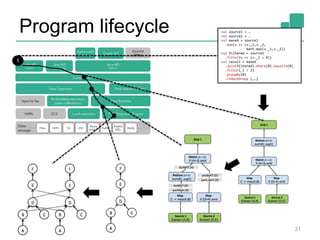
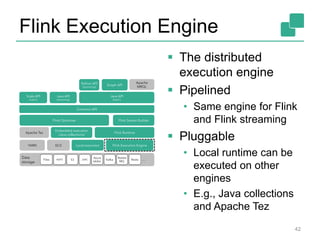
![Memory in Flink (2)
Internal memory management
• Flink initially allocates 70% of the free heap as byte[]
segments
• Internal operators allocate() and release() these
segments
Flink has its own serialization stack
• All accepted data types serialized to data segments
Easy to reason about memory, (almost) no
OutOfMemory errors, reduces the pressure to the
GC (smooth performance)
40](https://image.slidesharecdn.com/flinkinternalsweb-141119101714-conversion-gate02/85/Flink-internals-web-40-320.jpg)











This document provides an overview of the internals of Apache Flink. It discusses how Flink programs are compiled into execution plans by the Flink optimizer and executed in a pipelined fashion by the Flink runtime. The runtime uses optimized implementations of sorting and hashing to represent data internally as serialized bytes, avoiding object overhead. It also describes how Flink handles iterative programs and memory management. Overall, it explains how Flink hides complexity from users while providing high performance distributed processing.























































