Downloaded 42 times

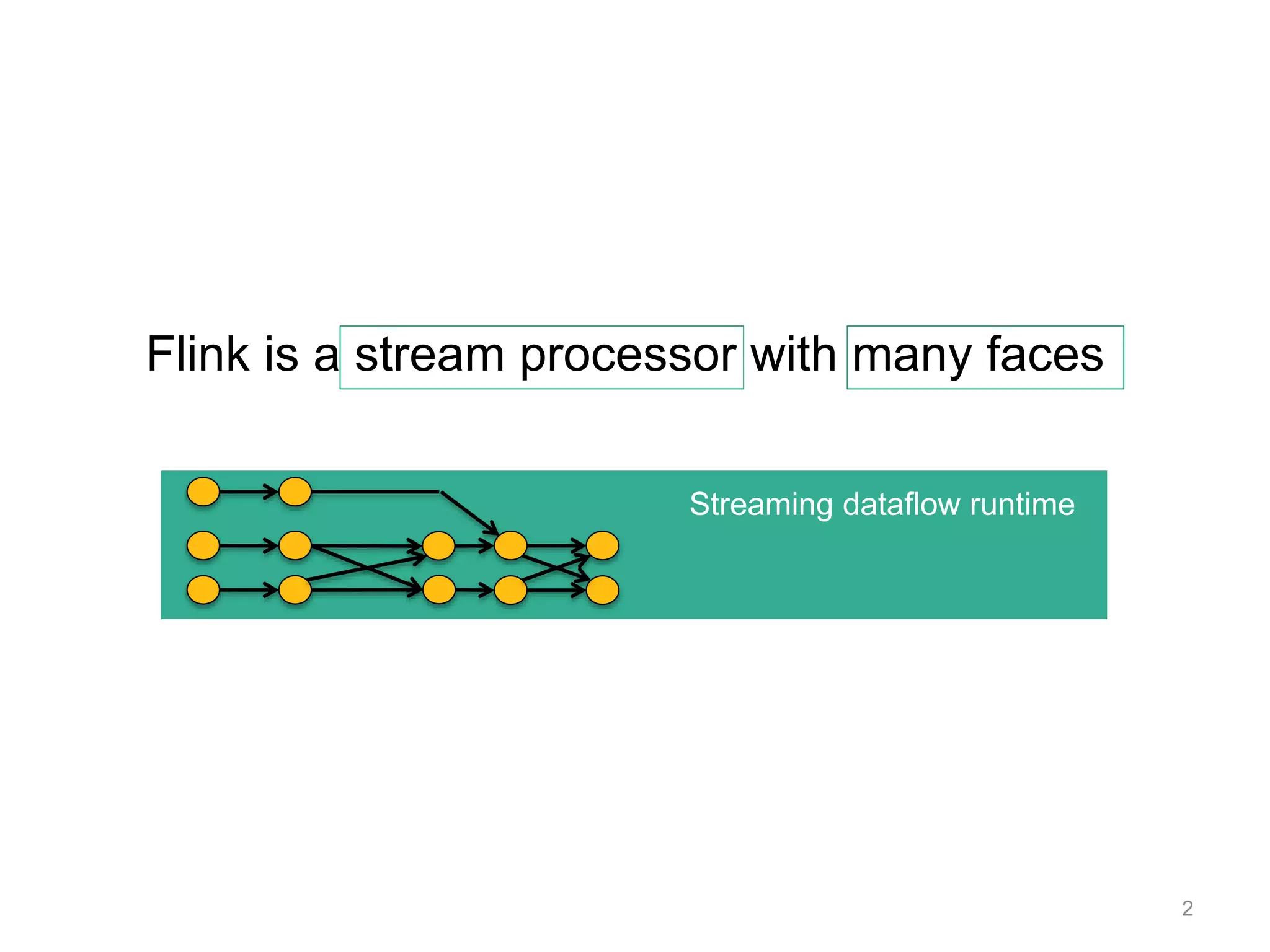
![3
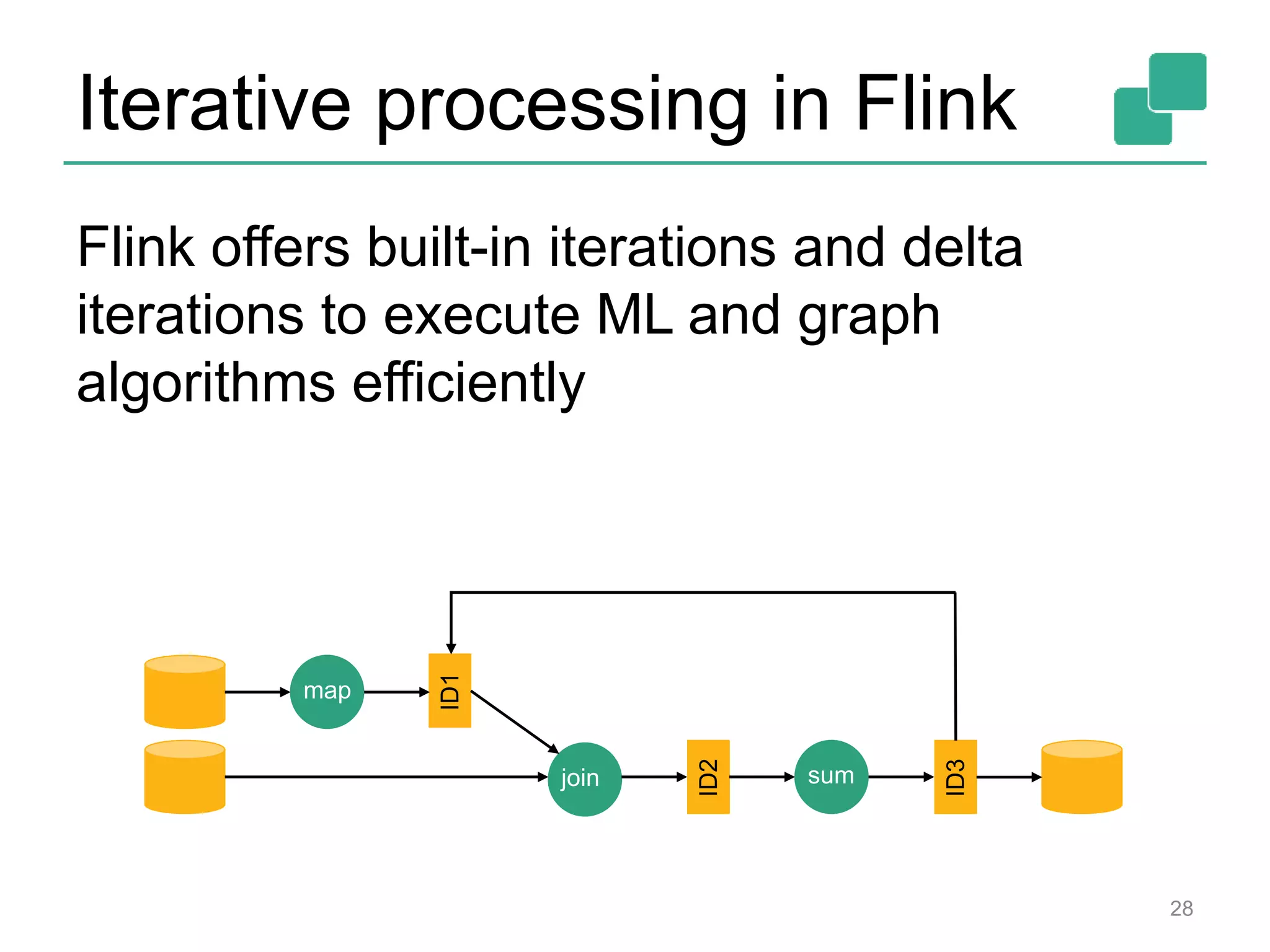
case class Path (from: Long, to:
Long)
val tc = edges.iterate(10) {
paths: DataSet[Path] =>
val next = paths
.join(edges)
.where("to")
.equalTo("from") {
(path, edge) =>
Path(path.from, edge.to)
}
.union(paths)
.distinct()
next
}
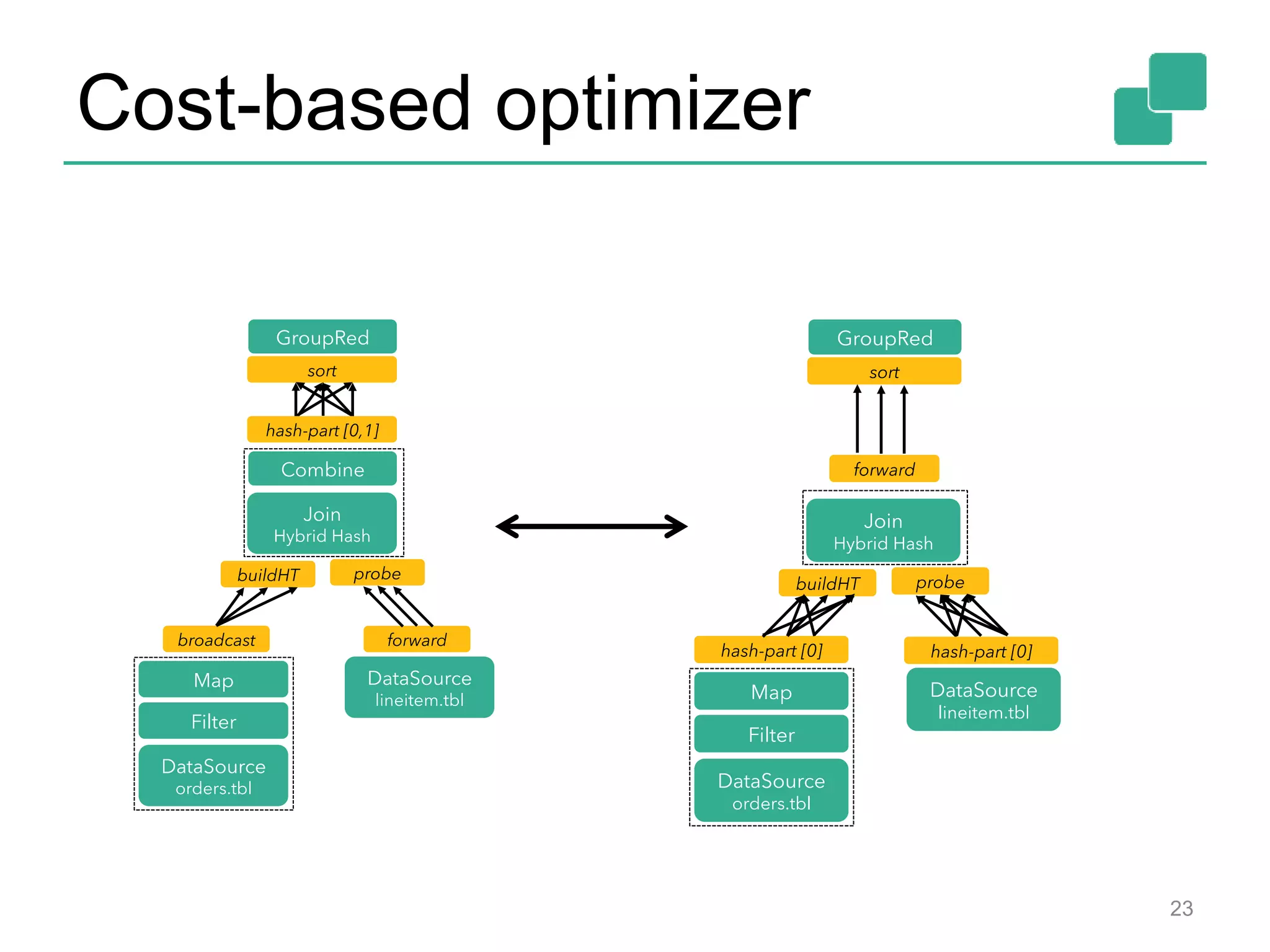
Optimizer
Type extraction
stack
Task
scheduling
Dataflow
metadata
Pre-flight (Client)
JobManager
TaskManagers
Data
Source
orders.tbl
Filter
Map
DataSourc
e
lineitem.tbl
Join
Hybrid Hash
build
HT
probe
hash-part [0] hash-part [0]
GroupRed
sort
forward
Program
Dataflow
Graph
deploy
operators
track
intermediate
results](https://image.slidesharecdn.com/flinkfirstbayareameetupweb-150621010824-lva1-app6891/75/First-Flink-Bay-Area-meetup-3-2048.jpg)

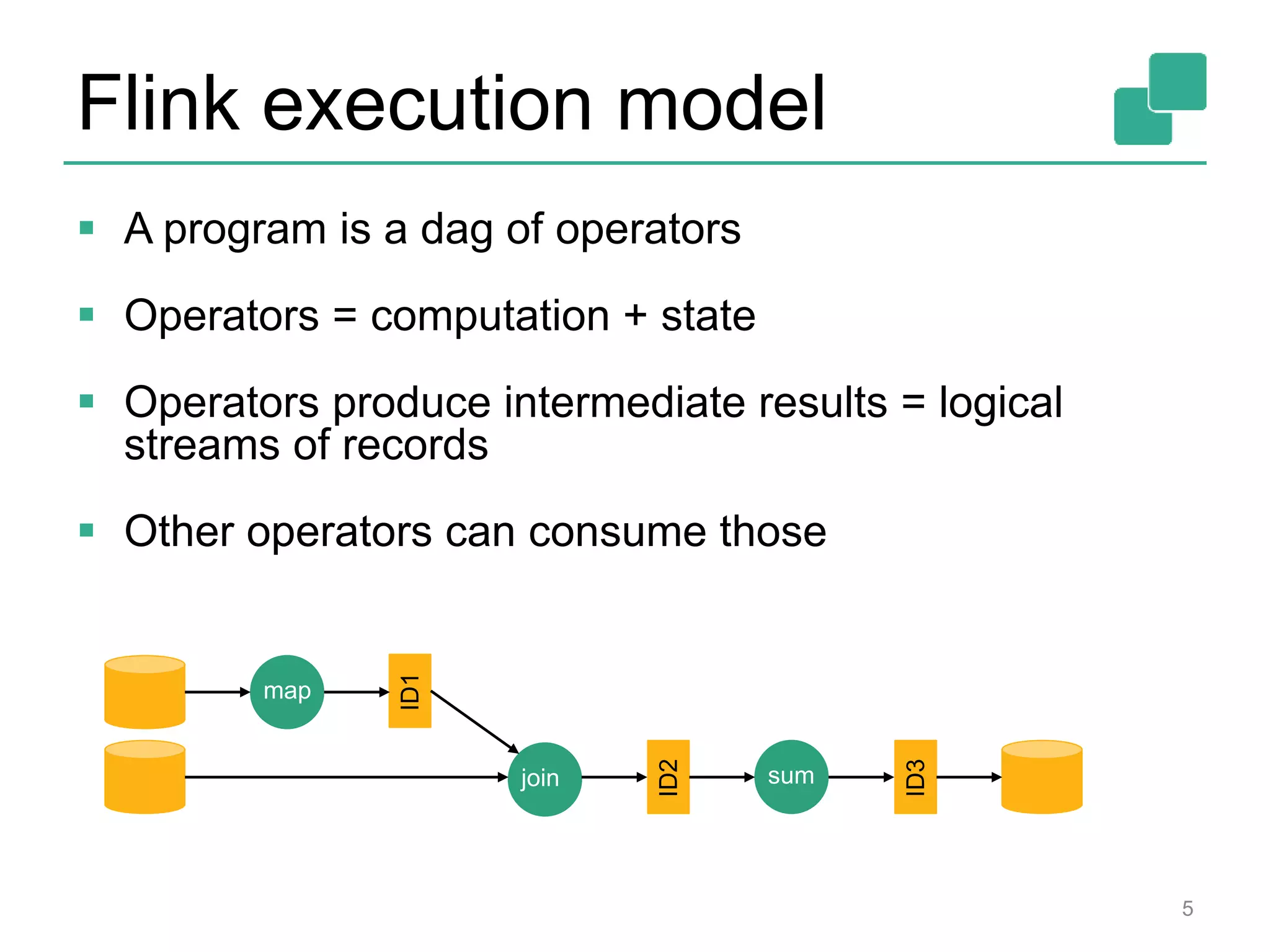



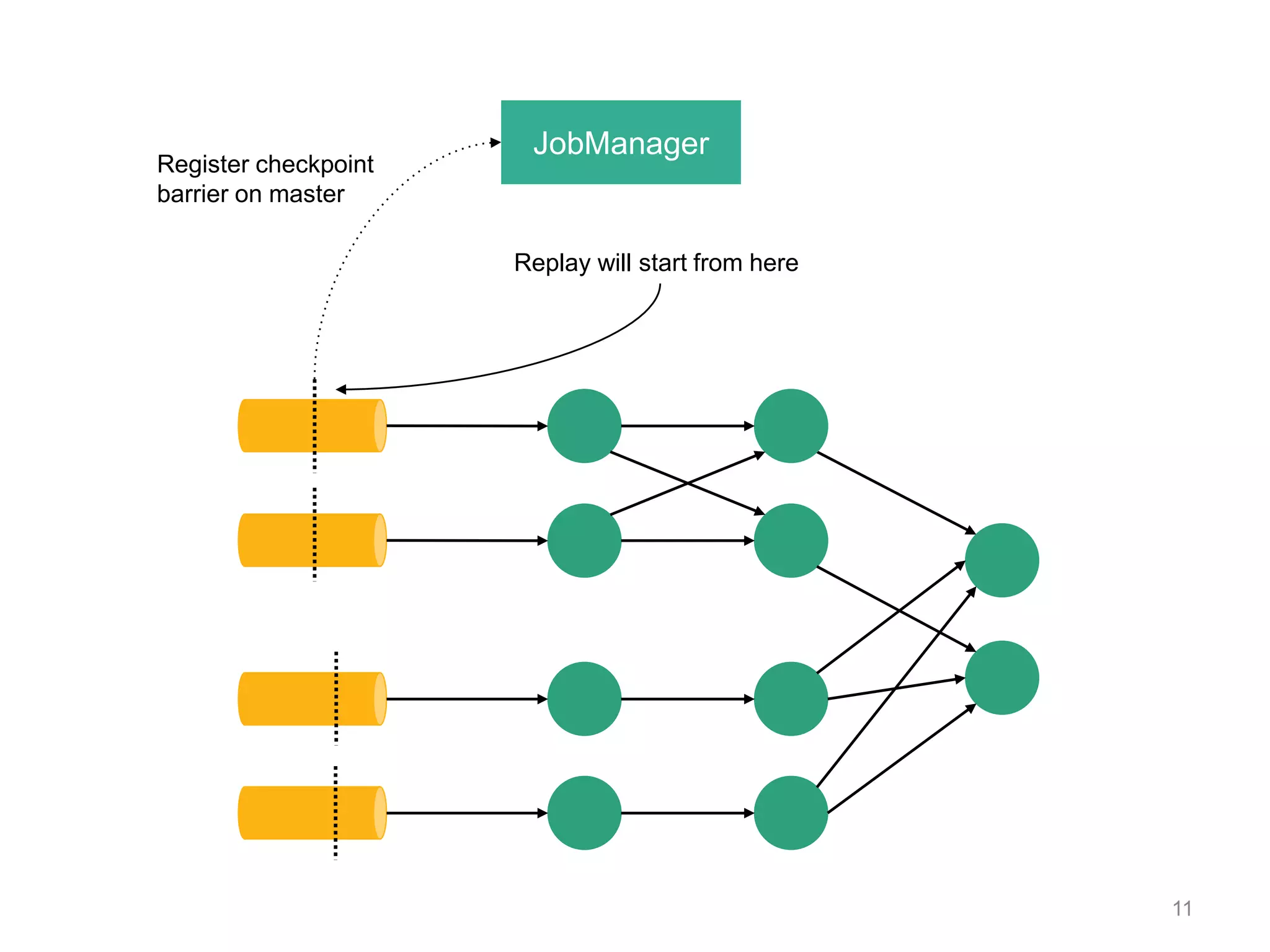
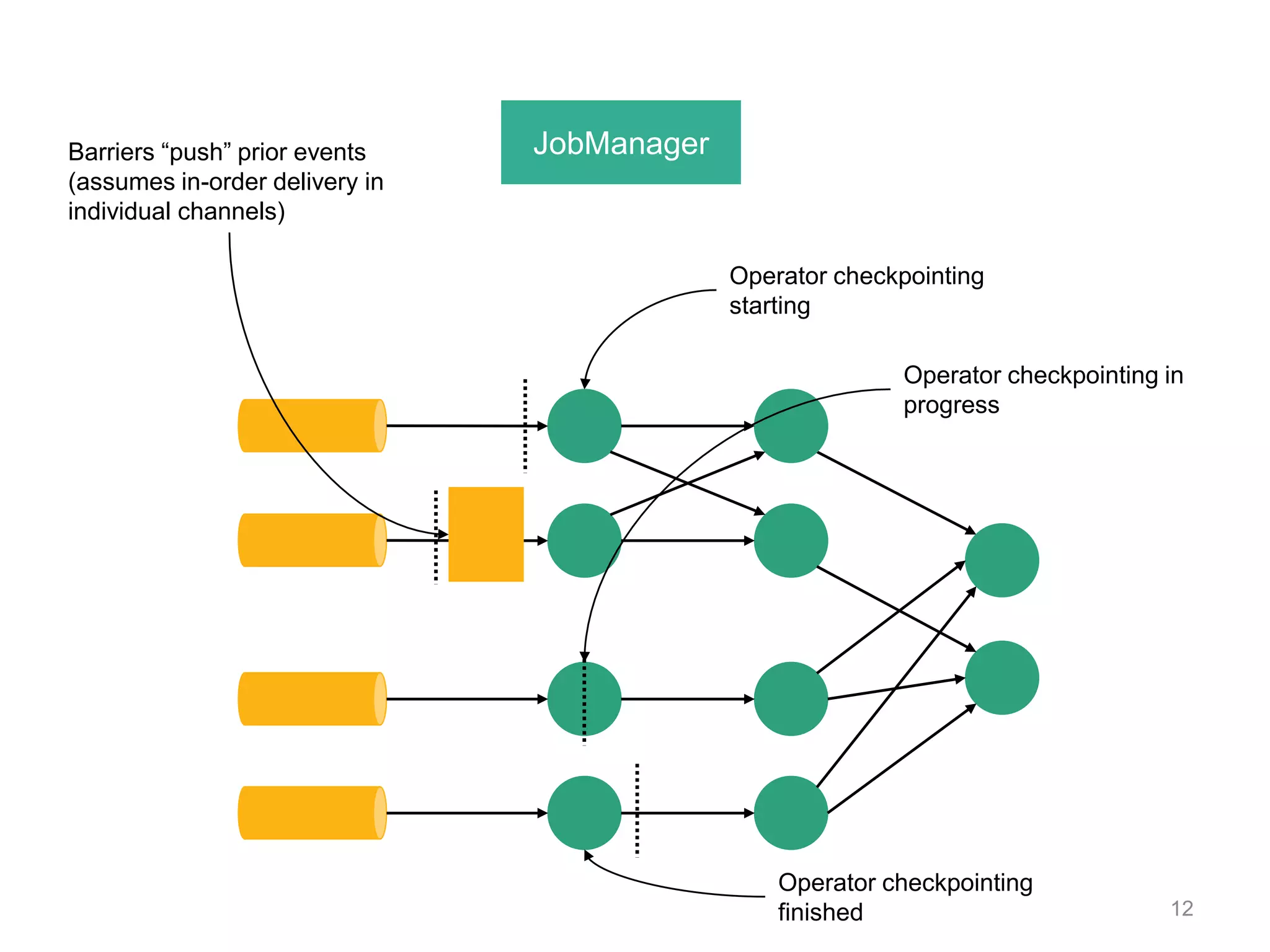
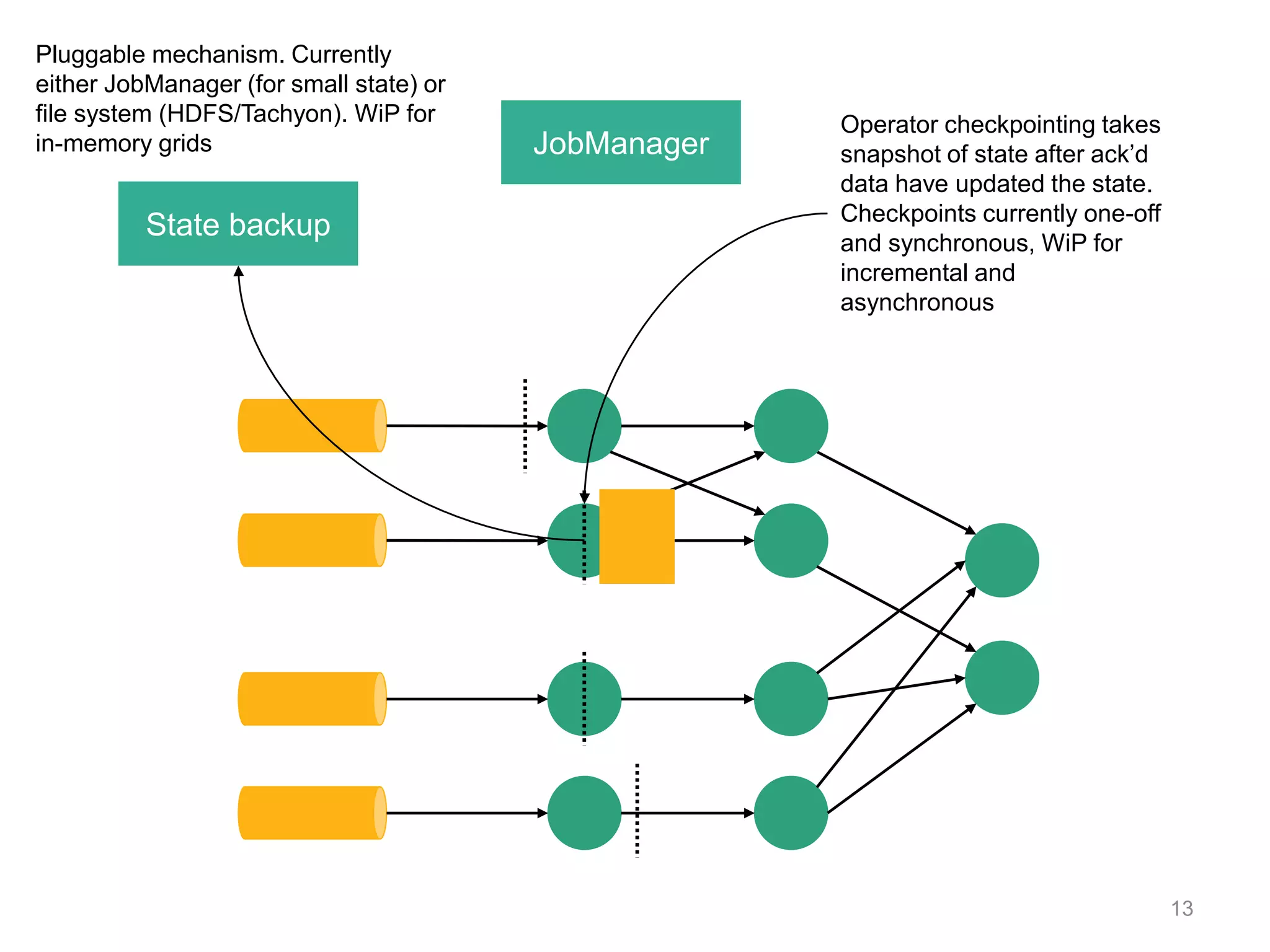
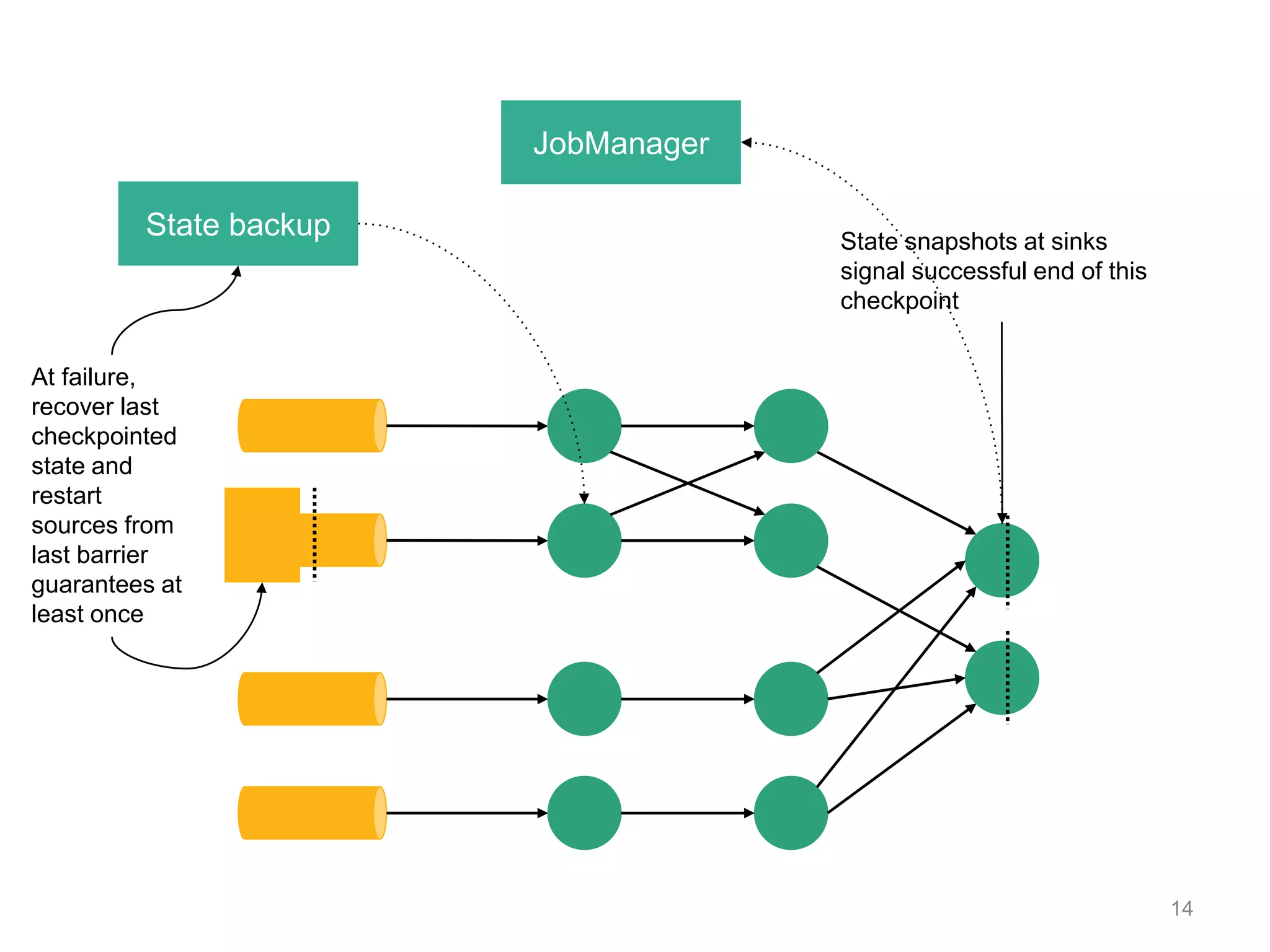


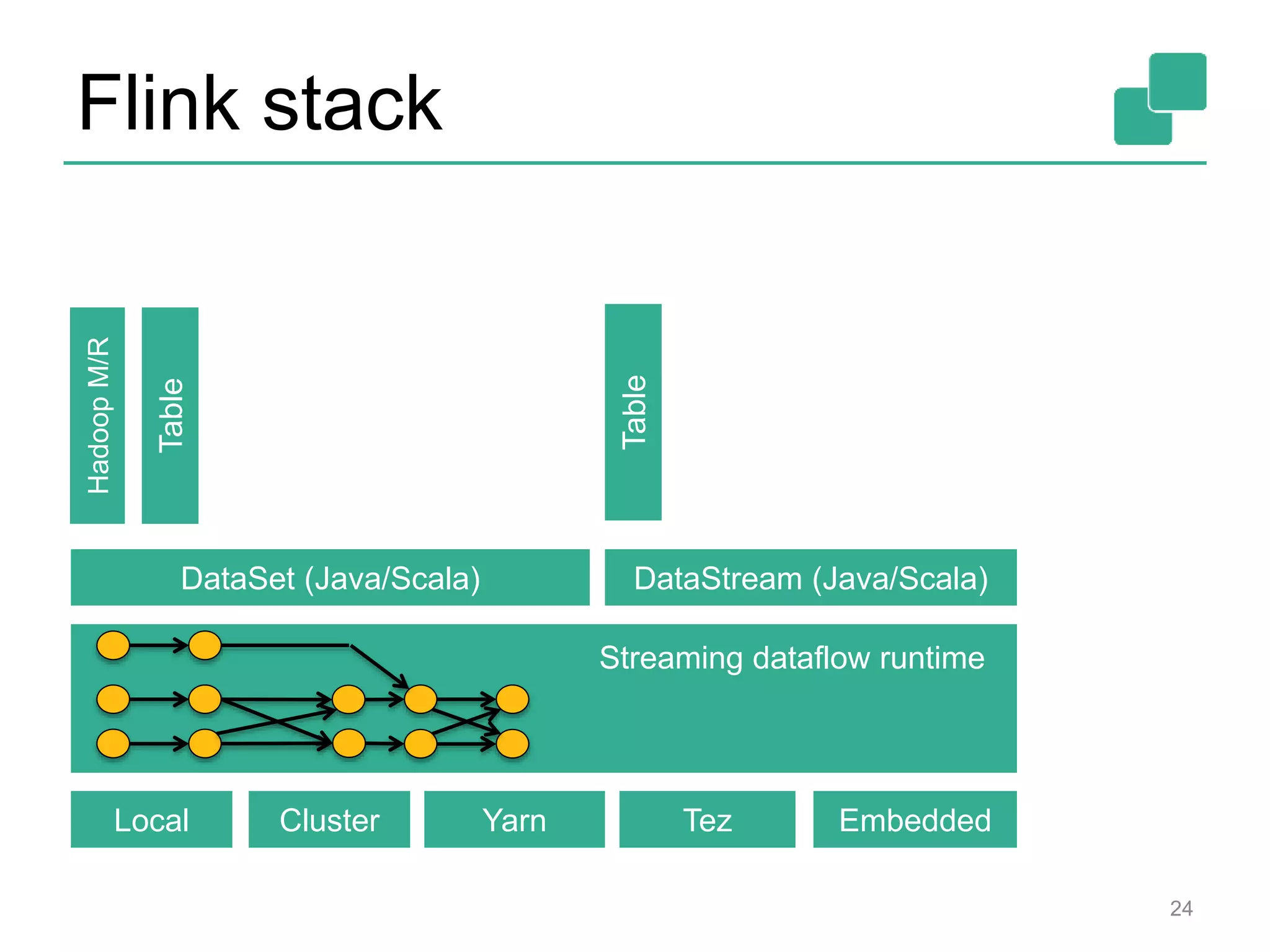
![DataStream API
18
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS))
.groupBy("word").sum("frequency")
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
DataSet API (batch):
DataStream API (streaming):](https://image.slidesharecdn.com/flinkfirstbayareameetupweb-150621010824-lva1-app6891/75/First-Flink-Bay-Area-meetup-18-2048.jpg)


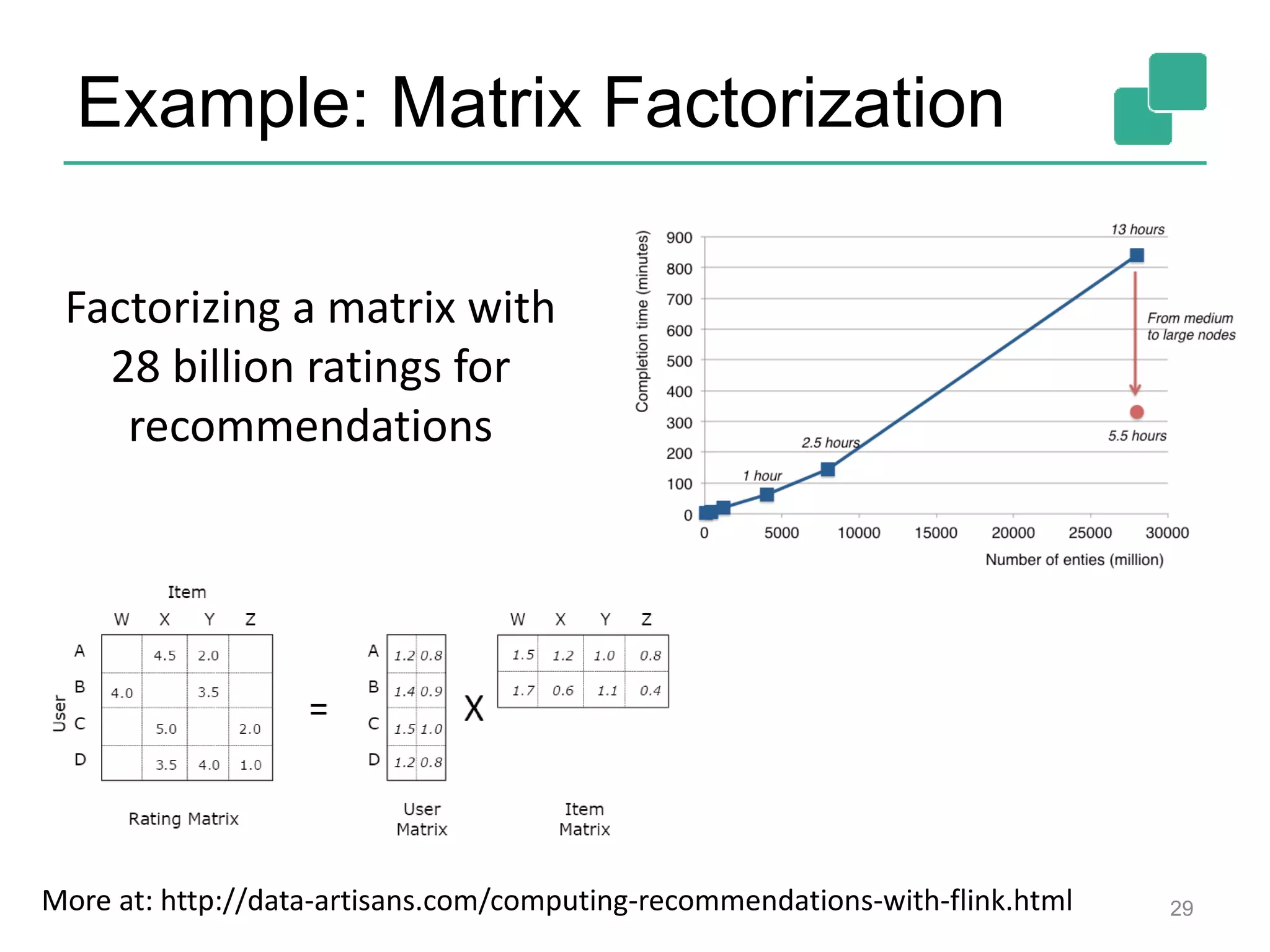
![FlinkML
API for ML pipelines inspired by scikit-learn
Collection of packaged algorithms
• SVM, Multiple Linear Regression, Optimization, ALS, ...
26
val trainingData: DataSet[LabeledVector] = ...
val testingData: DataSet[Vector] = ...
val scaler = StandardScaler()
val polyFeatures = PolynomialFeatures().setDegree(3)
val mlr = MultipleLinearRegression()
val pipeline = scaler.chainTransformer(polyFeatures).chainPredictor(mlr)
pipeline.fit(trainingData)
val predictions: DataSet[LabeledVector] = pipeline.predict(testingData)](https://image.slidesharecdn.com/flinkfirstbayareameetupweb-150621010824-lva1-app6891/75/First-Flink-Bay-Area-meetup-26-2048.jpg)

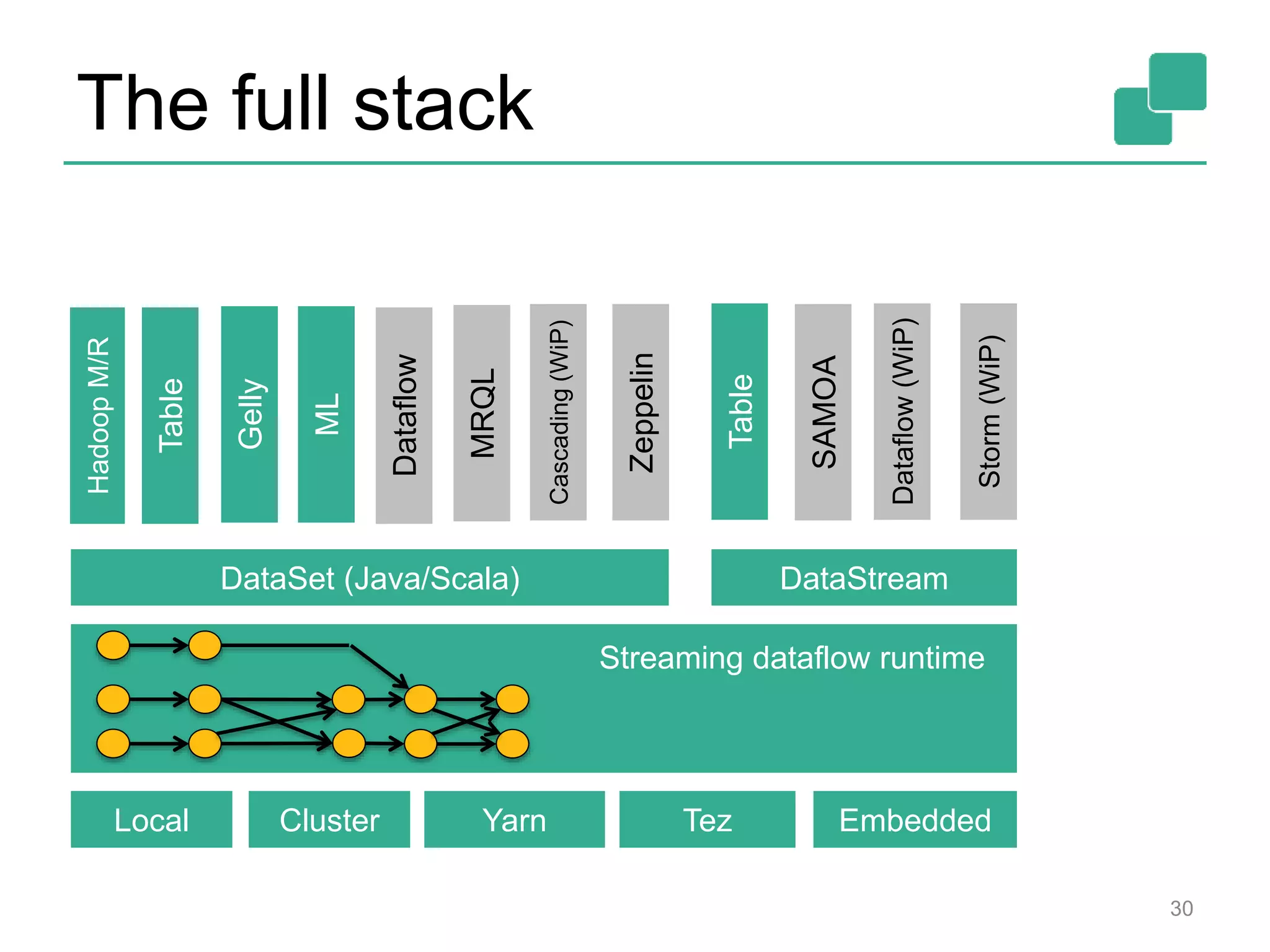






This document introduces Apache Flink, an open-source stream processing framework. It discusses how Flink can be used for both streaming and batch data processing using common APIs. It also summarizes Flink's features like exactly-once stream processing, iterative algorithms, and libraries for machine learning, graphs, and SQL-like queries. The document promotes Flink as a high-performance stream processor that is easy to use and integrates streaming and batch workflows.

































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
