Downloaded 305 times

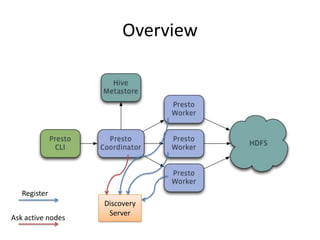
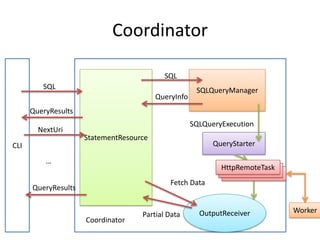
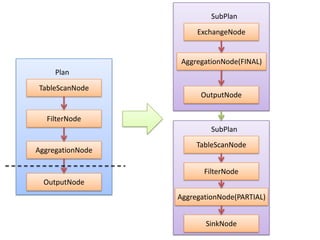
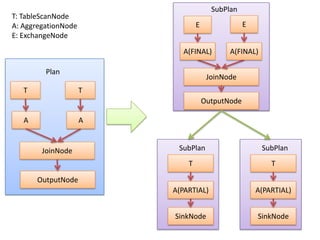
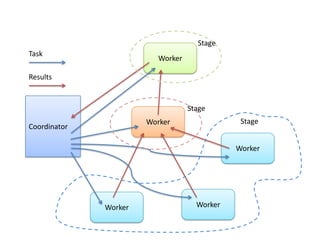

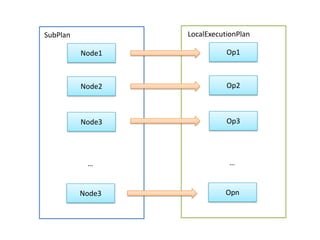
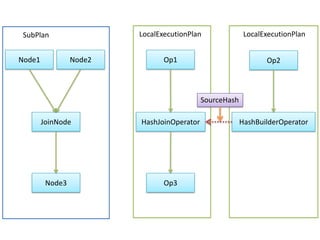

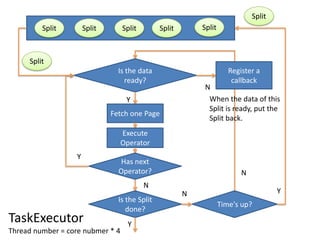

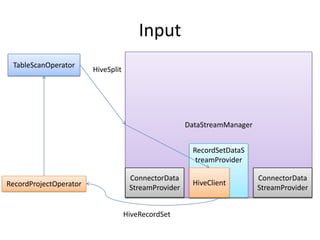







Presto is a distributed SQL query engine that allows users to run SQL queries against various data sources. It consists of three main components - a coordinator, workers, and clients. The coordinator manages query execution by generating execution plans, coordinating workers, and returning final results to the client. Workers contain execution engines that process individual tasks and fragments of a query plan. The system uses a dynamic query scheduler to distribute tasks across workers based on data and node locality.









































































