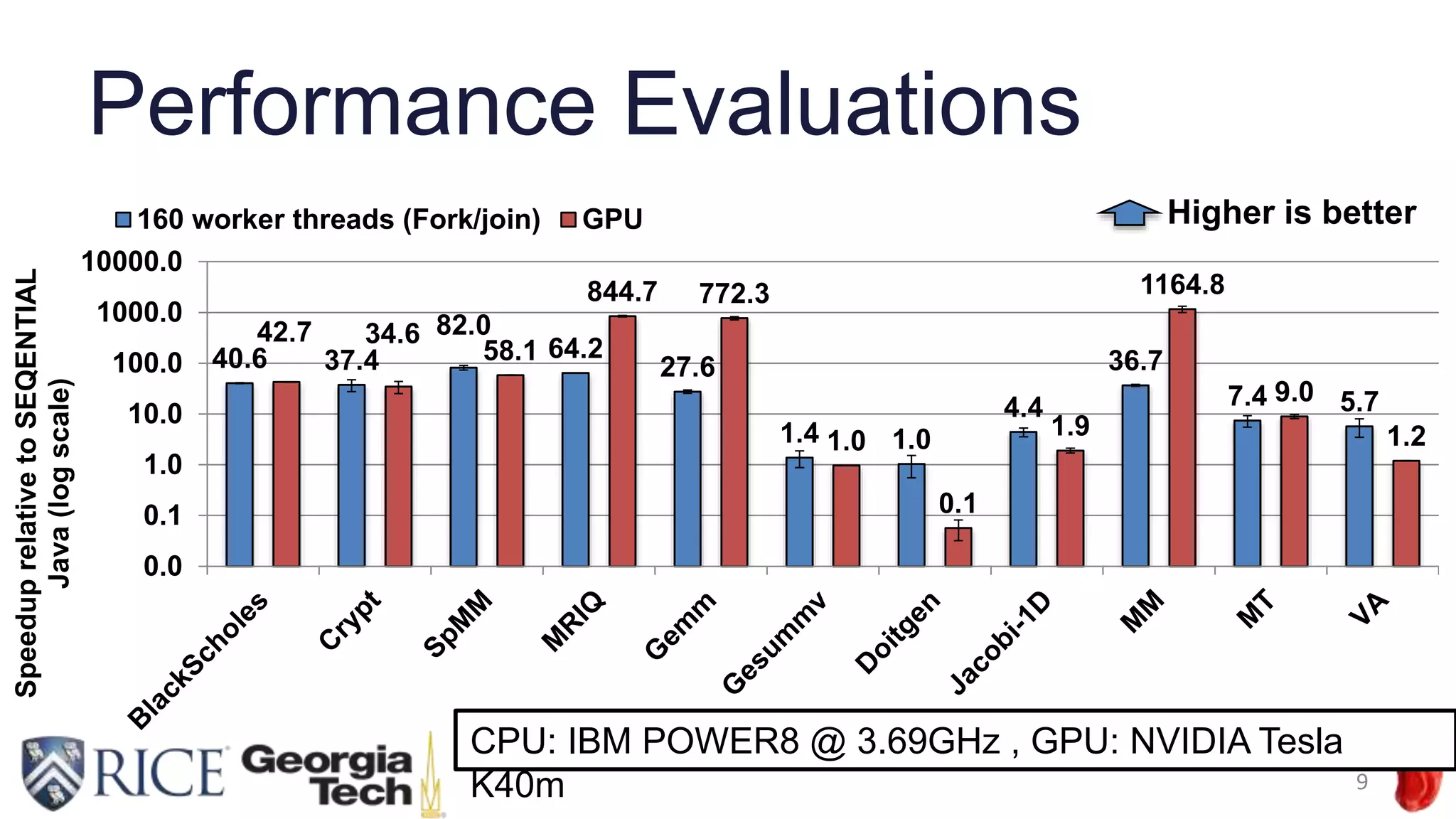
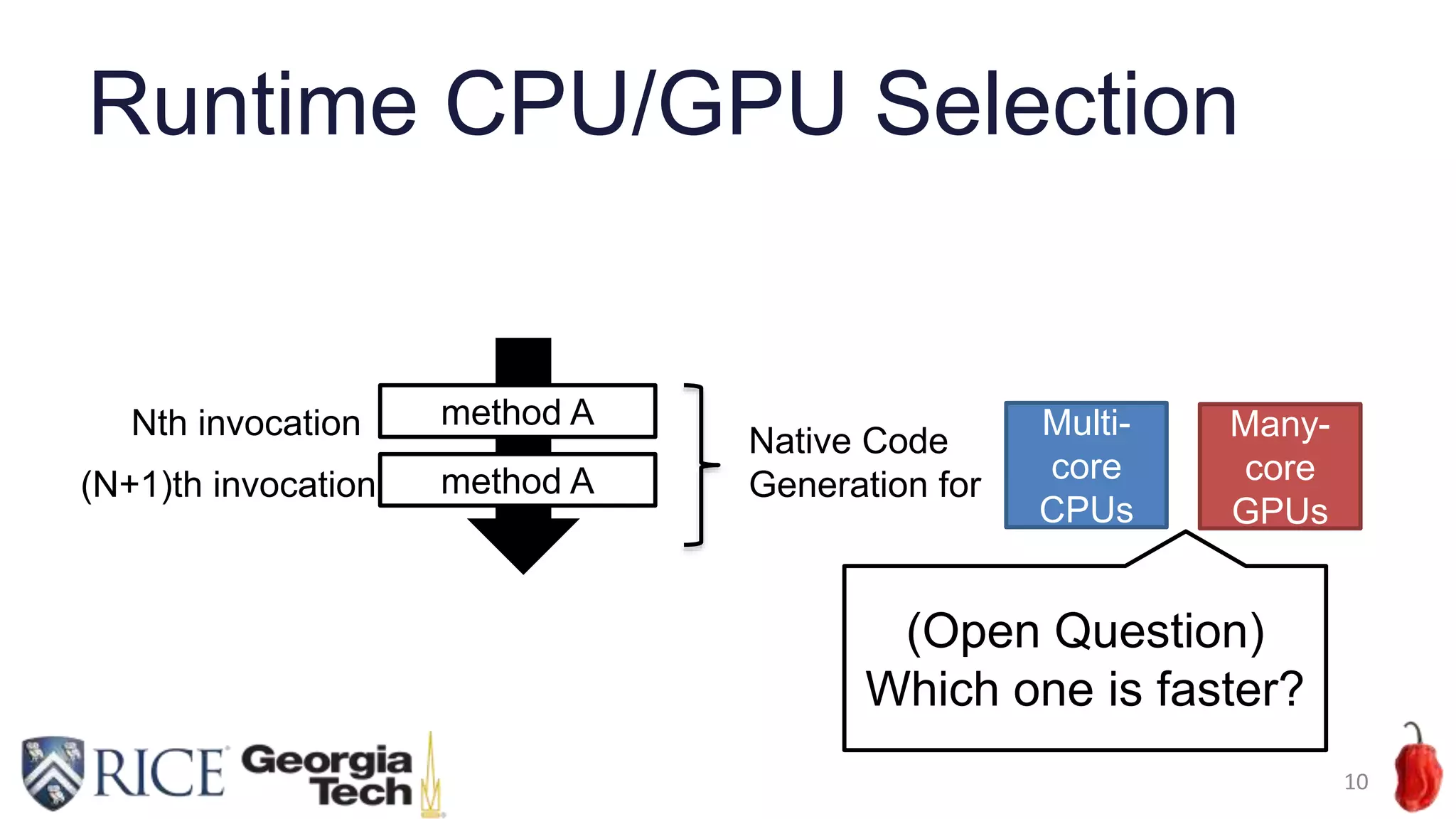
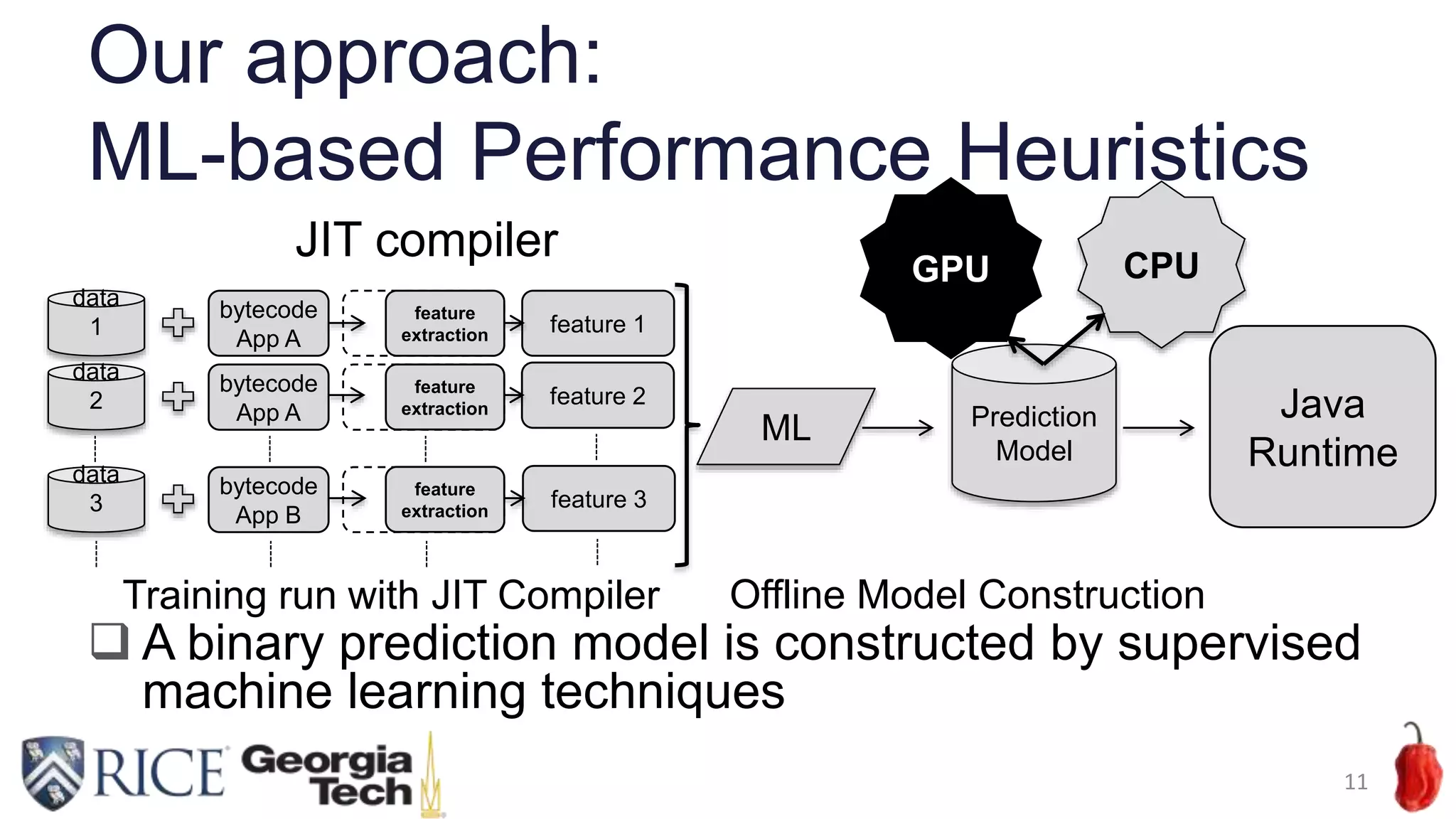
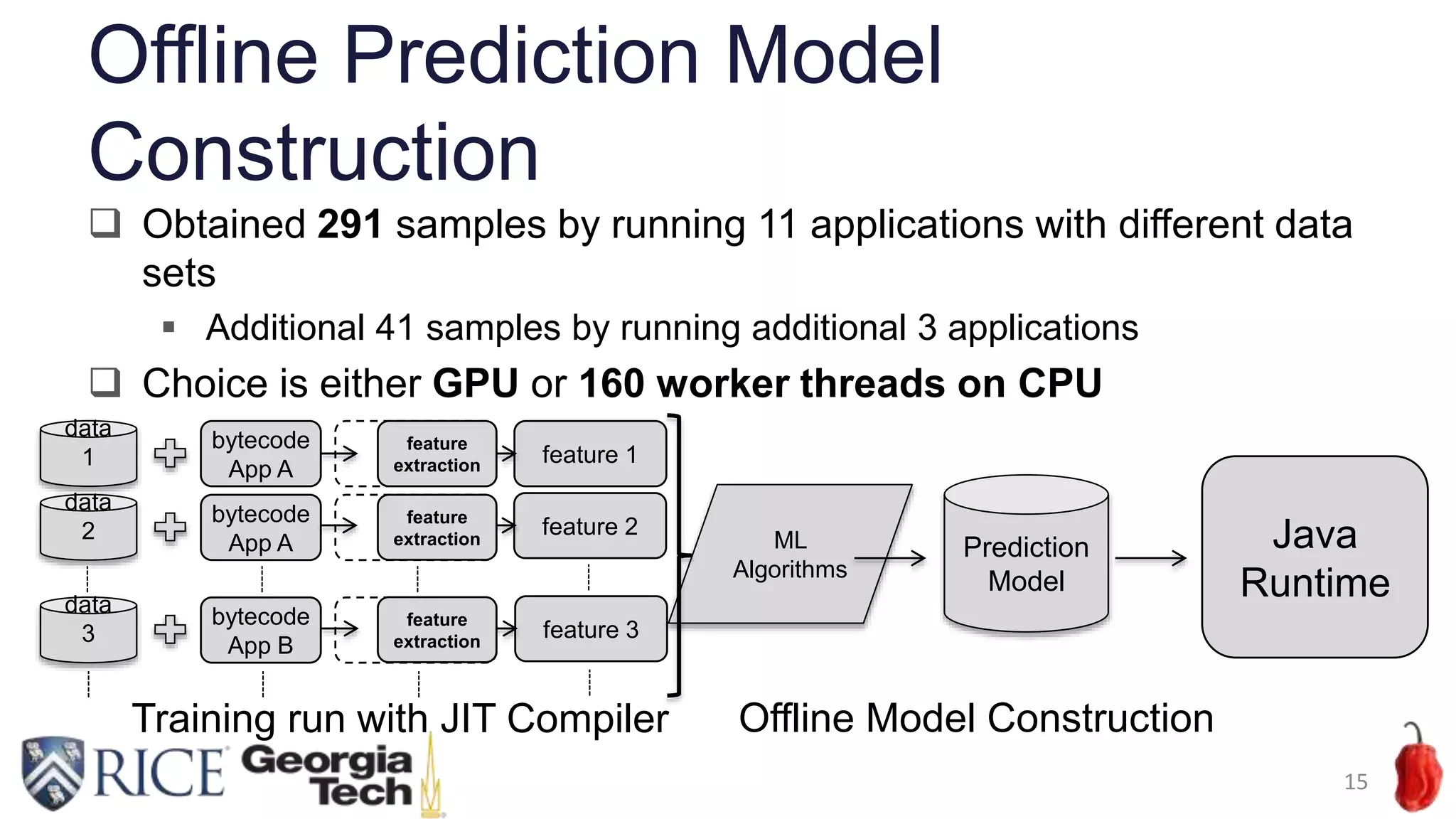
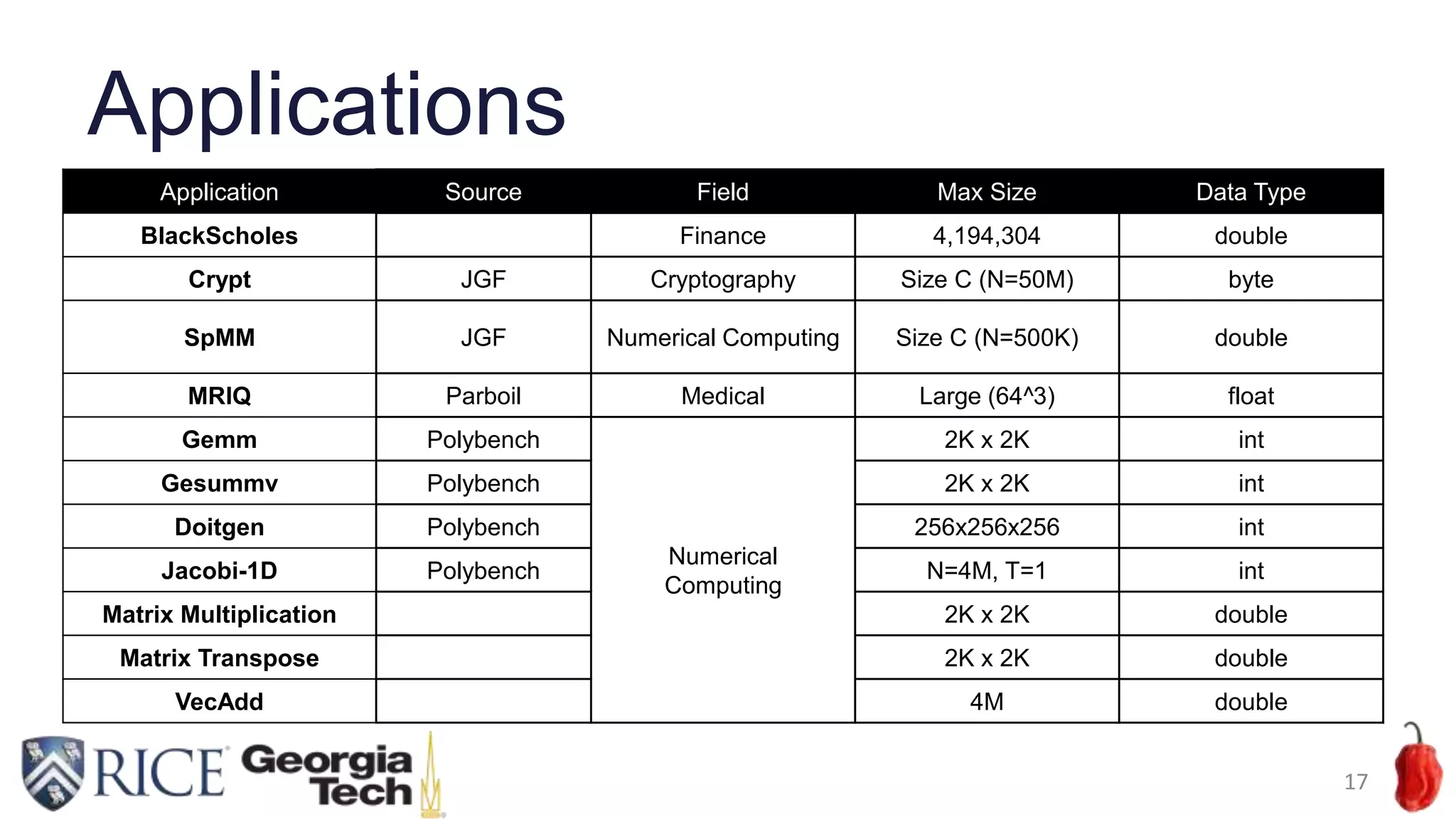
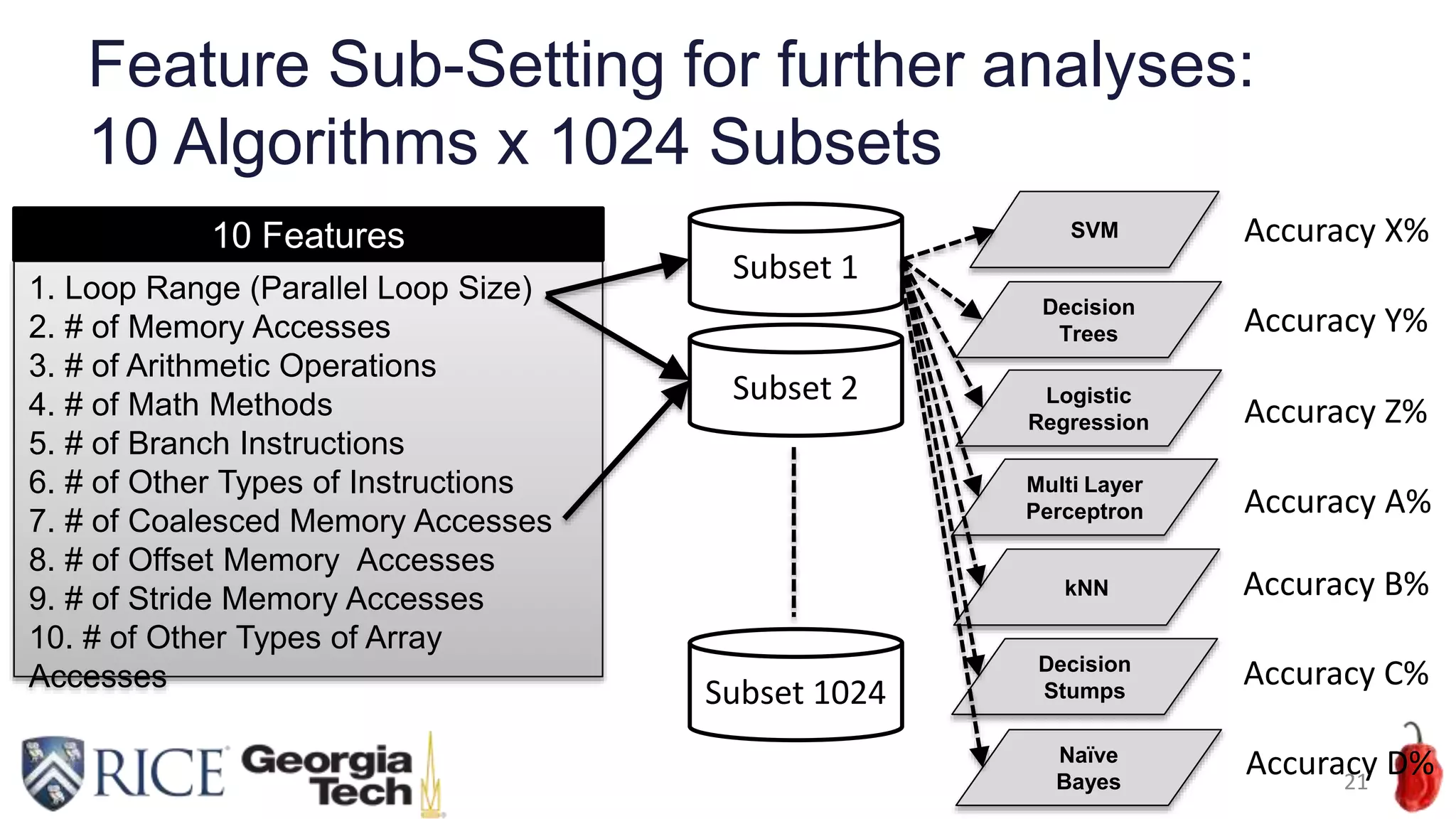
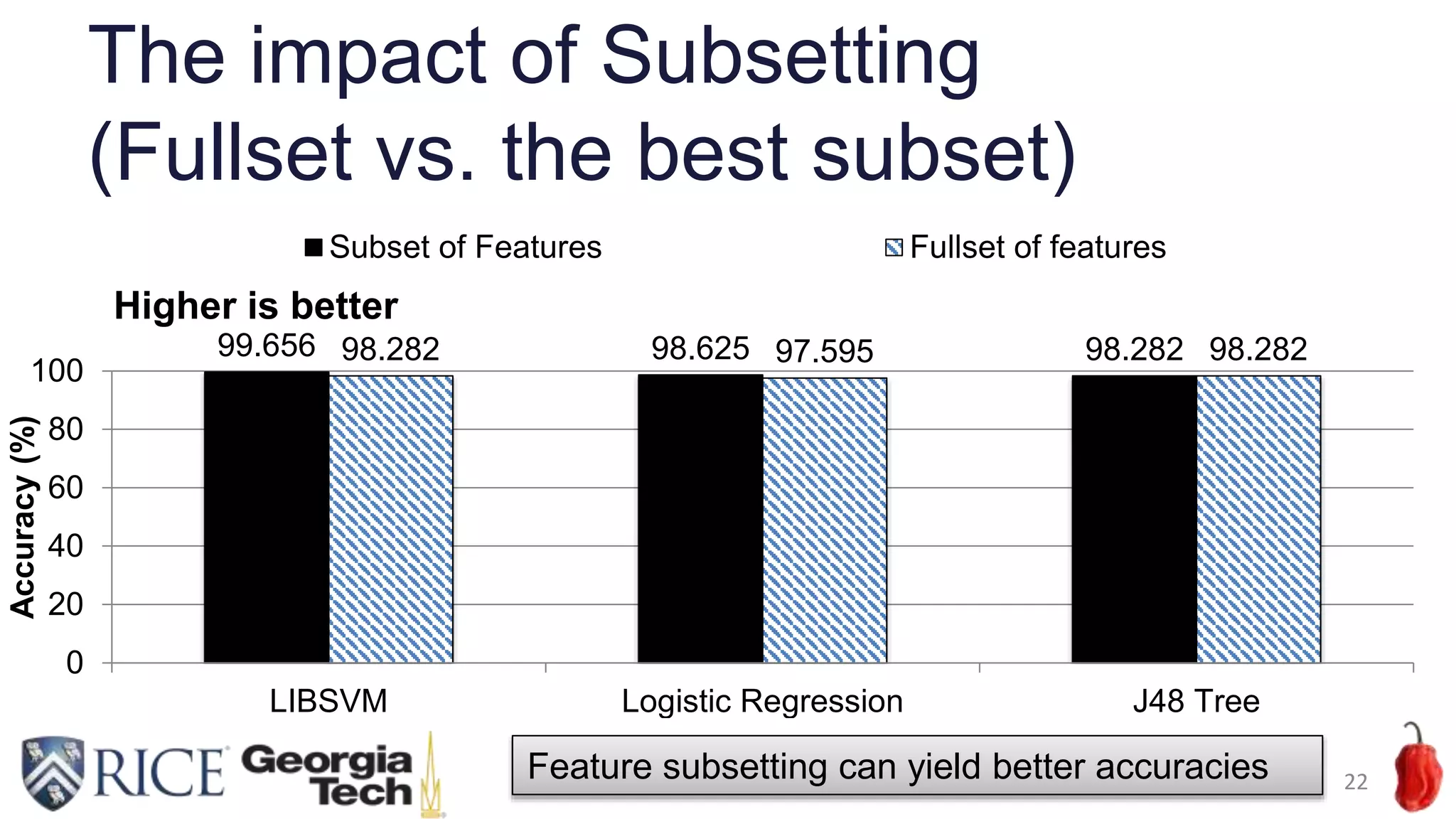
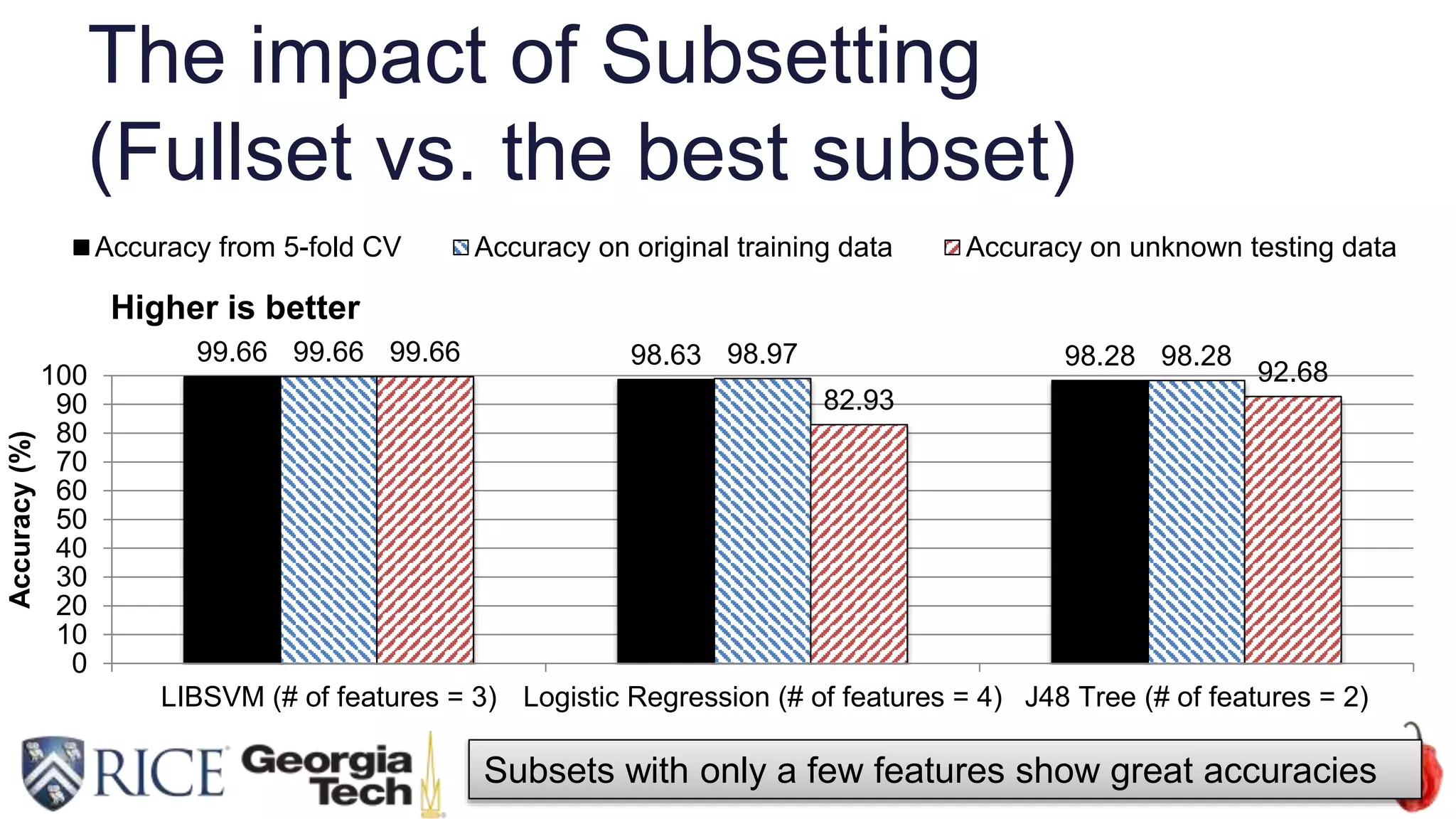
Download to read offline





![Features of program (Cont’d)
The dynamic number of Array Accesses
Coalesced Access (a[i])
Offset Access (a[i+c])
Stride Access (a[c*i])
Other Access (a[b[i]])
13
0 5 10 15 20 25 30
050100150200
c : offset or stride size
Bandwidth(GB/s)
●
● ● ●
● ● ● ● ● ● ● ● ● ● ● ●
●
● ● ●
●
● ● ● ● ● ● ● ● ● ● ●
●
●
Offset : array[i+c]
Stride : array[c*i]](https://image.slidesharecdn.com/ahayashi20171113-180226235309/75/Exploration-of-Supervised-Machine-Learning-Techniques-for-Runtime-Selection-of-CPU-vs-GPU-Execution-in-Java-Programs-13-2048.jpg)
![An example of feature vector
14
"features" : {
"range": 256,
"ILs" : {
"Memory": 9, "Arithmetic": 7, "Math": 0,
"Branch": 1, "Other": 1 },
"Array Accesses" : {
"Coalesced": 3, "Offset": 0, "Stride": 0, "Random": 0},
}
IntStream.range(0, N)
.parallel()
.forEach(i -> { a[i] = b[i] + c[i];});](https://image.slidesharecdn.com/ahayashi20171113-180226235309/75/Exploration-of-Supervised-Machine-Learning-Techniques-for-Runtime-Selection-of-CPU-vs-GPU-Execution-in-Java-Programs-14-2048.jpg)




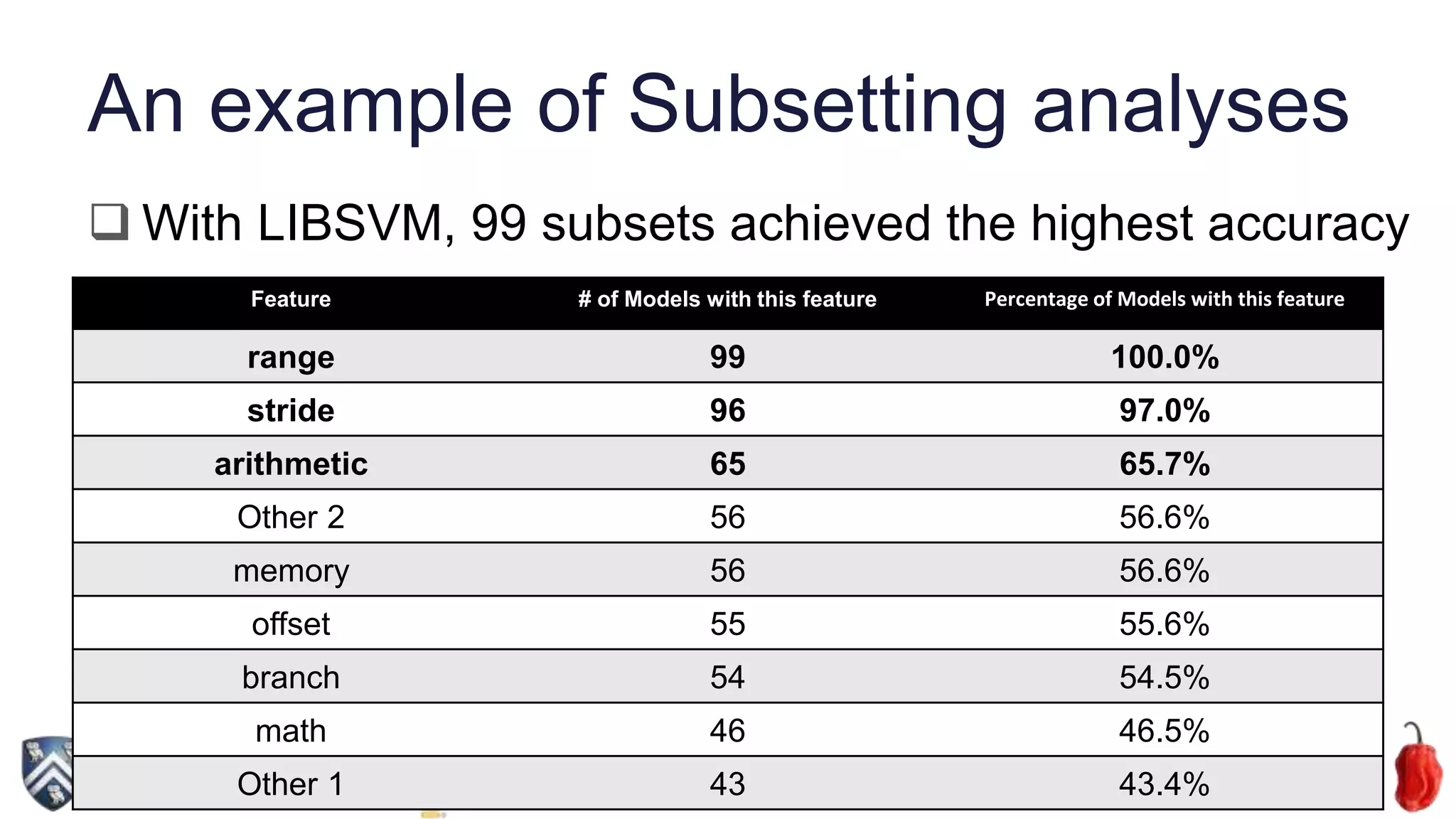






The document discusses the application of supervised machine learning techniques for selecting between CPU and GPU execution in Java programs, particularly focusing on enhancing performance through Java 8's parallel streams API. It highlights the challenges associated with GPU code generation and outlines a method using machine learning-based heuristics to optimize device selection, achieving high prediction accuracy with minimal overhead. Future work includes exploring performance improvements and applying the technique to other parallel programming frameworks.












































































