Downloaded 10 times


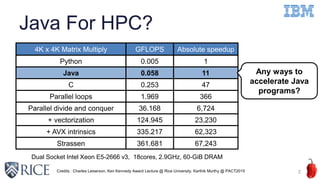



![Java Features on GPUs
Exceptions
Explicit exception checking on GPUs
ArrayIndexOutOfBoundsException
NullPointerException
ArithmeticException (Division by zero only)
Further Optimizations
Loop Versioning for redundant exception checking elimination
on GPUs based on [Artigas+, ICS’00]
Virtual Method Calls
Direct De-virtualization or Guarded De-virtualization
[Ishizaki+, OOPSLA’00]
8
Challenge 1 : Supporting Java Features on GPUs](https://image.slidesharecdn.com/ahayashi20151103-151115205412-lva1-app6891/85/Machine-learning-based-performance-heuristics-for-Runtime-CPU-GPU-Selection-in-Java-8-320.jpg)
![Loop Versioning Example
9
IntStream.range(0, N)
.parallel()
.forEach(
i -> {
Array[i] = i / N;
}
);
// Speculative Checking on CPU
if (Array != null
&& 0 <= Array.length
&& N <= Array.length
&& N != 0) {
// Safe GPU Execution
} else {
May cause
OutOfBoundsException
May cause
ArithmeticException
May cause
NullPointerException
Challenge 1 : Supporting Java Features on GPUs](https://image.slidesharecdn.com/ahayashi20151103-151115205412-lva1-app6891/85/Machine-learning-based-performance-heuristics-for-Runtime-CPU-GPU-Selection-in-Java-9-320.jpg)

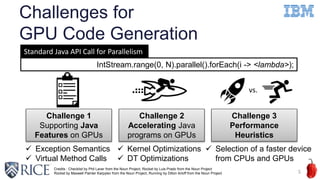
![The Alignment Optimization Example
11
0 128
a[0]-a[31]
Object header
Memory address
a[32]-a[63]
Naive
alignment
strategy
a[0]-a[31] a[32]-a[63]
256 384
Our
alignment
strategy
One memory transaction for a[0:31]
Two memory transactions for
a[0:31]
a[64]-a[95]
a[64]-a[95]
Challenge 2 : Accelerating Java programs on
GPUs](https://image.slidesharecdn.com/ahayashi20151103-151115205412-lva1-app6891/85/Machine-learning-based-performance-heuristics-for-Runtime-CPU-GPU-Selection-in-Java-11-320.jpg)
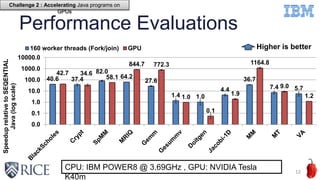
![Related Work : Linear Regression
Regression based cost estimation is specific to an application
14
0e+00 4e+07 8e+07
0.00.20.40.60.81.0
The dynamic number of IR instructions
KernelExecutionTime(msec) NVIDIA Tesla K40 GPU
IBM POWER8 CPU
App 1) BlackScholes
ExecutionTime(msec)
0e+00 4e+07 8e+07
01234
The dynamic number of IR instructions
KernelExecutionTime(msec)
NVIDIA Tesla K40 GPU
IBM POWER8 CPU
ExecutionTime
(msec)
App 2) Vector Addition
CPU
GPU
CPU
GPU
[1] Leung et al. Automatic Parallelization for Graphics Processing Units (PPPJ’09)
[2] Kerr et al. Modeling GPU-CPU Workloads and Systems (GPGPU-3)
Challenge 3 : Performance Heuristics](https://image.slidesharecdn.com/ahayashi20151103-151115205412-lva1-app6891/85/Machine-learning-based-performance-heuristics-for-Runtime-CPU-GPU-Selection-in-Java-14-320.jpg)


![Features of program (Cont’d)
The dynamic number of Array Accesses
Coalesced Access (a[i])
Offset Access (a[i+c])
Stride Access (a[c*i])
Other Access (a[b[i]])
Data Transfer Size
H2D Transfer Size
D2H Transfer Size
18
0 5 10 15 20 25 30
050100150200
c : offset or stride size
Bandwidth(GB/s)
●
● ● ●
● ● ● ● ● ● ● ● ● ● ● ●
●
● ● ●
●
● ● ● ● ● ● ● ● ● ● ●
●
●
Offset : array[i+c]
Stride : array[c*i]
Challenge 3 : Performance Heuristics](https://image.slidesharecdn.com/ahayashi20151103-151115205412-lva1-app6891/85/Machine-learning-based-performance-heuristics-for-Runtime-CPU-GPU-Selection-in-Java-18-320.jpg)
![An example of feature vector
19
Challenge 3 : Performance Heuristics
"features" : {
"range": 256,
"ILs" : {
"Memory": 9, "Arithmetic": 7, "Math": 0,
"Branch": 1, "Other": 1 },
"Array Accesses" : {
"Coalesced": 3, "Offset": 0, "Stride": 0, "Random": 0},
"H2D Transfer" : [2064, 2064, 2064, …, 0],
"D2H Transfer" : [2048, 2048, 2048, …, 0]}
IntStream.range(0, N)
.parallel()
.forEach(i -> { a[i] = b[i] + c[i];});](https://image.slidesharecdn.com/ahayashi20151103-151115205412-lva1-app6891/85/Machine-learning-based-performance-heuristics-for-Runtime-CPU-GPU-Selection-in-Java-19-320.jpg)
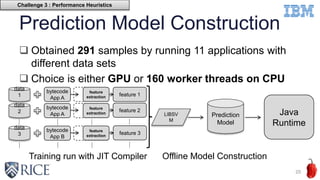
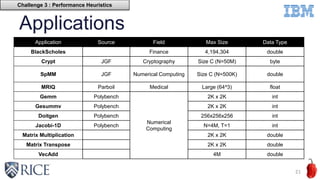

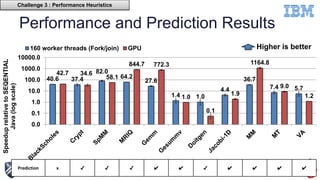

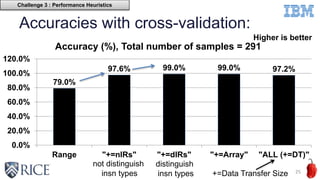

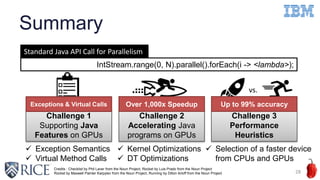



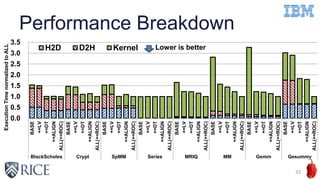

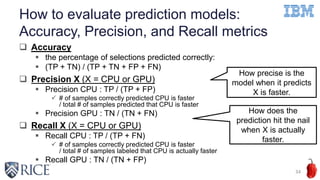
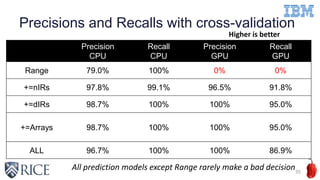

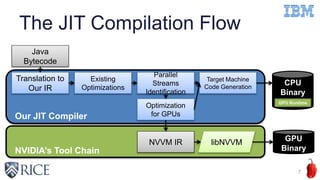
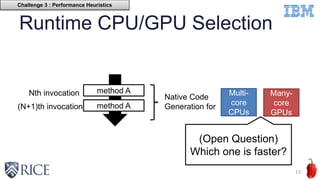
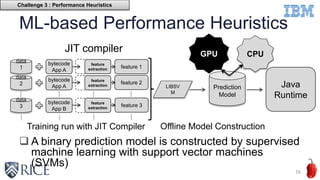
This document discusses using machine learning techniques to perform runtime selection of CPUs or GPUs for executing Java programs. It describes challenges in supporting Java features like exceptions on GPUs and accelerating Java programs. Features like loop characteristics, instruction counts, memory accesses are extracted from programs to train an SVM model to predict faster device. Evaluating on 11 apps, the model achieves 97.6-99% accuracy using 5-fold cross validation to avoid overfitting. This runtime selection approach can adapt to new hardware without needing to rebuild performance models.













































![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





























