Downloaded 18 times




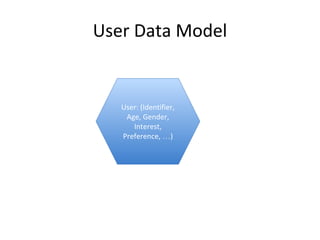
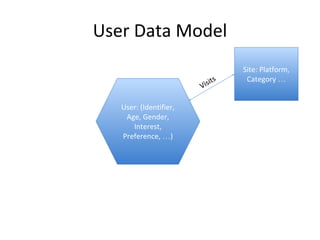
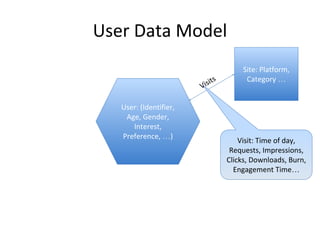
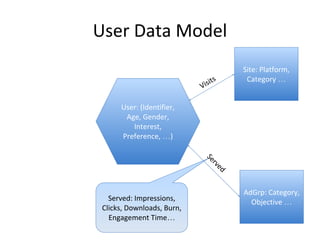
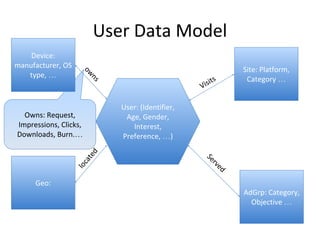
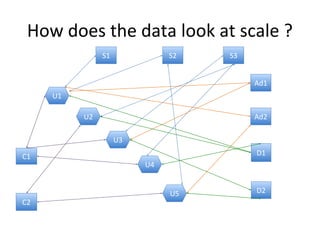





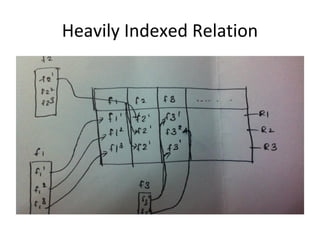
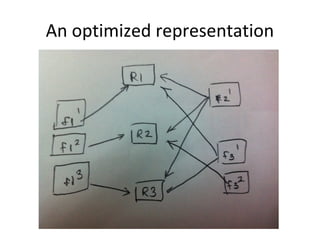



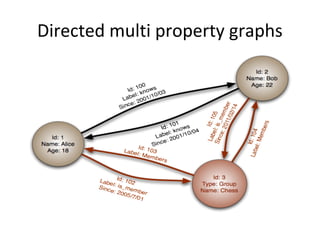








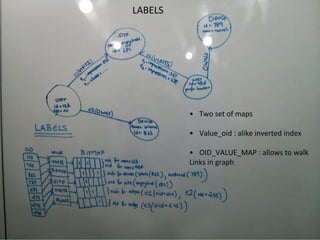
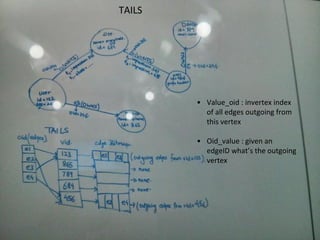
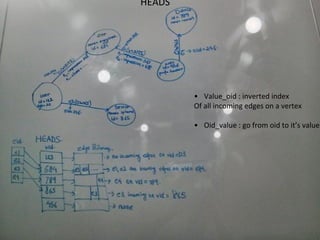
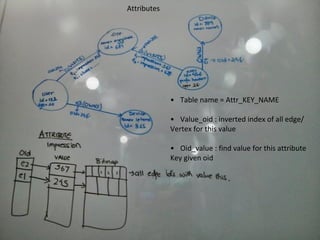

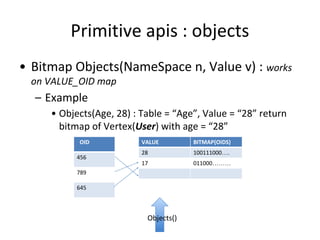
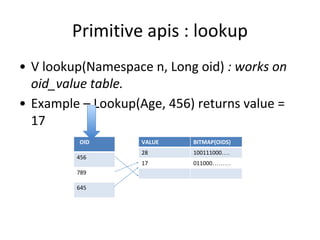
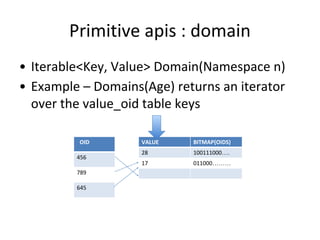







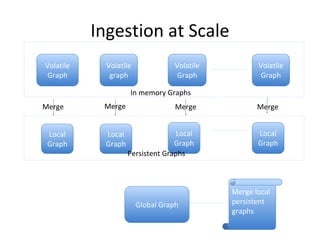
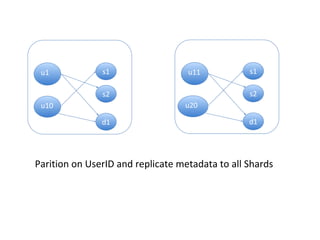




This document discusses building a user data store and analytics platform for an ad system. It outlines storing user profile data and activity data in a graph database to allow querying relationships between users, sites visited, ads served, devices used, and locations. The challenges of querying huge graphs with "super nodes" with millions of connections are discussed. The document proposes using a directed multi-property graph model with bitmap indexing to optimize expensive queries by avoiding costly graph traversals. It provides examples of how the bitmap indexes would allow set operations to efficiently retrieve user subsets and analyze user behavior patterns over time.




























![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)









![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)






![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

