



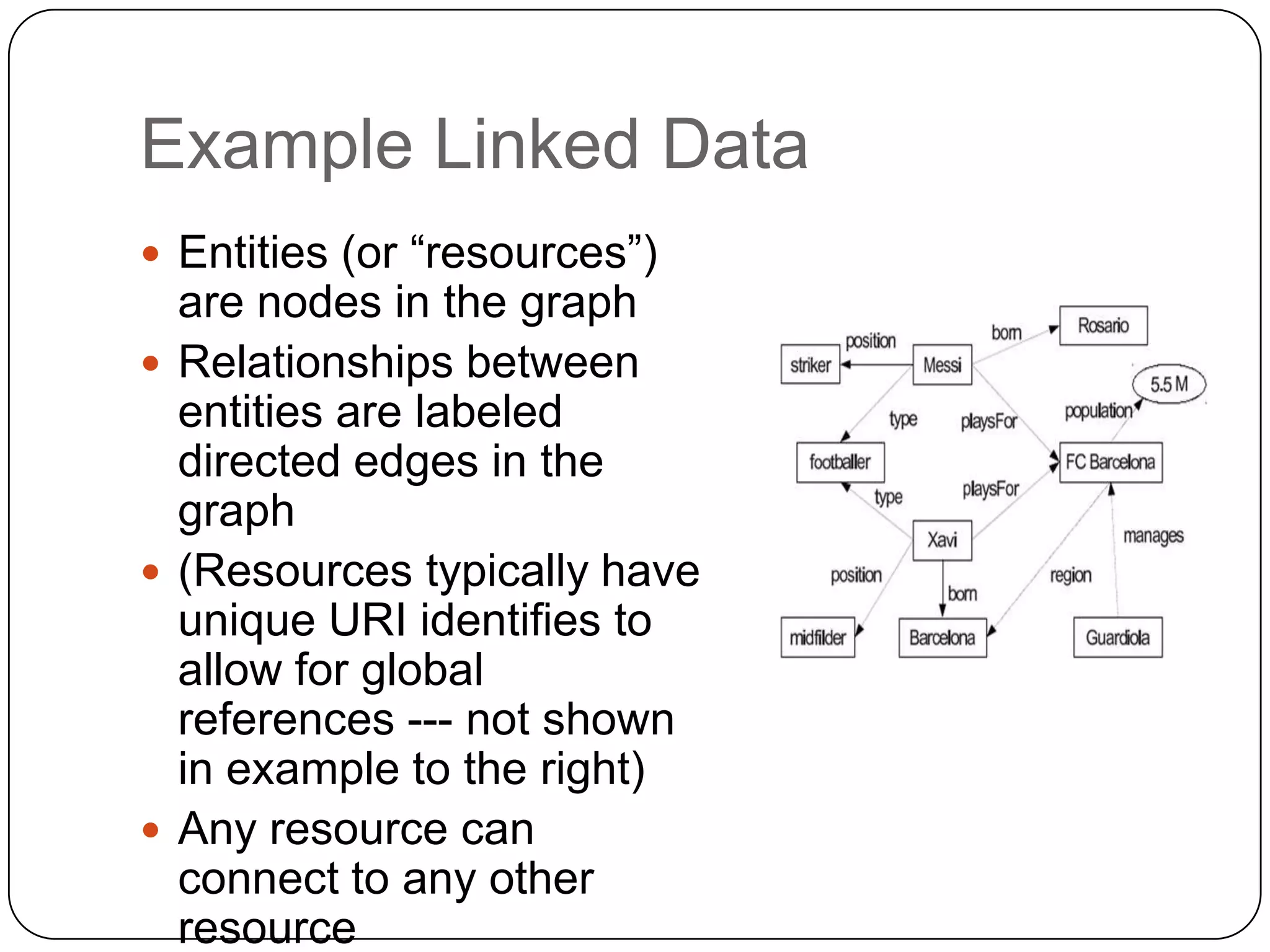

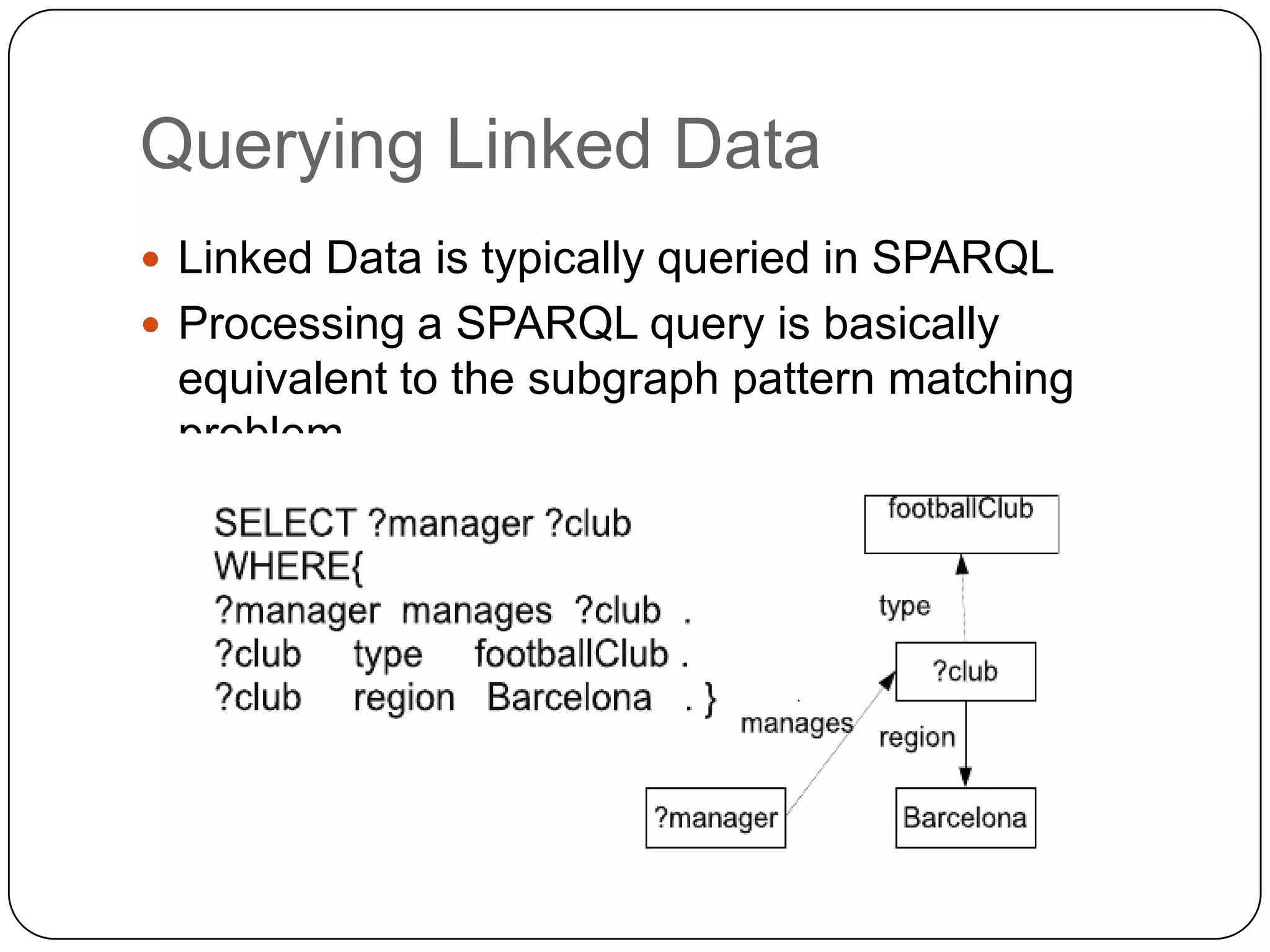

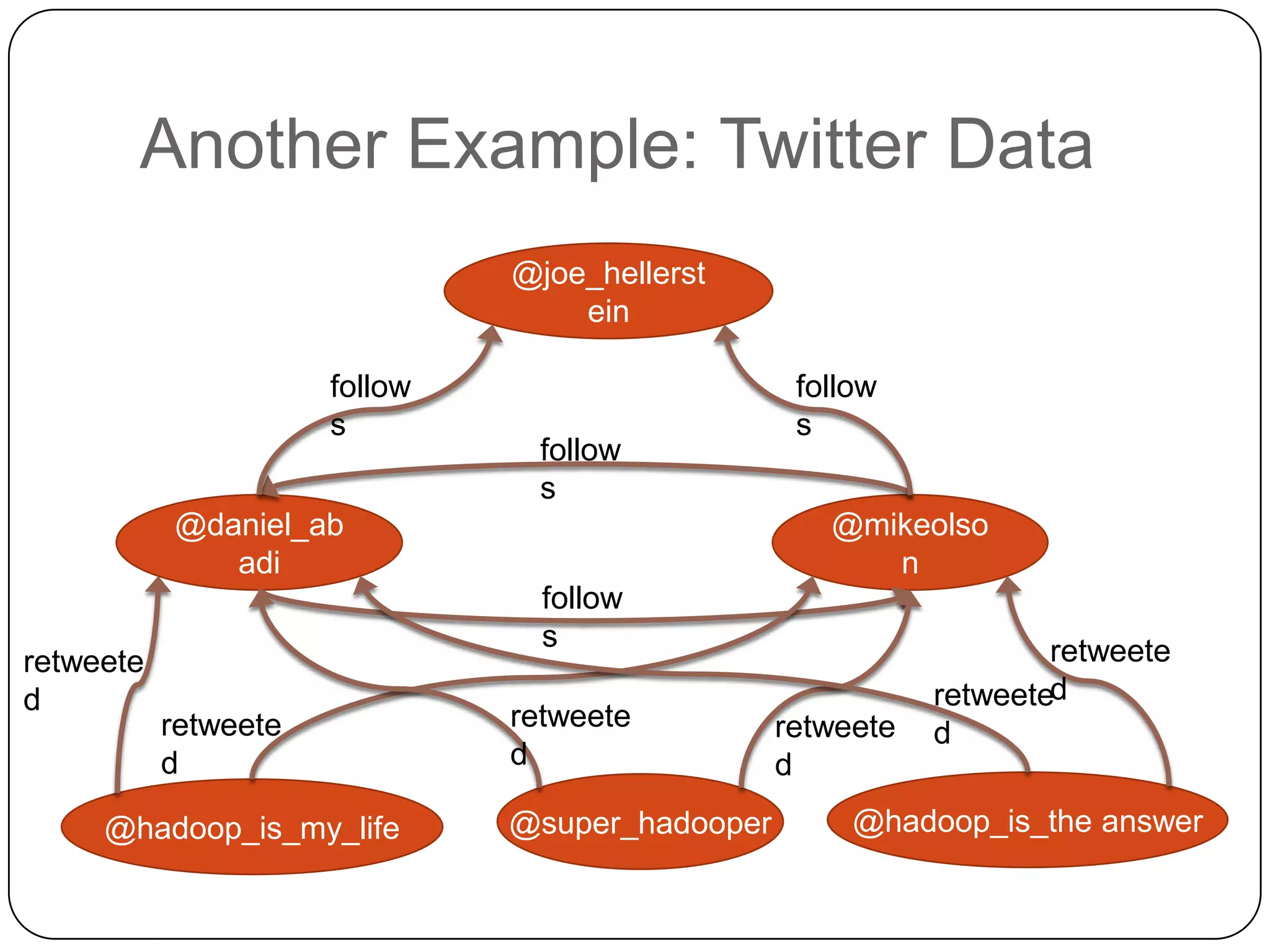
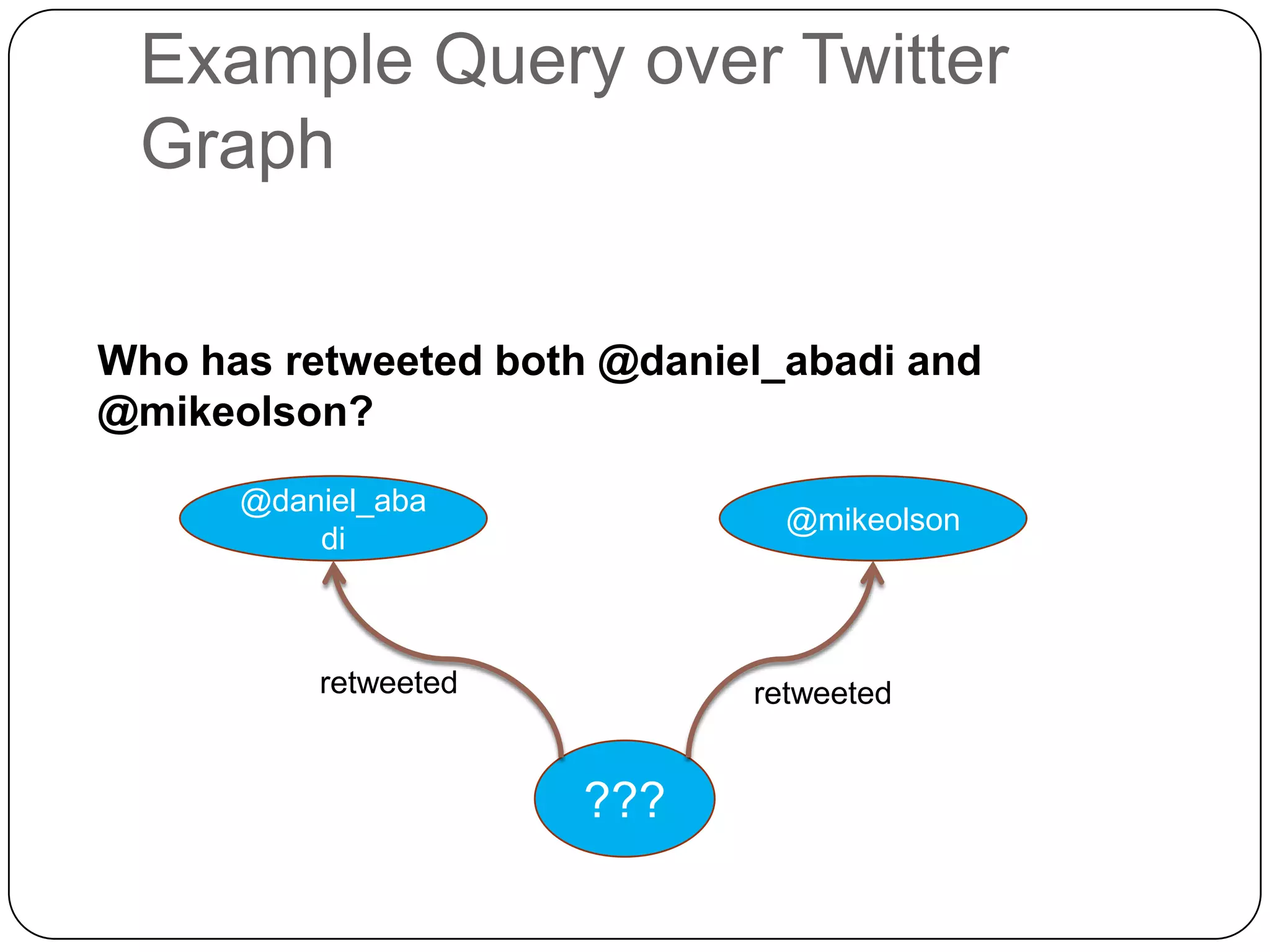



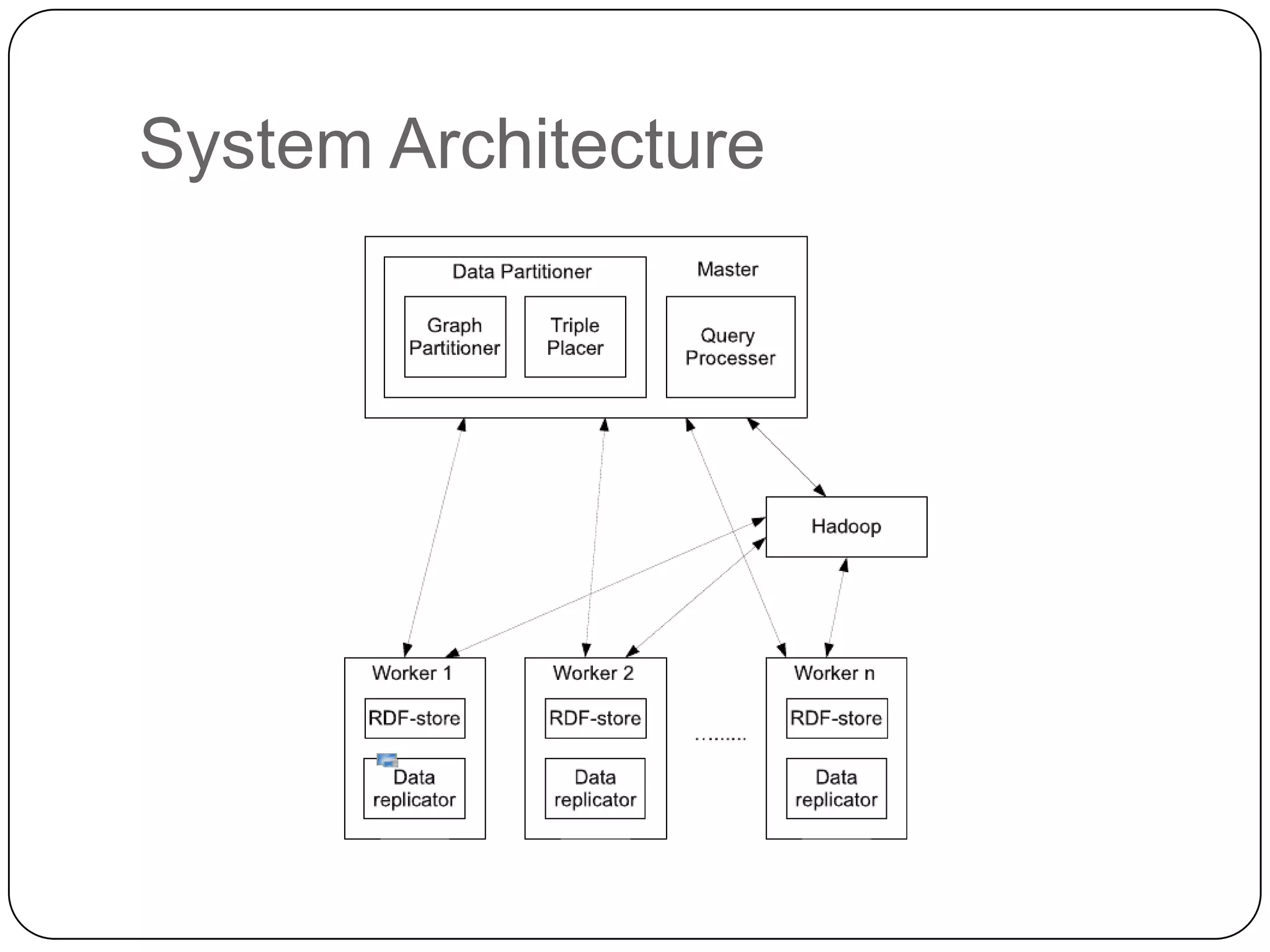

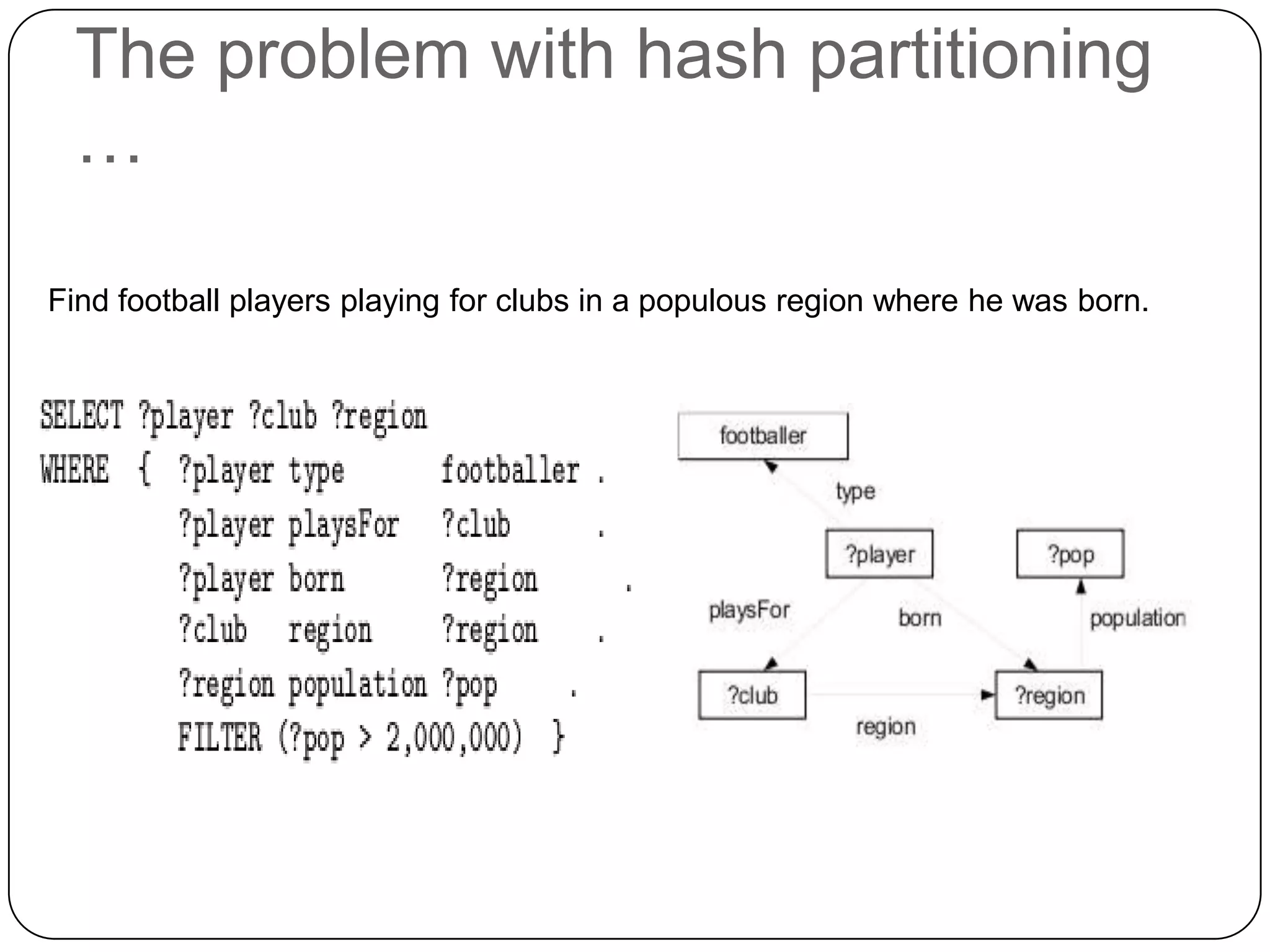

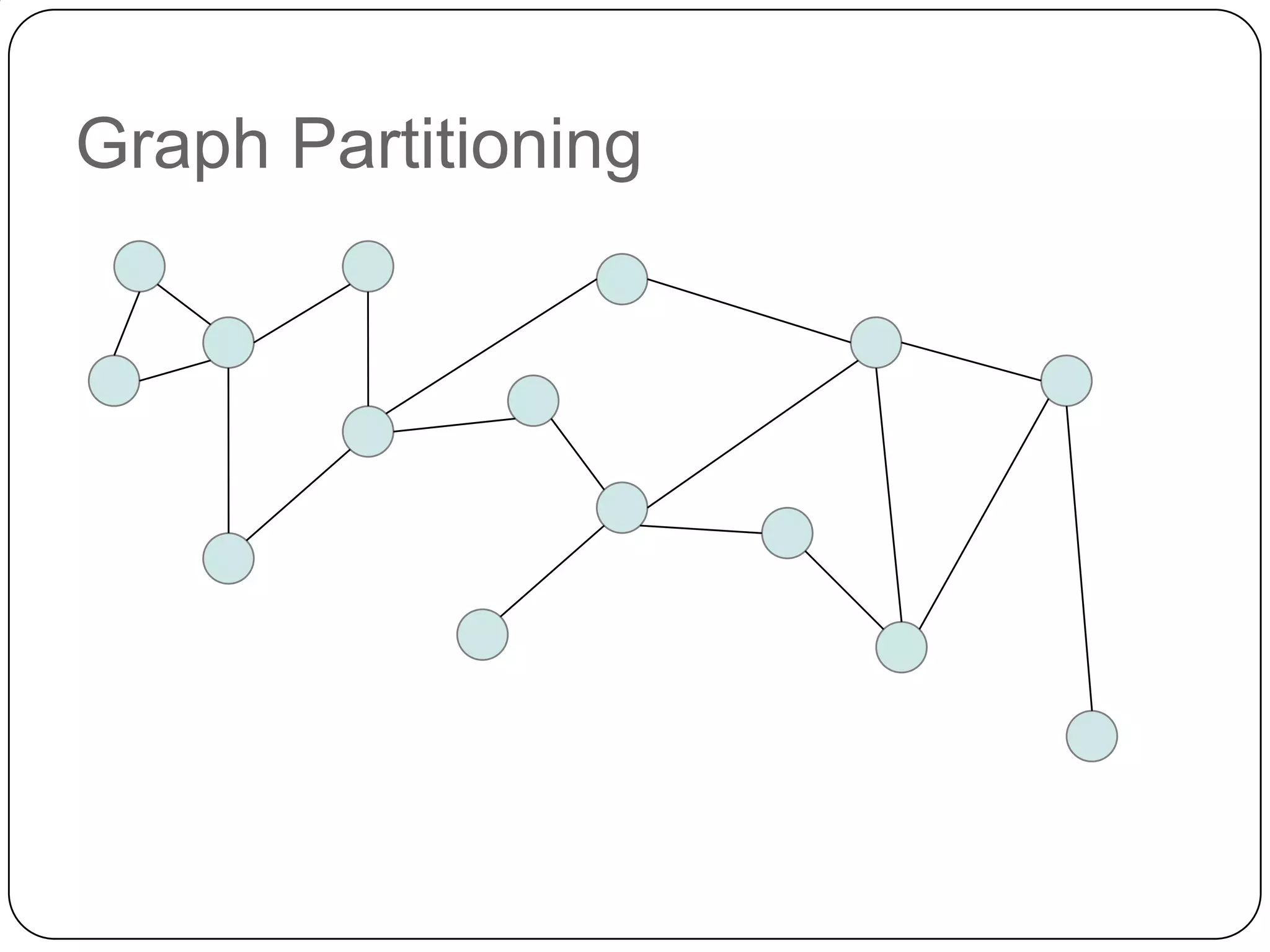
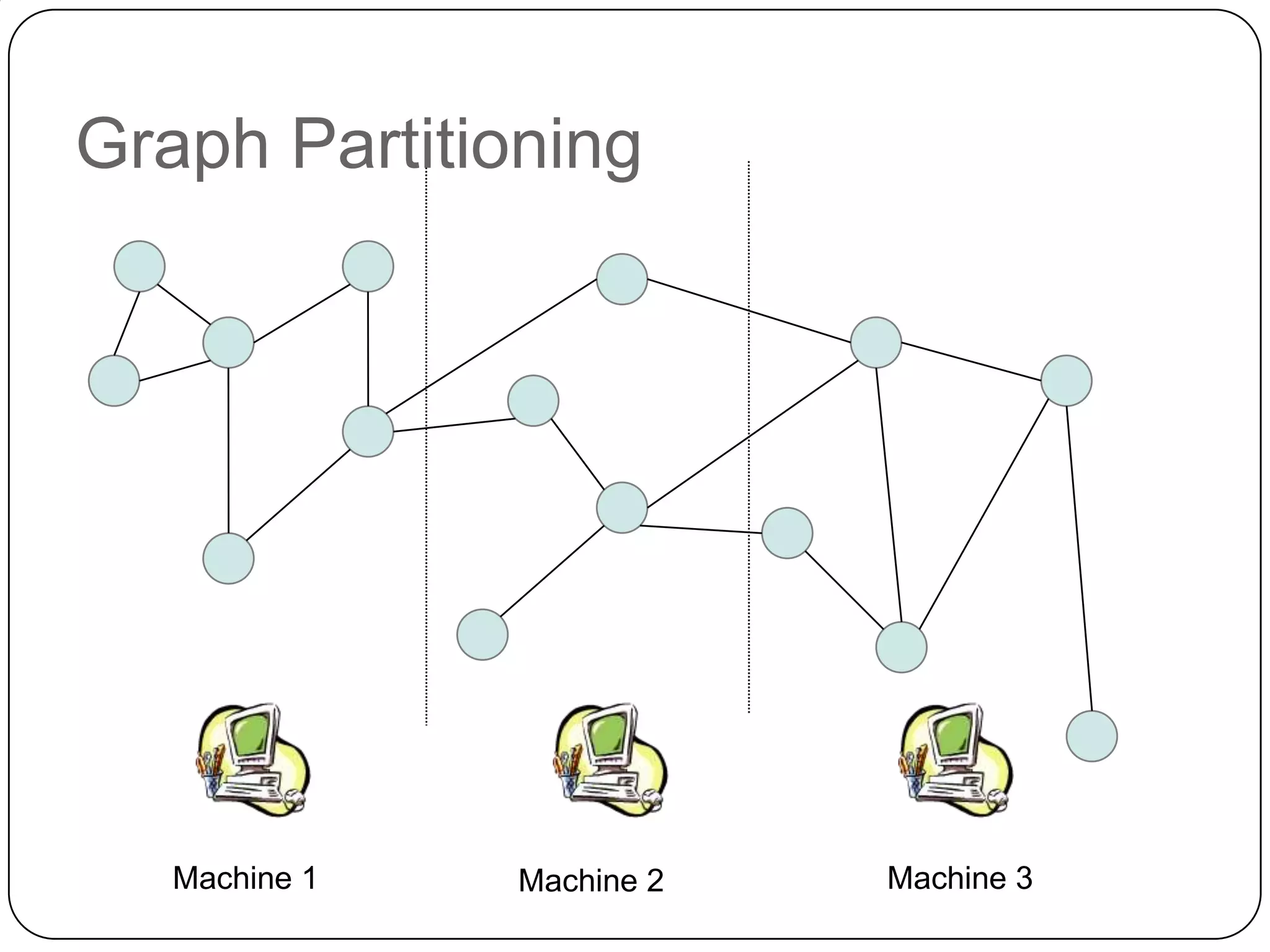

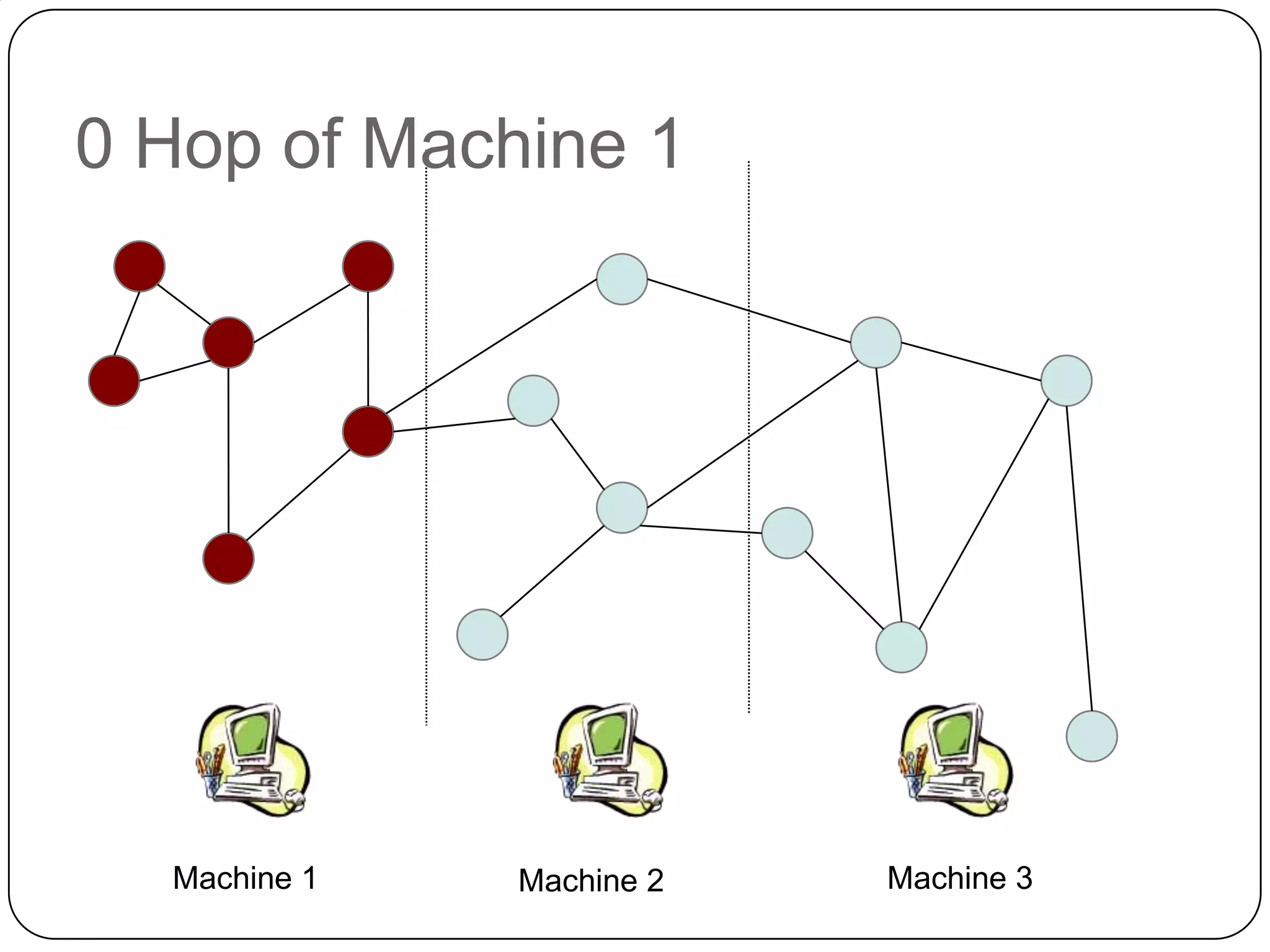
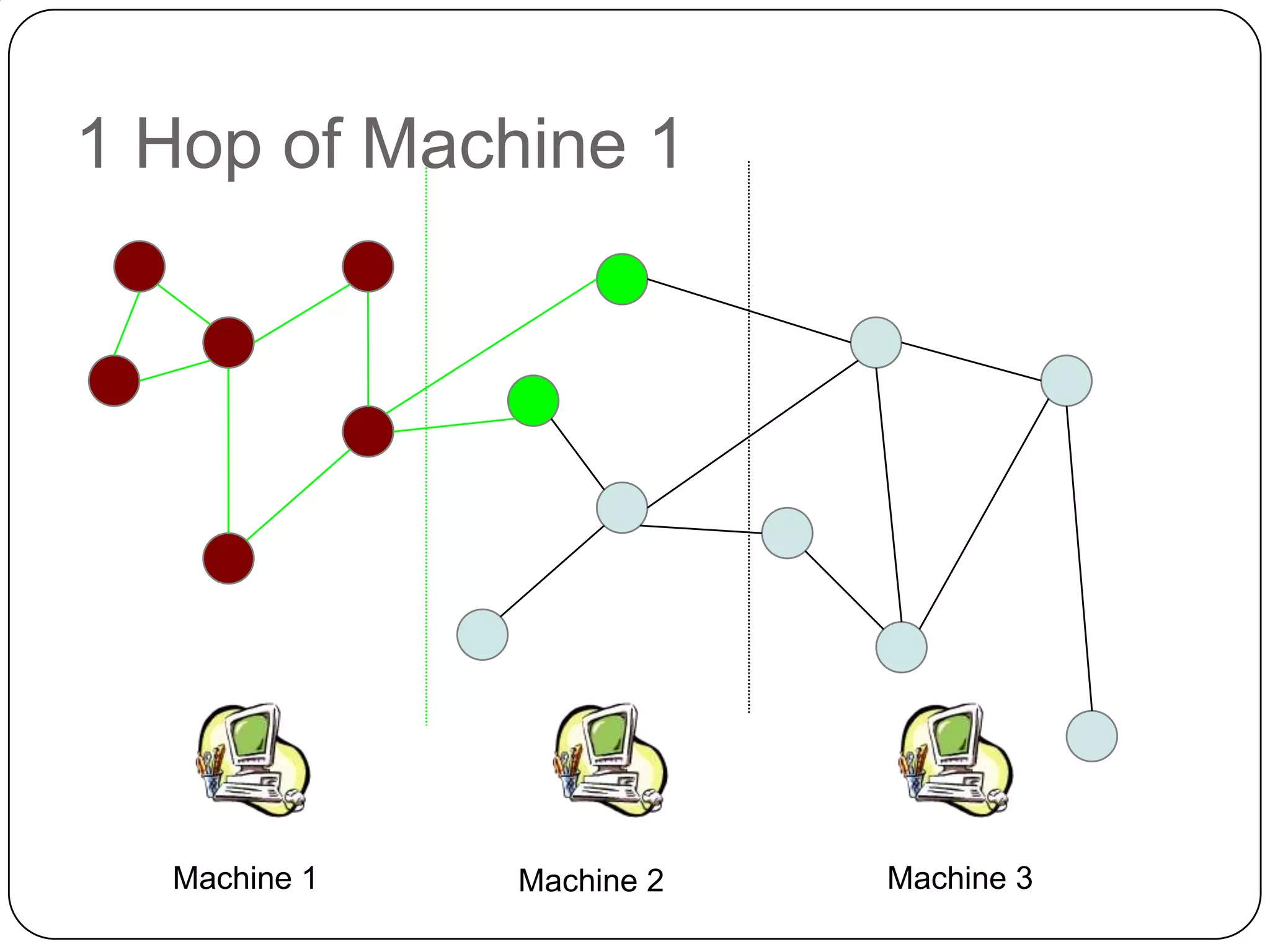
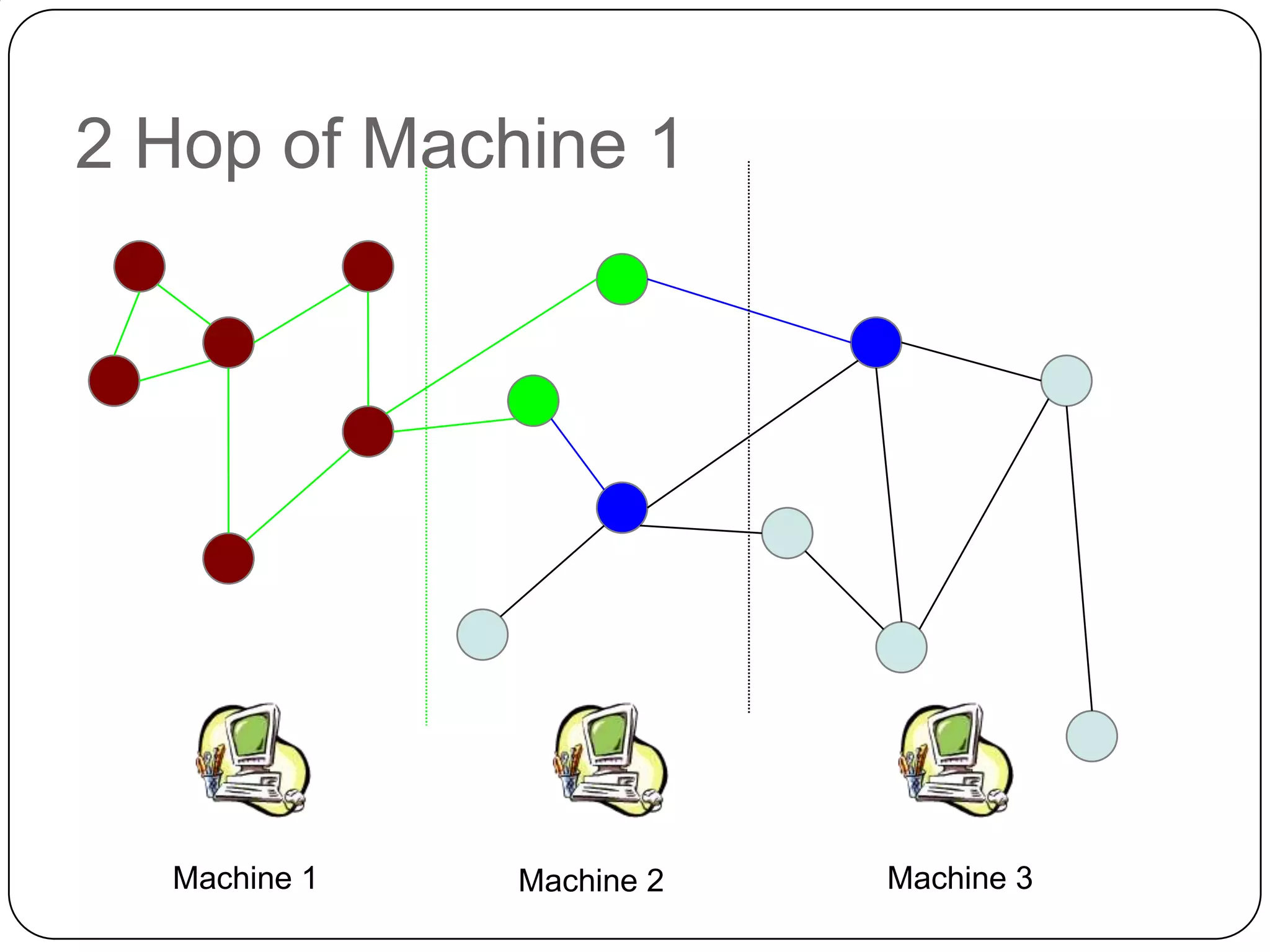
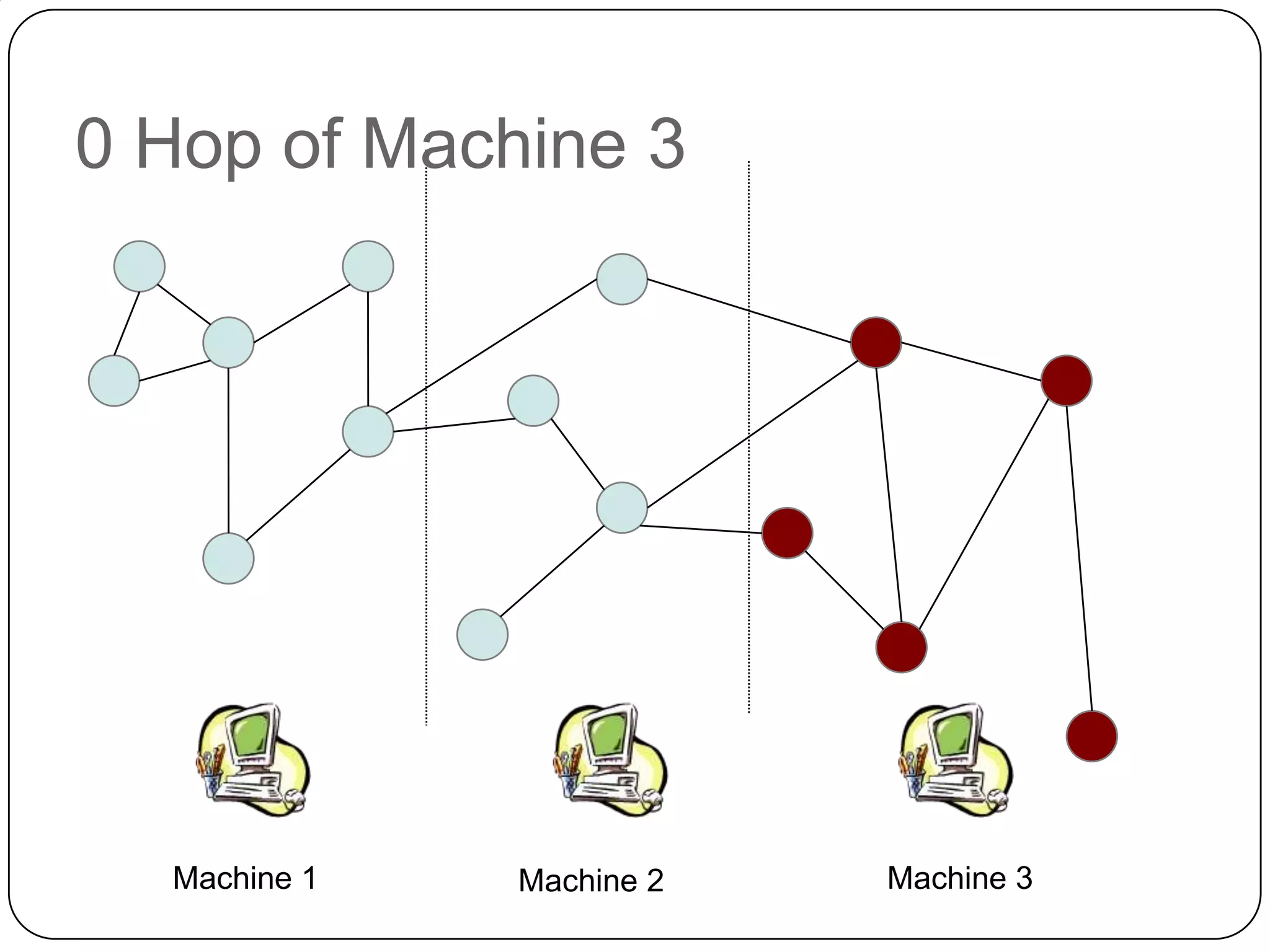
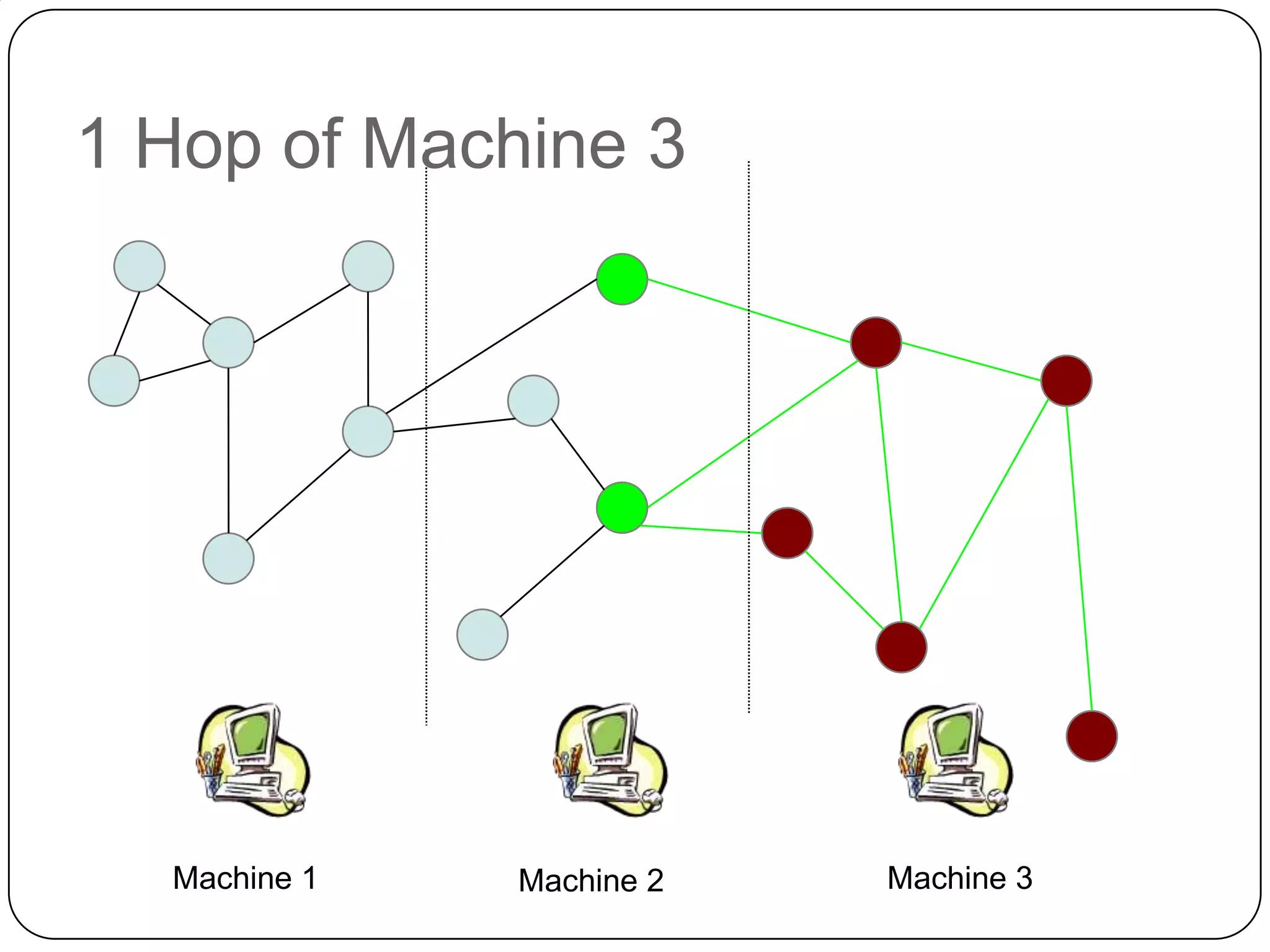
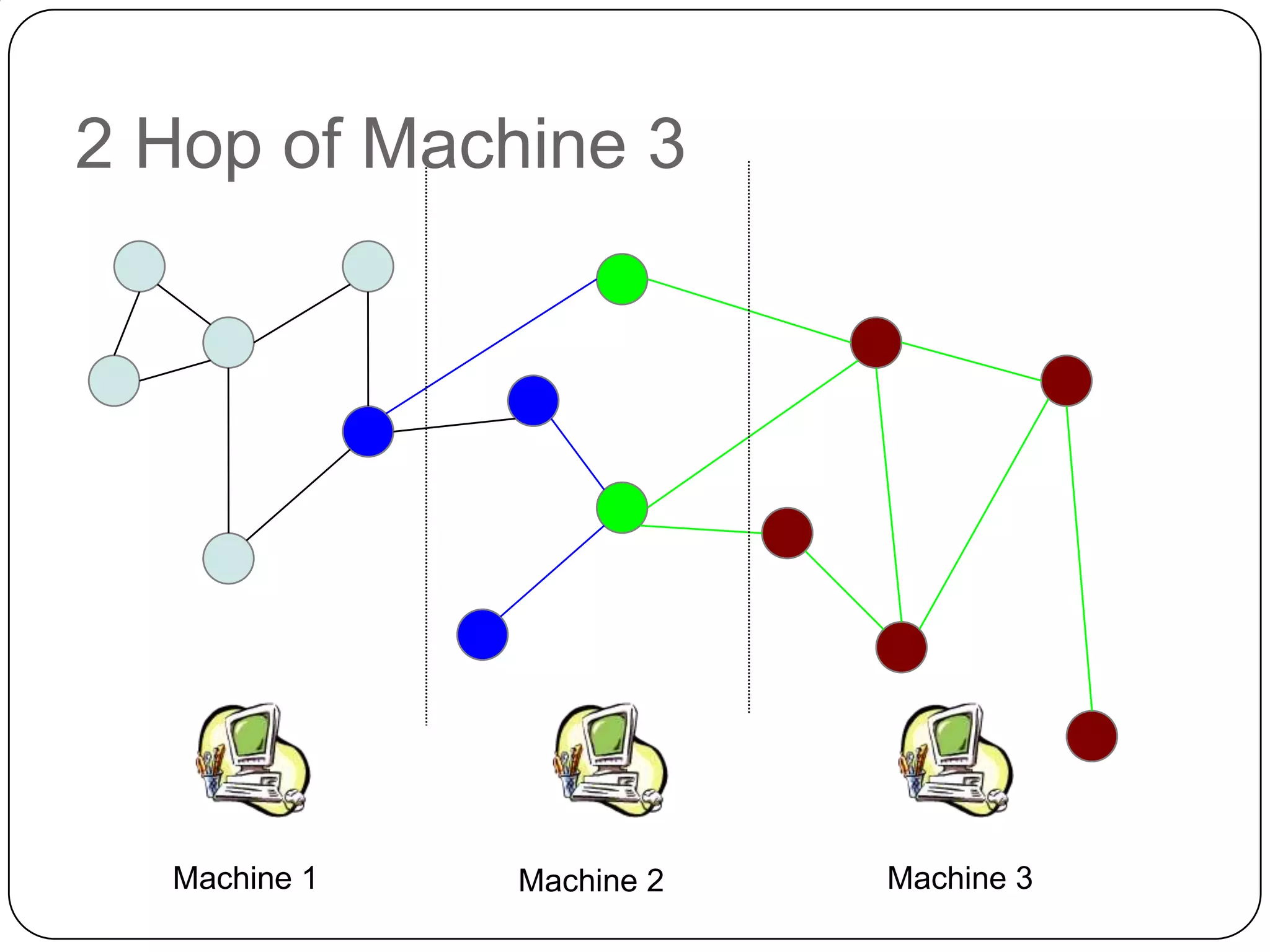



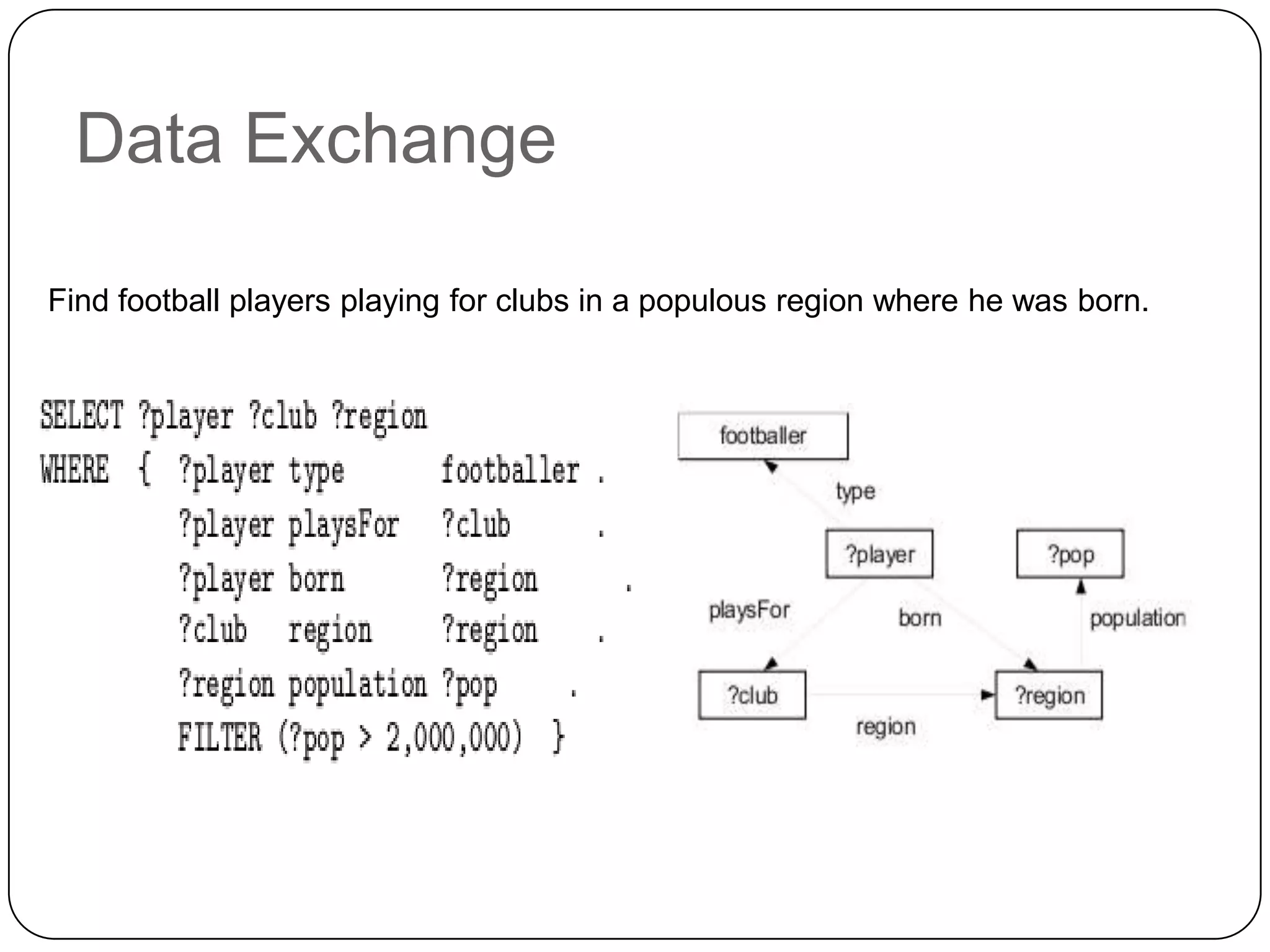

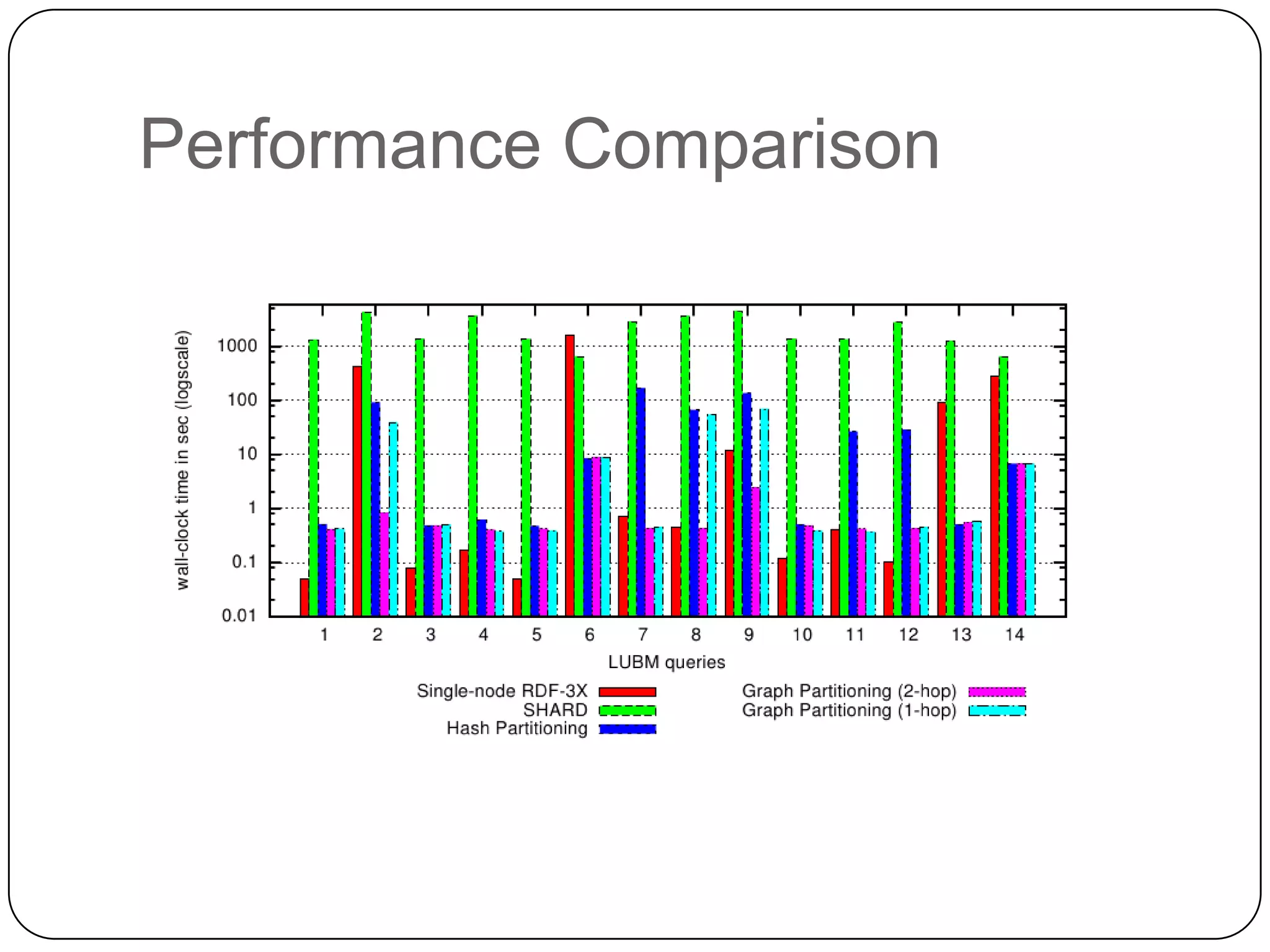
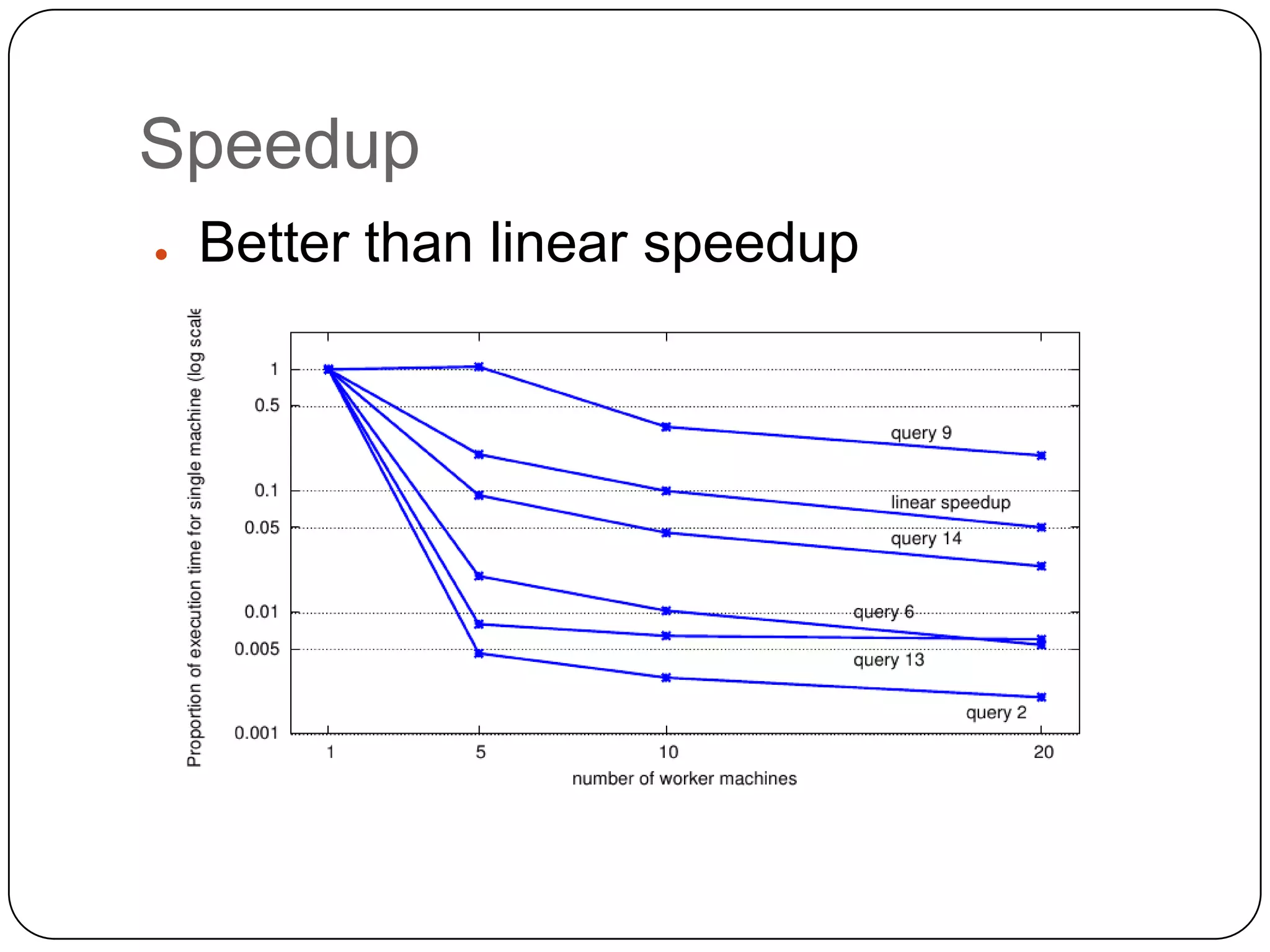

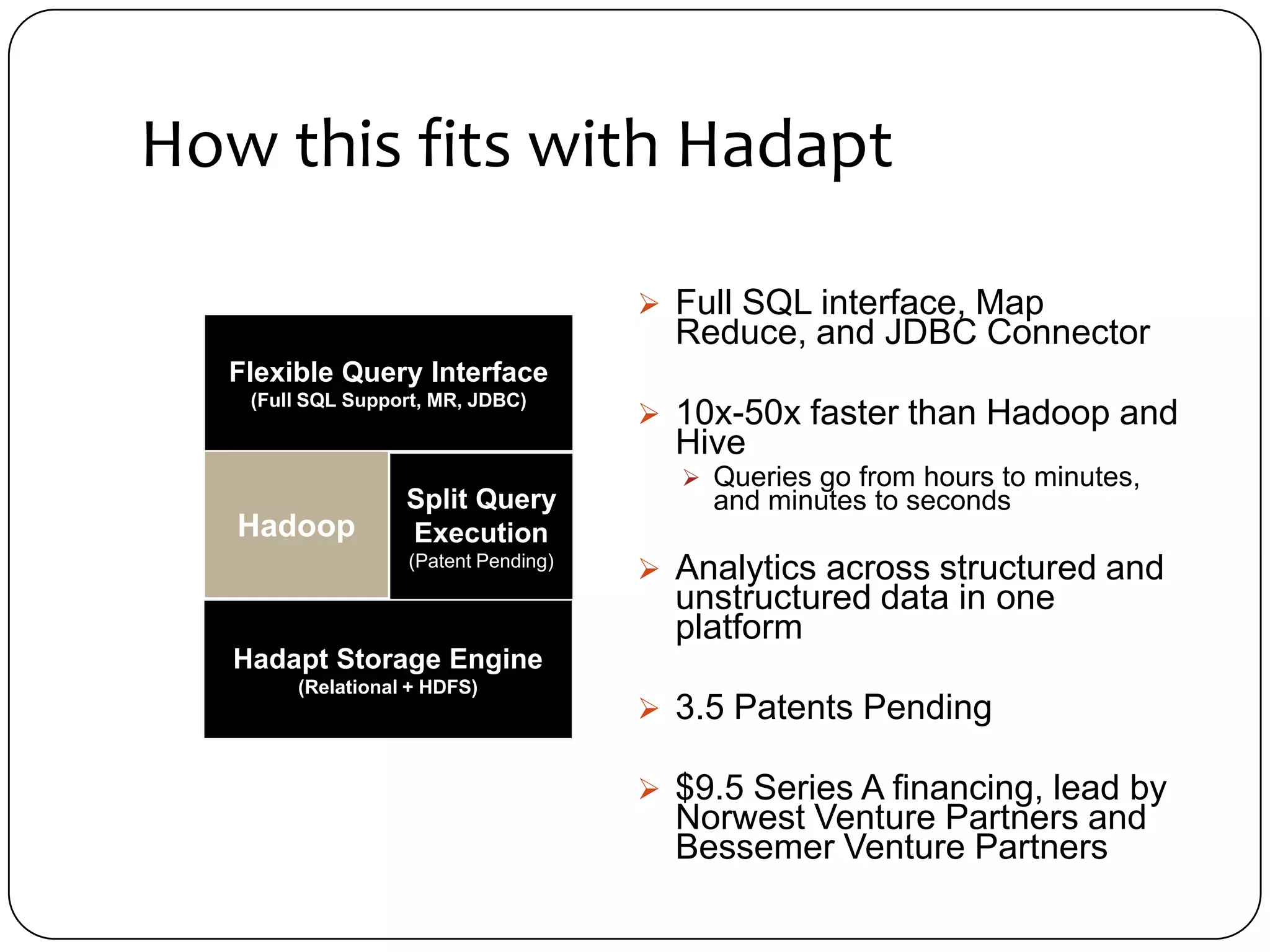


The document discusses the intersection of Hadoop and graph data management, highlighting both the challenges and opportunities presented by using Hadoop for processing graph data. It identifies Hadoop as a growing standard in large-scale data processing but points out its limitations, such as non-optimized algorithms and inefficient data partitioning. The document proposes solutions for improving graph data processing efficiency and emphasizes the importance of optimized storage systems.































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












