Downloaded 150 times




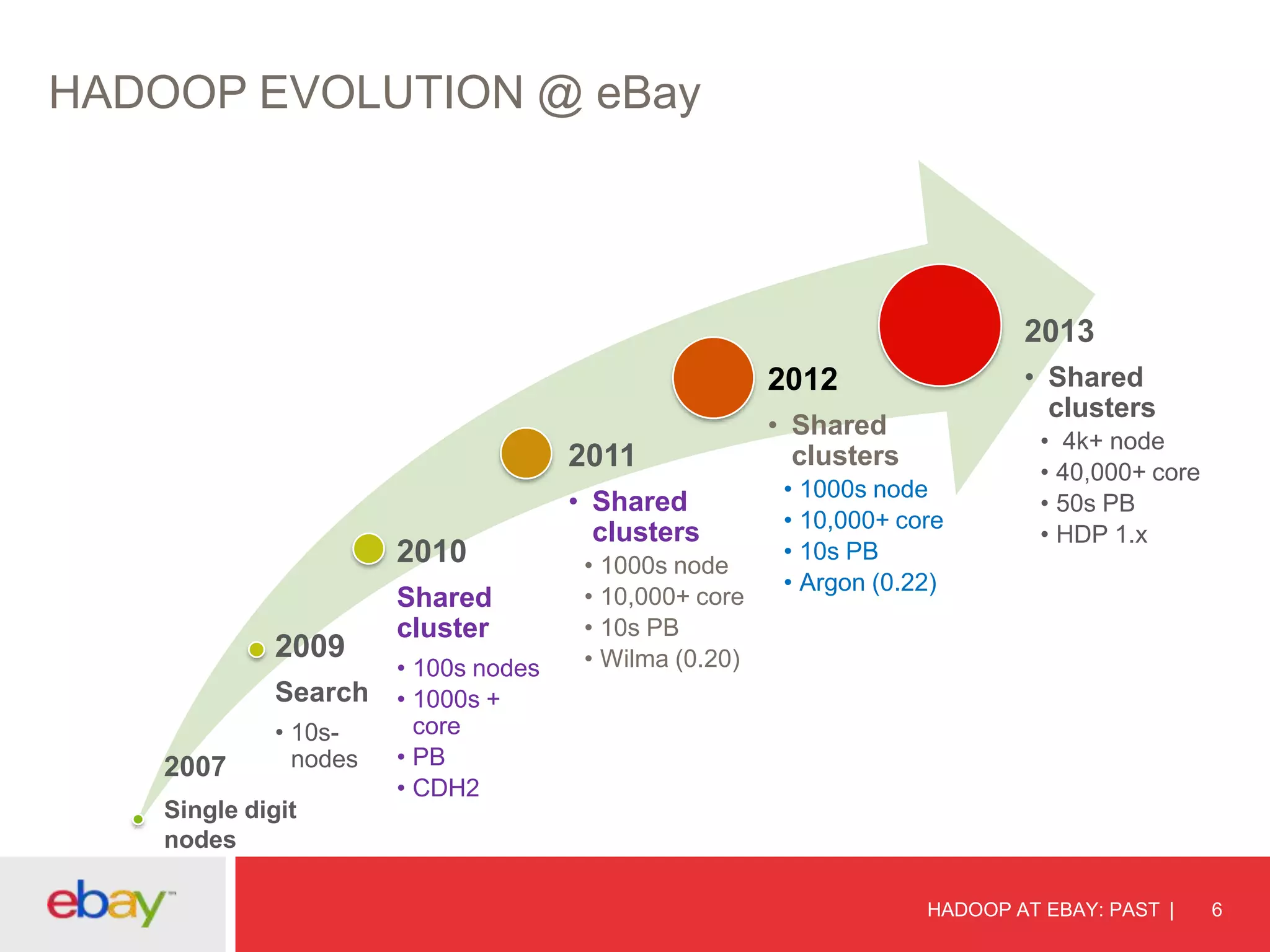

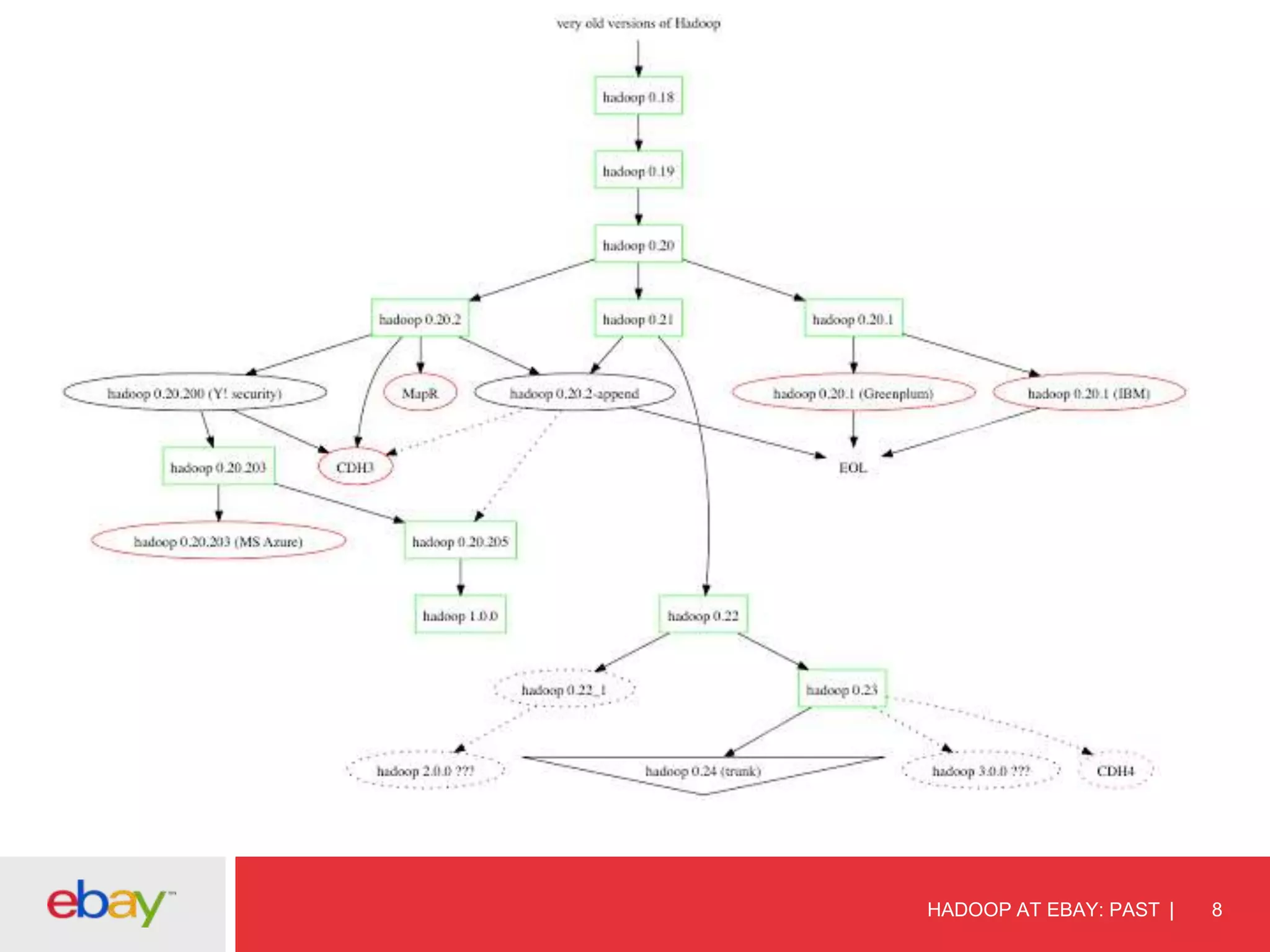



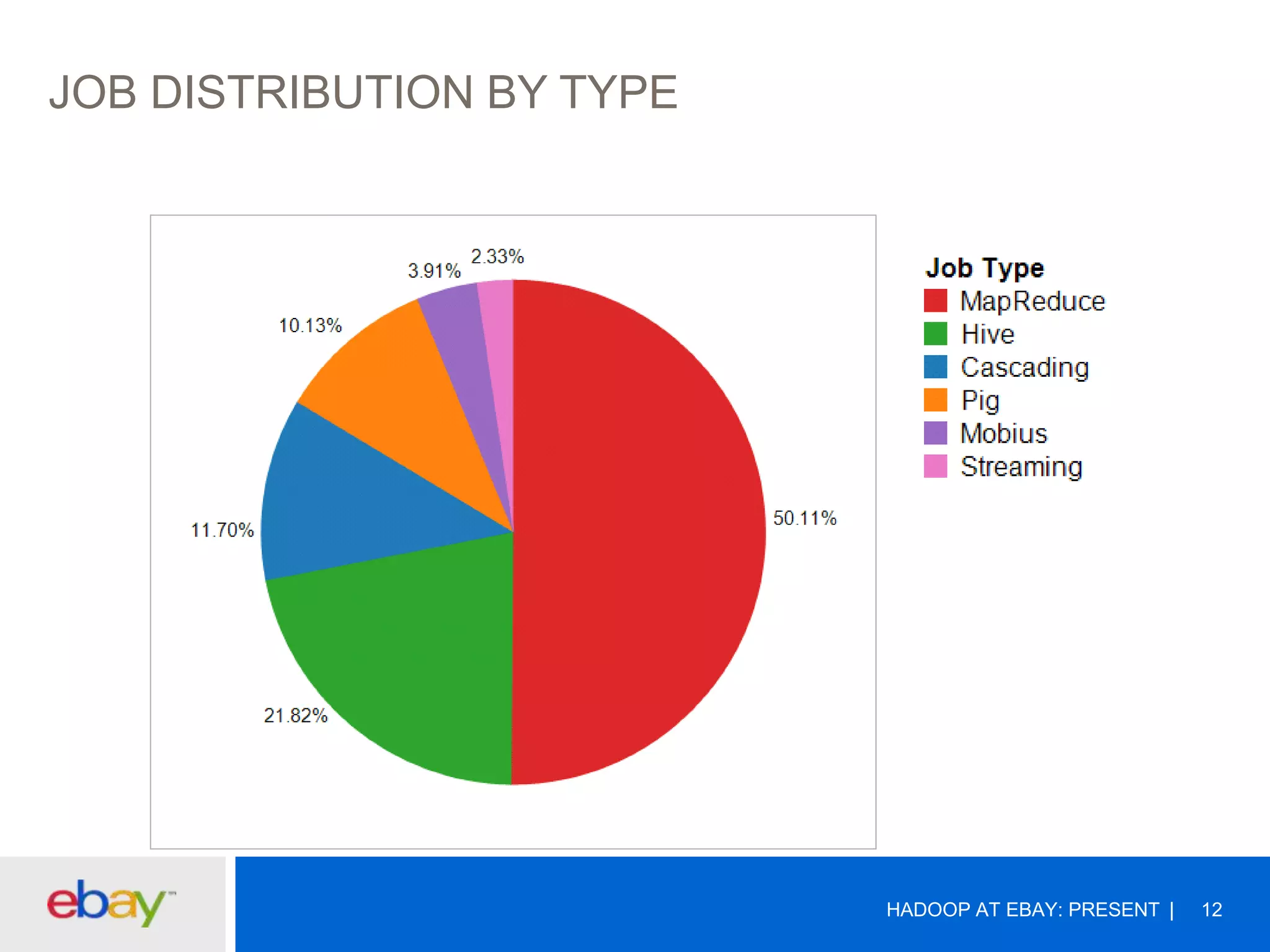




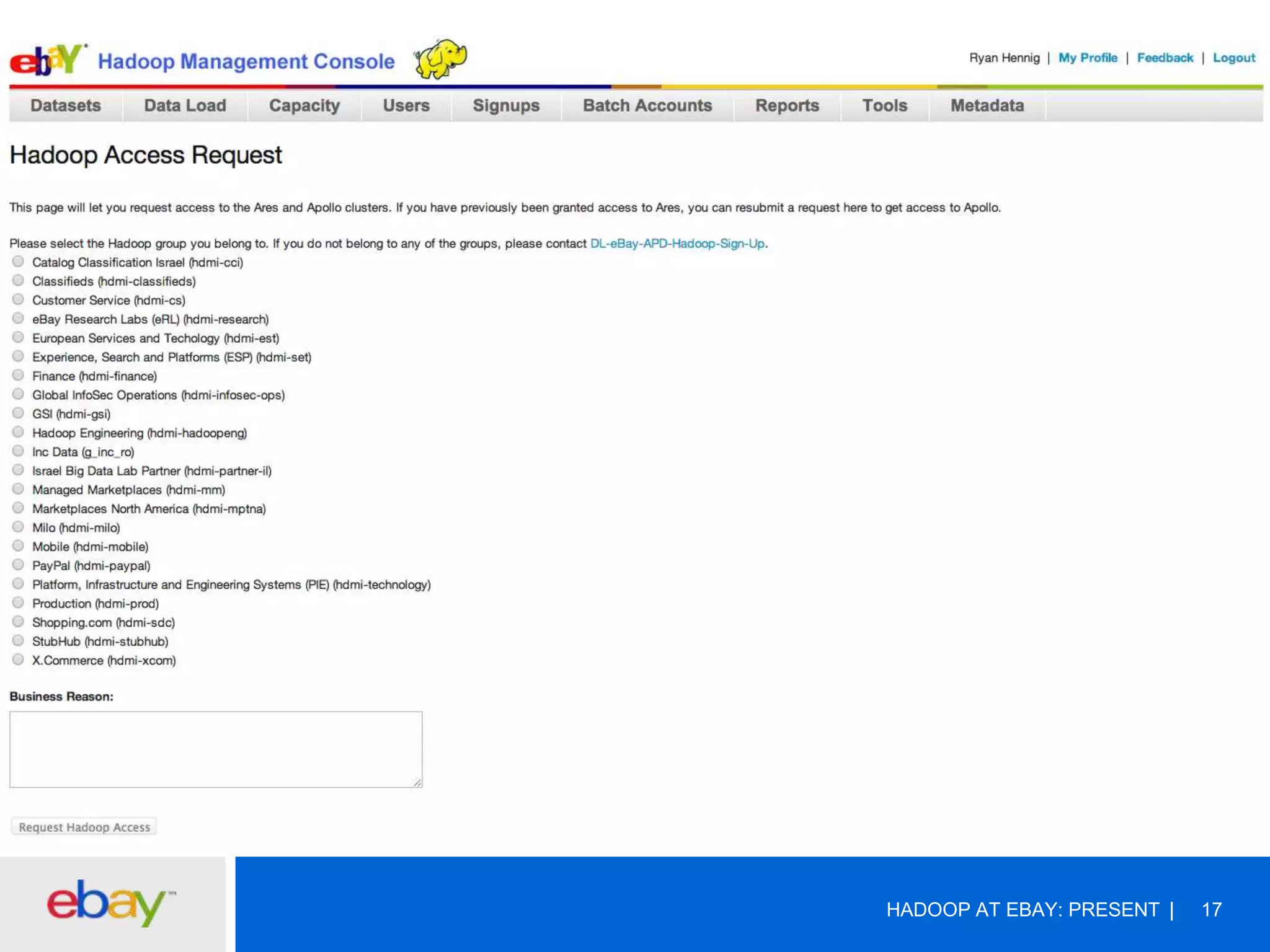
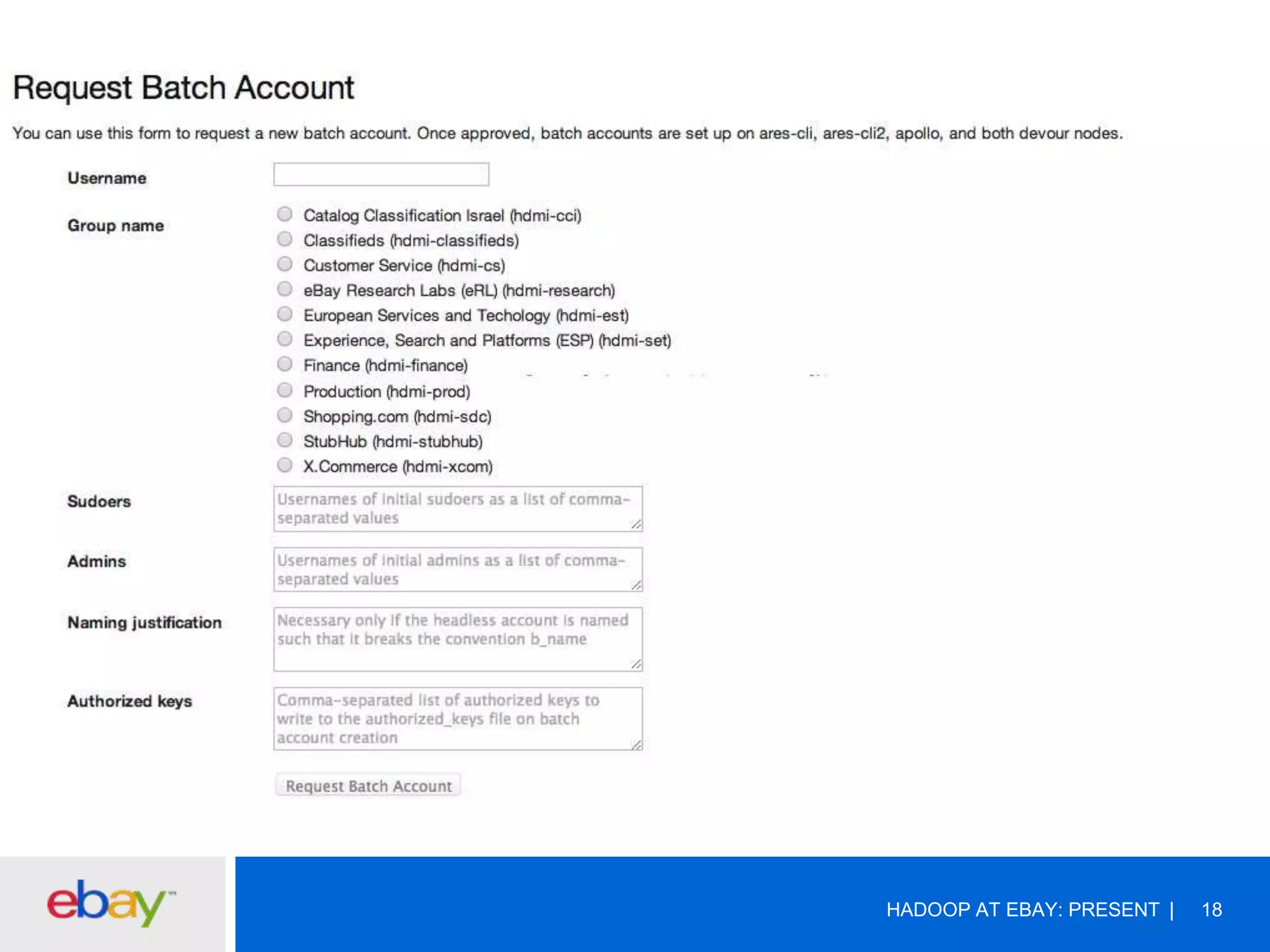
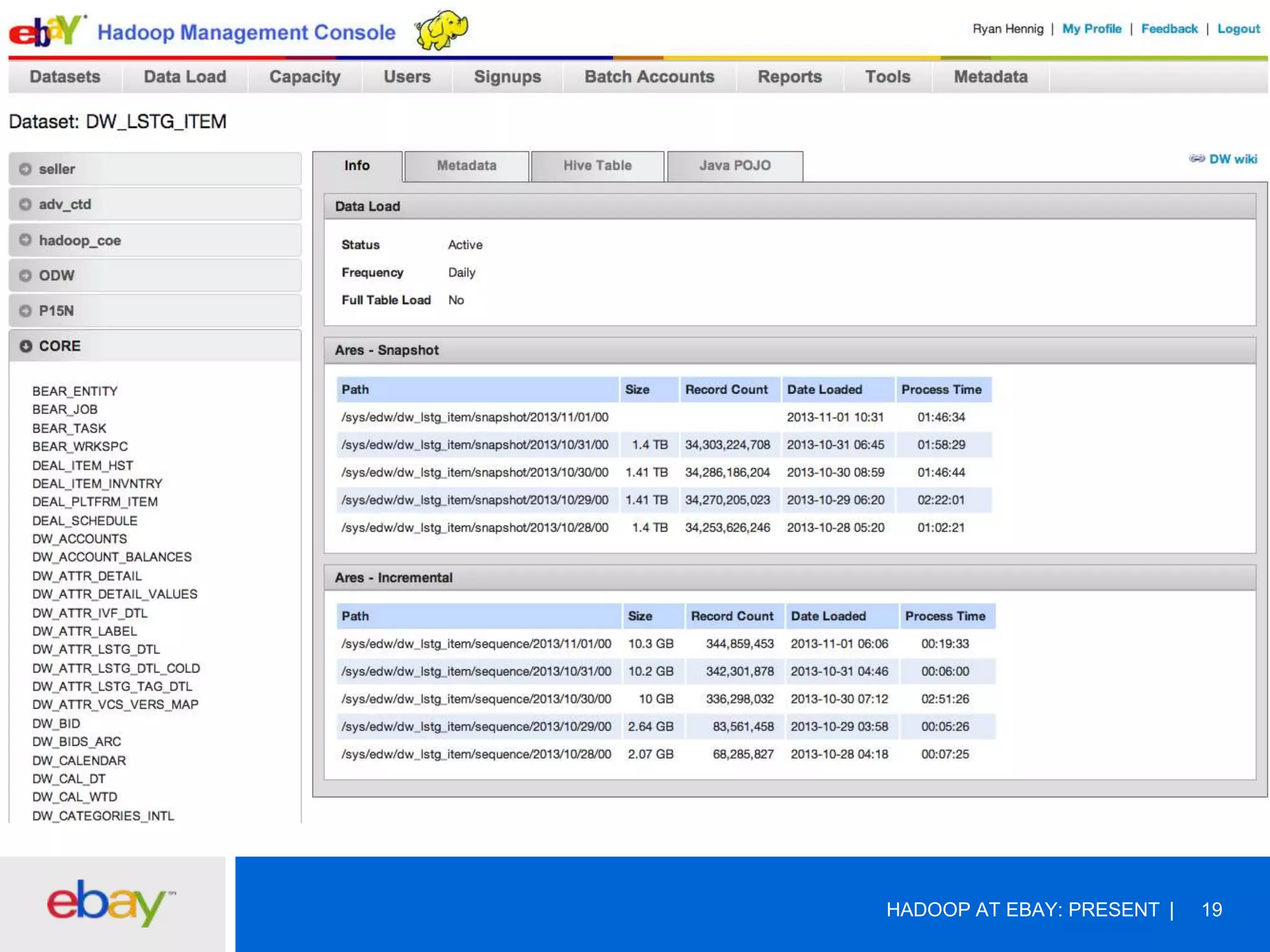
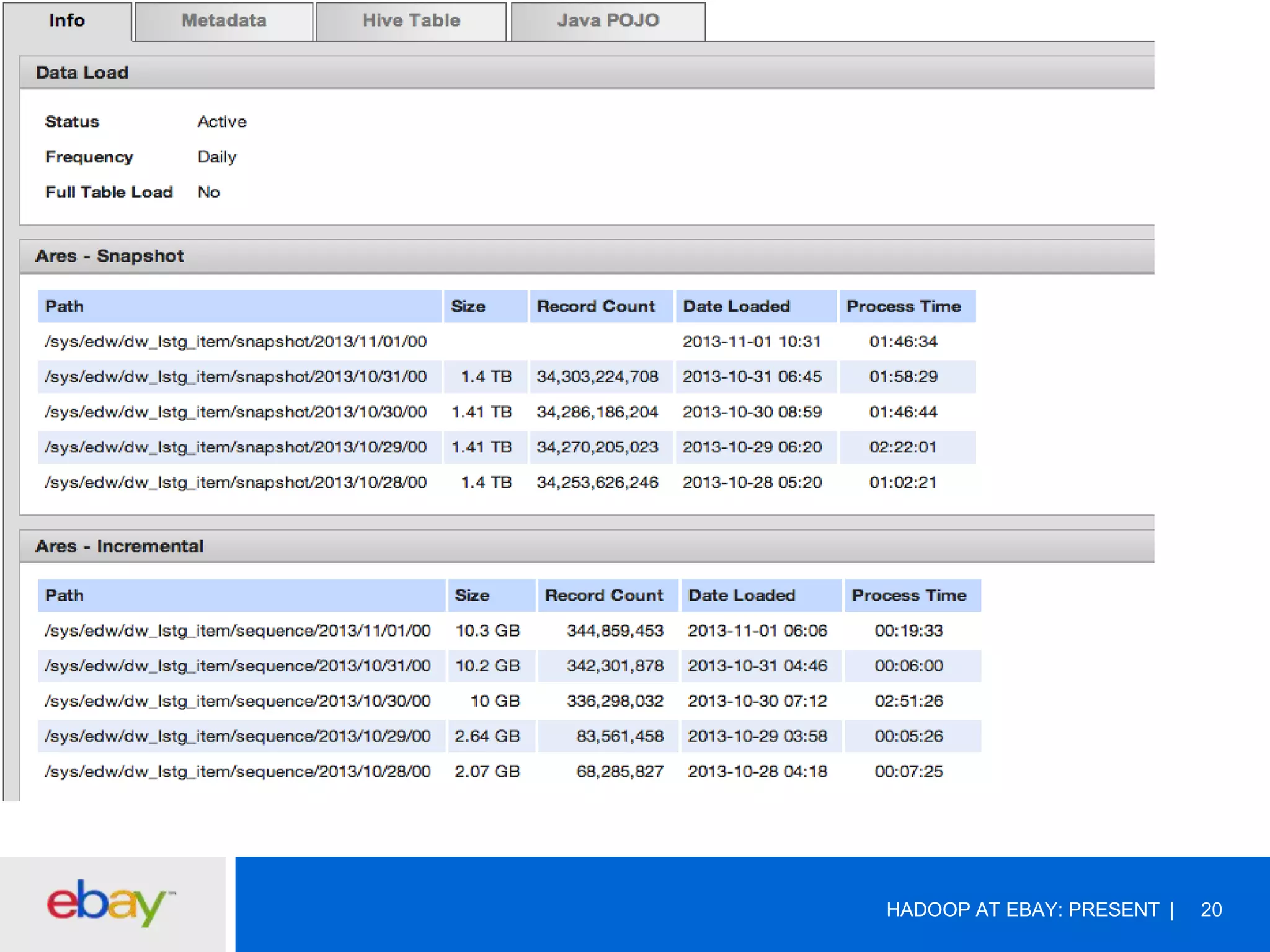
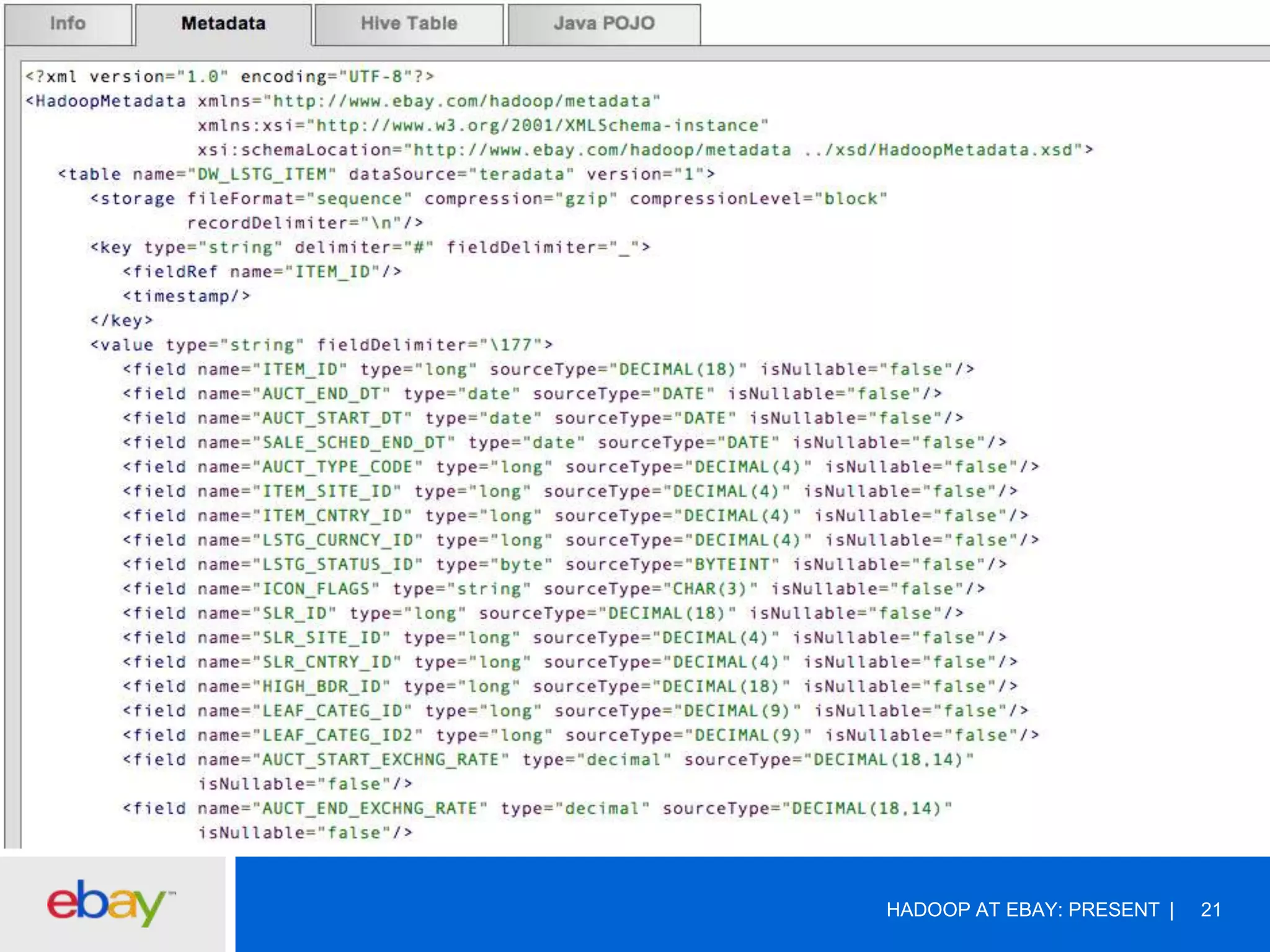
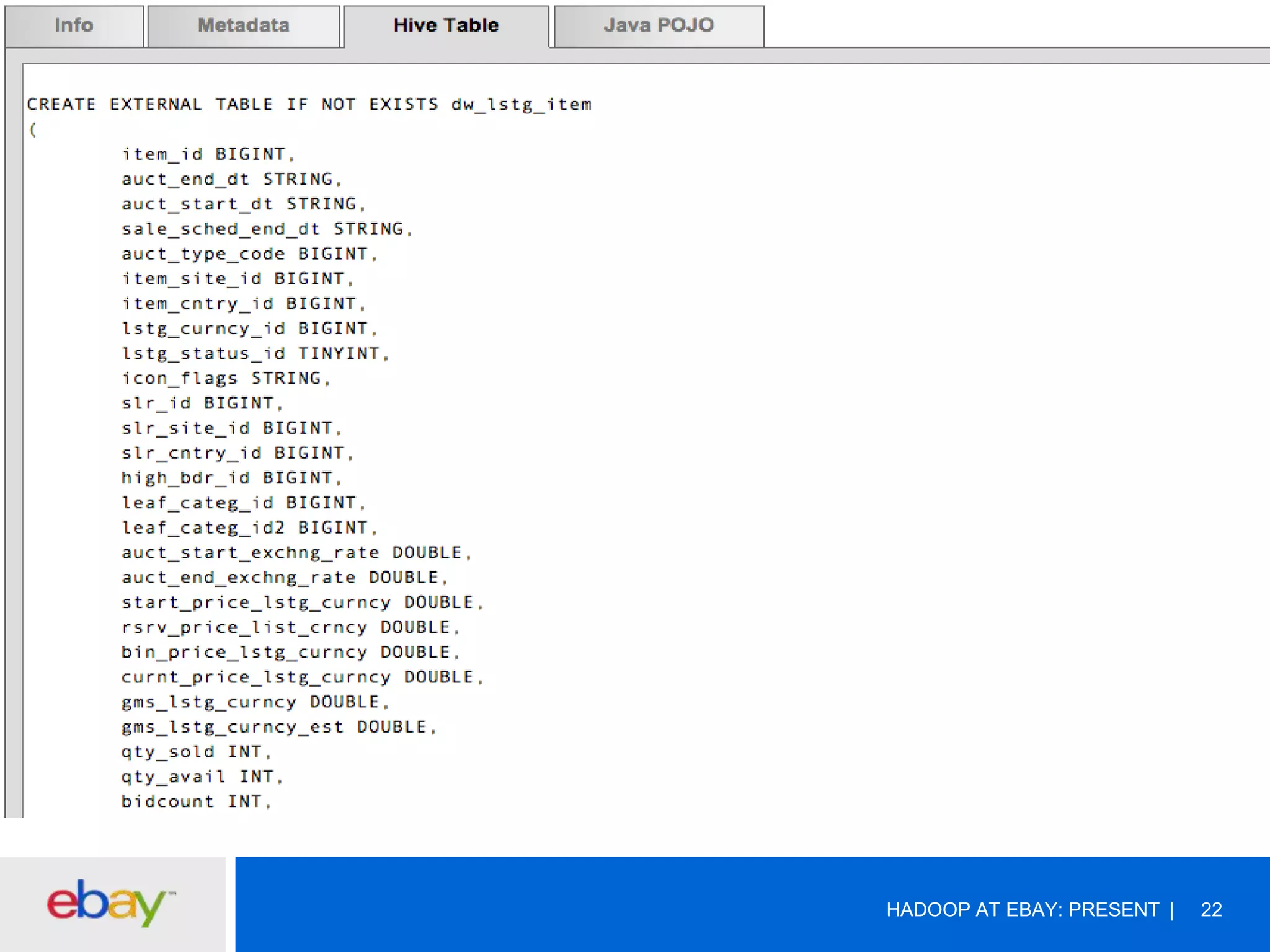
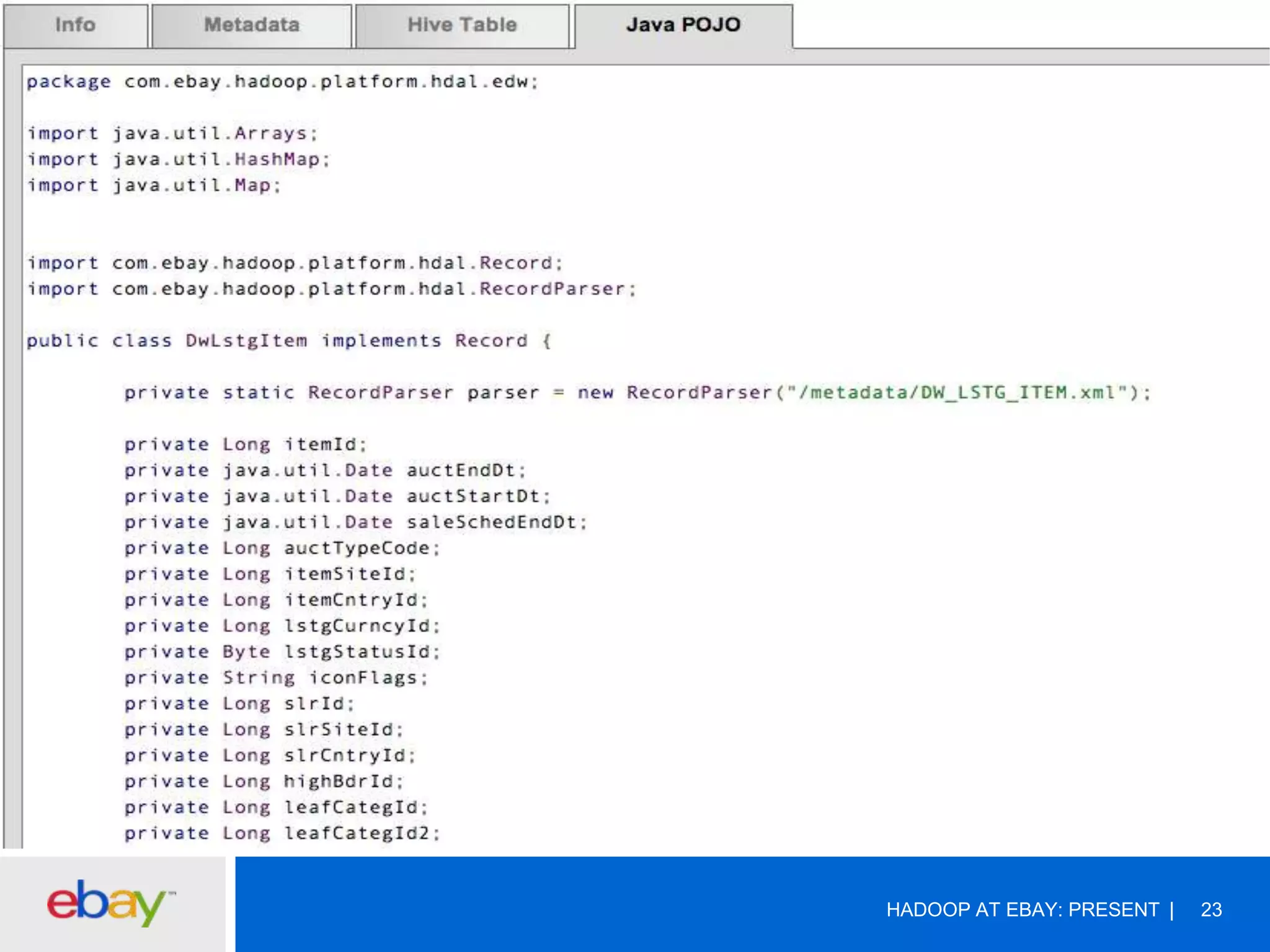



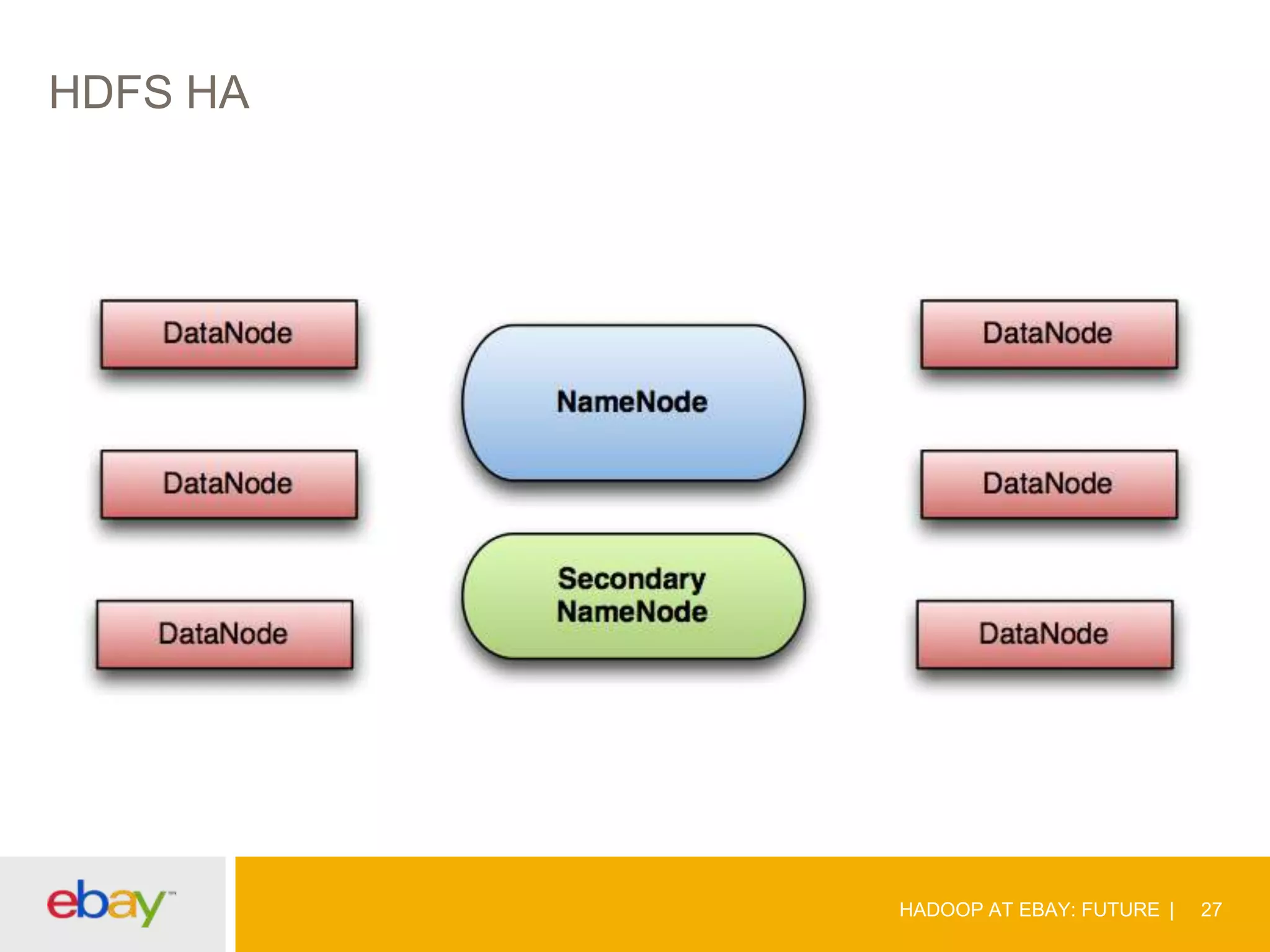
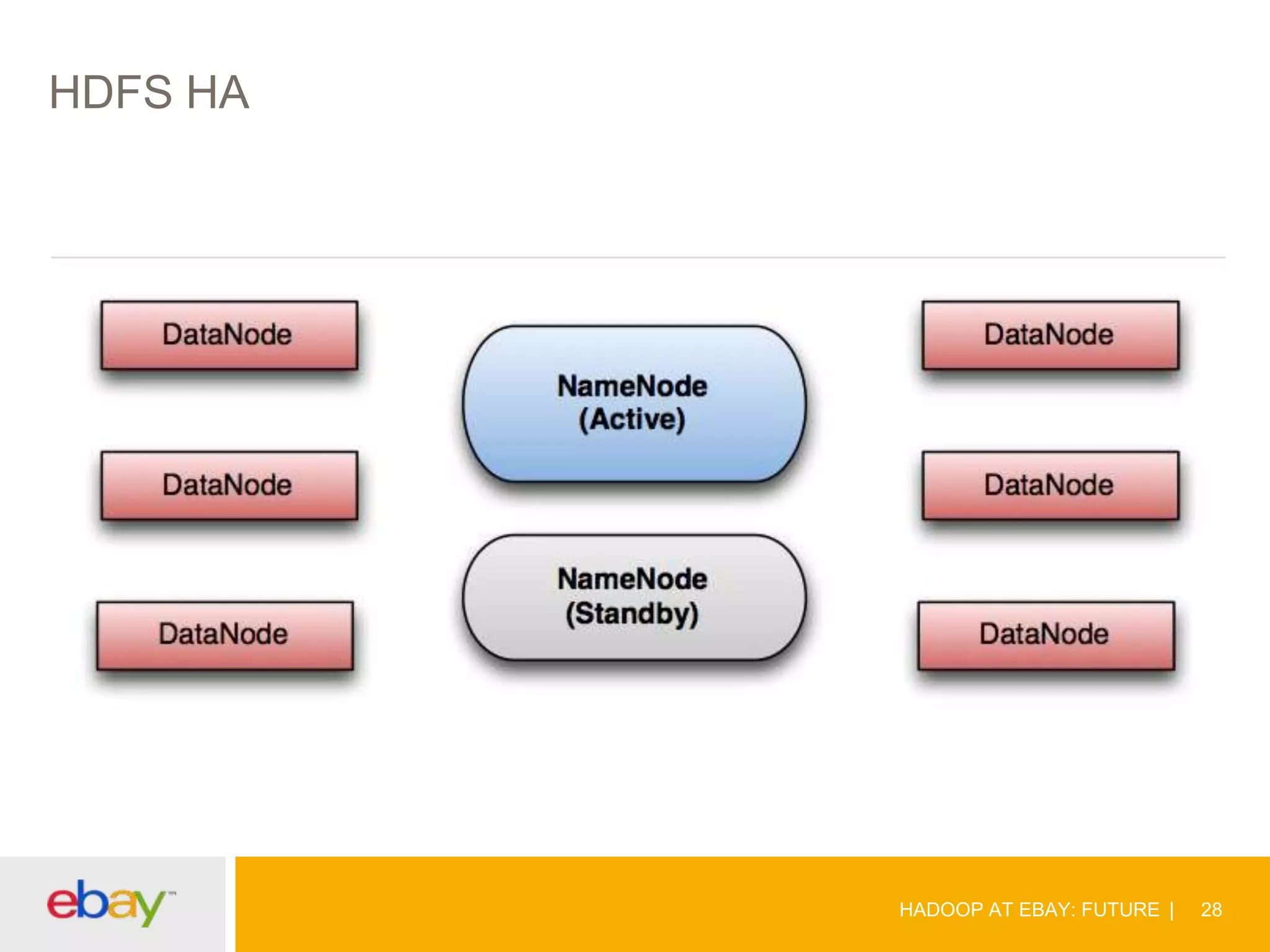
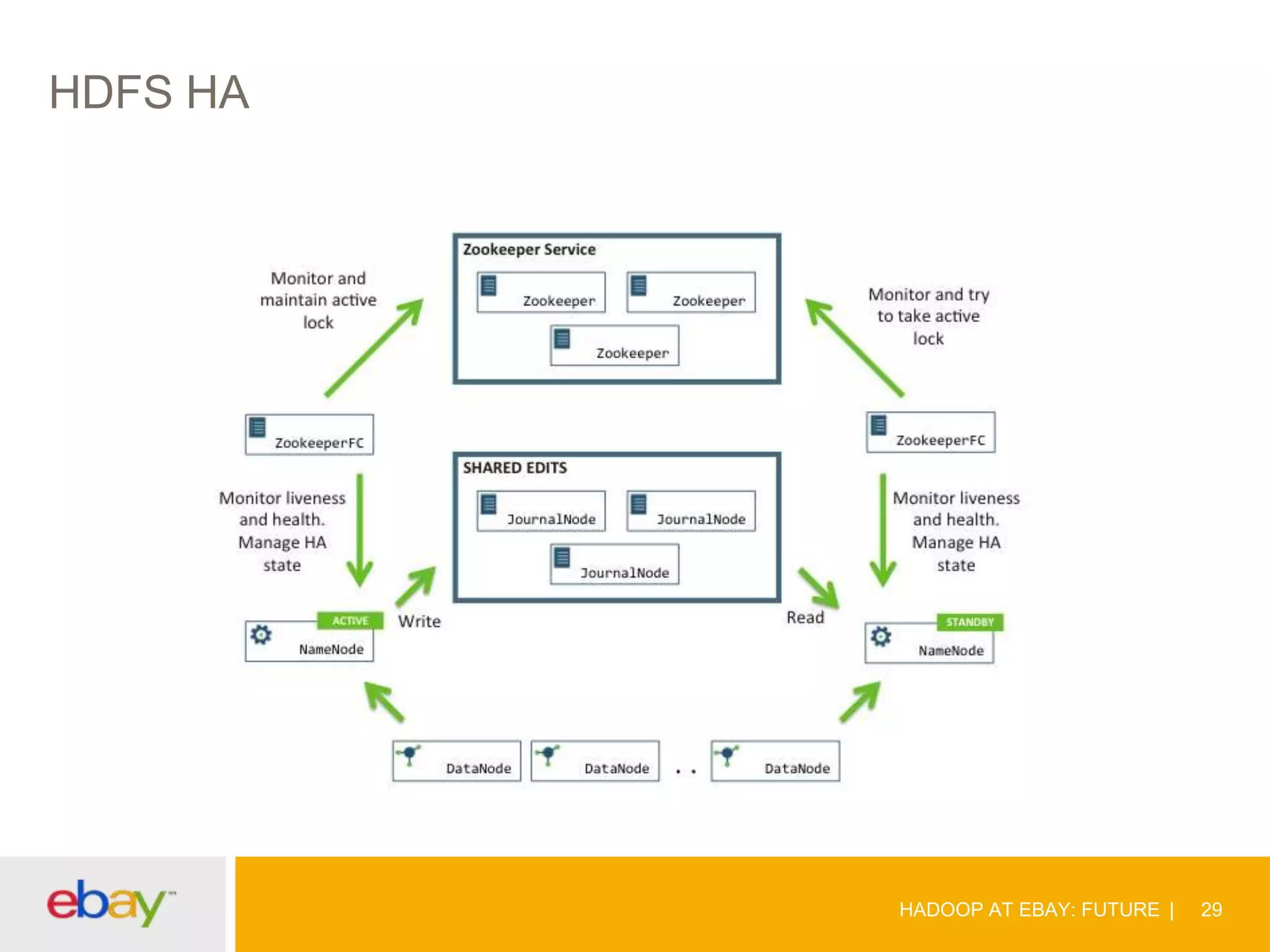
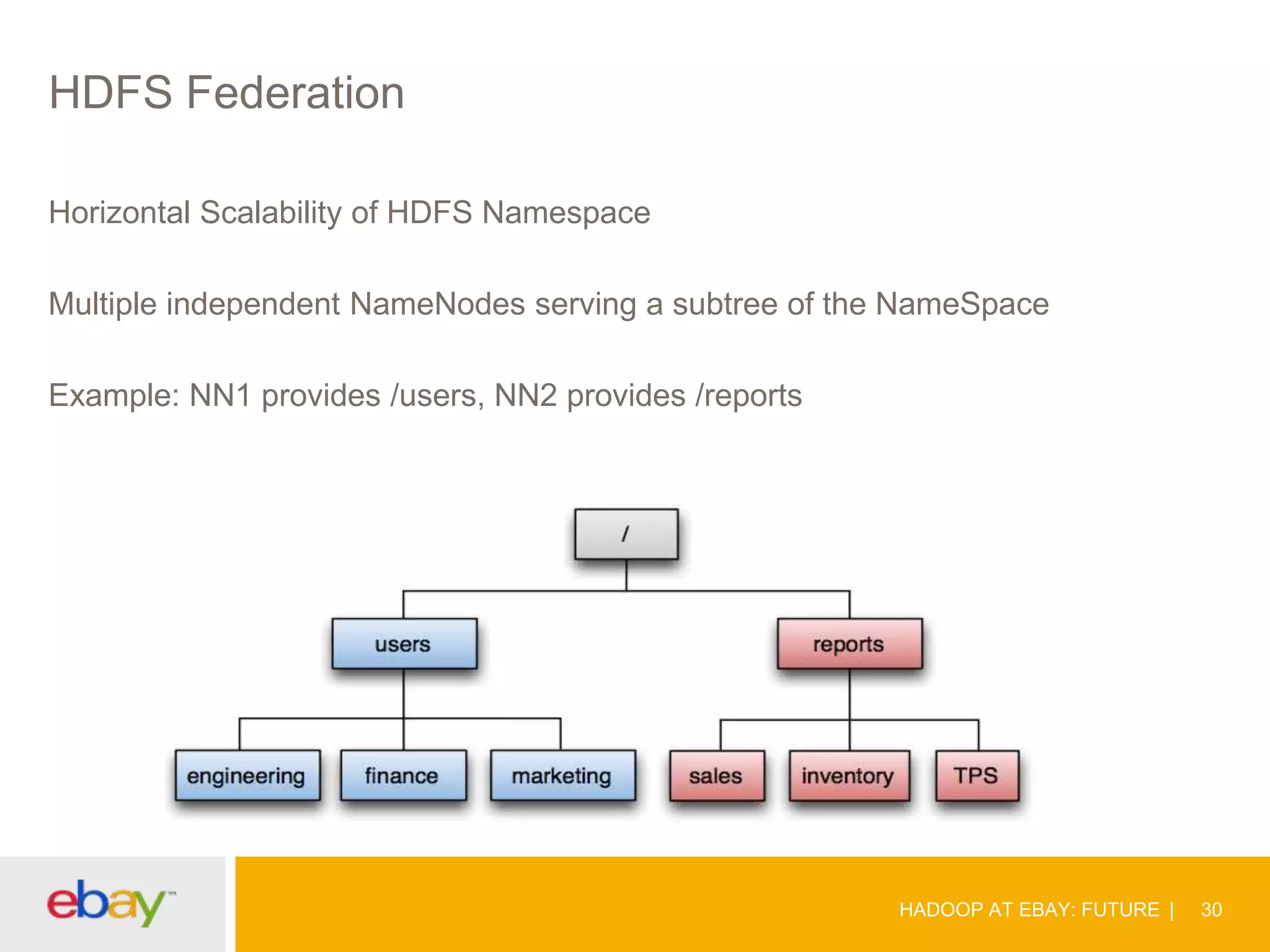

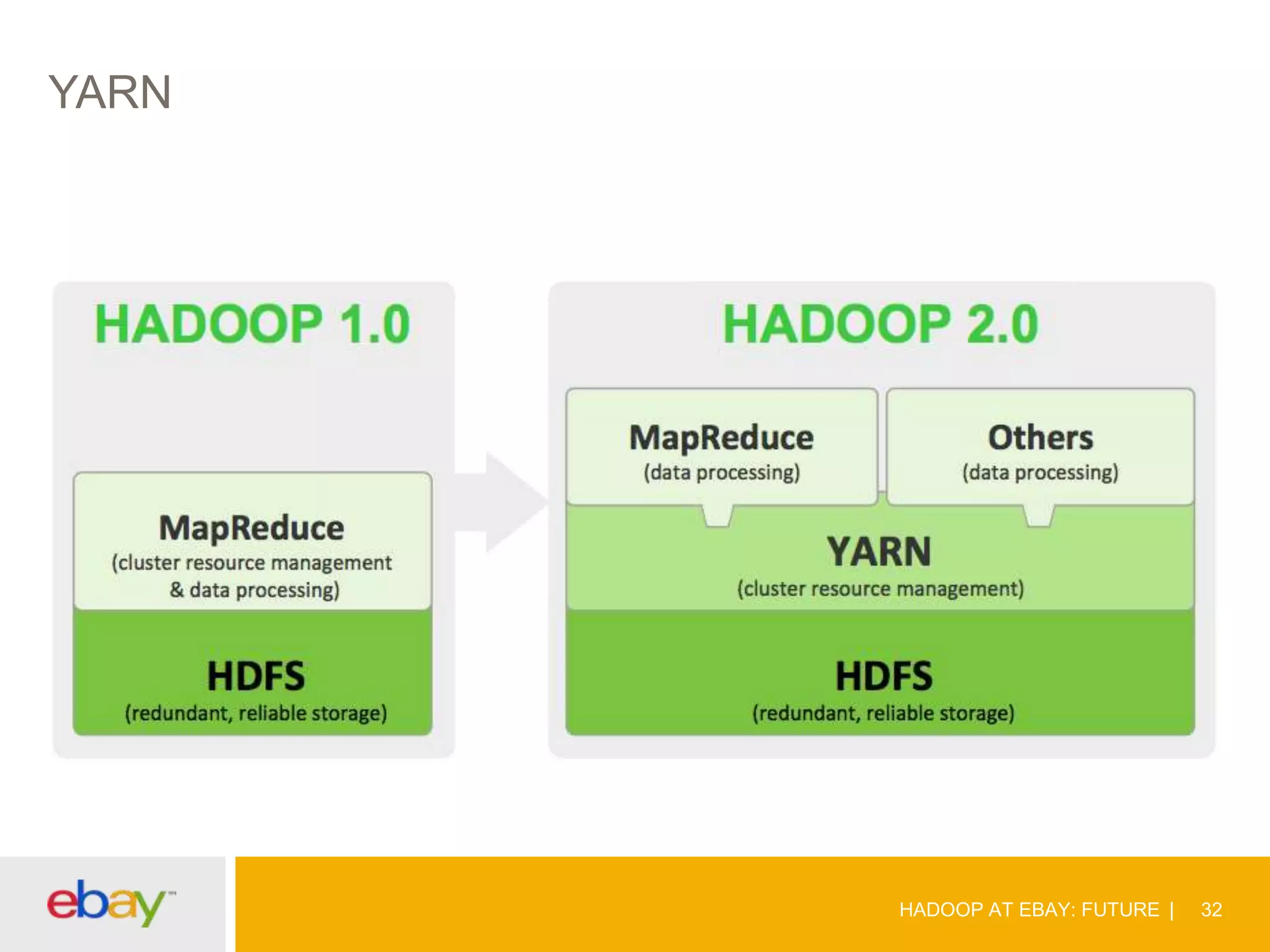
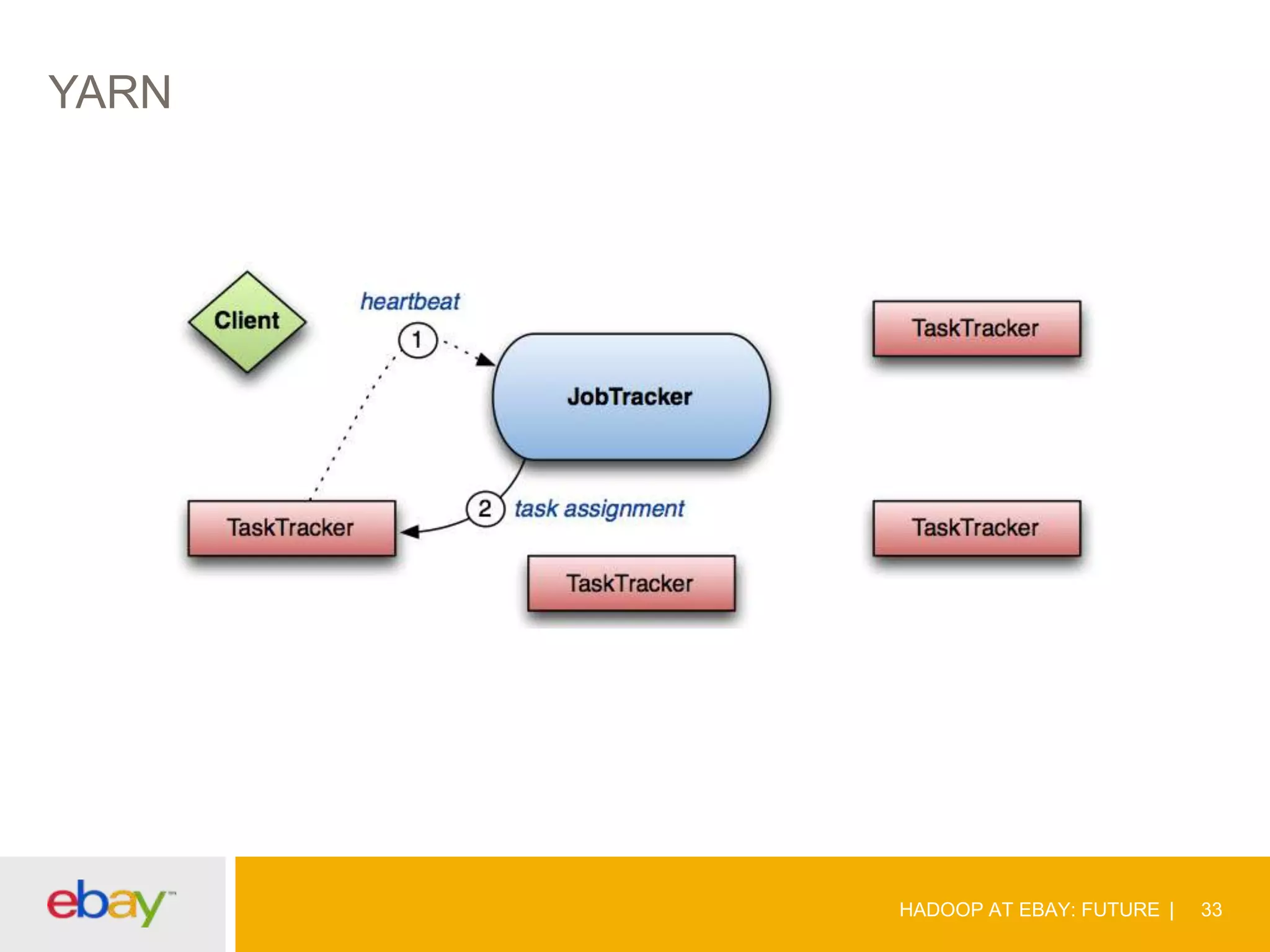
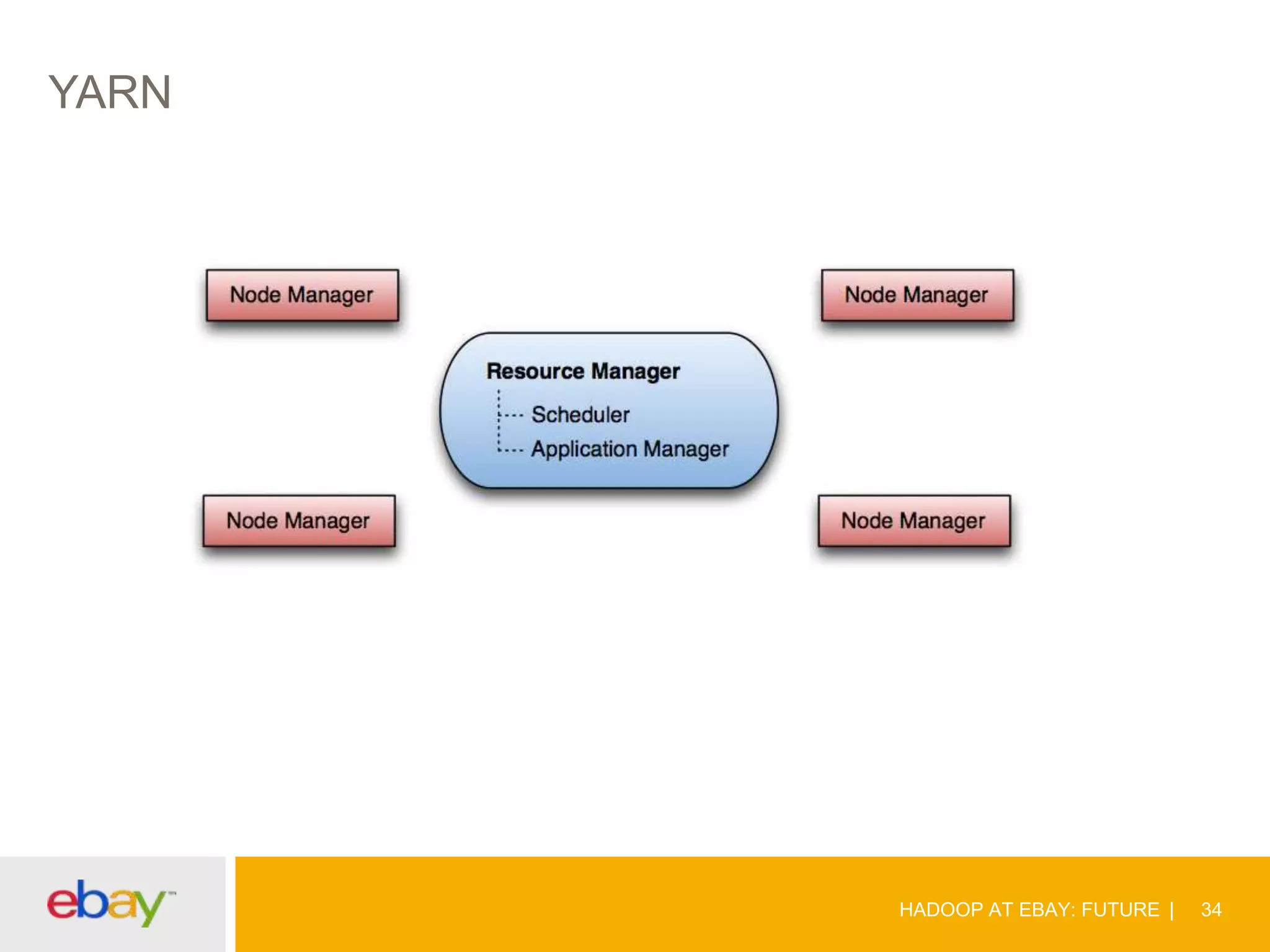
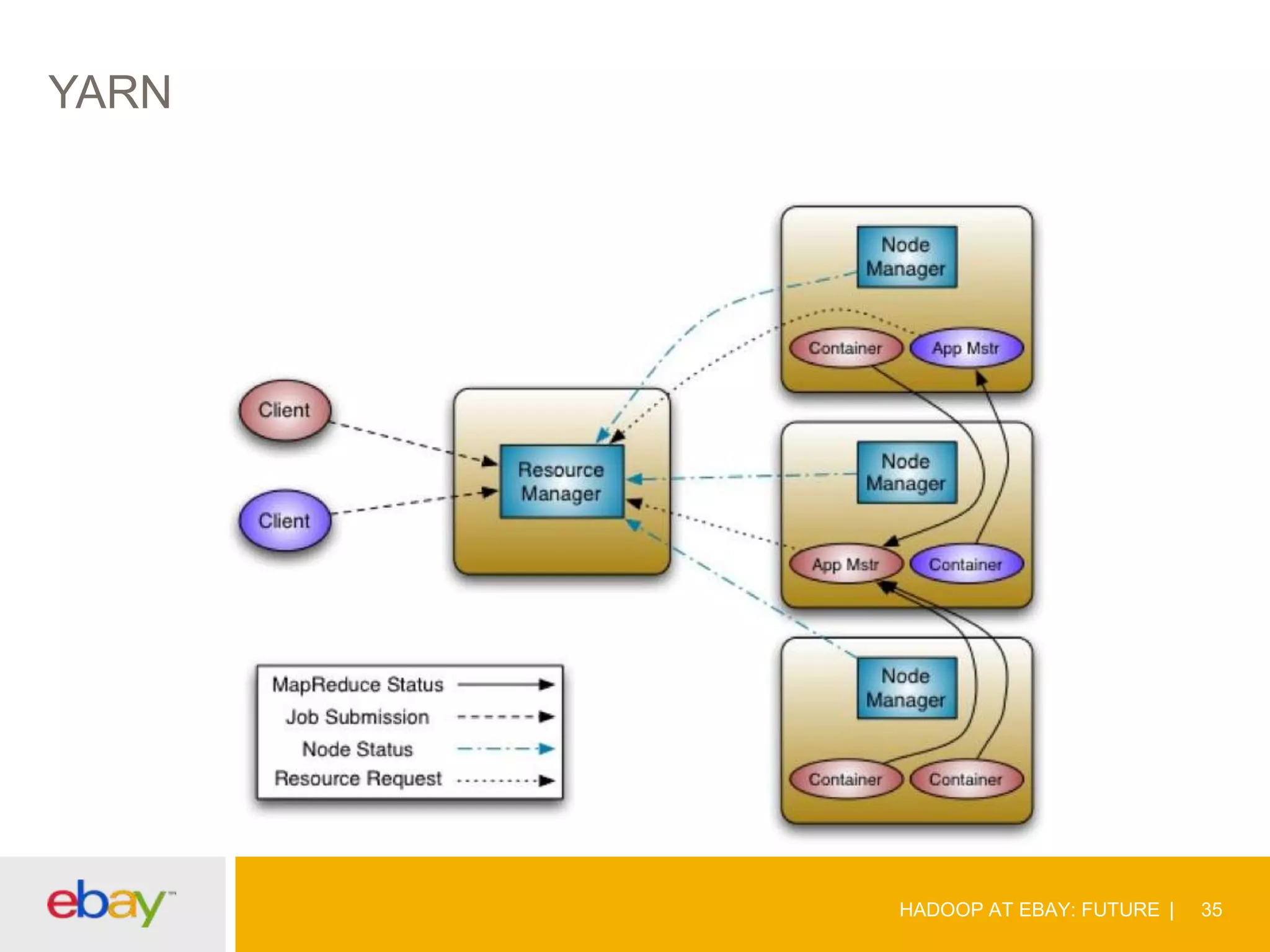





The document discusses the evolution and current use of Hadoop at eBay, detailing its growth, partnerships, and operational tools. It covers the transition from shared clusters to more specialized dedicated clusters along with various use cases such as search engine indexing and analytics dashboards. The future of Hadoop at eBay emphasizes advancements like HDFS federation, yarn for resource management, and a focus on operational efficiency and open source contributions.
![[Postgre sql9.4新機能]レプリケーション・スロットの活用](https://cdn.slidesharecdn.com/ss_thumbnails/postgresql9-140909012453-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[Pgday.Seoul 2021] 1. 예제로 살펴보는 포스트그레스큐엘의 독특한 SQL](https://cdn.slidesharecdn.com/ss_thumbnails/sql-211217063145-thumbnail.jpg?width=640&height=640&fit=bounds)






























































