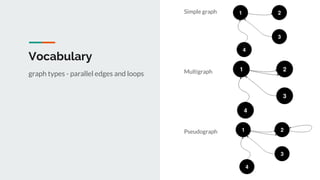
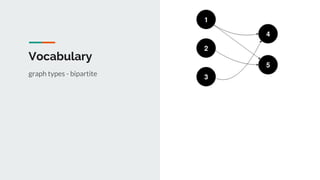
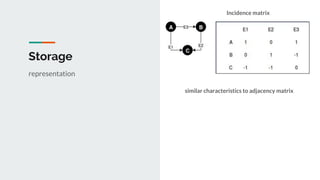
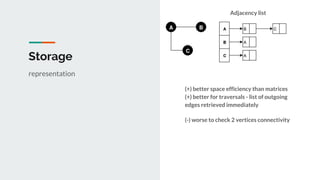
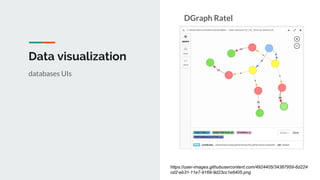
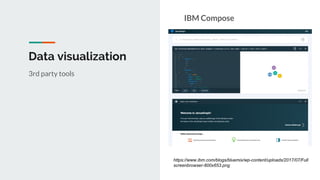
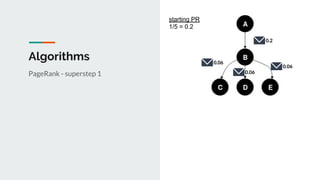
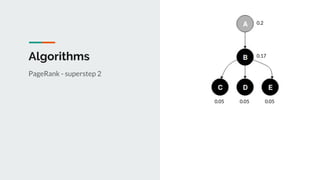
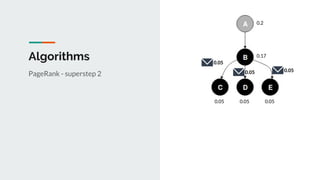
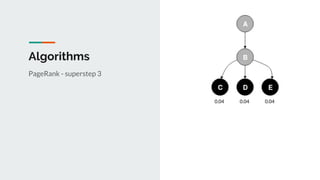
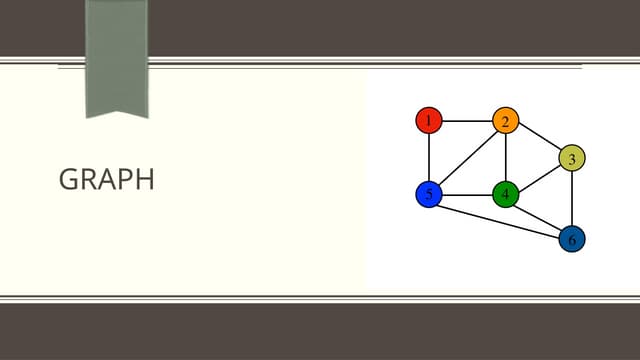
This document discusses challenges and approaches for working with graphs at scale in a distributed environment. It begins with an overview of graph terminology and representations. It then covers approaches for distributed storage of graphs using techniques like adjacency matrices, lists, and NoSQL databases. Methods for distributed graph processing are discussed, including vertex-centric, graph-centric, and streaming approaches. Graph query languages like Cypher, Gremlin and GraphQL are presented. The document also reviews algorithms like PageRank and tools for visualizing large graphs. It concludes by noting challenges like partitioning graphs across servers and providing real-time capabilities at large scale.











![Ad-hoc analysis
Cypher
● natural representation of graphs in query
language
○ expresses graph traversal
○ applies to simple and more complex
cases
● limited to Neo4J
Any edges between node1 and node2
MATCH (node1)-->(node2)
Users with more than 10 friends
MATCH (user)-[:FRIEND]-(friend) WHERE
user.name = $name WITH user,
count(friend) AS friends WHERE
friends > 10 RETURN user
Edge creation with a property
CREATE (worker)-[:WORKS_FORY {since:
2018}]->(company)
query languages](https://image.slidesharecdn.com/distributedgraphprocessing-181124050826/85/Distributed-graph-processing-22-320.jpg)











































![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)




