Download as PDF, PPTX













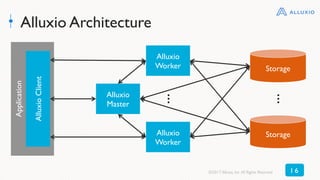
![Alluxio Client
Applications interact with Alluxio via the Alluxio client
• Java Native Alluxio Filesystem Client
• Alluxio specific operations like [un]pin, [un]mount, [un]set TTL
• HDFS-Compatible Filesystem Client
• No code change necessary
• S3 API
©2017 Alluxio, Inc.All Rights Reserved 1 7](https://image.slidesharecdn.com/la2genepang-171031223440/85/Best-Practices-for-Using-Alluxio-with-Apache-Spark-with-Gene-Pang-17-320.jpg)



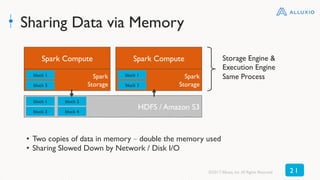
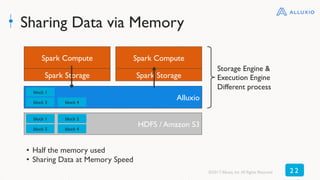
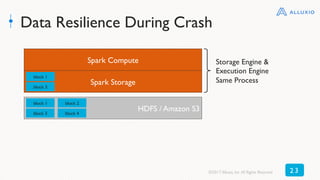
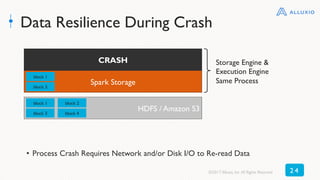







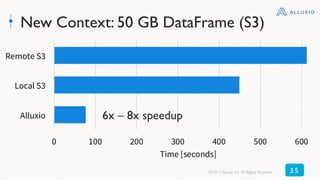



The document discusses best practices for using Alluxio with Spark, highlighting how Alluxio streamlines data access across various storage systems without requiring application changes. It provides case studies showing improved performance and operational efficiency through Alluxio, including data query enhancements resulting in up to 300x speed improvements. Additionally, the document outlines the Alluxio architecture and how to deploy it effectively with Spark for optimal I/O performance.























































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)






