Downloaded 123 times









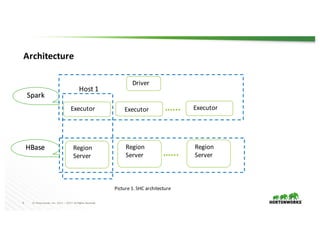
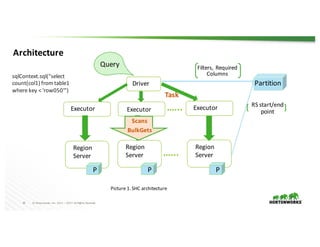
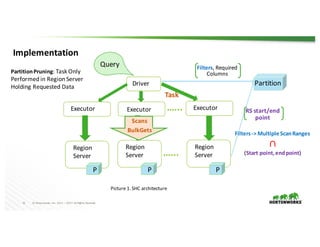
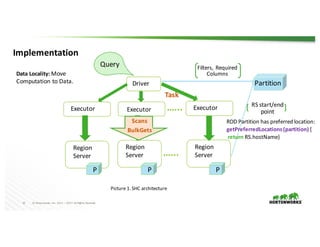
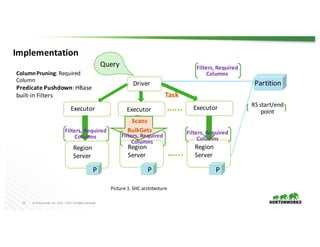
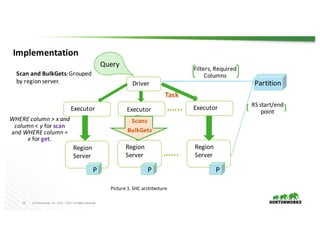








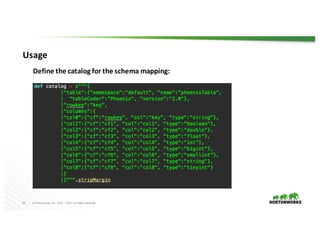





The document presents the Apache Spark - Apache HBase connector (SHC), highlighting its efficient integration with Spark for enhanced access to HBase through Spark SQL. It details the architecture, implementation, and high-performance features such as partition pruning and data locality. Additionally, it provides usage instructions and examples, along with references for further information.


![[Oracle DBA & Developer Day 2012] 高可用性システムに適した管理性と性能を向上させるASM と RMAN の魅力](https://cdn.slidesharecdn.com/ss_thumbnails/ma-4print20121205-200702094006-thumbnail.jpg?width=640&height=640&fit=bounds)
























![OOW16 - Advanced Architectures for Oracle E-Business Suite [CON6705]](https://cdn.slidesharecdn.com/ss_thumbnails/con6705-elkephelps-advanced-architectures-for-oracle-e-business-suite-160930182612-thumbnail.jpg?width=640&height=640&fit=bounds)















































































