Downloaded 71 times































![4
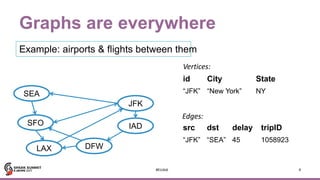
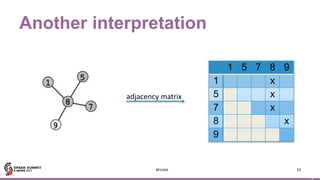
Motif finding
41
JFK
IAD
LAX
SFO
SEA
DFW
Search for structural
patterns within a graph.
val paths: DataFrame =
g.find(“(a)-[e1]->(b);
(b)-[e2]->(c);
!(c)-[]->(a)”)
#EUds6](https://image.slidesharecdn.com/17-10-25sparksummiteuropegraphframespurple3-171031172920/85/Web-Scale-Graph-Analytics-with-Apache-Spark-with-Tim-Hunter-40-320.jpg)
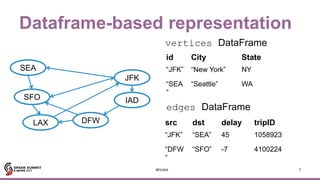
![4
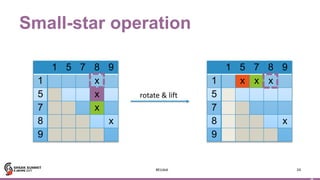
Motif finding
42
JFK
IAD
LAX
SFO
SEA
DFW
(b)
(a)Search for structural
patterns within a graph.
val paths: DataFrame =
g.find(“(a)-[e1]->(b);
(b)-[e2]->(c);
!(c)-[]->(a)”)
#EUds6](https://image.slidesharecdn.com/17-10-25sparksummiteuropegraphframespurple3-171031172920/85/Web-Scale-Graph-Analytics-with-Apache-Spark-with-Tim-Hunter-41-320.jpg)
![4
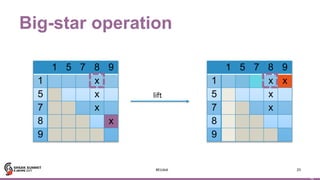
Motif finding
43
JFK
IAD
LAX
SFO
SEA
DFW
(b)
(a)
(c)
Search for structural
patterns within a graph.
val paths: DataFrame =
g.find(“(a)-[e1]->(b);
(b)-[e2]->(c);
!(c)-[]->(a)”)
#EUds6](https://image.slidesharecdn.com/17-10-25sparksummiteuropegraphframespurple3-171031172920/85/Web-Scale-Graph-Analytics-with-Apache-Spark-with-Tim-Hunter-42-320.jpg)
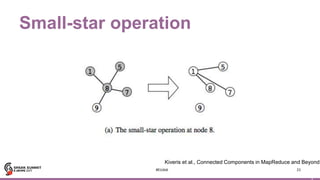
![4
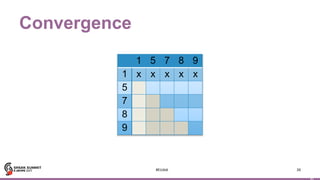
Motif finding
44
JFK
IAD
LAX
SFO
SEA
DFW
(b)
(a)
(c)
Search for structural
patterns within a graph.
val paths: DataFrame =
g.find(“(a)-[e1]->(b);
(b)-[e2]->(c);
!(c)-[]->(a)”)
#EUds6](https://image.slidesharecdn.com/17-10-25sparksummiteuropegraphframespurple3-171031172920/85/Web-Scale-Graph-Analytics-with-Apache-Spark-with-Tim-Hunter-43-320.jpg)
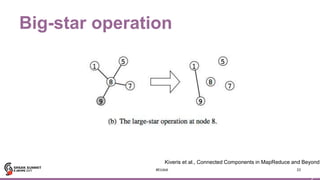
![4
Motif finding
45
JFK
IAD
LAX
SFO
SEA
DFW
Search for structural
patterns within a graph.
val paths: DataFrame =
g.find(“(a)-[e1]->(b);
(b)-[e2]->(c);
!(c)-[]->(a)”)
(b)
(a)
(c)
Then filter using vertex
& edge data.
paths.filter(“e1.delay > 20”)
#EUds6](https://image.slidesharecdn.com/17-10-25sparksummiteuropegraphframespurple3-171031172920/85/Web-Scale-Graph-Analytics-with-Apache-Spark-with-Tim-Hunter-44-320.jpg)



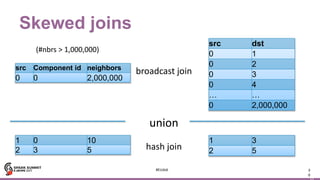
The document discusses web-scale graph analytics using Apache Spark, focusing on the GraphFrames package that simplifies using DataFrames for graph processing. It covers the implementation of scalable algorithms for tasks like connected components, incorporates challenges such as skewed joins, and highlights experimental results comparing GraphX and GraphFrames performance. Future improvements and additional graph analysis capabilities, including motif finding and various graph algorithms, are also presented.























































































