Download as PDF, PPTX





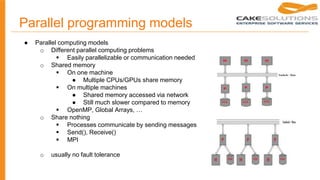








![Performance
Hadoop Spark Spark
Data size 102.5 TB 100 TB 1000 TB
Time [min] 72 23 234
Nodes 2100 206 190
Cores 50400 6592 6080
Rate/node [GB/min] 0.67 20.7 22.5
Environment dedicated data center EC2 EC2
● fastest open source solution to sort 100TB data in Daytona Gray Sort Benchmark (http:
//sortbenchmark.org/)
● required some improvements in shuffle approach
● very optimized sorting algorithm (cache locality, unsafe off-heap memory structures, gc, …)
● Databricks blog + presentation](https://image.slidesharecdn.com/ywmbjyaprb2bapj6copq-signature-3db3a17e1556848bfe53049583963bbef677077a5f04358c90161dc3d524fda3-poli-150329134145-conversion-gate01/85/Apache-spark-Spark-s-distributed-programming-model-15-320.jpg)





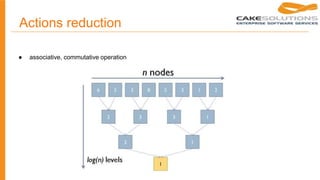



![Shared variables - accumulators
object VectorAccumulatorParam extends AccumulatorParam[Vector] {
def zero(initialValue: Vector): Vector = {
Vector.zeros(initialValue.size)
}
def addInPlace(v1: Vector, v2: Vector): Vector = {
v1 += v2
}
}](https://image.slidesharecdn.com/ywmbjyaprb2bapj6copq-signature-3db3a17e1556848bfe53049583963bbef677077a5f04358c90161dc3d524fda3-poli-150329134145-conversion-gate01/85/Apache-spark-Spark-s-distributed-programming-model-25-320.jpg)



Spark's distributed programming model uses resilient distributed datasets (RDDs) and a directed acyclic graph (DAG) approach. RDDs support transformations like map, filter, and actions like collect. Transformations are lazy and form the DAG, while actions execute the DAG. RDDs support caching, partitioning, and sharing state through broadcasts and accumulators. The programming model aims to optimize the DAG through operations like predicate pushdown and partition coalescing.































![[임팩트투자 디파티] 닷(dot) 최아름 팀장_D.CAMP_201607](https://cdn.slidesharecdn.com/ss_thumbnails/dot0720-160725082957-thumbnail.jpg?width=640&height=640&fit=bounds)




























































