

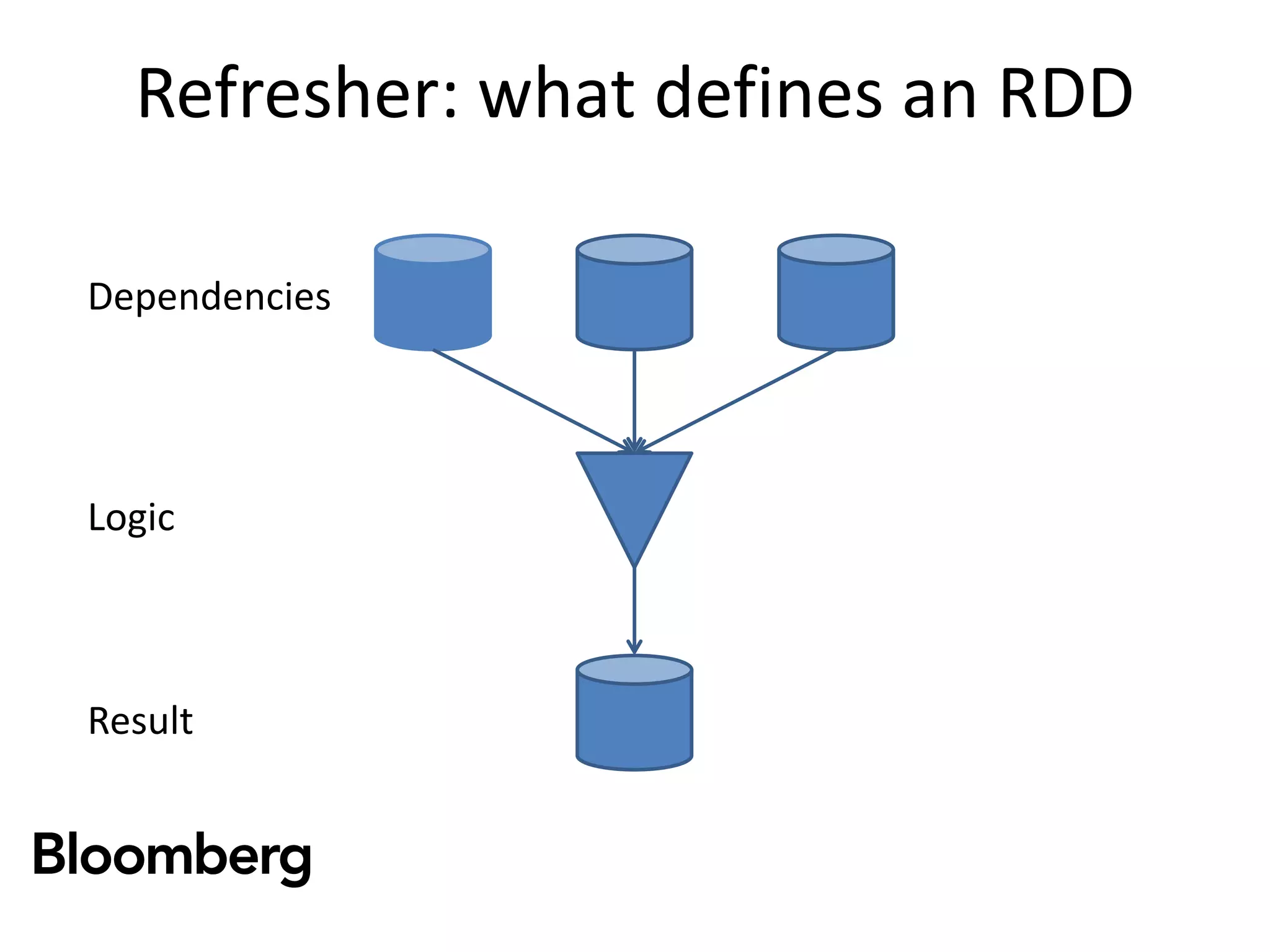
![Refresher: what defines an RDD
Dependencies
Logic
Result
[1,2,3,4,5…]
[2,4,6,8,10…]
map(x => x*2)](https://image.slidesharecdn.com/ksyht1agrv6vlu4zdkmb-signature-69355c809d9a6336ca38bf5abf1dae264186cfd906eb899523a9fe08c1b9f6c7-poli-160812175307/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Iterative-Spark-Development-at-Bloomberg-Nimbus-Goehausen-Senior-Software-Engineer-Bloomberg-13-2048.jpg)






![RDD vs DC
val numbers: DC[Int] = parallelize(1 to 10)
val filtered: DC[Int] = numbers.filter(_ < 5)
val doubled: DC[Int] = filtered.map(_ * 2)
val doubledRDD: RDD[Int] = doubled.getRDD(sc)
val numbers: RDD[Int] = sc.parallelize(1 to 10)
val filtered: RDD[Int] = numbers.filter(_ < 5)
val doubled: RDD[Int] = filtered.map(_ * 2)](https://image.slidesharecdn.com/ksyht1agrv6vlu4zdkmb-signature-69355c809d9a6336ca38bf5abf1dae264186cfd906eb899523a9fe08c1b9f6c7-poli-160812175307/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Iterative-Spark-Development-at-Bloomberg-Nimbus-Goehausen-Senior-Software-Engineer-Bloomberg-21-2048.jpg)
![Easy checkpoint
val numbers: DC[Int] = parallelize(1 to 10)
val filtered: DC[Int] = numbers.filter(_ < 5).checkpoint()
val doubled: DC[Int] = filtered.map(_ * 2)](https://image.slidesharecdn.com/ksyht1agrv6vlu4zdkmb-signature-69355c809d9a6336ca38bf5abf1dae264186cfd906eb899523a9fe08c1b9f6c7-poli-160812175307/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Iterative-Spark-Development-at-Bloomberg-Nimbus-Goehausen-Senior-Software-Engineer-Bloomberg-22-2048.jpg)
![Problem: Non lazy definition
val numbers: RDD[Int] = sc.parallelize(1 to 10)
val doubles: RDD[Double] = numbers.map(x => x.toDouble)
val sum: Double = doubles.sum()
val normalized: RDD[Double] = doubles.map(x => x / sum)
We can’t get a signature of `normalized` without computing the sum!](https://image.slidesharecdn.com/ksyht1agrv6vlu4zdkmb-signature-69355c809d9a6336ca38bf5abf1dae264186cfd906eb899523a9fe08c1b9f6c7-poli-160812175307/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Iterative-Spark-Development-at-Bloomberg-Nimbus-Goehausen-Senior-Software-Engineer-Bloomberg-23-2048.jpg)

![Deferred Result example
val numbers: DC[Int] = parallelize(1 to 10)
val doubles: DC[Double] = numbers.map(x => x.toDouble)
val sum: DR[Double] = doubles.sum()
val normalized: DC[Double] = doubles.withResult(sum).map{case (x, s) => x / s}
We can compute a signature for `normalized` without computing a sum.](https://image.slidesharecdn.com/ksyht1agrv6vlu4zdkmb-signature-69355c809d9a6336ca38bf5abf1dae264186cfd906eb899523a9fe08c1b9f6c7-poli-160812175307/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Iterative-Spark-Development-at-Bloomberg-Nimbus-Goehausen-Senior-Software-Engineer-Bloomberg-25-2048.jpg)




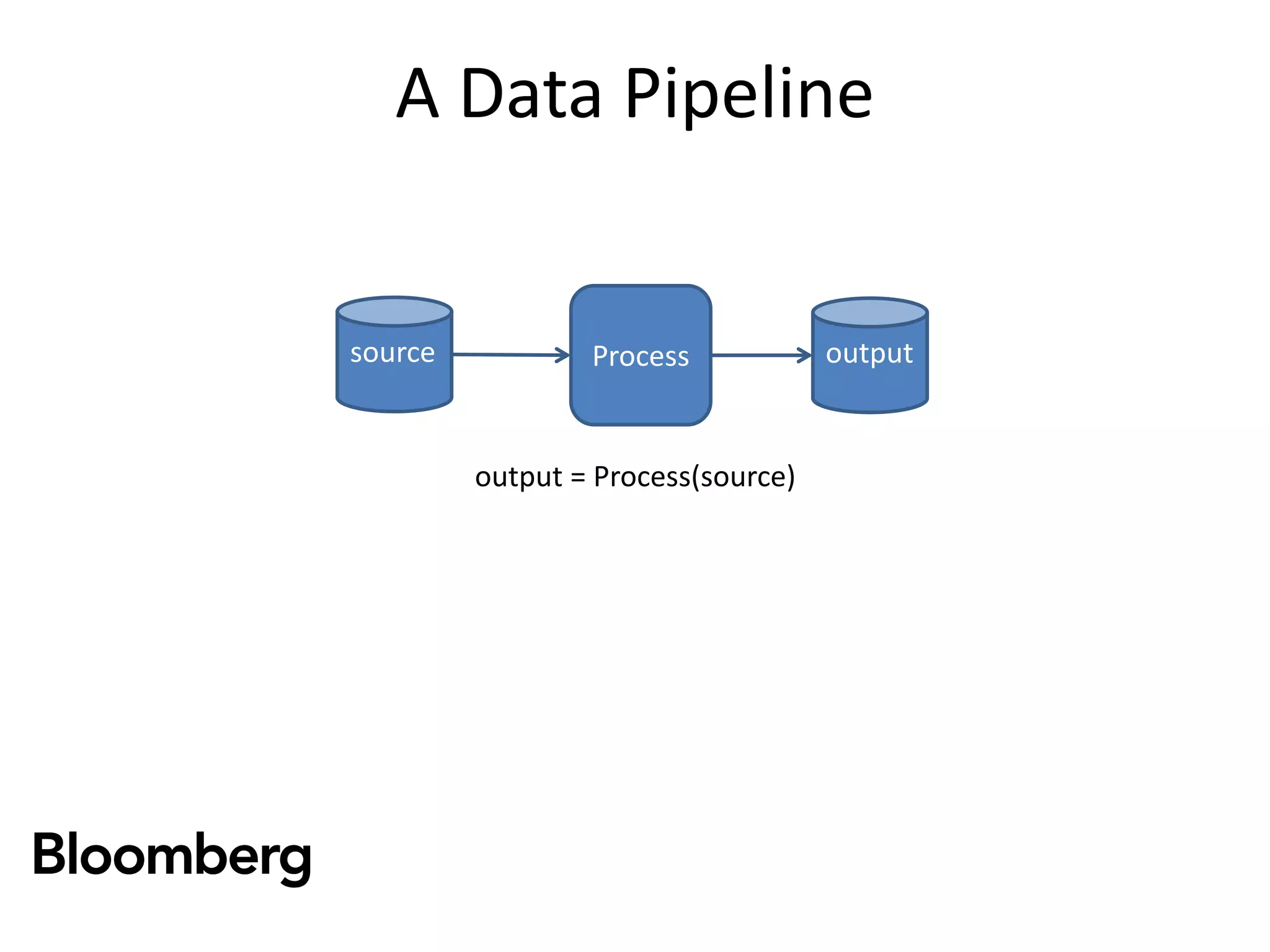
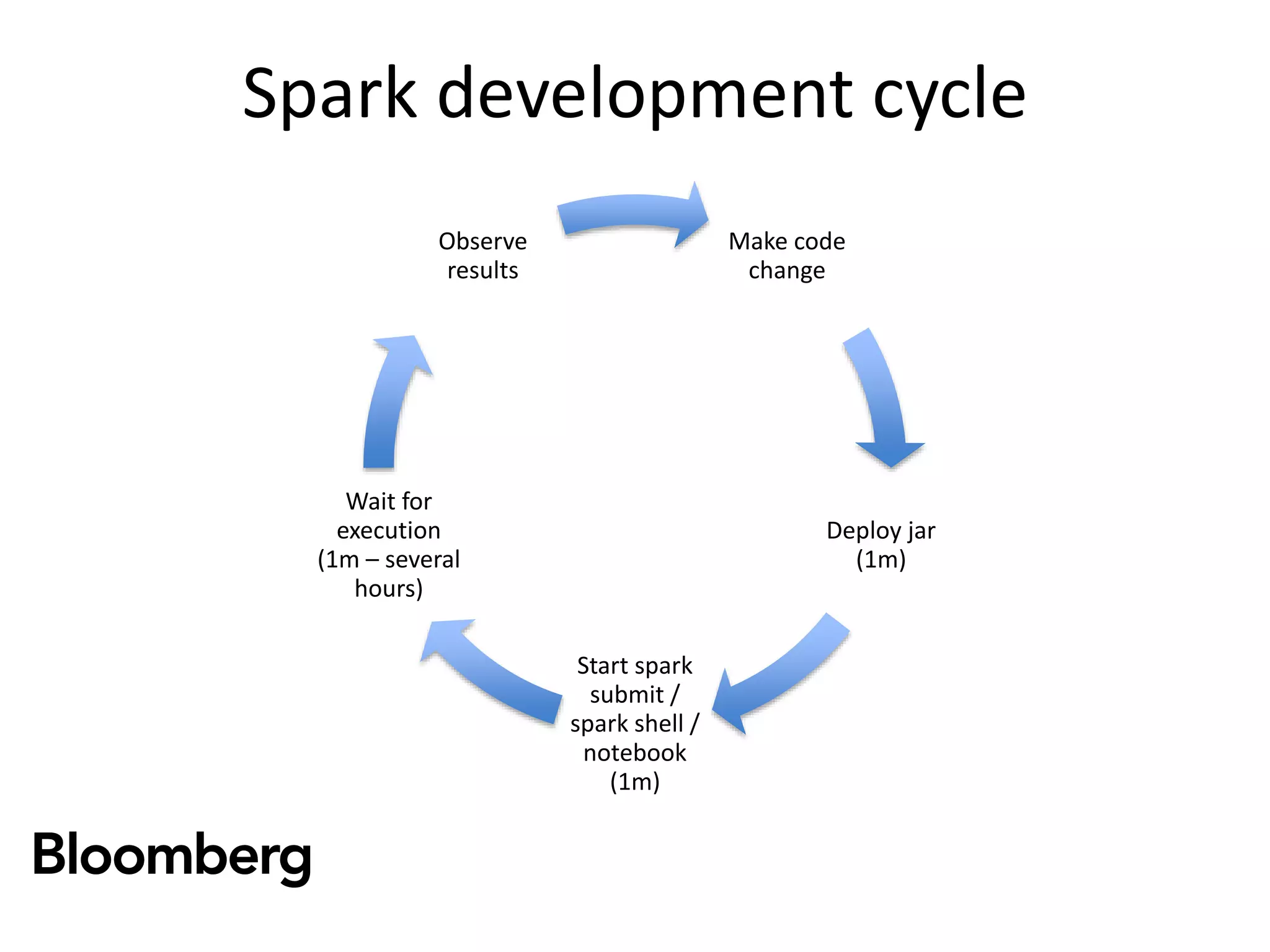
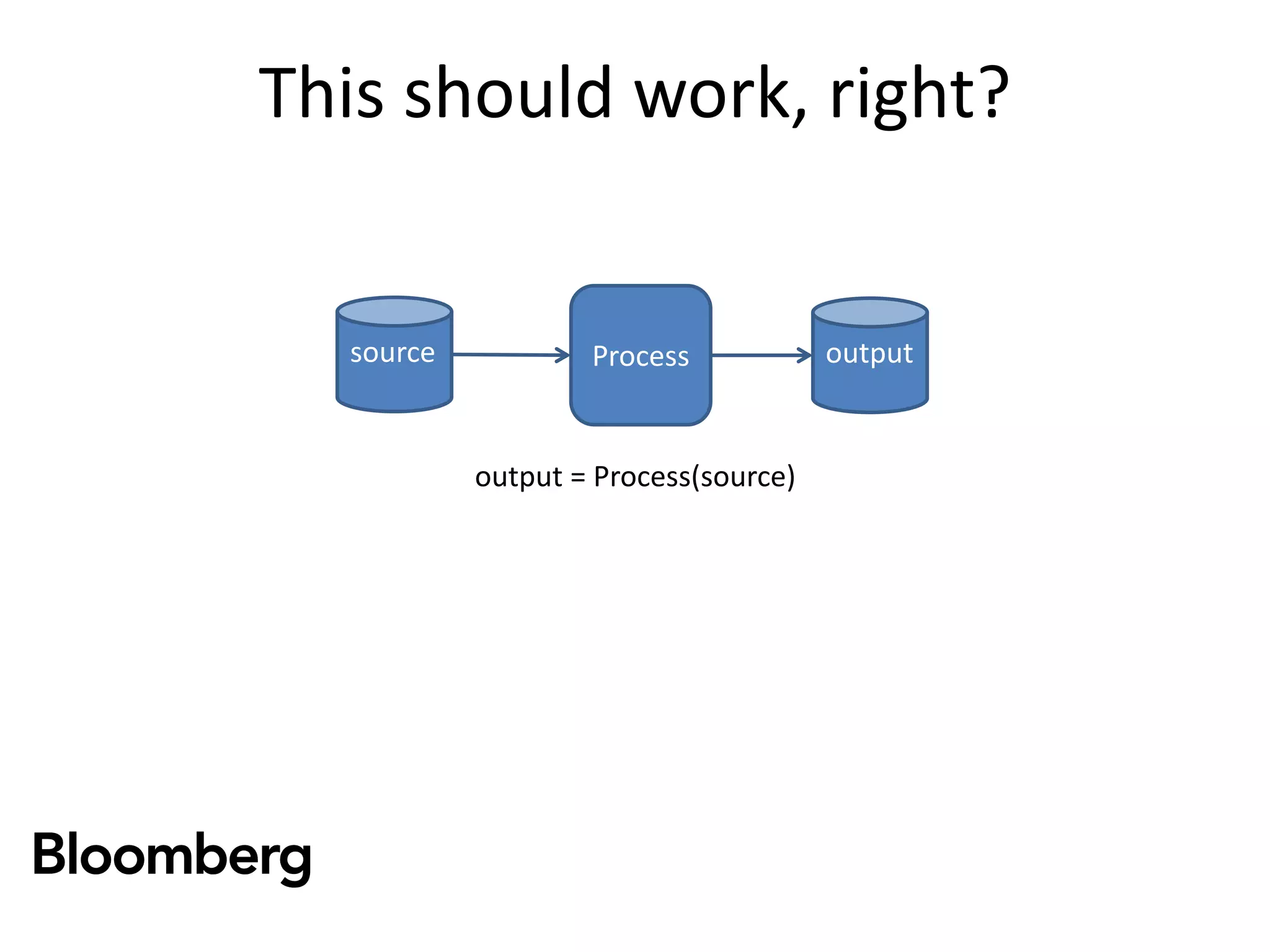
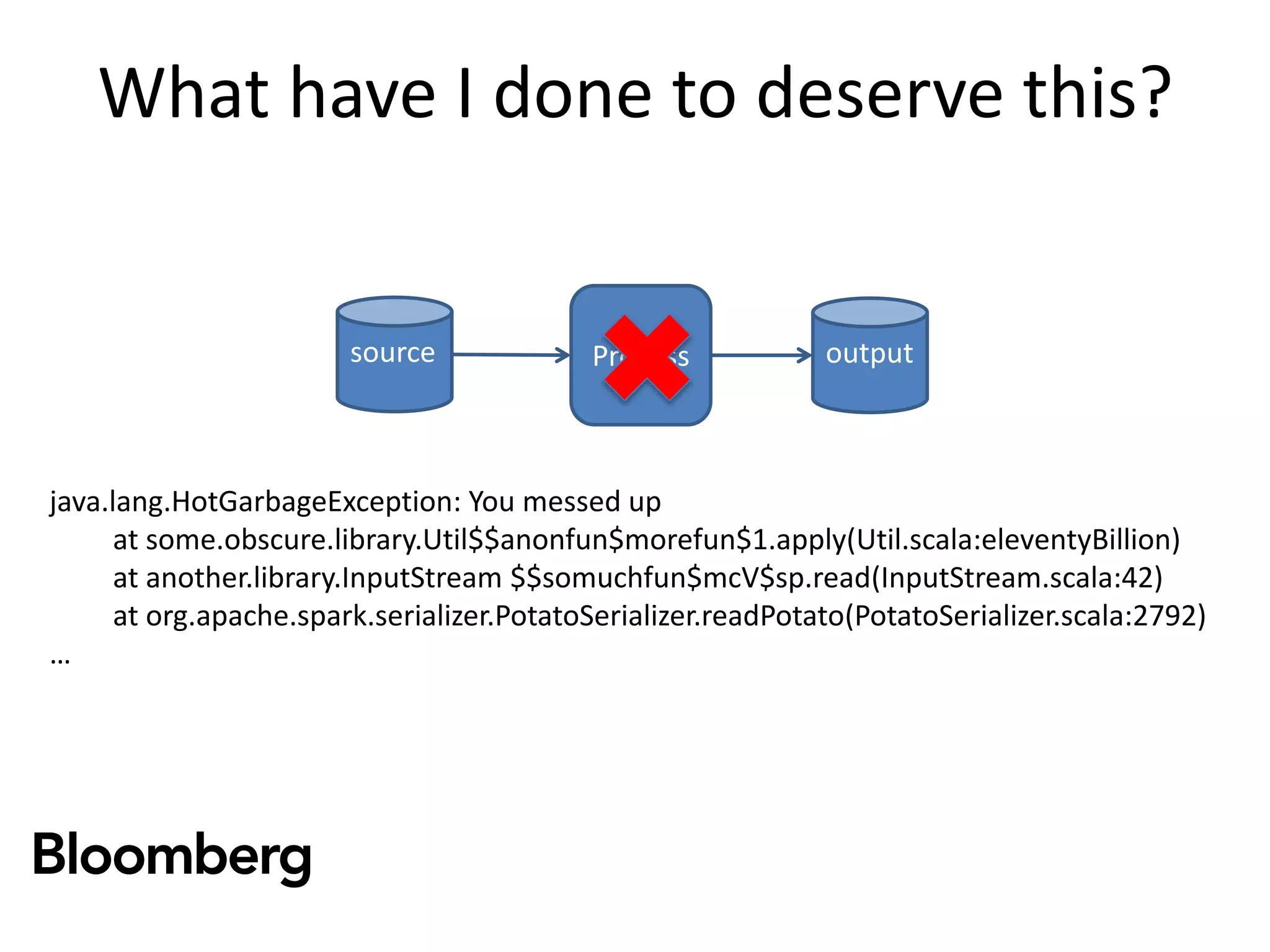
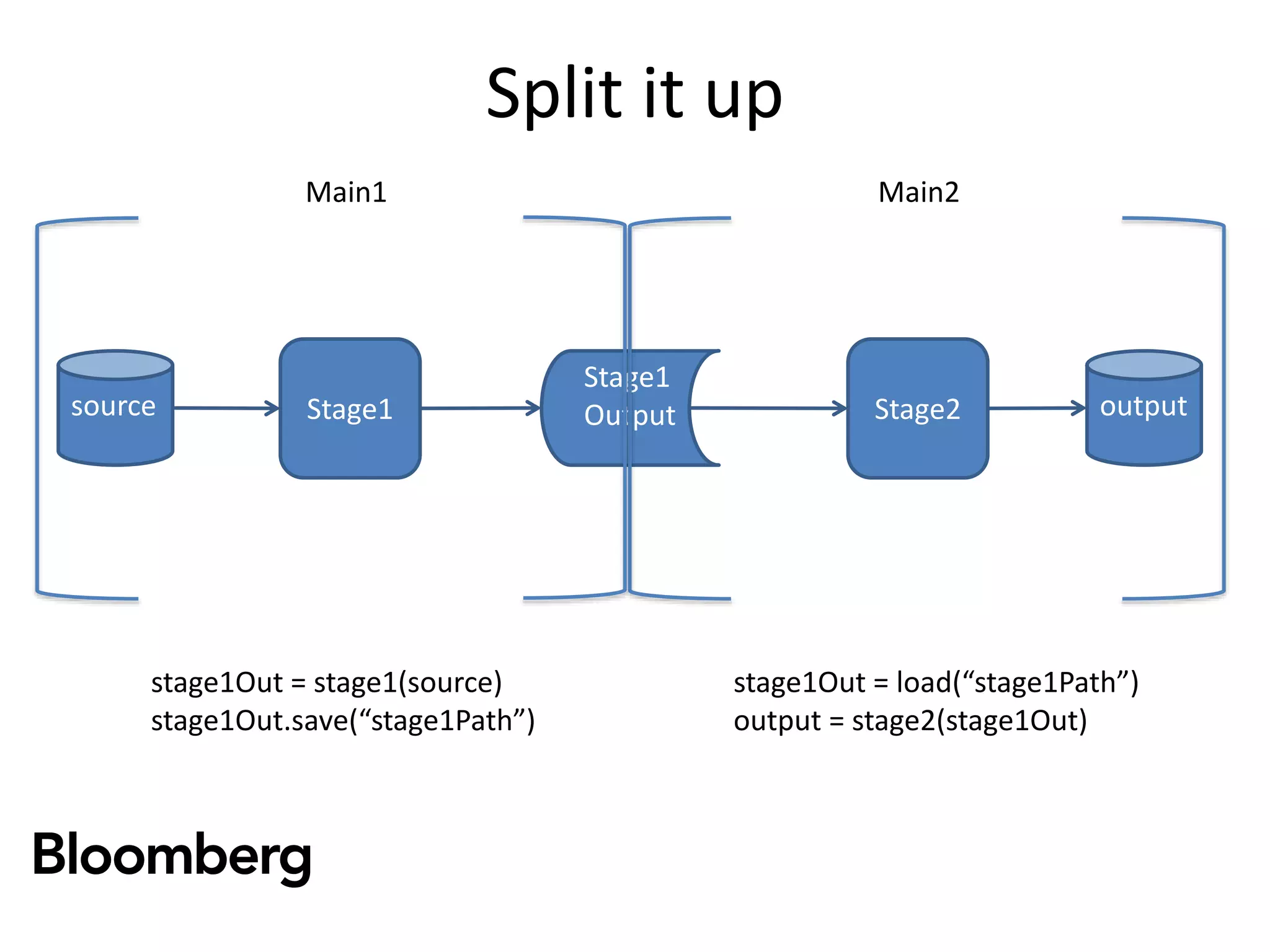
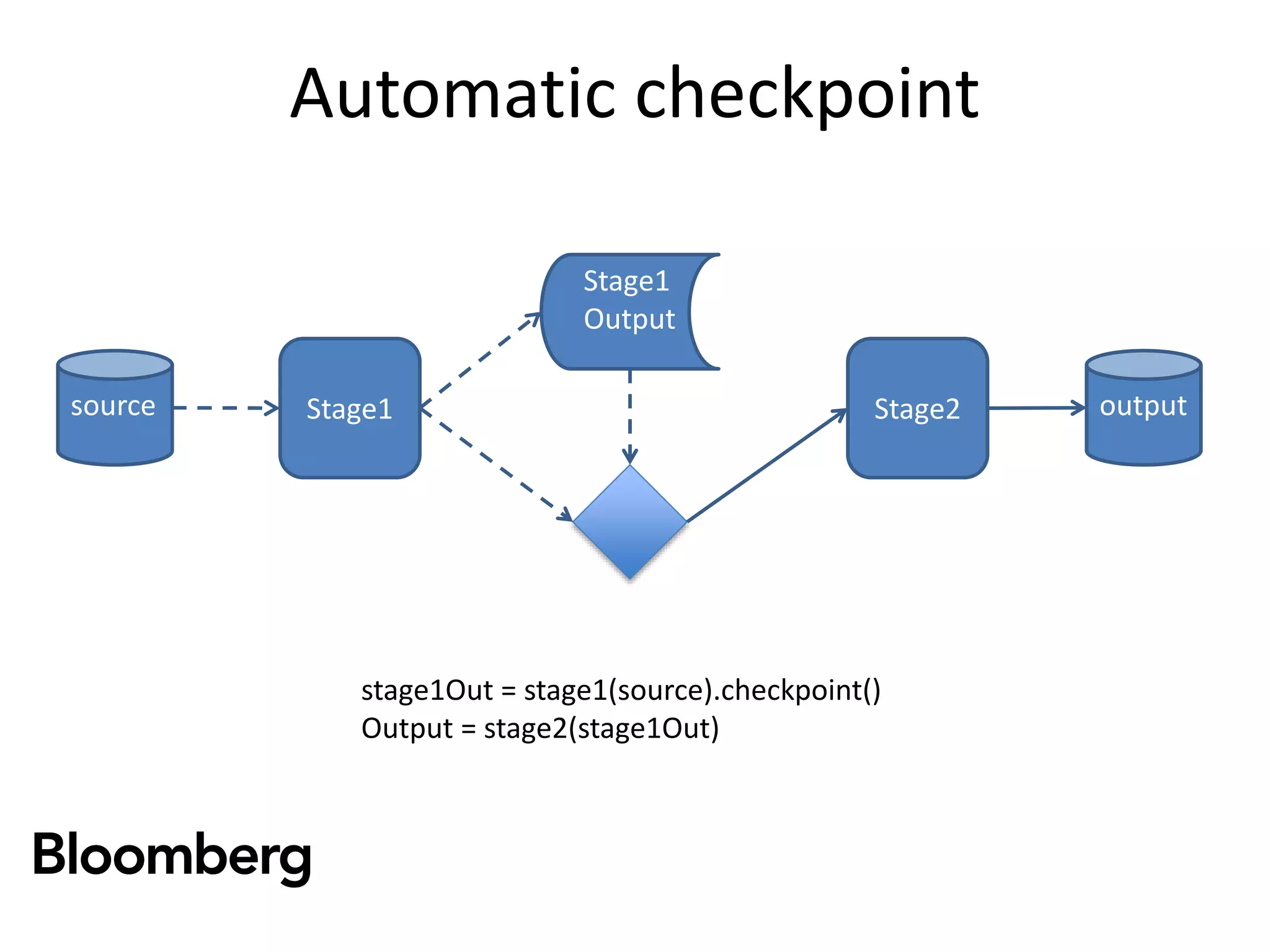
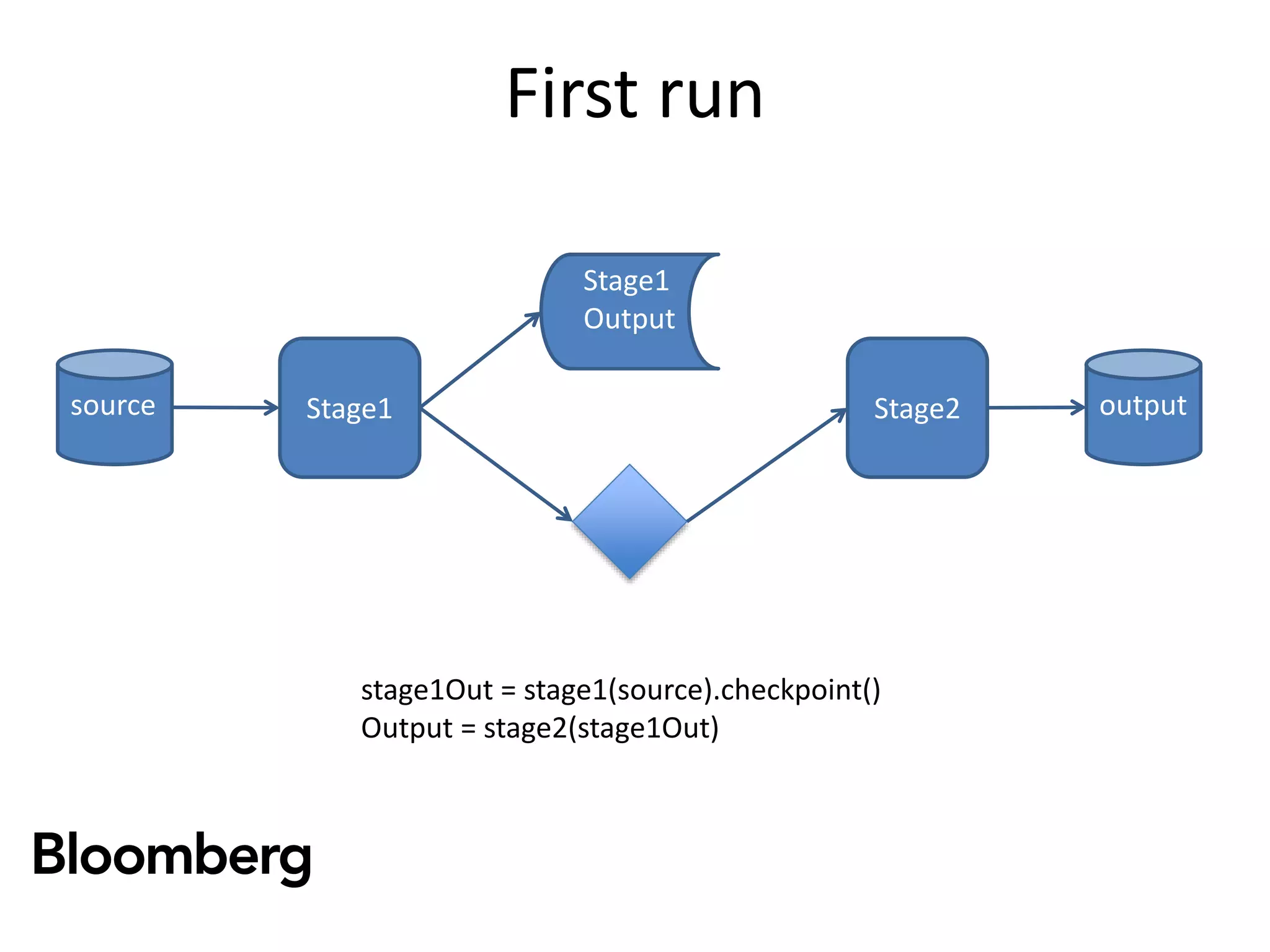
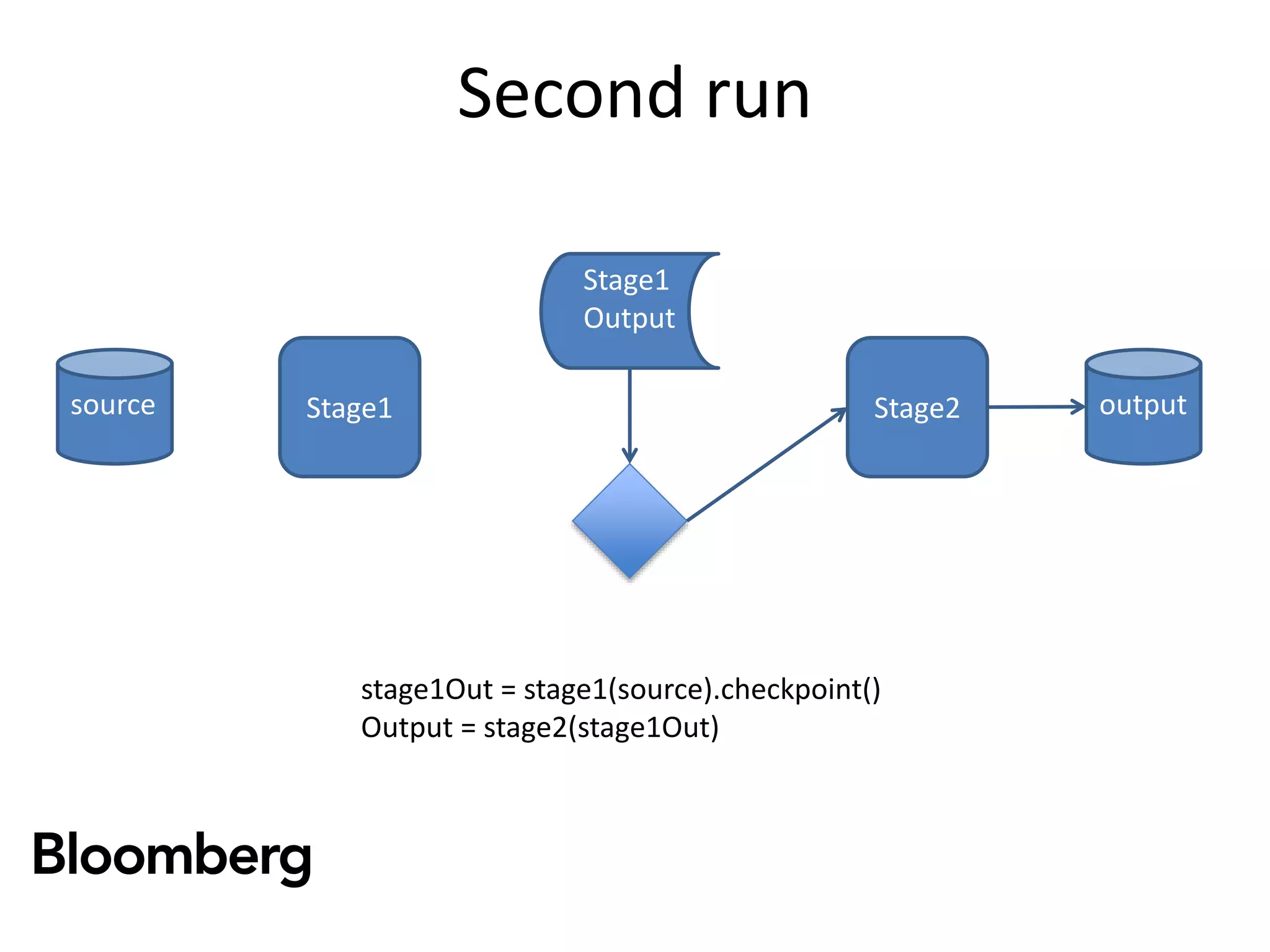
The document discusses iterative Spark development techniques used at Bloomberg, focusing on the optimization of data pipeline processes and the management of Spark job execution. It introduces concepts such as distributed collections (DC) as alternatives to RDDs, methods for automatic checkpointing, and the generation of logical signatures for improved efficiency. The document concludes with an invitation for further discussion and an upcoming open source release.









![[QE 2018] Łukasz Gawron – Testing Batch and Streaming Spark Applications](https://cdn.slidesharecdn.com/ss_thumbnails/gawrontestingbatchandstreamingsparkapplications-180702090002-thumbnail.jpg?width=640&height=640&fit=bounds)
































































































