Downloaded 277 times




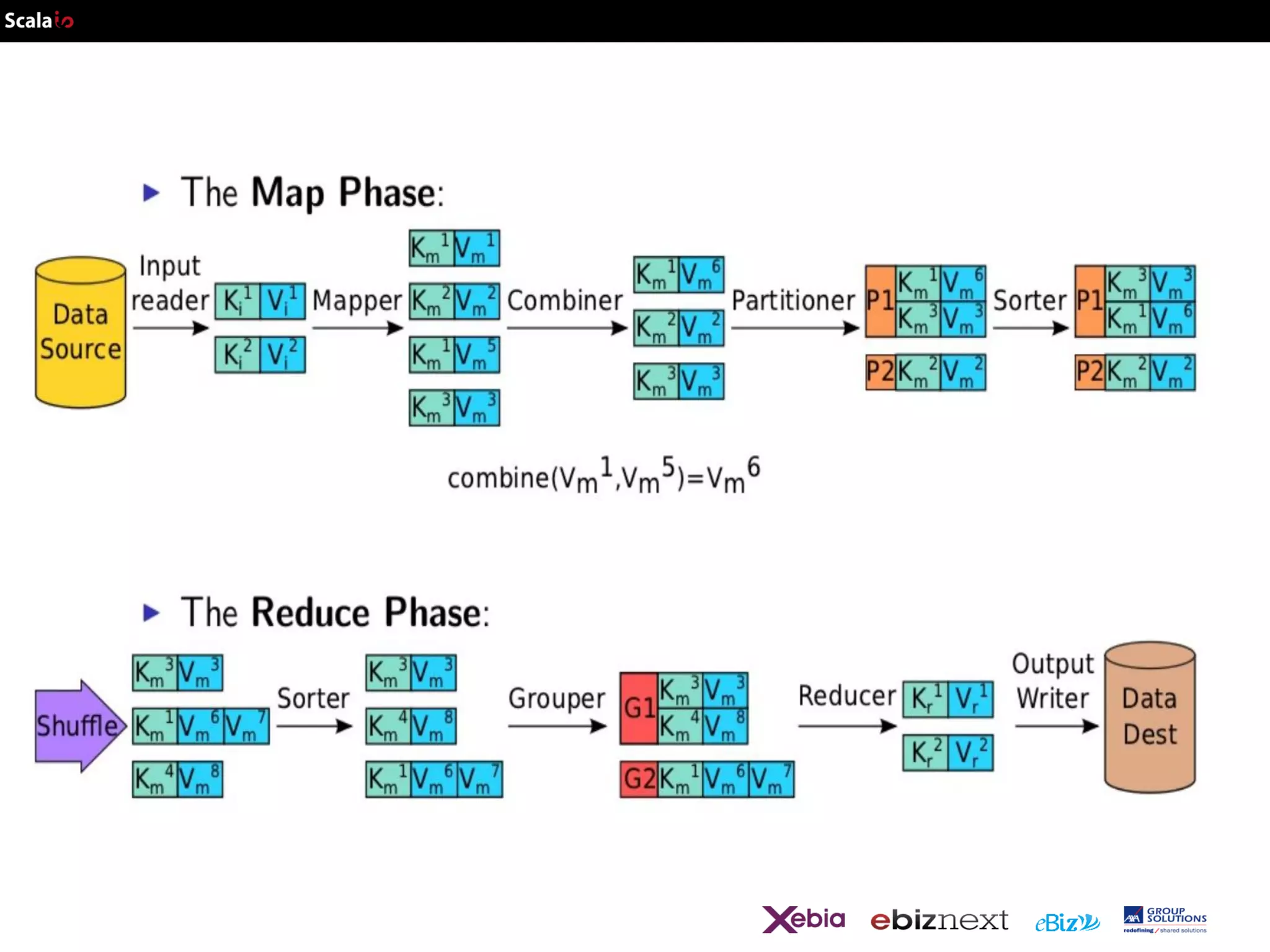
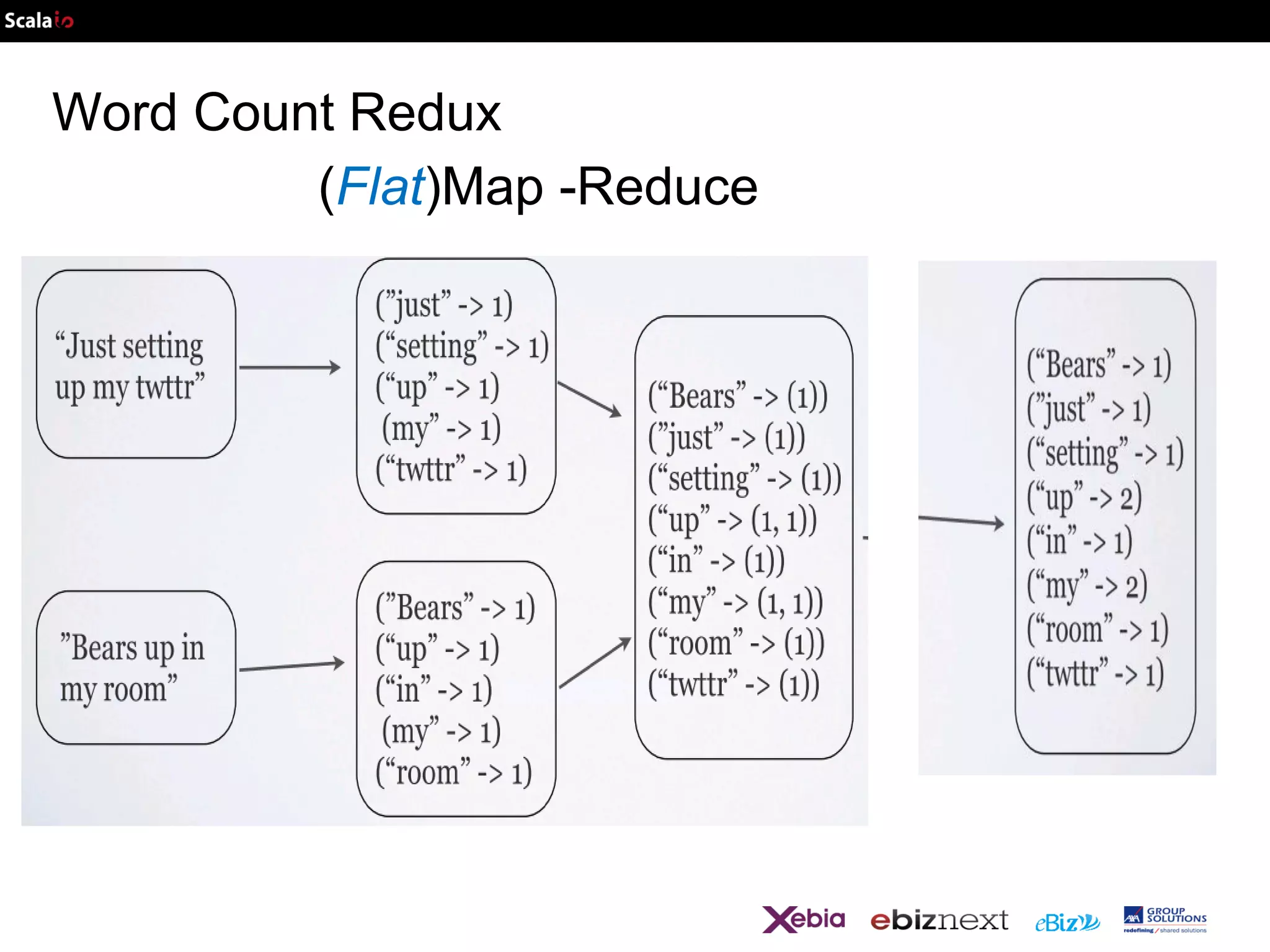
![Map Reduce redux
map : (Km, Vm) List (Km, Vm)
in Scala : T =>
List[(K,V)]
reduce :(Km, List(Vm))List(Kr, Vr)
(K, List[V]) => List[(K,V)]](https://image.slidesharecdn.com/scalaio-biganalytics-131027093540-phpapp02/75/Big-Data-Analytics-with-Scala-at-SCALA-IO-2013-8-2048.jpg)


![SCALDING : Clustering with Mahout
lazy val clust = new StreamingKMeans(new FastProjectionSearch(
new EuclideanDistanceMeasure,5,10),
args("sloppyclusters").toInt, (10e-6).asInstanceOf[Float])
val count = 0;
val sloppyClusters =
TextLine(args("input"))
.map{ str =>
val vec = str.split("t").map(_.toDouble)
val cent = new Centroid(count, new
DenseVector(vec))
count += 1
cent }
.unorderedFold [StreamingKMeans,Centroid](clust)
{(cl,cent) => cl.cluster(cent);
cl }
.flatMap(c => c.iterator.asScala.toIterable)](https://image.slidesharecdn.com/scalaio-biganalytics-131027093540-phpapp02/75/Big-Data-Analytics-with-Scala-at-SCALA-IO-2013-15-2048.jpg)

![Scalding
- Two APIs : Field based API, and Typed API
- Field API : project, map, discard , groupBy…
- Typed API : TypedPipe[T], works like
scala.collection.Iterator[T]
- Matrix Library
- ALGEBIRD : Abstract Algebra library … we’ll
talk about it later](https://image.slidesharecdn.com/scalaio-biganalytics-131027093540-phpapp02/75/Big-Data-Analytics-with-Scala-at-SCALA-IO-2013-17-2048.jpg)
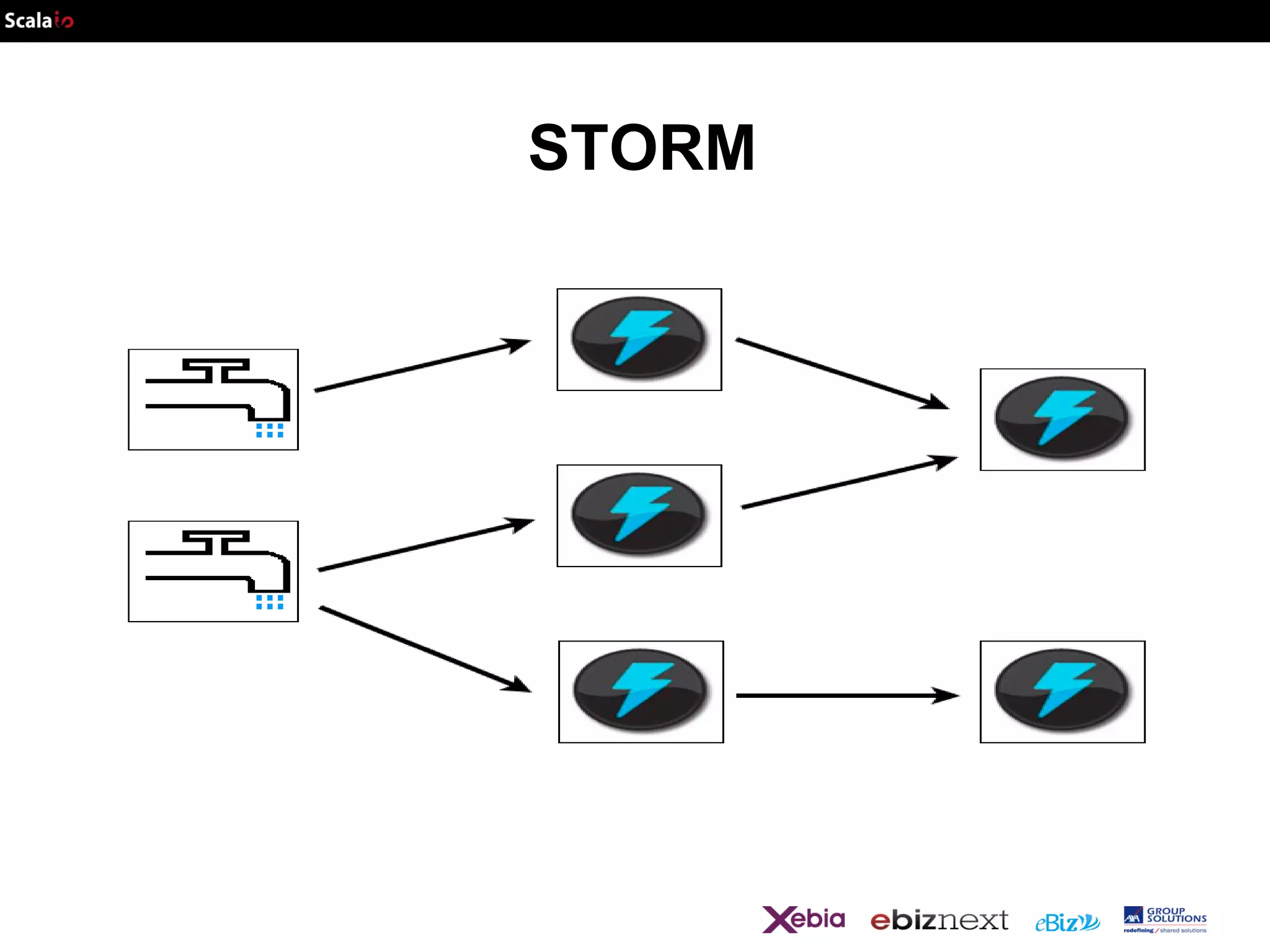

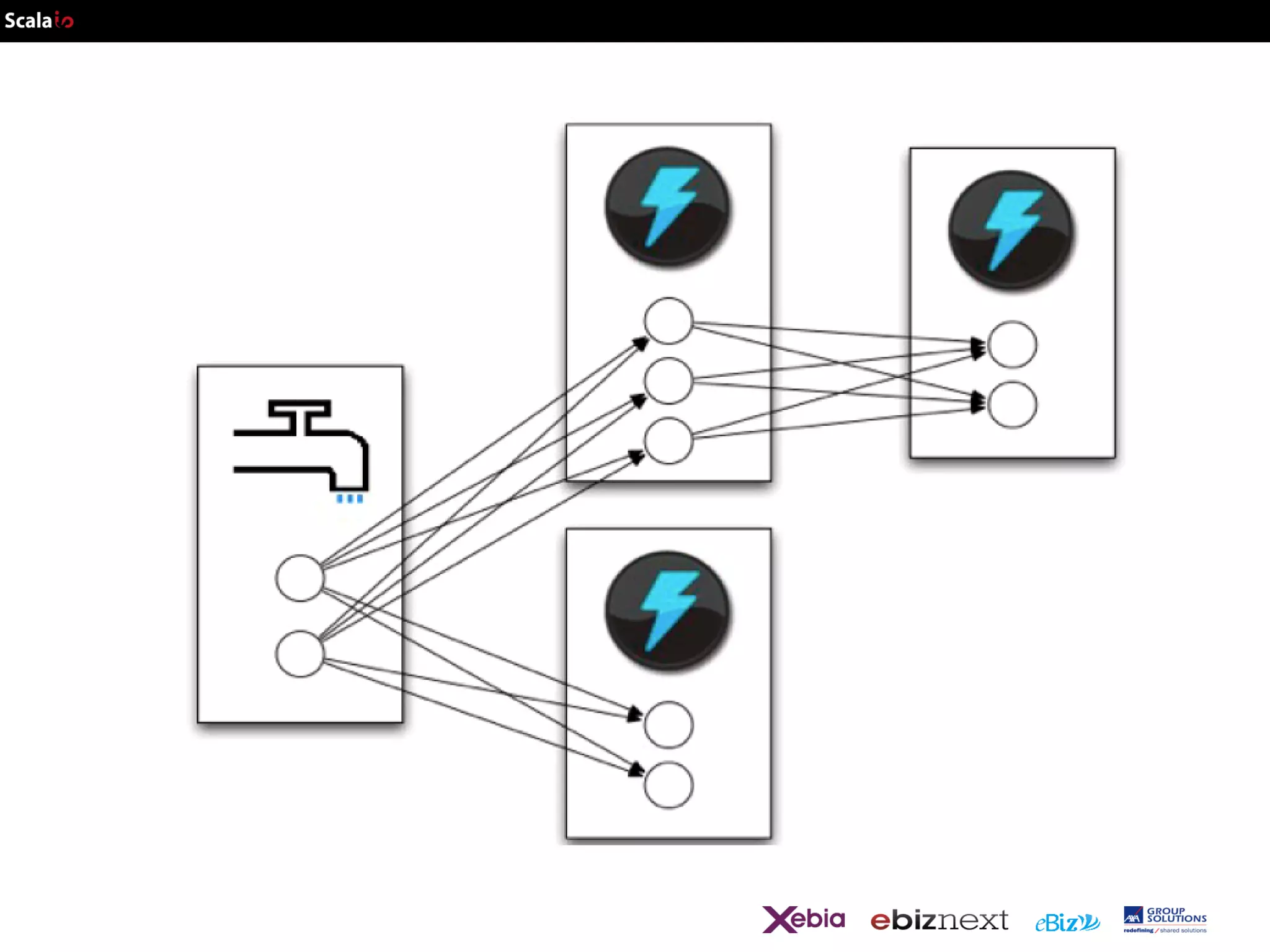
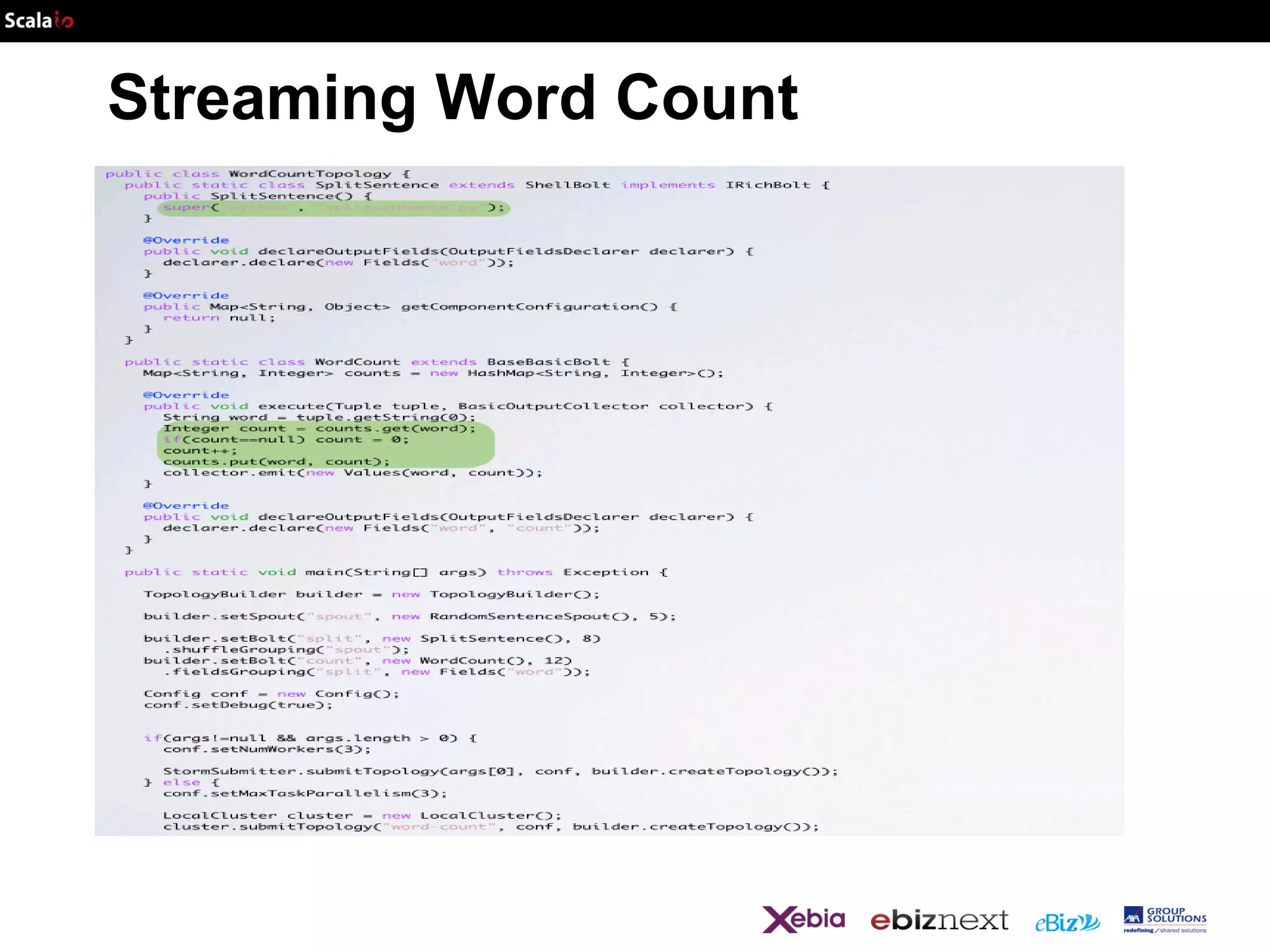



![def wordCount[P <: Platform[P]]
(source: Producer[P, String], store: P#Store[String, Long]) =
source.flatMap {
line => line.split(‘’s+’’).map(_ -> 1L) }
.sumByKey(store)](https://image.slidesharecdn.com/scalaio-biganalytics-131027093540-phpapp02/75/Big-Data-Analytics-with-Scala-at-SCALA-IO-2013-27-2048.jpg)
![SummingBird
trait Platform[P <: Platform[P]]
{
type Source[+T]
type Store[-K, V]
type Sink[-T]
type Service[-K, +V]
type Plan[T}
}](https://image.slidesharecdn.com/scalaio-biganalytics-131027093540-phpapp02/75/Big-Data-Analytics-with-Scala-at-SCALA-IO-2013-28-2048.jpg)
![On Storm
- Source[+T] : Spout[(Long, T)]
- Store[-K, V] : StormStore [K, V]
- Sink[-T] : (T => Future[Unit])
- Service[-K, +V] : StormService[K,V]
- Plan[T] : StormTopology](https://image.slidesharecdn.com/scalaio-biganalytics-131027093540-phpapp02/75/Big-Data-Analytics-with-Scala-at-SCALA-IO-2013-29-2048.jpg)
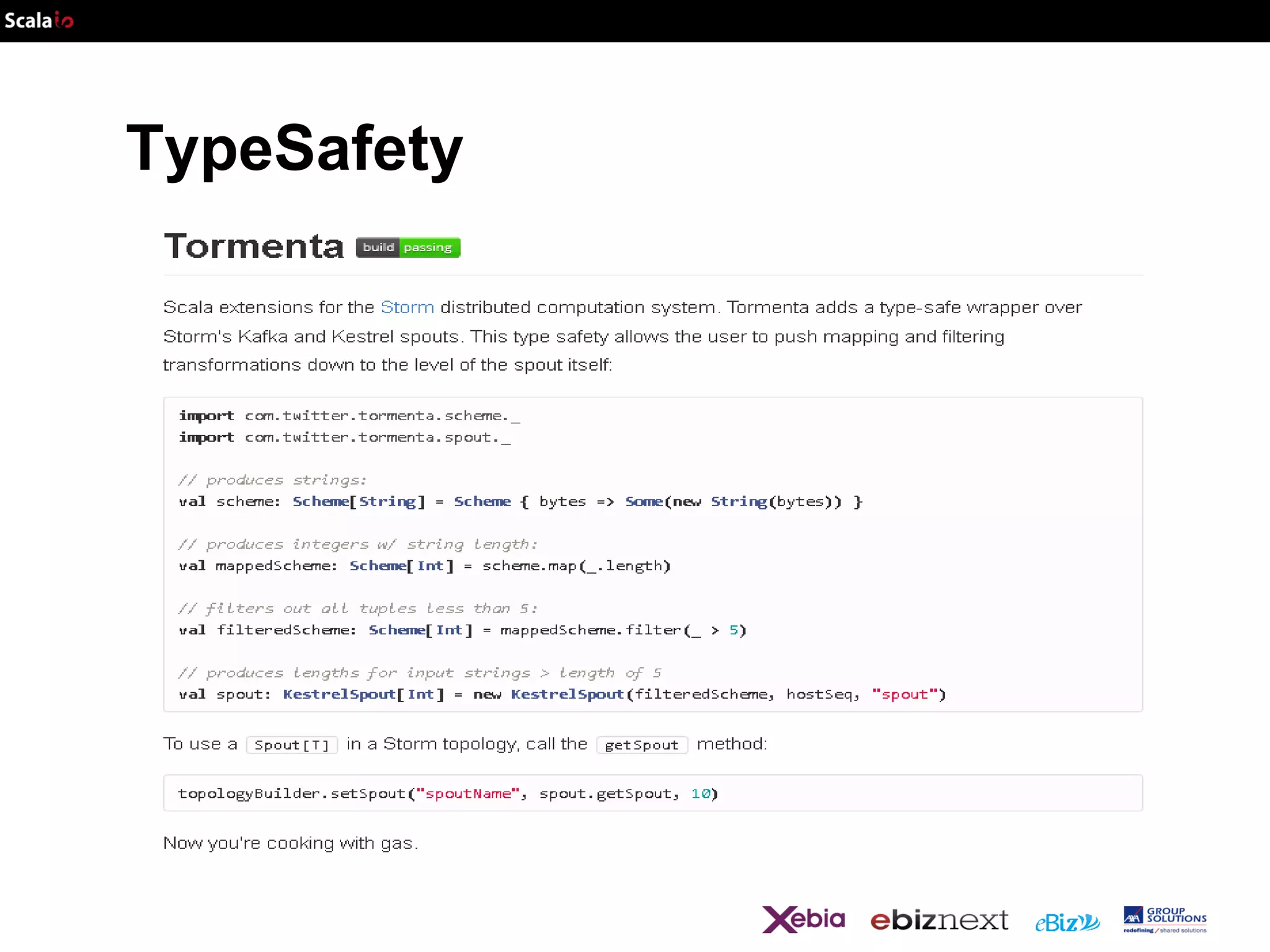

![But
- Can only aggregate values that are
associative : Monoids!!!!!!
trait Monoid [V] {
def zero : V
def aggregate(left : V, right :V): V
}](https://image.slidesharecdn.com/scalaio-biganalytics-131027093540-phpapp02/75/Big-Data-Analytics-with-Scala-at-SCALA-IO-2013-32-2048.jpg)
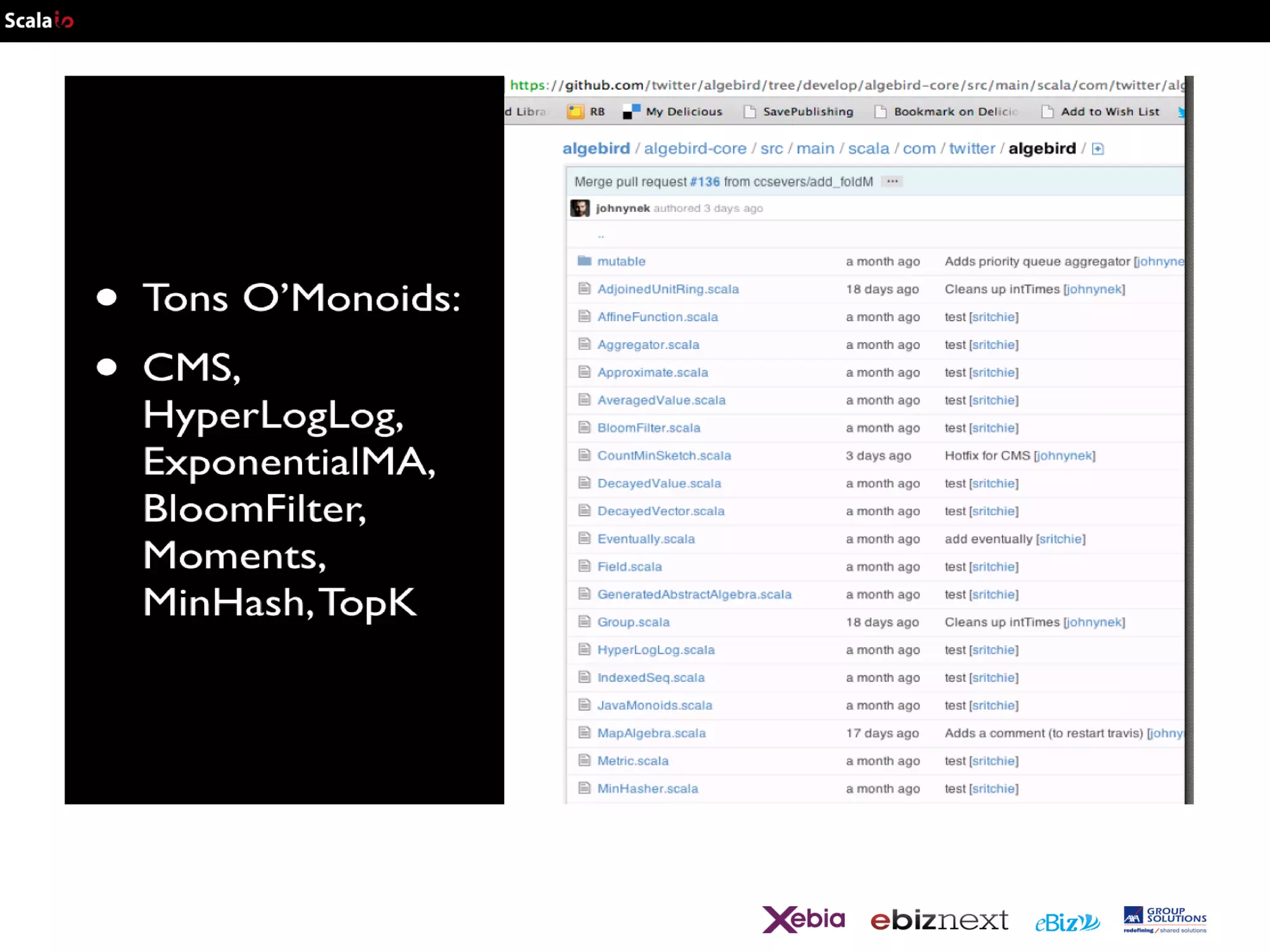
![Clustering with Mahout redux
def StreamClustering(source : Platform[P.String], store : P#Store[_,_]) {
lazy val clust = new StreamingKMeans(new FastProjectionSearch(
new EuclideanDistanceMeasure,5,10),
args("sloppyclusters").toInt, (10e-6).asInstanceOf[Float])
val count = 0;
val sloppyClusters =
source
.map{ str =>
val vec = str.split("t").map(_.toDouble)
val cent = new Centroid(count, new
DenseVector(vec))
count += 1
cent }
.unorderedFold [StreamingKMeans,Centroid](clust)
{(cl,cent) => cl.cluster(cent); cl }
.flatMap(c => c.iterator.asScala.toIterable)](https://image.slidesharecdn.com/scalaio-biganalytics-131027093540-phpapp02/75/Big-Data-Analytics-with-Scala-at-SCALA-IO-2013-34-2048.jpg)






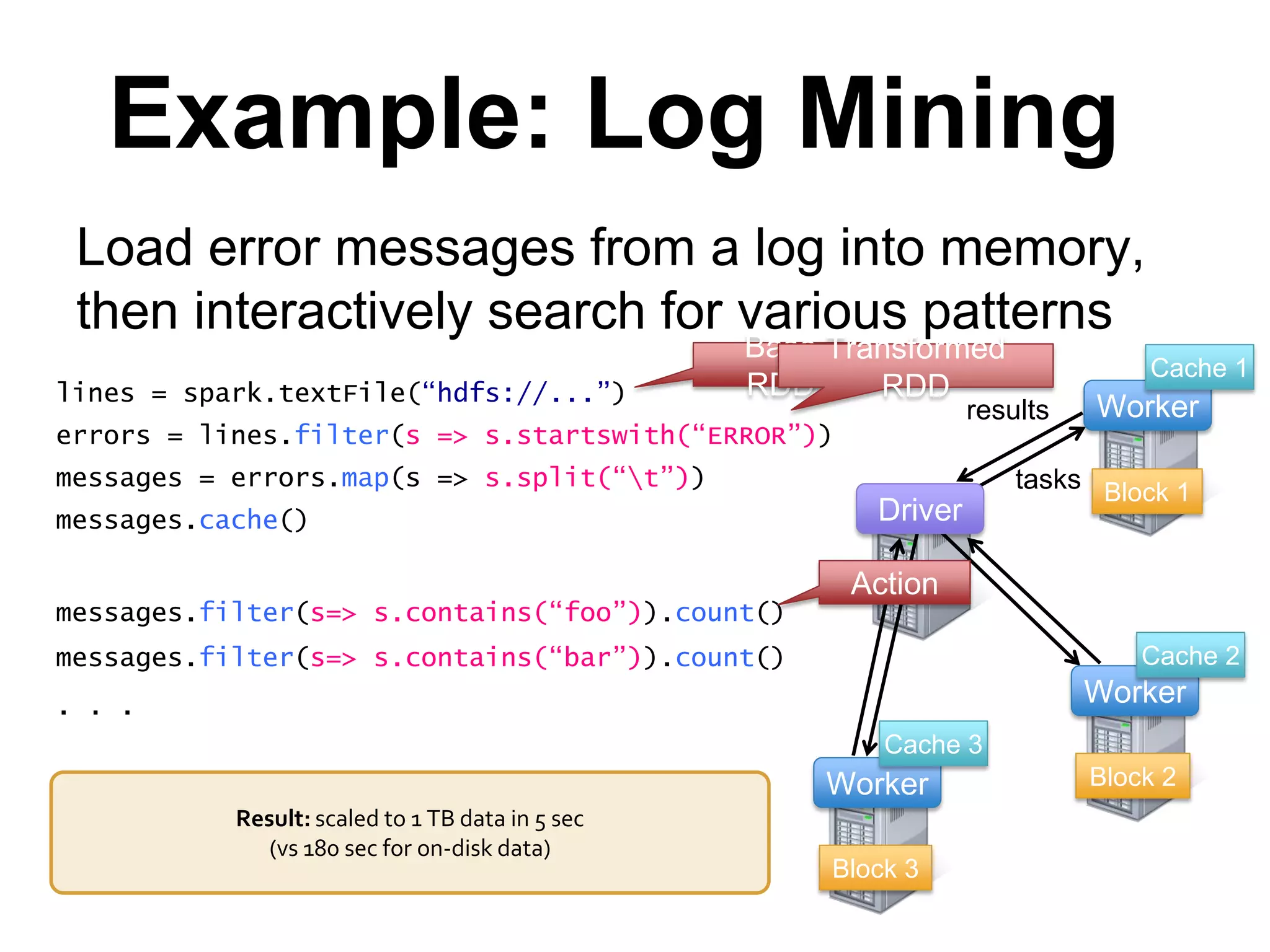

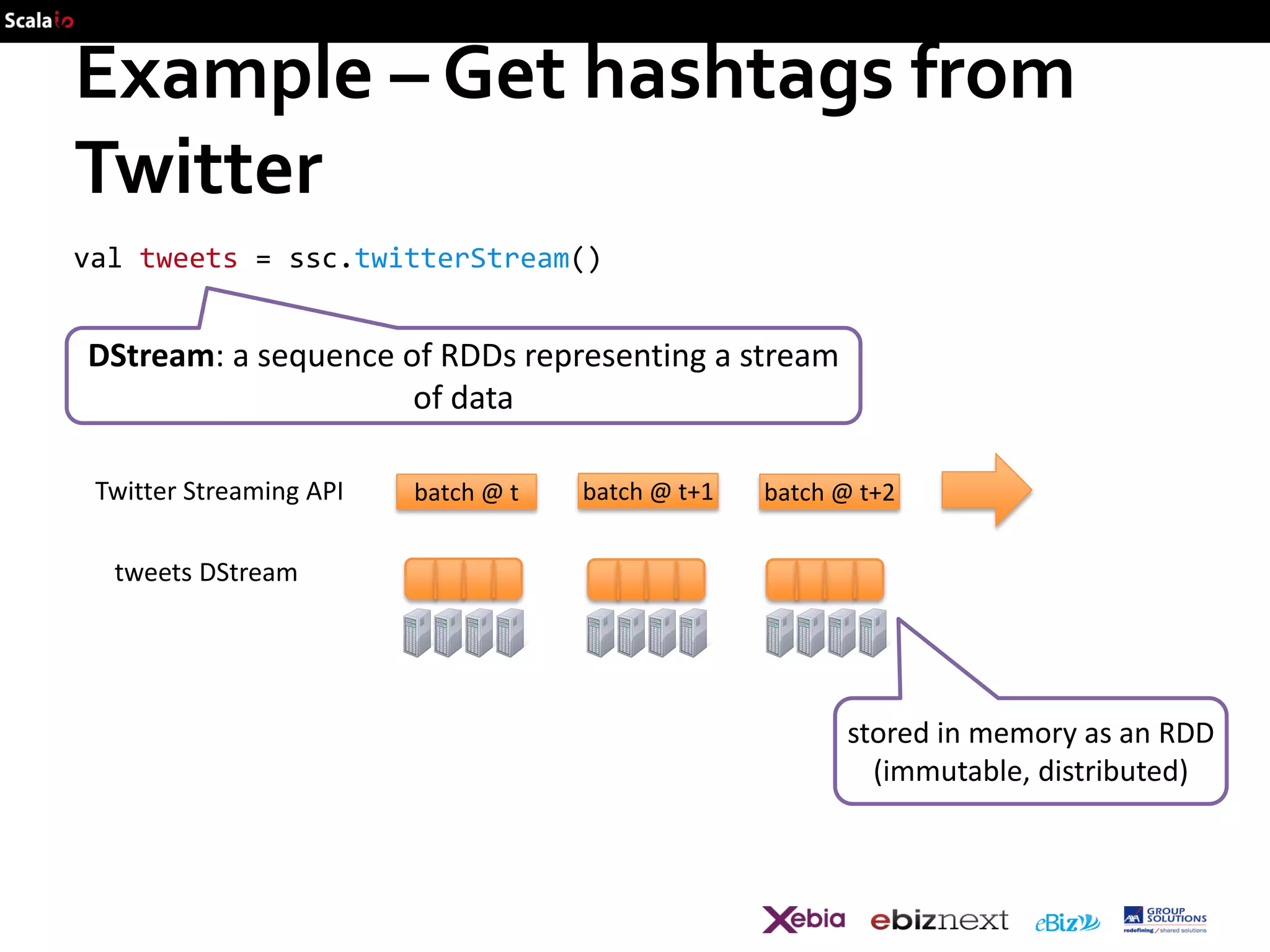
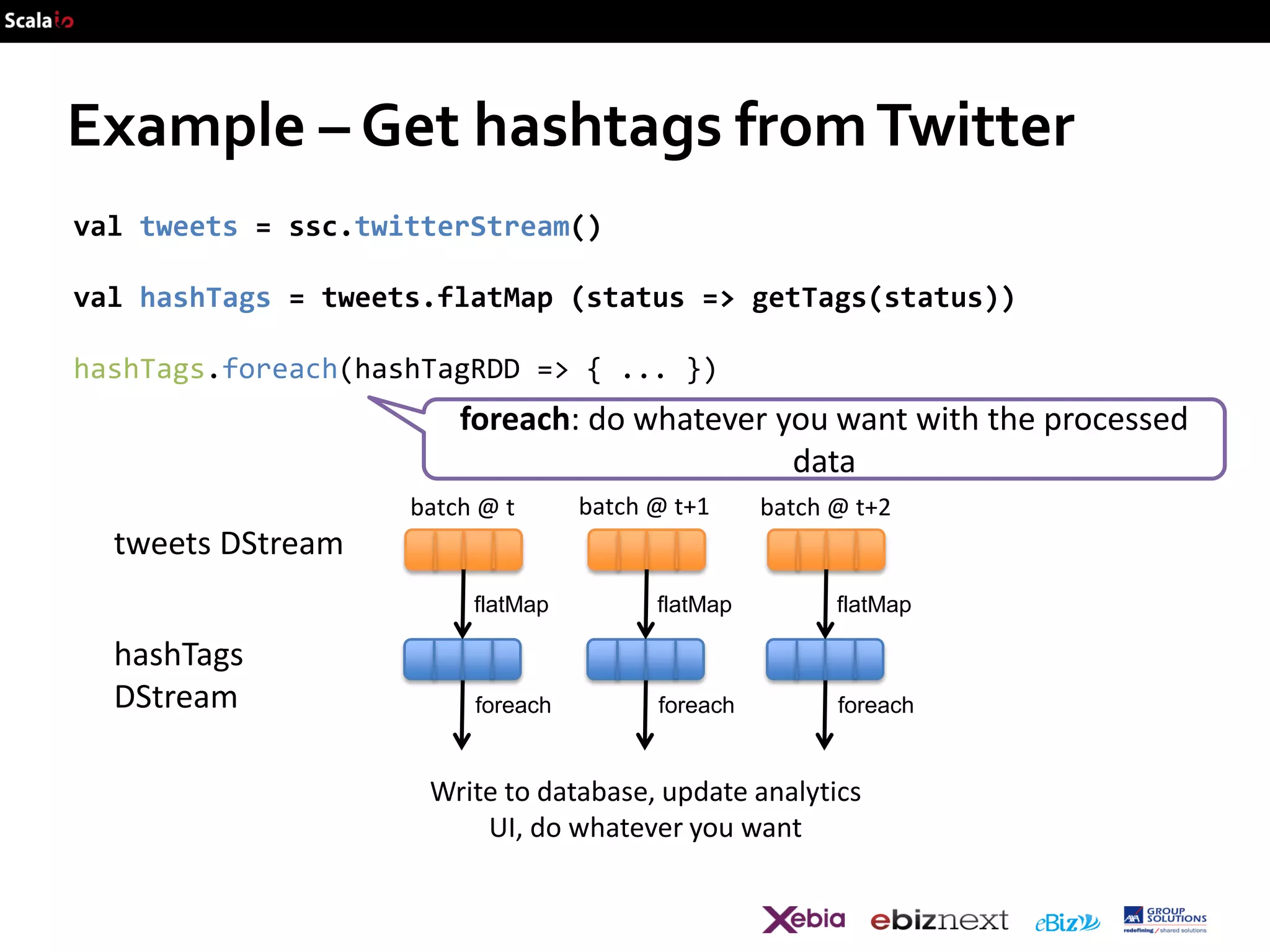
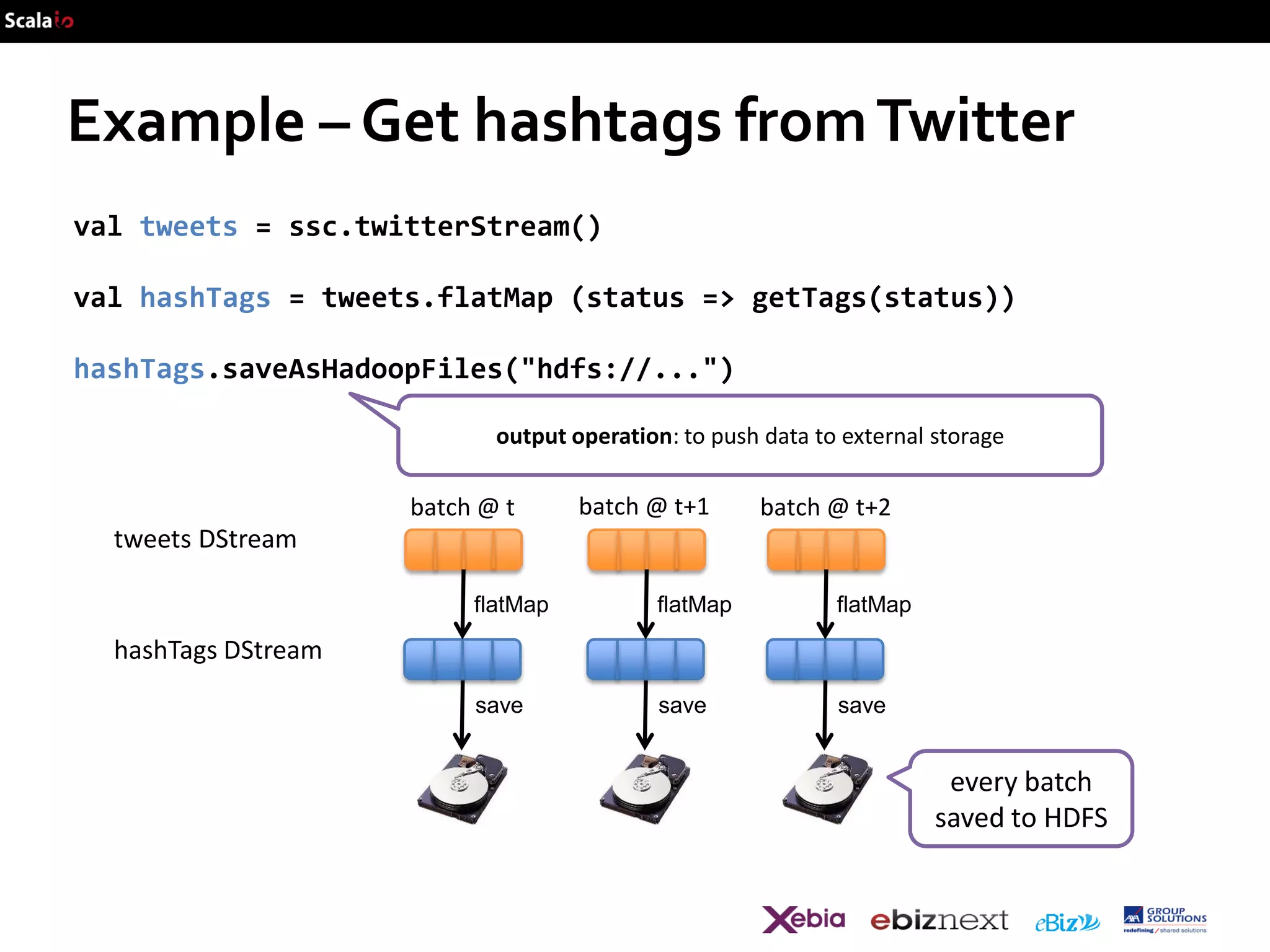
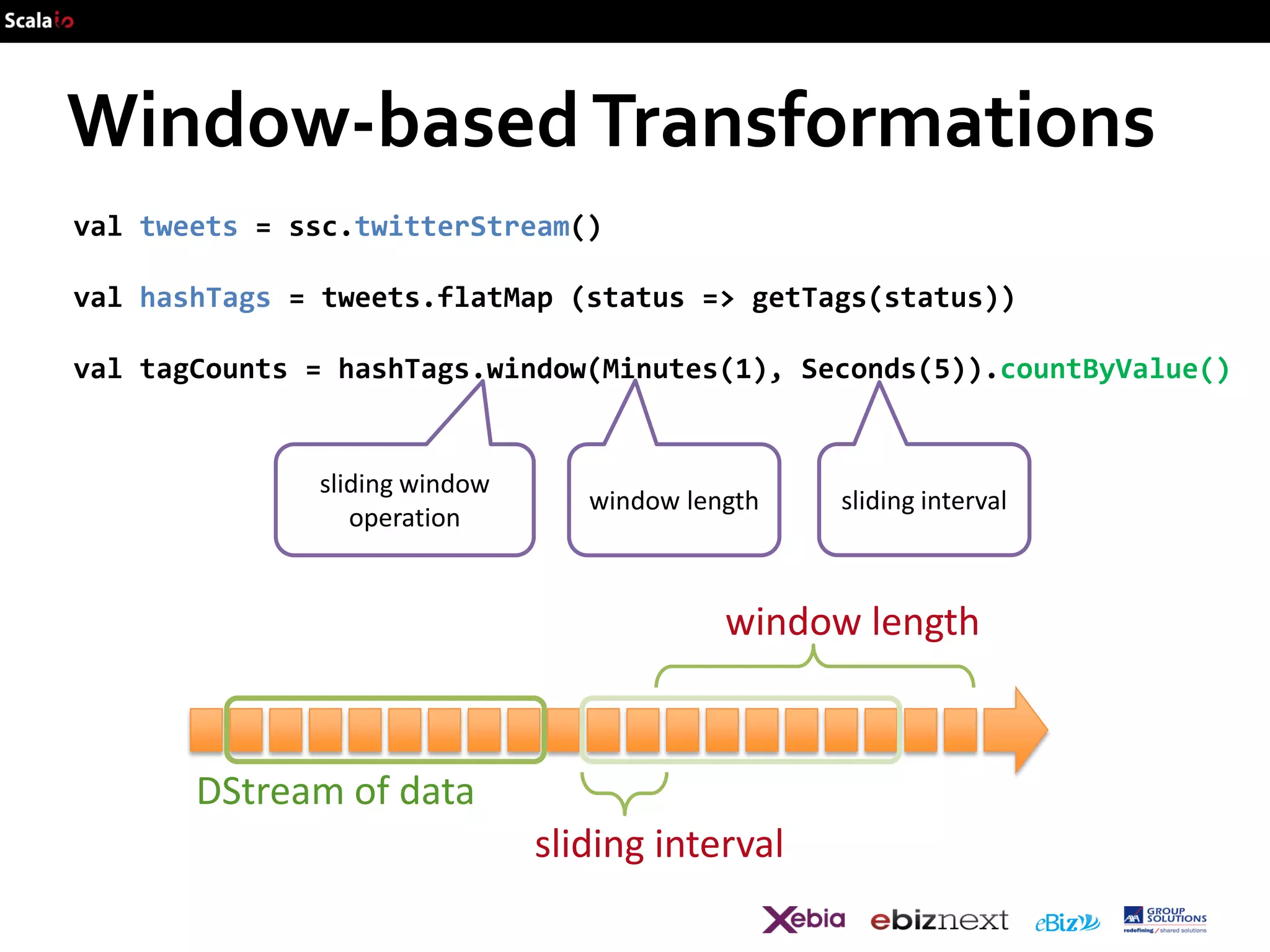
![Example – Get hashtags from Twitter
val tweets = ssc.twitterStream()
val hashTags = tweets.flatMap (status => getTags(status))
new DStream
transformation: modify data in one DStream to create another
DStream
batch @ t
batch @ t+1
batch @ t+2
tweets DStream
hashTags Dstream
[#cat, #dog, … ]
flatMap
flatMap
…
flatMap
new RDDs created
for every batch](https://image.slidesharecdn.com/scalaio-biganalytics-131027093540-phpapp02/75/Big-Data-Analytics-with-Scala-at-SCALA-IO-2013-47-2048.jpg)
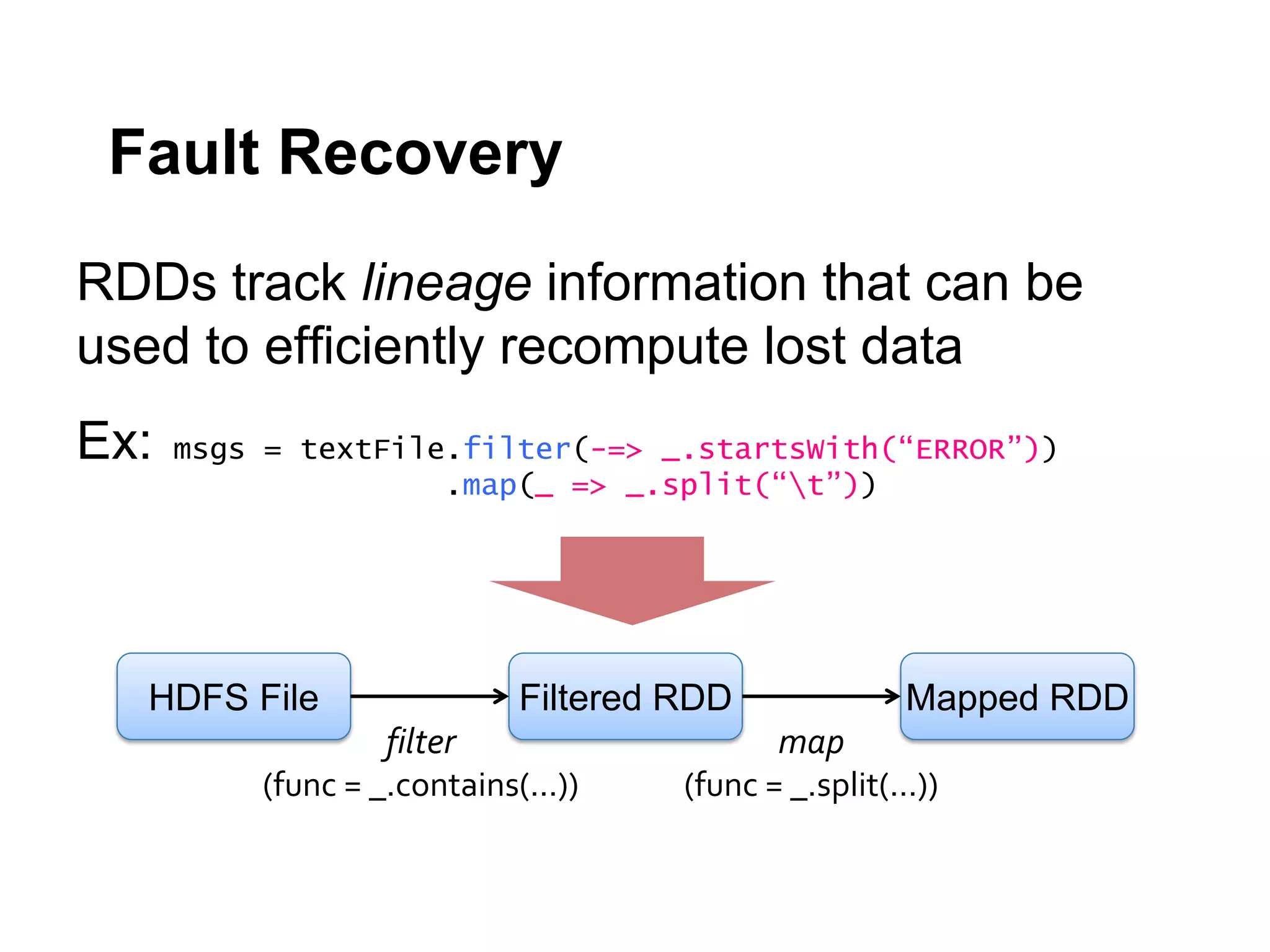
![Compute TopK Ip addresses
val ssc = new StreamingContext(master, "AlgebirdCMS", Seconds(10), …)
val stream = ssc.KafkaStream(None, filters, StorageLevel.MEMORY, ..)
val addresses = stream.map(ipAddress => ipAddress.getText)
val cms = new CountMinSketchMonoid(EPS, DELTA, SEED, PERC)
val globalCMS = cms.zero
val mm = new MapMonoid[Long, Int]()
//init
val topAddresses = adresses.mapPartitions(ids => {
ids.map(id => cms.create(id))
})
.reduce(_ ++ _)](https://image.slidesharecdn.com/scalaio-biganalytics-131027093540-phpapp02/75/Big-Data-Analytics-with-Scala-at-SCALA-IO-2013-51-2048.jpg)
![topAddresses.foreach(rdd => {
if (rdd.count() != 0) {
val partial = rdd.first()
val partialTopK = partial.heavyHitters.map(id =>
(id, partial.frequency(id).estimate))
.toSeq.sortBy(_._2).reverse.slice(0, TOPK)
globalCMS ++= partial
val globalTopK = globalCMS.heavyHitters.map(id =>
(id, globalCMS.frequency(id).estimate))
.toSeq.sortBy(_._2).reverse.slice(0, TOPK)
globalTopK.mkString("[", ",", "]")))
}
})](https://image.slidesharecdn.com/scalaio-biganalytics-131027093540-phpapp02/75/Big-Data-Analytics-with-Scala-at-SCALA-IO-2013-52-2048.jpg)
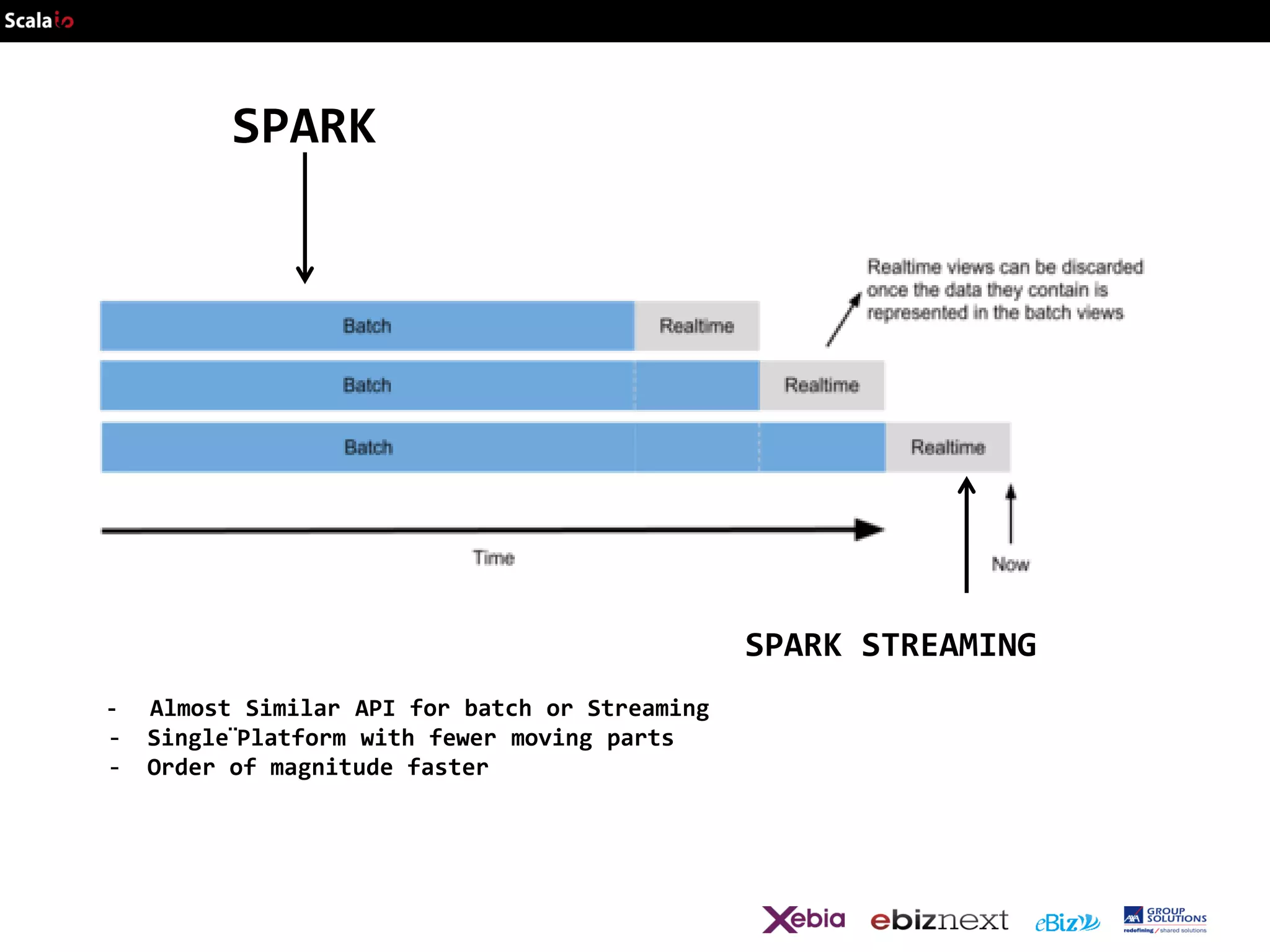



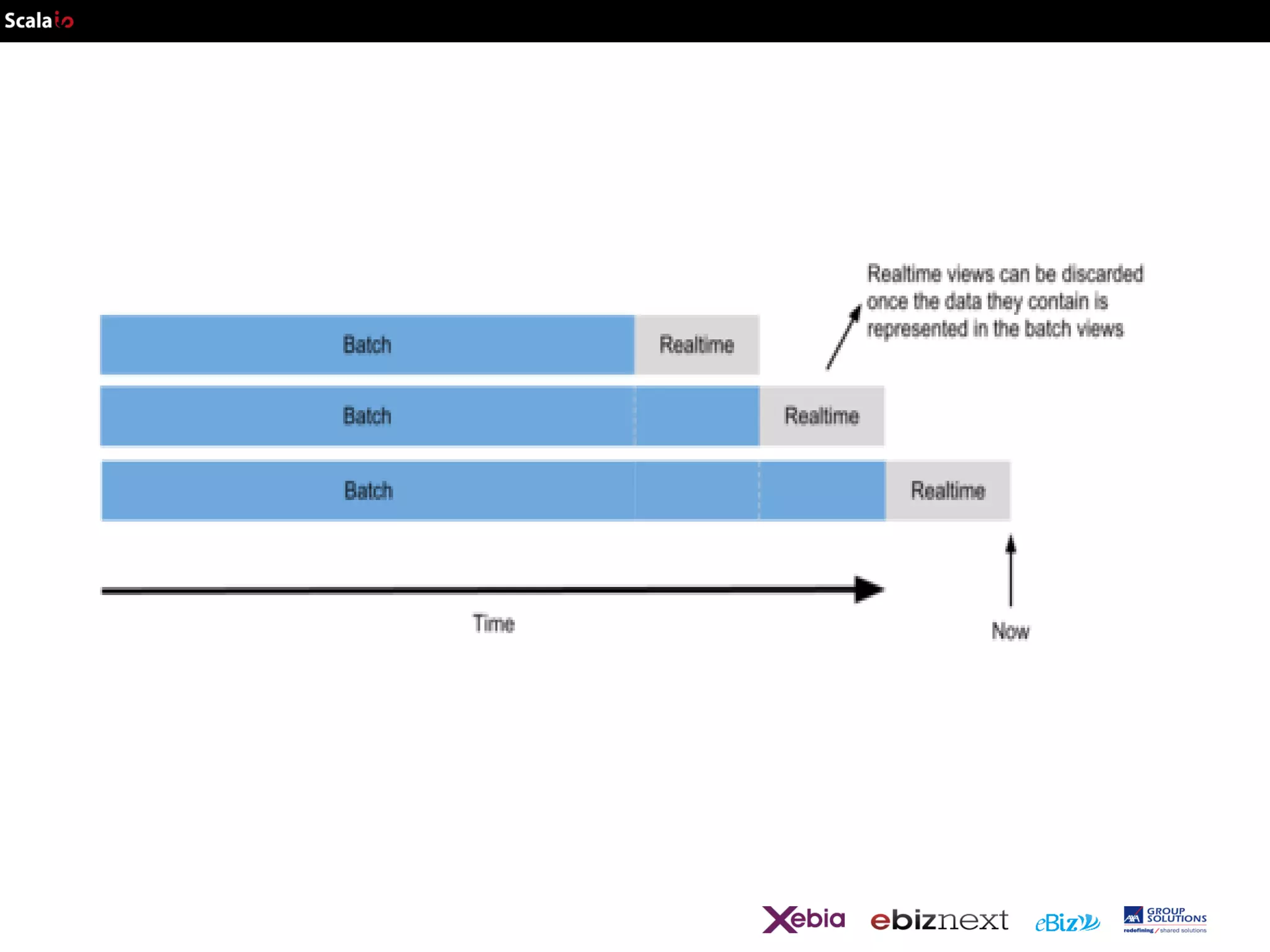
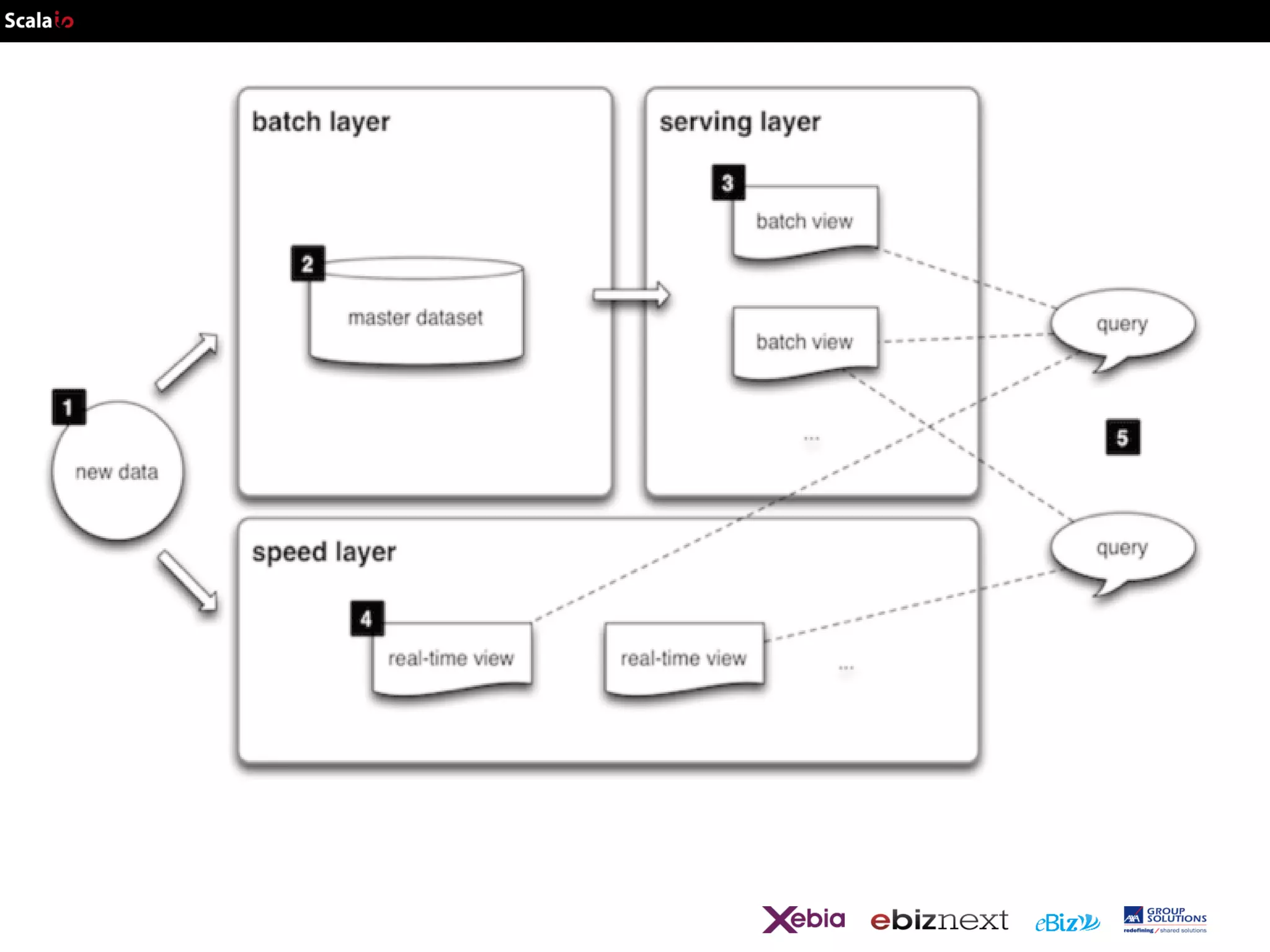
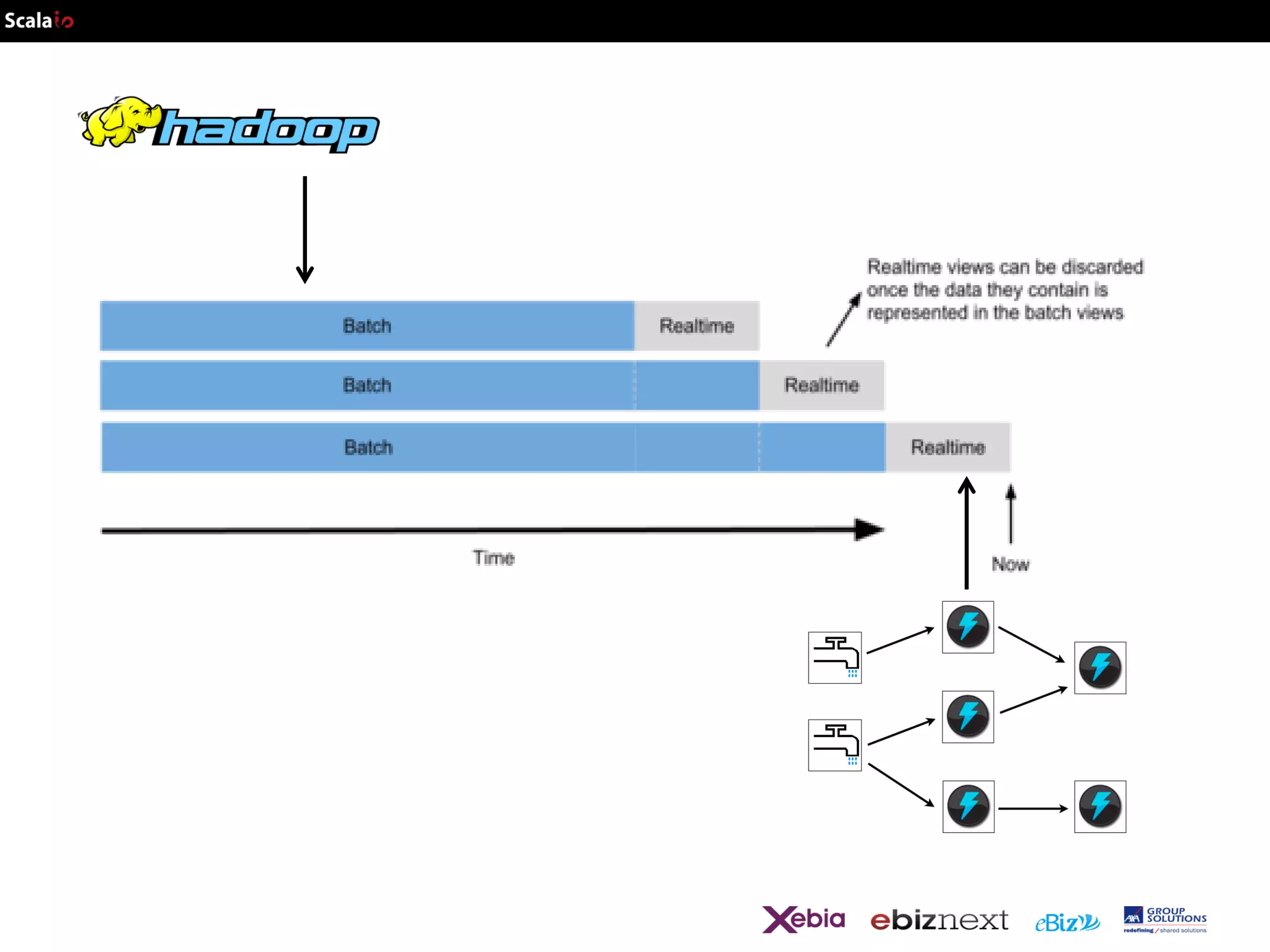
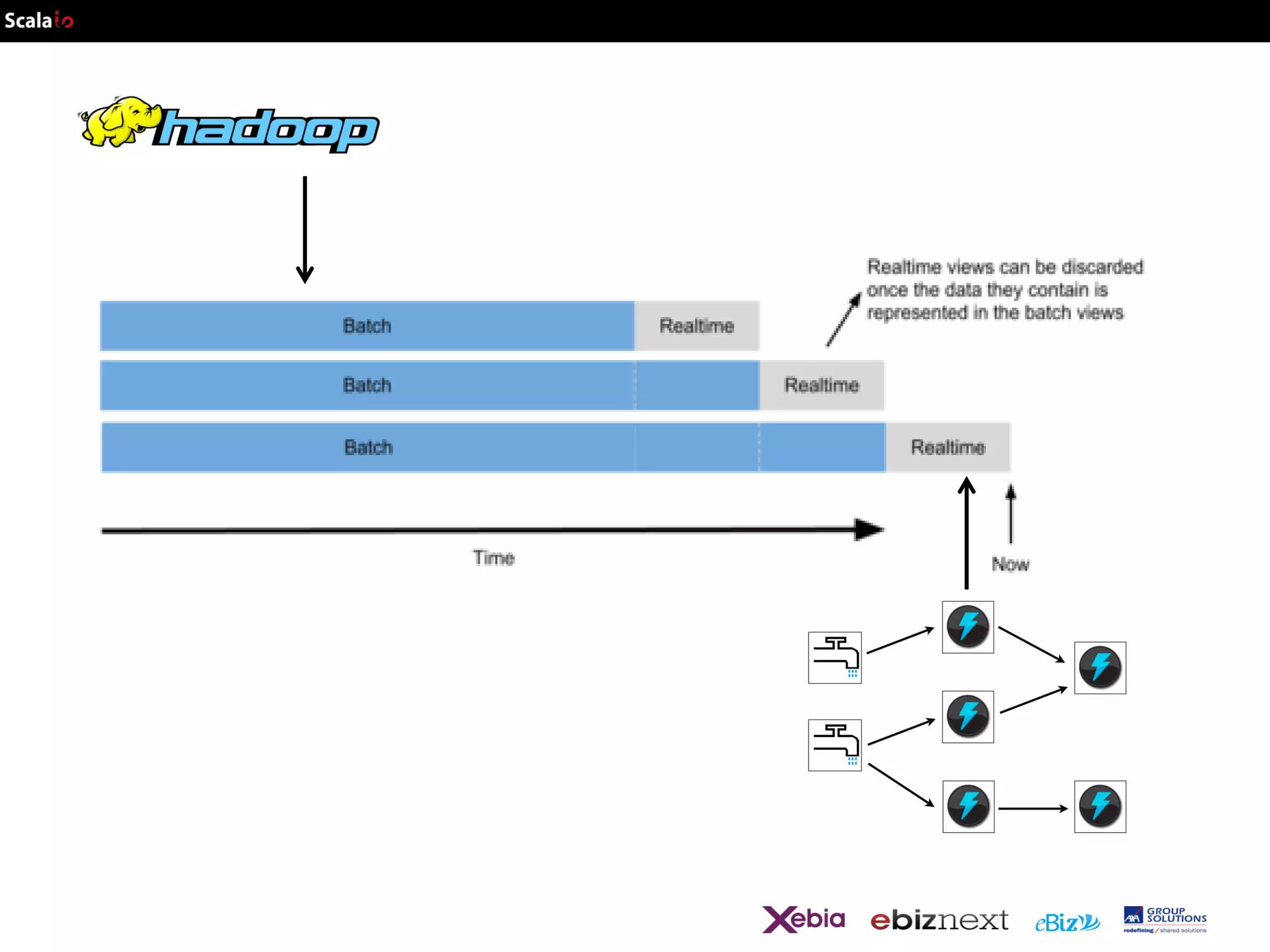
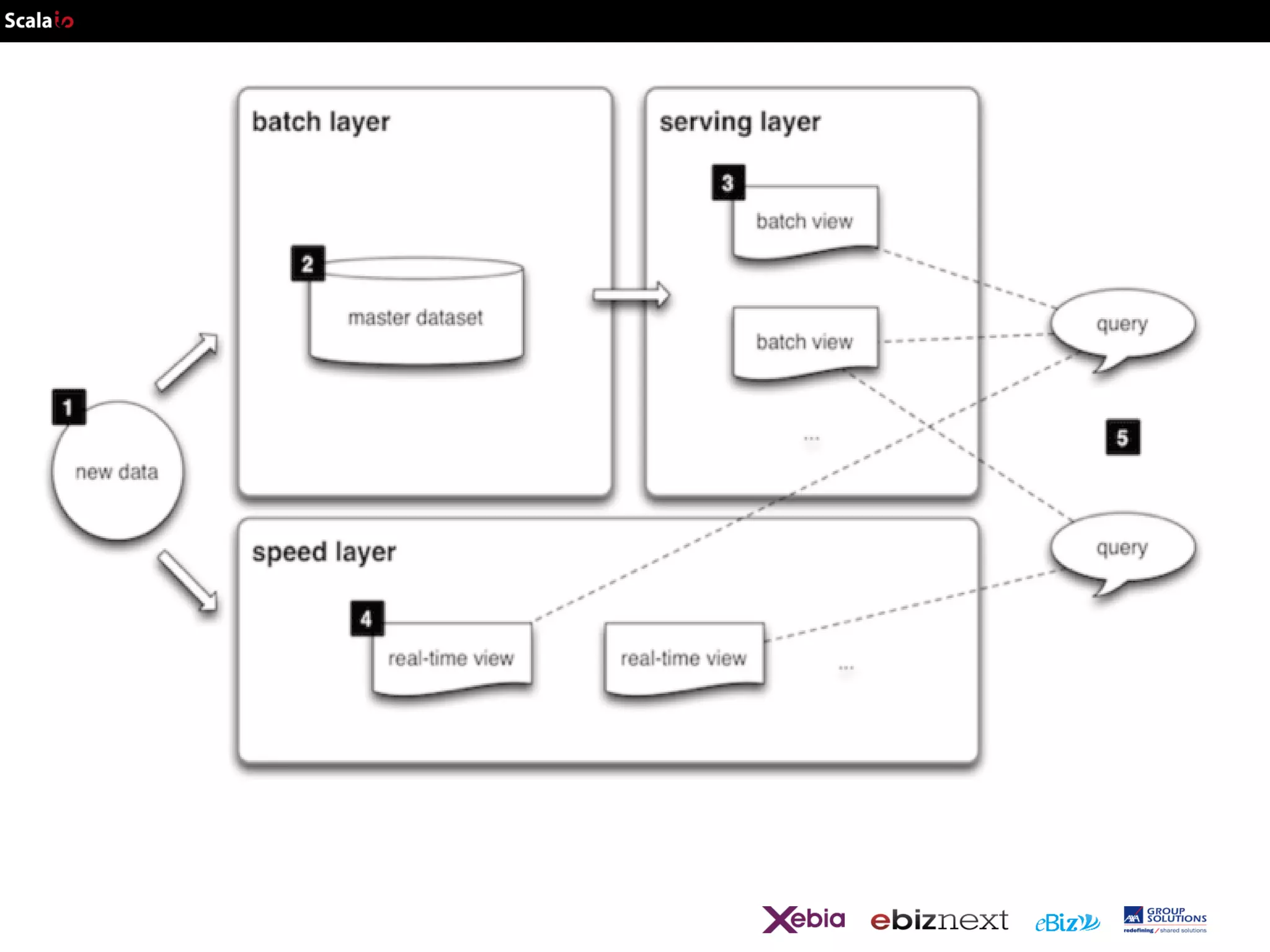
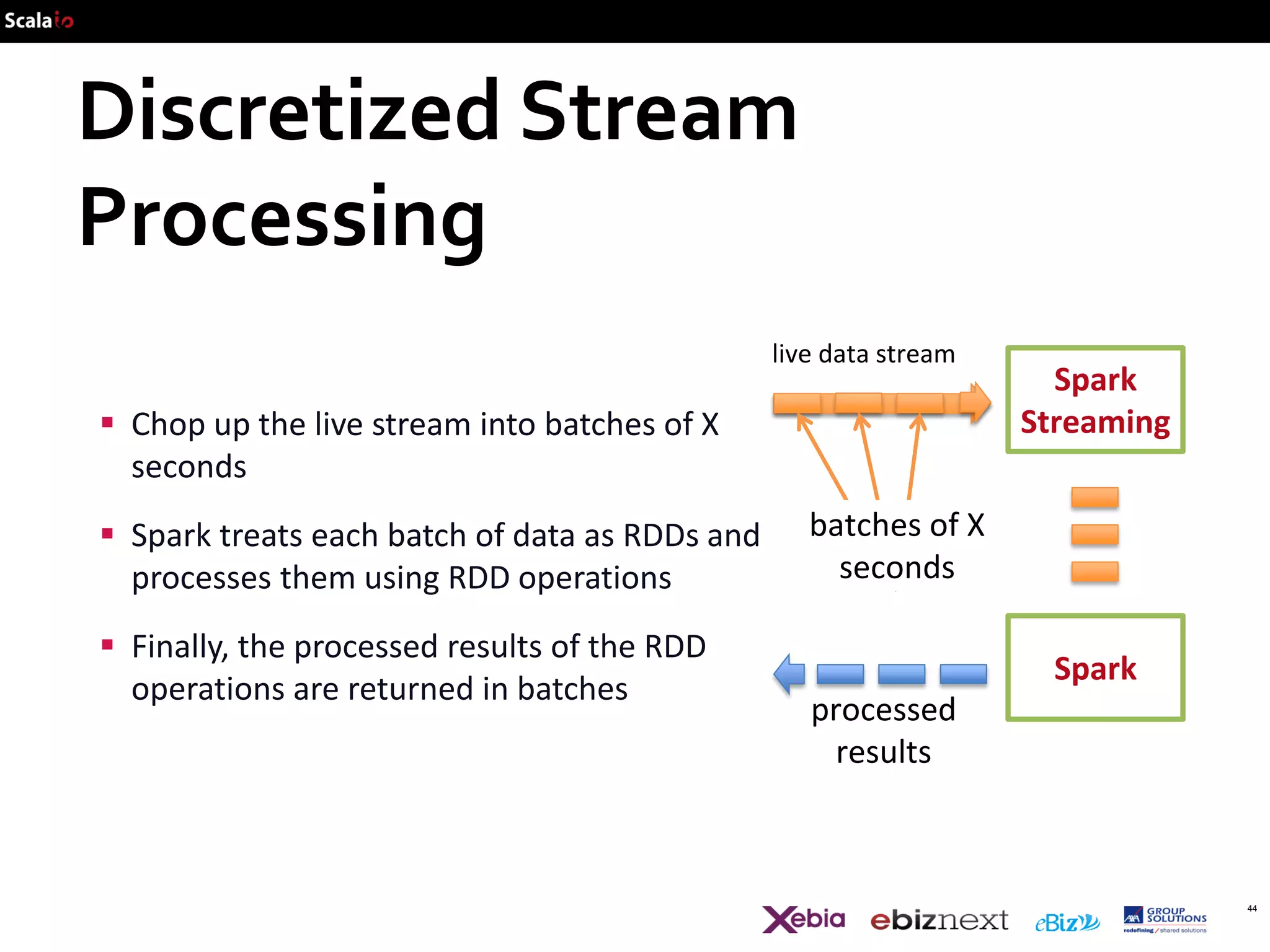
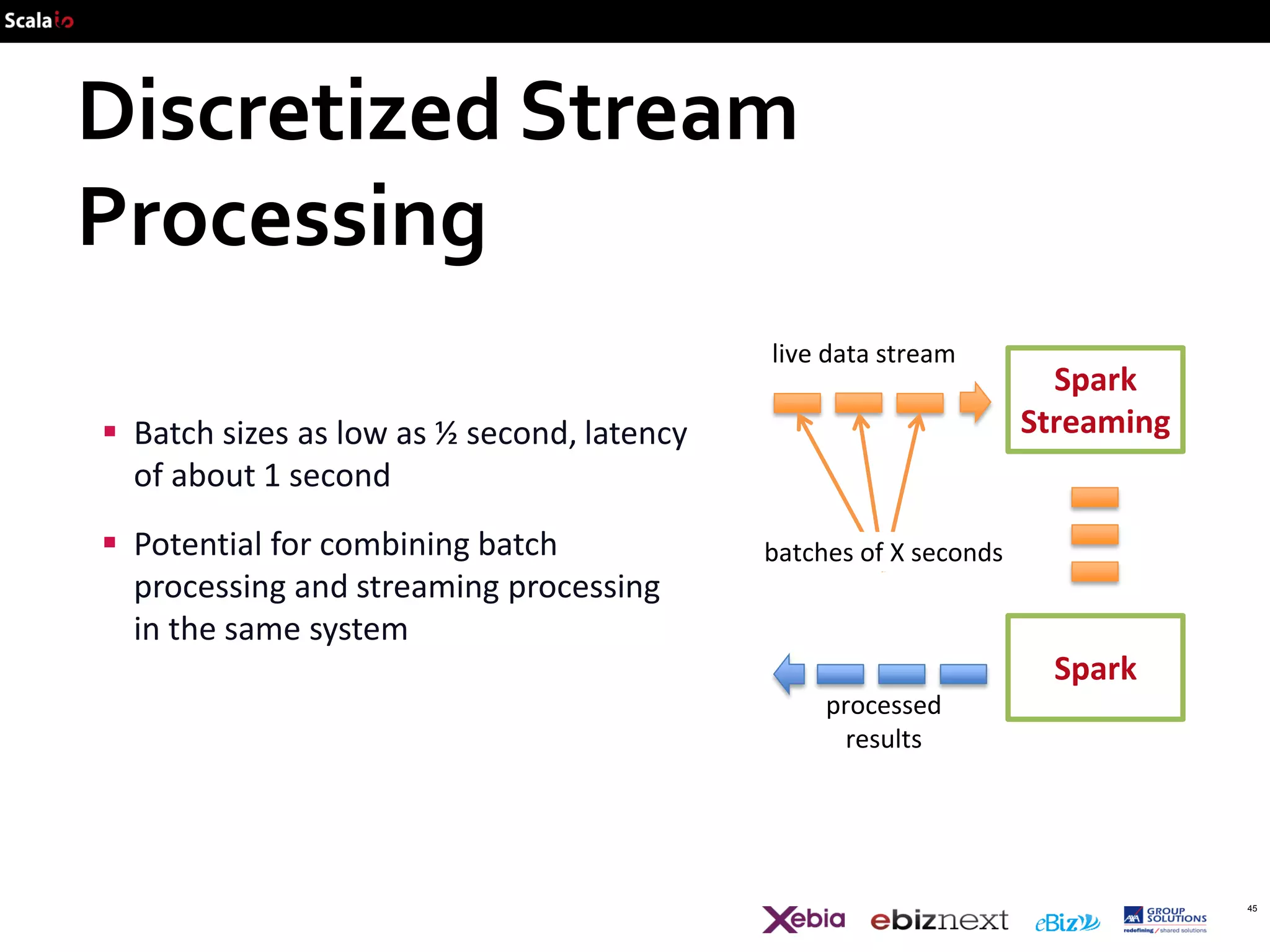
This document provides an overview of big data analytics with Scala, including common frameworks and techniques. It discusses Lambda architecture, MapReduce, word counting examples, Scalding for batch and streaming jobs, Apache Storm, Trident, SummingBird for unified batch and streaming, and Apache Spark for fast cluster computing with resilient distributed datasets. It also covers clustering with Mahout, streaming word counting, and analytics platforms that combine batch and stream processing.





























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












