Download as PDF, PPTX



![DataStream API
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment()
DataStream<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount
DataStream<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.keyBy(0) // [word, [1, 1, …]] for 10 seconds
.timeWindow(Time.of(10, TimeUnit.SECONDS))
.sum(1); // sum per word per 10 second window
counts.print();
env.execute();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-8-320.jpg)
![DataStream API
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment()
DataStream<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount
DataStream<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.keyBy(0) // [word, [1, 1, …]] for 10 seconds
.timeWindow(Time.of(10, TimeUnit.SECONDS))
.sum(1); // sum per word per 10 second window
counts.print();
env.execute();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-9-320.jpg)
![DataStream API
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment()
DataStream<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount
DataStream<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.keyBy(0) // [word, [1, 1, …]] for 10 seconds
.timeWindow(Time.of(10, TimeUnit.SECONDS))
.sum(1); // sum per word per 10 second window
counts.print();
env.execute();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-10-320.jpg)
![DataStream API
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment()
DataStream<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount
DataStream<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.keyBy(0) // [word, [1, 1, …]] for 10 seconds
.timeWindow(Time.of(10, TimeUnit.SECONDS))
.sum(1); // sum per word per 10 second window
counts.print();
env.execute();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-11-320.jpg)
![DataStream API
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment()
DataStream<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount
DataStream<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.keyBy(0) // [word, [1, 1, …]] for 10 seconds
.timeWindow(Time.of(10, TimeUnit.SECONDS))
.sum(1); // sum per word per 10 second window
counts.print();
env.execute();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-12-320.jpg)
![DataStream API
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment()
DataStream<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount
DataStream<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.keyBy(0) // [word, [1, 1, …]] for 10 seconds
.timeWindow(Time.of(10, TimeUnit.SECONDS))
.sum(1); // sum per word per 10 second window
counts.print();
env.execute();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-13-320.jpg)
![DataStream API
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment()
DataStream<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount
DataStream<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.keyBy(0) // [word, [1, 1, …]] for 10 seconds
.timeWindow(Time.of(10, TimeUnit.SECONDS))
.sum(1); // sum per word per 10 second window
counts.print();
env.execute();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-14-320.jpg)
![DataStream API
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment()
DataStream<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataStream Windowed WordCount
DataStream<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.keyBy(0) // [word, [1, 1, …]] for 10 seconds
.timeWindow(Time.of(10, TimeUnit.SECONDS))
.sum(1); // sum per word per 10 second window
counts.print();
env.execute();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-15-320.jpg)


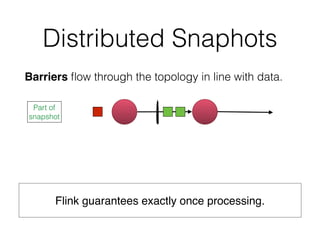
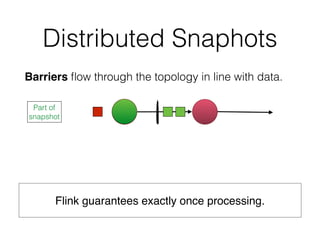
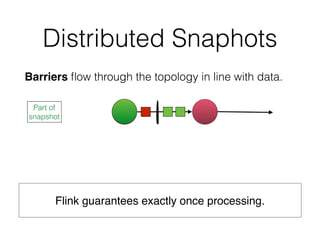
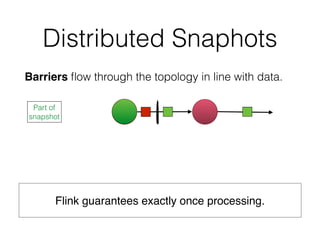
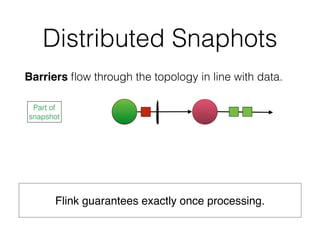
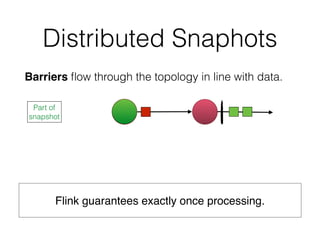
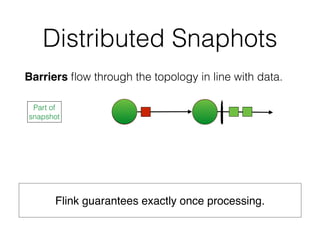
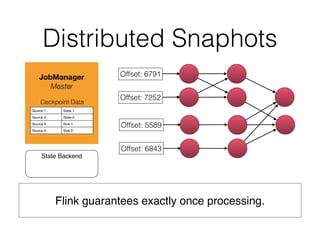


![DataSet API
ExecutionEnvironment env = ExecutionEnvironment
.getExecutionEnvironment()
DataSet<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount
DataSet<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.groupBy(0) // [word, [1, 1, …]]
.sum(1); // sum per word for all occurrences
counts.print();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-47-320.jpg)
![DataStream API
ExecutionEnvironment env = ExecutionEnvironment
.getExecutionEnvironment()
DataSet<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount
DataSet<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.groupBy(0) // [word, [1, 1, …]]
.sum(1); // sum per word for all occurrences
counts.print();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-48-320.jpg)
![DataStream API
ExecutionEnvironment env = ExecutionEnvironment
.getExecutionEnvironment()
DataSet<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount
DataSet<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.groupBy(0) // [word, [1, 1, …]]
.sum(1); // sum per word for all occurrences
counts.print();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-49-320.jpg)
![DataStream API
ExecutionEnvironment env = ExecutionEnvironment
.getExecutionEnvironment()
DataSet<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount
DataSet<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.groupBy(0) // [word, [1, 1, …]]
.sum(1); // sum per word for all occurrences
counts.print();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-50-320.jpg)
![DataStream API
ExecutionEnvironment env = ExecutionEnvironment
.getExecutionEnvironment()
DataSet<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount
DataSet<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.groupBy(0) // [word, [1, 1, …]]
.sum(1); // sum per word for all occurrences
counts.print();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-51-320.jpg)
![DataStream API
ExecutionEnvironment env = ExecutionEnvironment
.getExecutionEnvironment()
DataSet<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount
DataSet<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.groupBy(0) // [word, [1, 1, …]]
.sum(1); // sum per word for all occurrences
counts.print();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-52-320.jpg)
![DataStream API
ExecutionEnvironment env = ExecutionEnvironment
.getExecutionEnvironment()
DataSet<String> data = env.fromElements(
"O Romeo, Romeo! wherefore art thou Romeo?”, ...);
// DataSet WordCount
DataSet<Tuple2<String, Integer>> counts = data
.flatMap(new SplitByWhitespace()) // (word, 1)
.groupBy(0) // [word, [1, 1, …]]
.sum(1); // sum per word for all occurrences
counts.print();](https://image.slidesharecdn.com/hug-london-151102085759-lva1-app6892/85/Streaming-Dataflow-with-Apache-Flink-53-320.jpg)



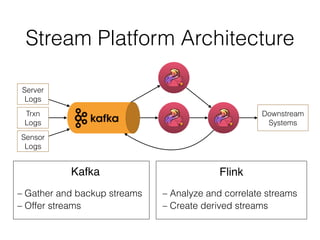
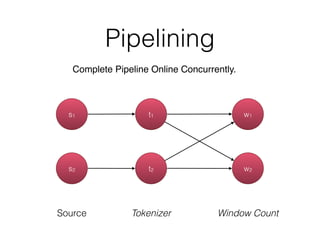
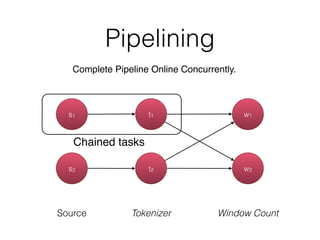
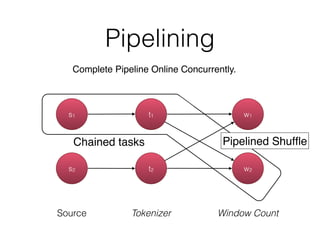
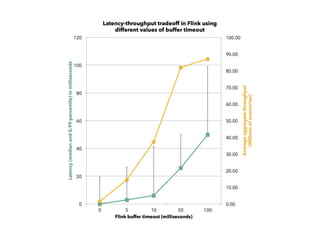
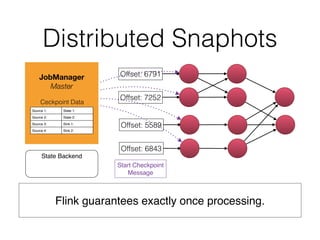
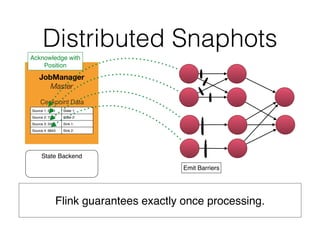
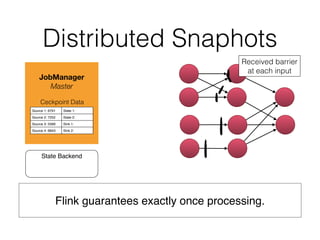
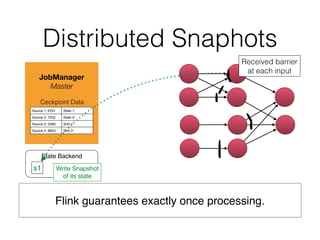
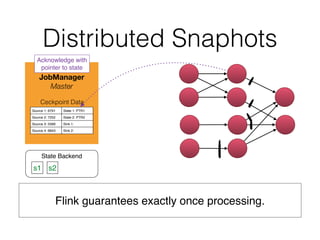
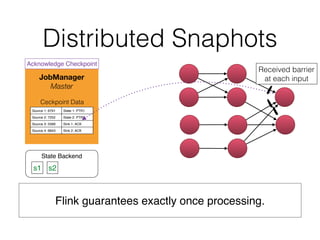
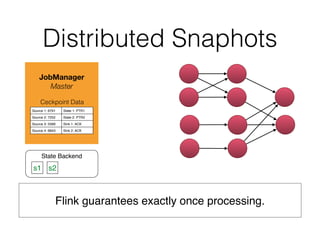
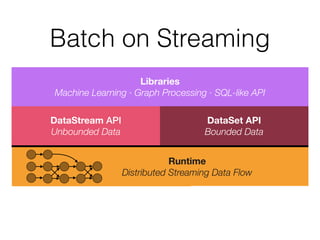
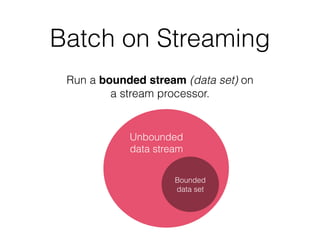
The document discusses Apache Flink, a stream processing framework that efficiently handles unbounded data with low latency and high throughput, guaranteeing exactly-once processing. It outlines various features, including its datastream and dataset APIs, as well as the capabilities for batch and stream processing. The document also provides insights into deployment options, fault tolerance, and the architecture behind Flink's processing mechanisms.























![RxJava applied [JavaDay Kyiv 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/pdfrxjava-appliedjavaday-161013154948-thumbnail.jpg?width=640&height=640&fit=bounds)


























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




