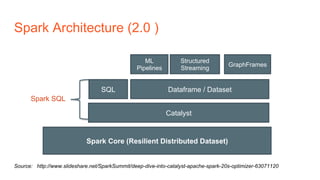
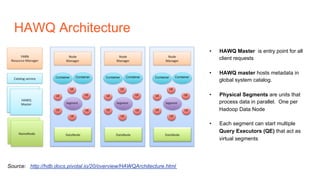
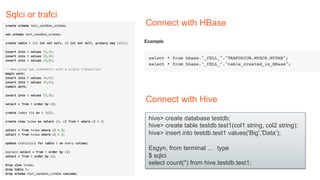
The document summarizes several popular options for SQL on Hadoop including Hive, SparkSQL, Drill, HAWQ, Phoenix, Trafodion, and Splice Machine. Each option is reviewed in terms of key features, architecture, usage patterns, and strengths/limitations. While all aim to enable SQL querying of Hadoop data, they differ in support for transactions, latency, data types, and whether they are native to Hadoop or require separate processes. Hive and SparkSQL are best for batch jobs while Drill, HAWQ and Splice Machine provide lower latency but with different integration models and capabilities.