Downloaded 257 times





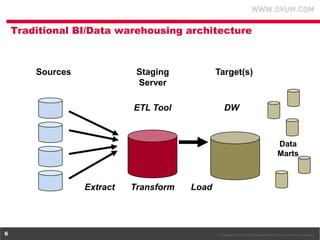


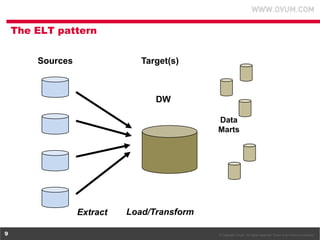
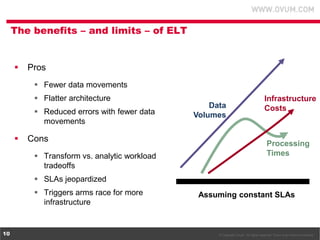






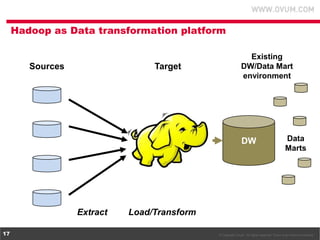












1. The document discusses using Hadoop as an extension to traditional data warehouses to overcome limitations of scaling and accommodating new data types. Hadoop provides a flexible and cost-effective platform for data transformation and analytics workloads. 2. Cloudera provides tools like Impala and Cloudera Manager to integrate Hadoop with SQL data platforms and better support Hadoop deployments. This allows Hadoop to be more easily used as a data transformation platform and extension to existing data warehouses. 3. Using Hadoop as an extension to data warehouses provides benefits like lower costs, ability to keep archived data active, and more flexible division of analytics and transformation workloads between Hadoop and SQL platforms.























































































