Download to read offline













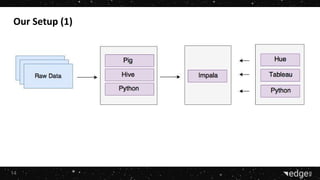
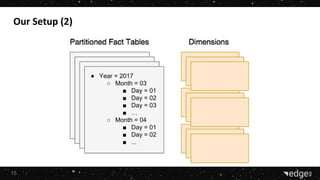







1. The company is building advertising management platforms to help customers make smarter decisions and reach business goals faster using real-time data. They lead the online advertising market and strive to build long-term client relationships. 2. They are hiring a Data & BI Team Leader experienced in big data technologies like Hadoop and Impala to deliver real-time insights from large data sets for tasks like fraud detection and predictive analytics. 3. They chose to use Impala for its ability to perform interactive queries directly on HDFS data without relying on MapReduce, its compatibility with HiveQL, and its support through Cloudera Manager.























































































