Downloaded 86 times




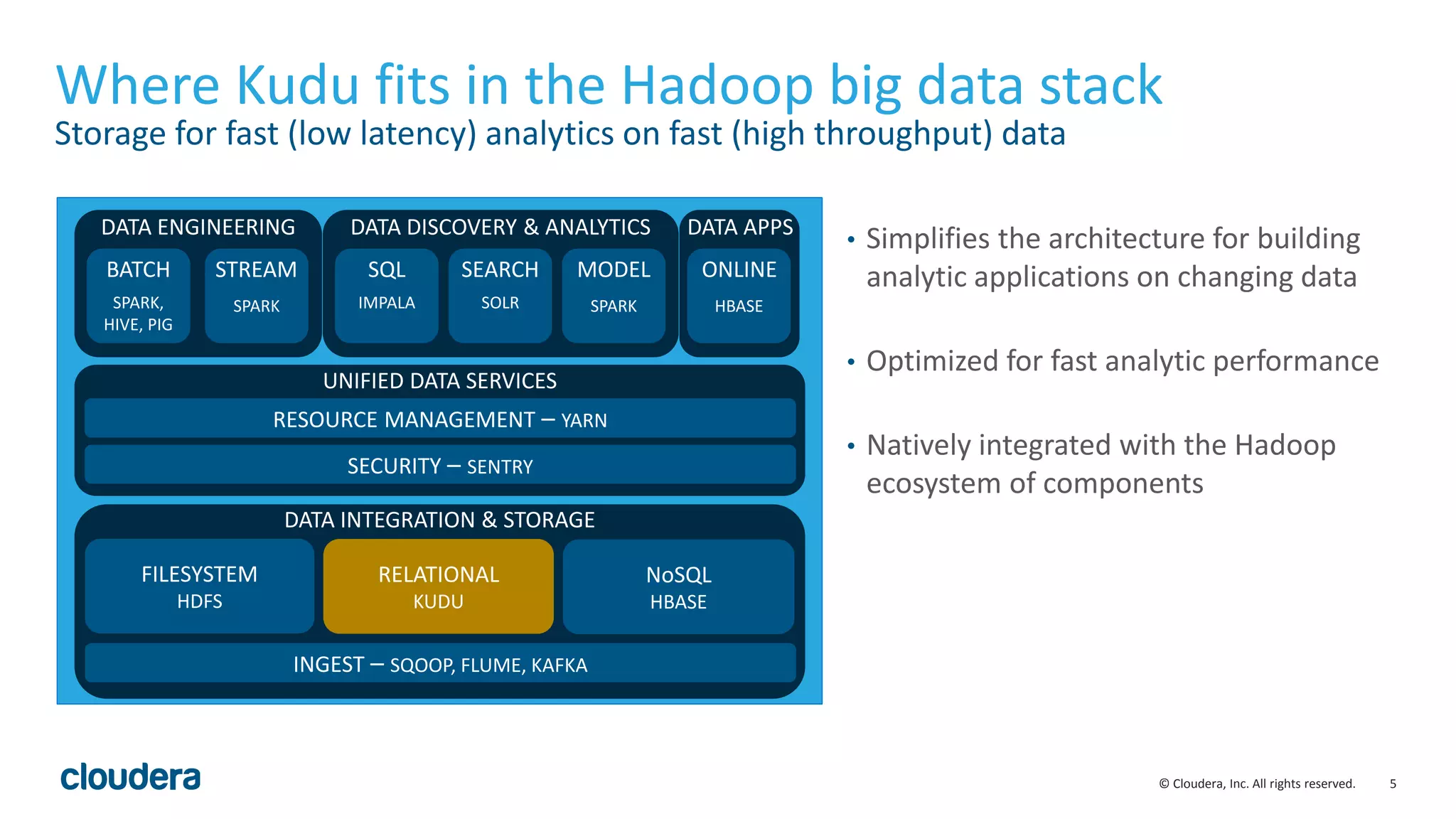




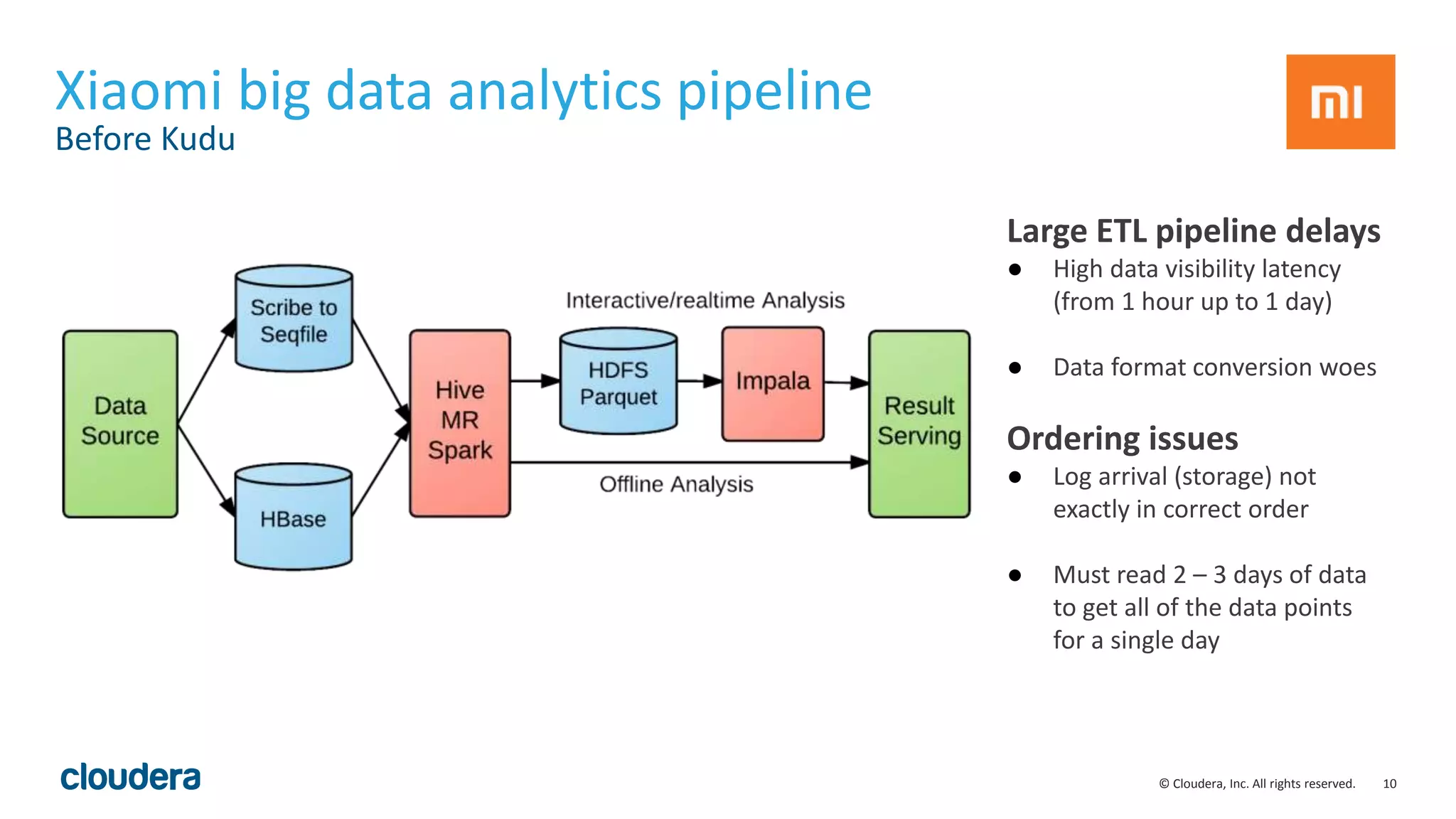
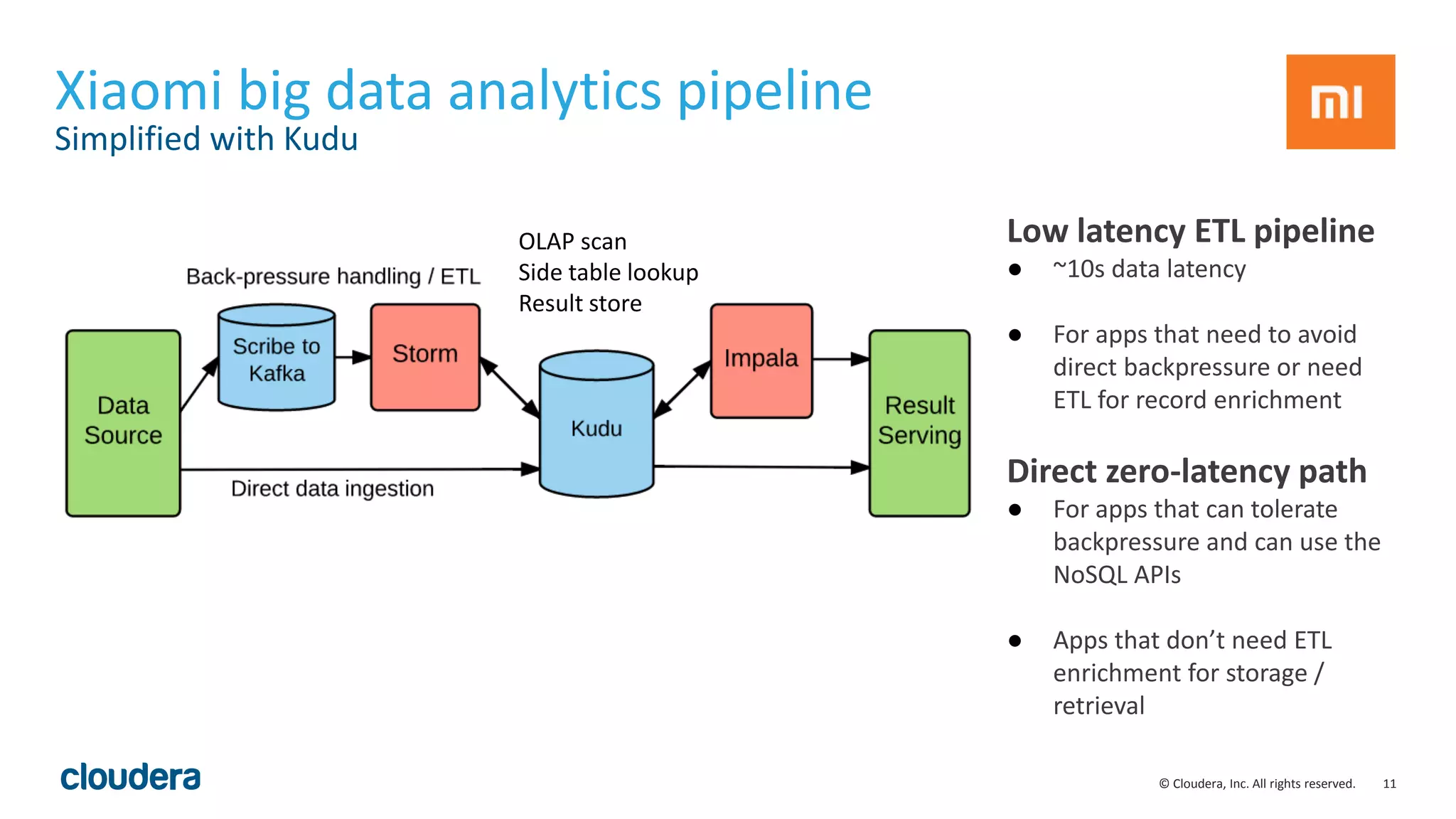

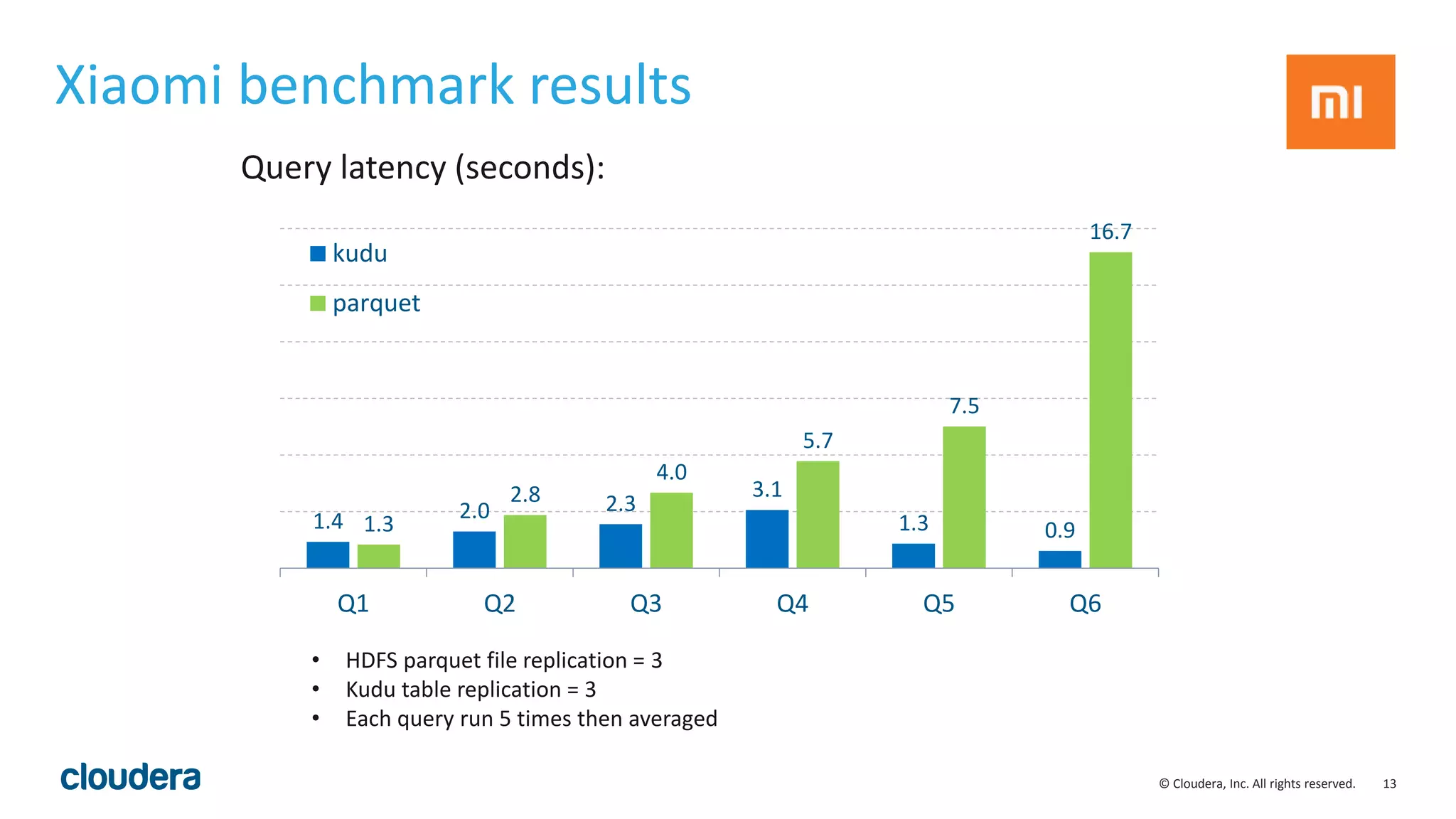

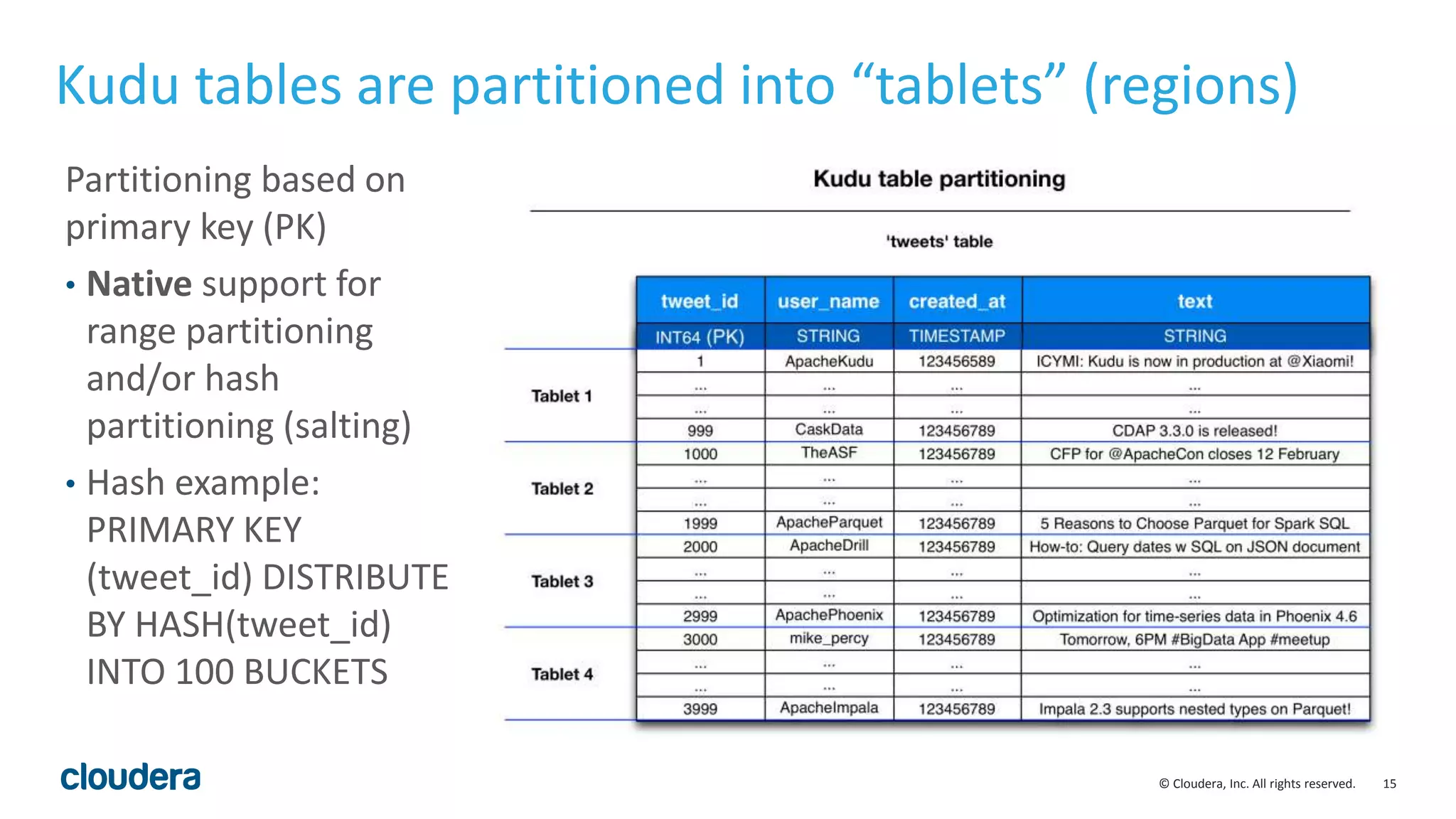
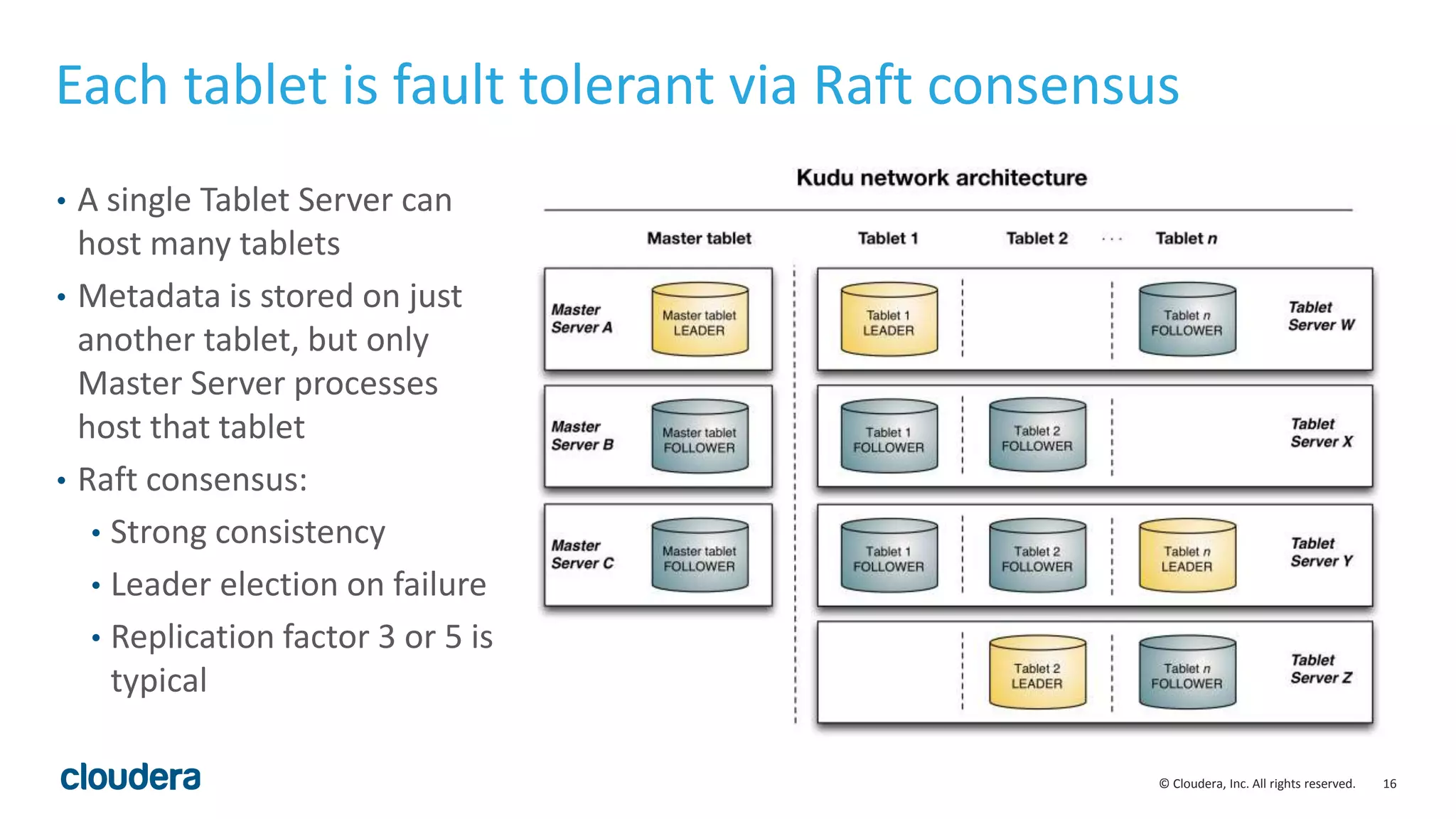






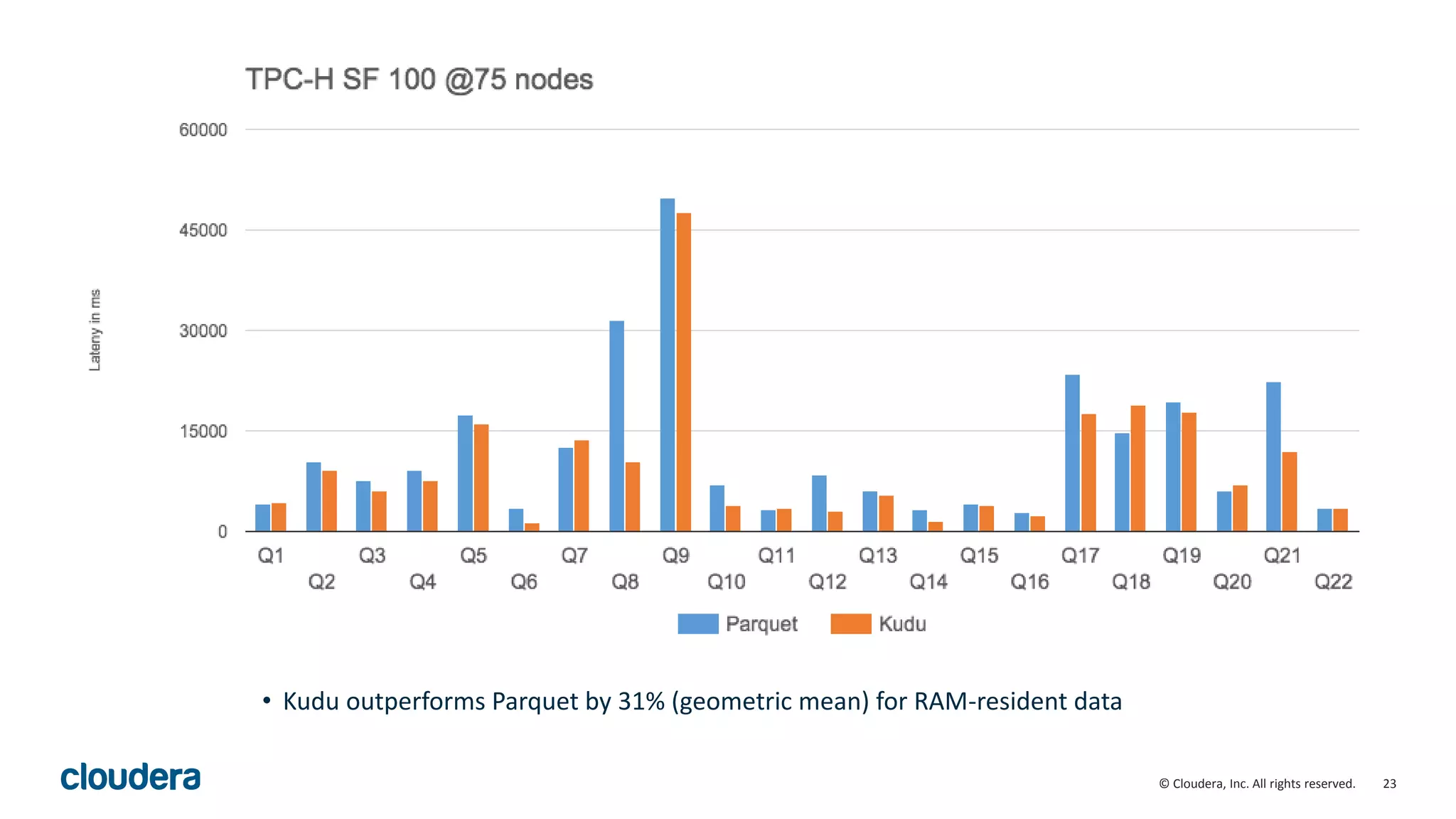
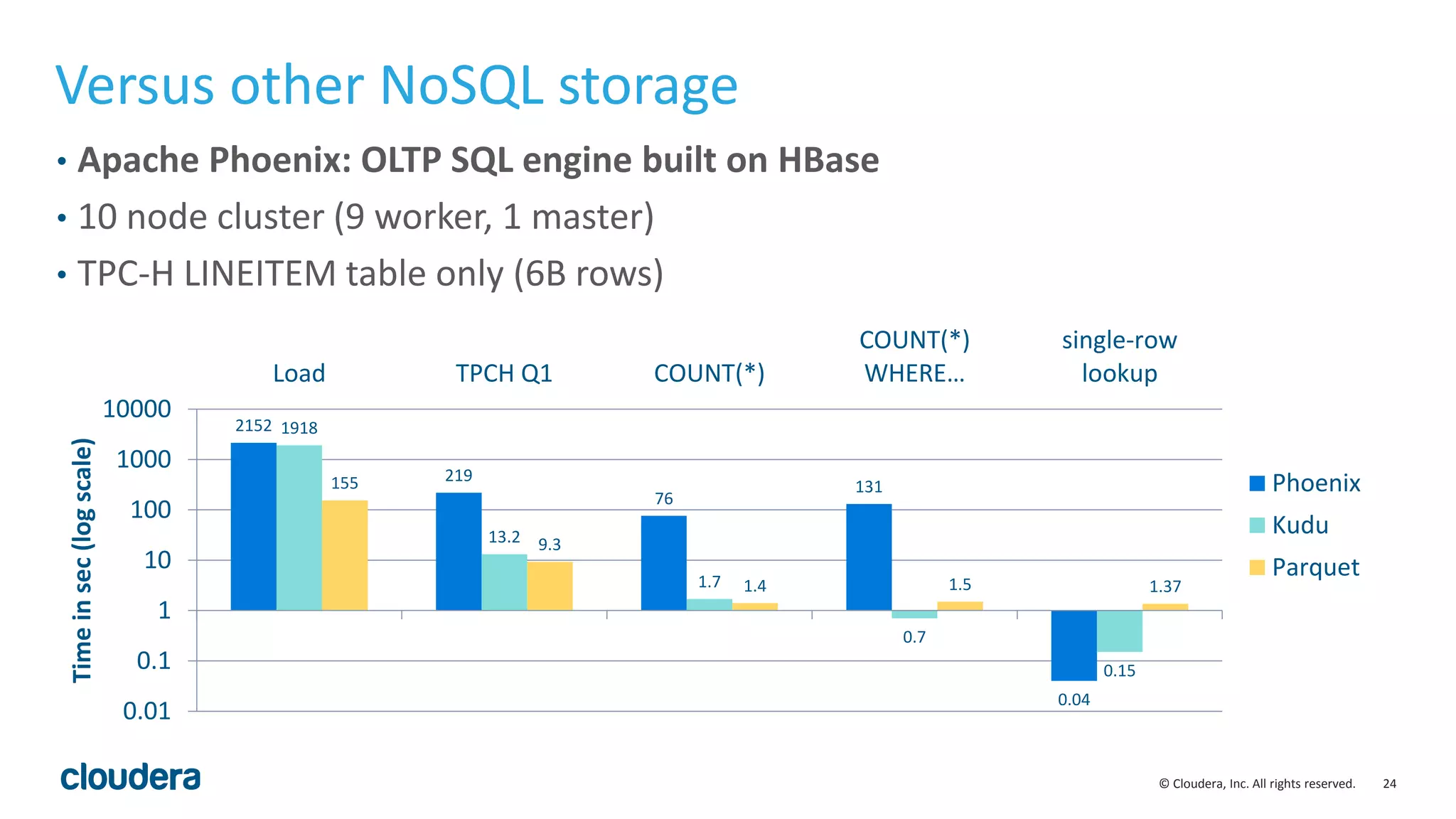





The document introduces Apache Kudu, a Hadoop storage solution optimized for fast analytics on rapidly changing data, filling gaps left by HDFS and HBase. It highlights Kudu's design goals for high throughput and low latency performance, as well as its integration with SQL engines and NoSQL APIs. Real-world use cases, including a case study with Xiaomi, demonstrate Kudu's efficiency in handling large-scale data with reduced latency compared to traditional ETL pipelines.






















































































