







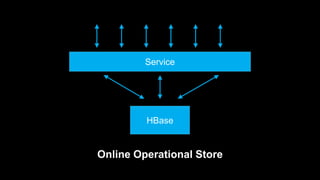
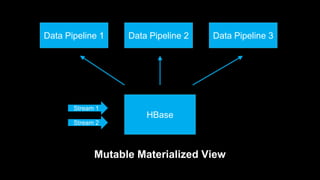
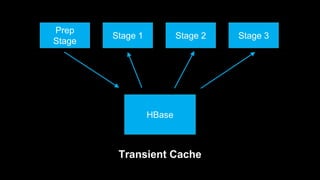



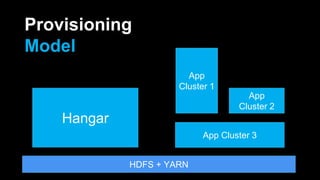


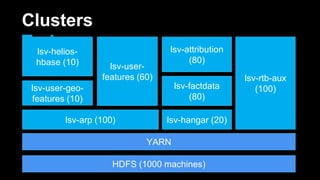











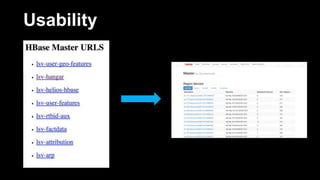



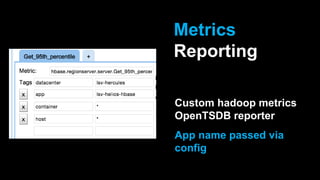

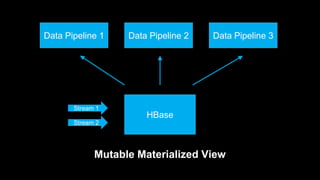




DeathStar is a system that runs HBase on YARN to provide easy, dynamic multi-tenant HBase clusters via YARN. It allows different applications to run HBase in separate application-specific clusters on a shared HDFS and YARN infrastructure. This provides strict isolation between applications and enables dynamic scaling of clusters as needed. Some key benefits are improved cluster utilization, easier capacity planning and configuration, and the ability to start new clusters on demand without lengthy provisioning times.










































![Inspiring Travel at Airbnb [WIP]](https://cdn.slidesharecdn.com/ss_thumbnails/june91205pmairbnbqiancheng-150616222059-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


















![Discover.hdp2.2.h base.final[2]](https://cdn.slidesharecdn.com/ss_thumbnails/discover-141218155001-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)











































