Downloaded 150 times
















![DREMIO
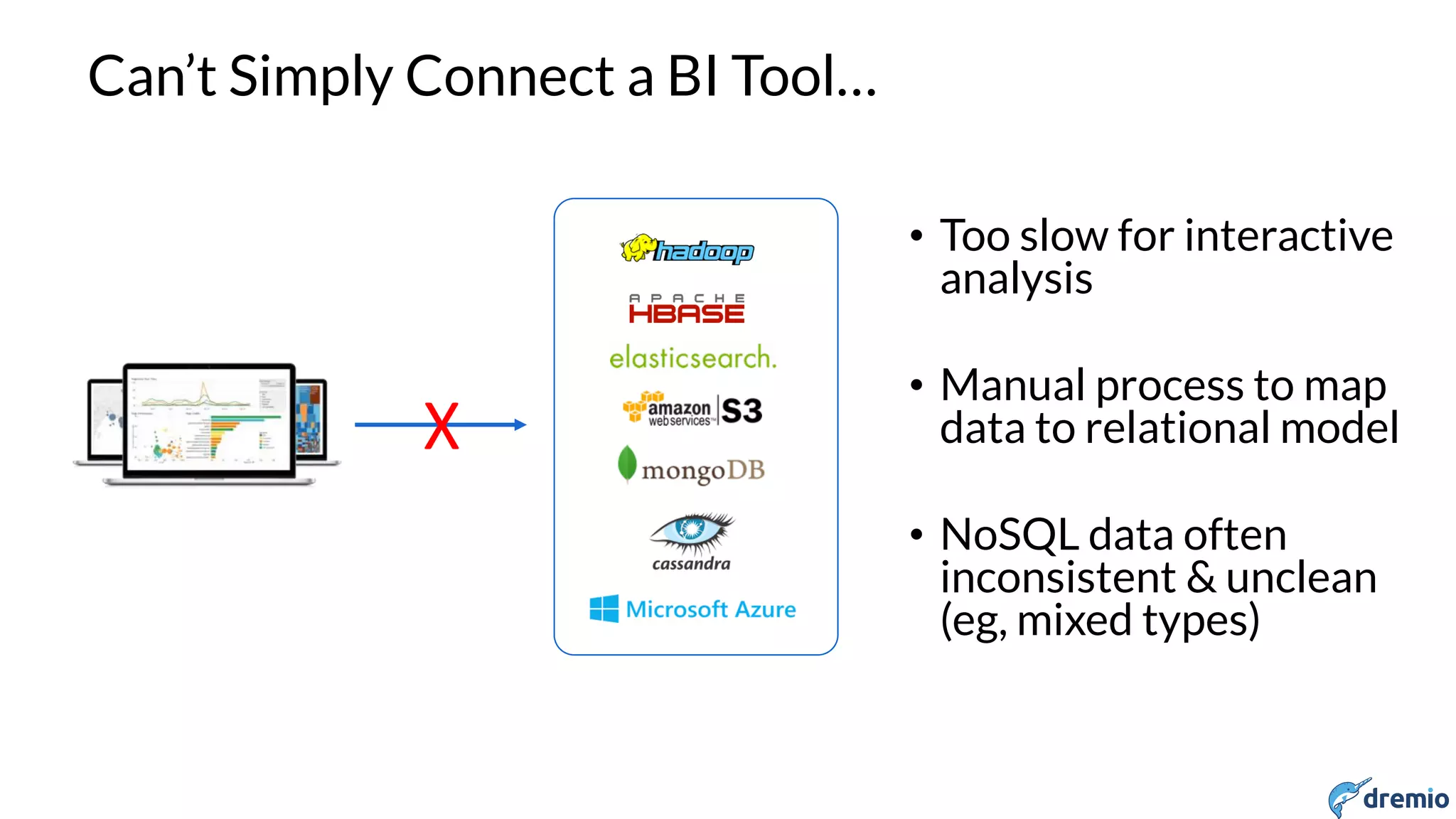
Native JSON Data Model
Access Arrays
SELECT categories[0]
{
"business_id": 123,
"name": "McDonalds",
"categories": ["restaurant", "fast food"],
"attributes": {
"family friendly": true,
"fast": true,
"romantic": false
}
}
Access Maps
WHERE t.attributes.romantic IS TRUE
Flatten Arrays
SELECT name, FLATTEN(categories)
Extract Keys
SELECT name, KVGEN(attributes)
Flatten Maps
SELECT name, FLATTEN(KVGEN(attributes))
Access Embedded JSON Blobs
SELECT d.address.state
FROM (SELECT CONVERT_FROM(t.data, JSON) d FROM t)](https://image.slidesharecdn.com/april131500dremioshiran-160425201129/75/The-Heterogeneous-Data-lake-24-2048.jpg)
![DREMIO
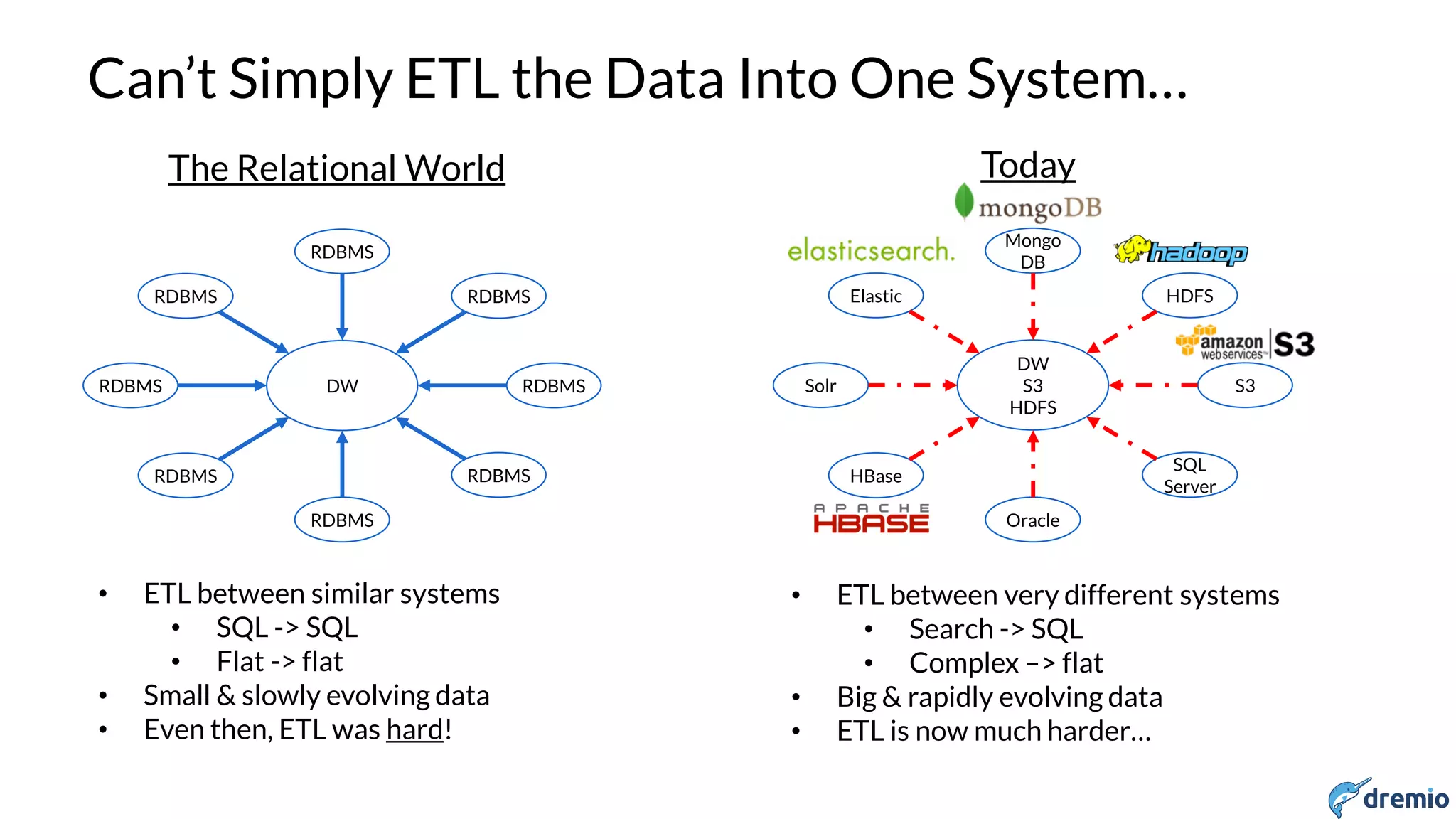
Accessing Array Elements
> SELECT categories FROM business LIMIT 2;
+-------------------------------------------+
| categories |
+-------------------------------------------+
| ["American (Traditional)","Restaurants"] |
| ["Chinese","Restaurants"] |
+-------------------------------------------+
> SELECT categories[0] FROM business LIMIT 2;
+-------------------------+
| EXPR$0 |
+-------------------------+
| American (Traditional) |
| Chinese |
+-------------------------+](https://image.slidesharecdn.com/april131500dremioshiran-160425201129/75/The-Heterogeneous-Data-lake-25-2048.jpg)
![DREMIO
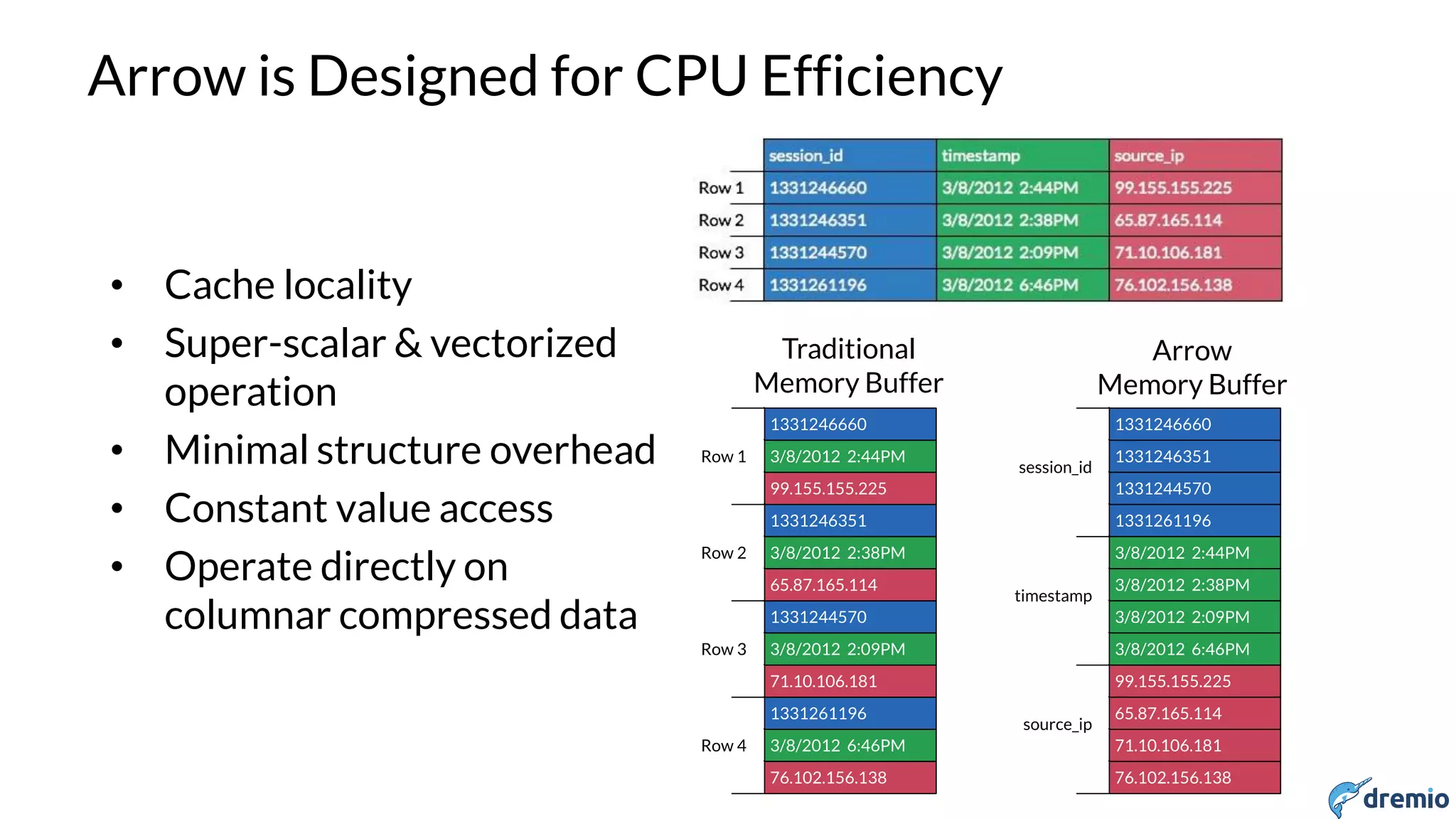
FLATTEN
• FLATTEN converts single record with array field into multiple records
– One output record for each array element
• Non FLATTENed fields are repeated in each of the output records
> SELECT categories
FROM business LIMIT 2;
+-------------------------------------------+
| categories |
+-------------------------------------------+
| ["American (Traditional)","Restaurants"] |
| ["Chinese","Restaurants"] |
+-------------------------------------------+
> SELECT FLATTEN(categories)
FROM business LIMIT 4;
+-------------------------+
| EXPR$0 |
+-------------------------+
| American (Traditional) |
| Restaurants |
| Chinese |
| Restaurants |
+-------------------------+](https://image.slidesharecdn.com/april131500dremioshiran-160425201129/75/The-Heterogeneous-Data-lake-26-2048.jpg)
![DREMIO
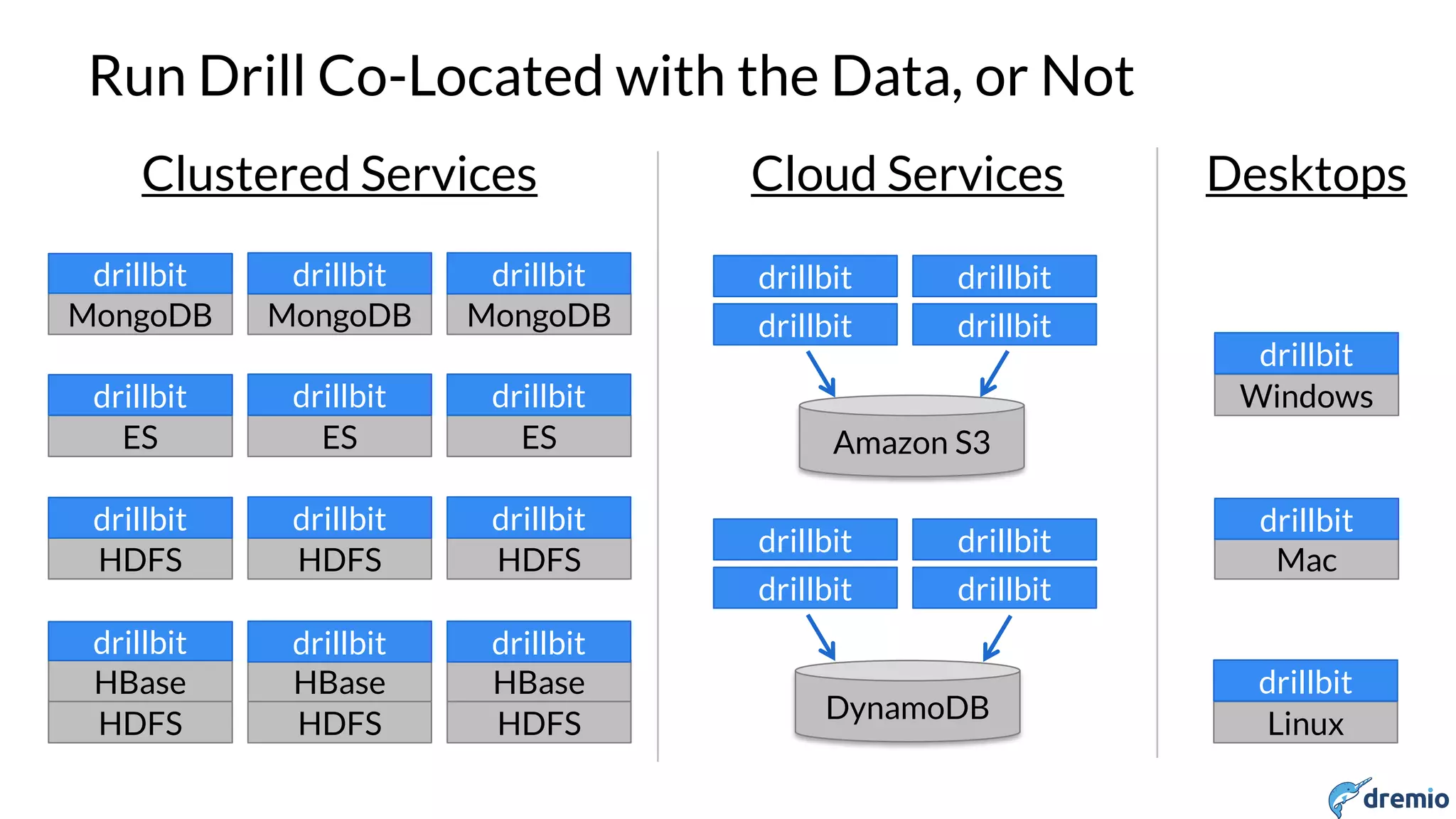
Non-FLATTENed Fields are Repeated
> SELECT name, categories FROM business LIMIT 2;
+------------------------------+-------------------------------------------+
| name | categories |
+------------------------------+-------------------------------------------+
| Deforest Family Restaurant | ["American (Traditional)","Restaurants"] |
| Chang Jiang Chinese Kitchen | ["Chinese","Restaurants"] |
+------------------------------+-------------------------------------------+
> SELECT name, FLATTEN(categories) FROM business LIMIT 4;
+------------------------------+-------------------------+
| name | EXPR$1 |
+------------------------------+-------------------------+
| Deforest Family Restaurant | American (Traditional) |
| Deforest Family Restaurant | Restaurants |
| Chang Jiang Chinese Kitchen | Chinese |
| Chang Jiang Chinese Kitchen | Restaurants |
+------------------------------+-------------------------+](https://image.slidesharecdn.com/april131500dremioshiran-160425201129/75/The-Heterogeneous-Data-lake-27-2048.jpg)
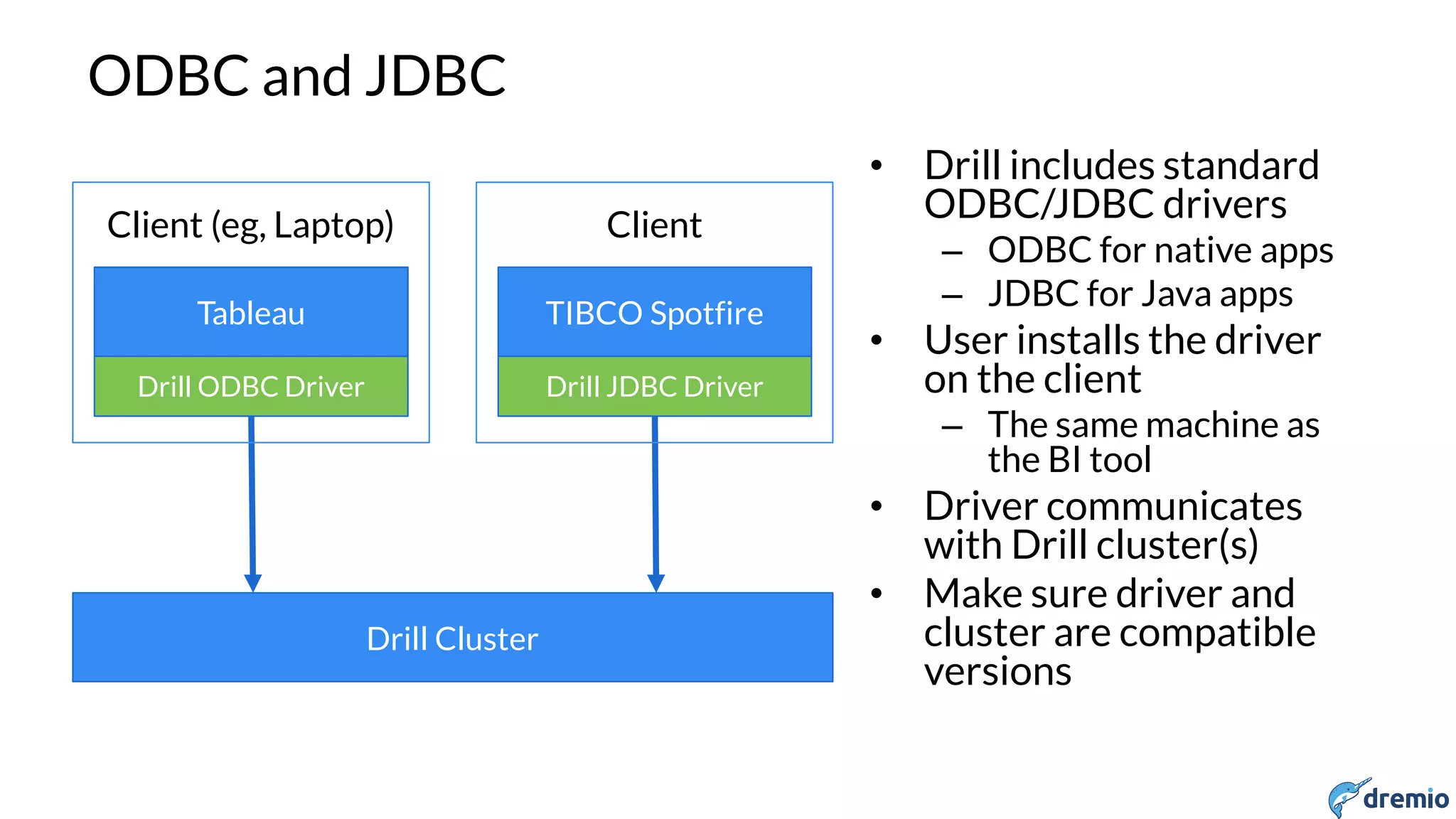




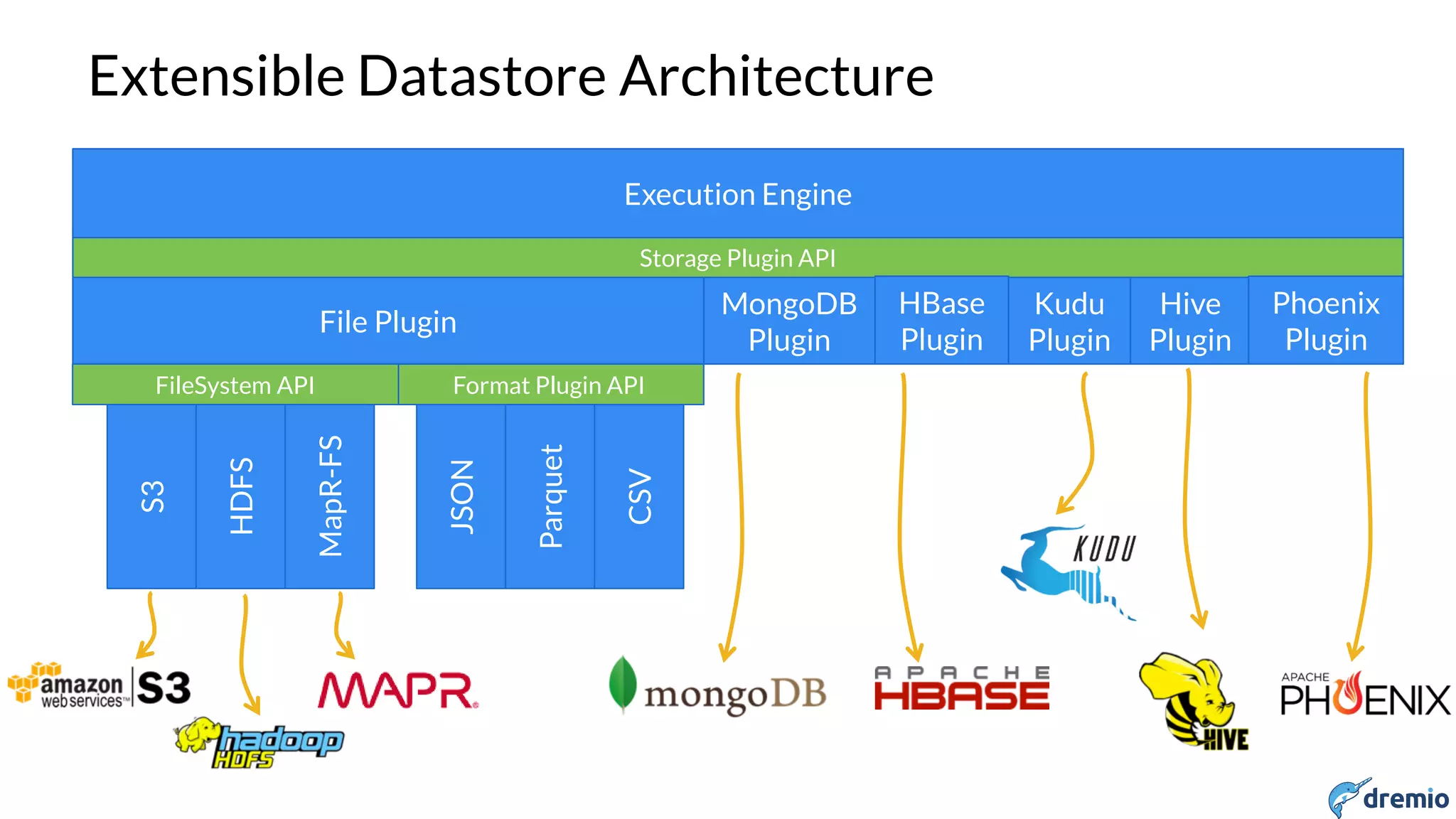
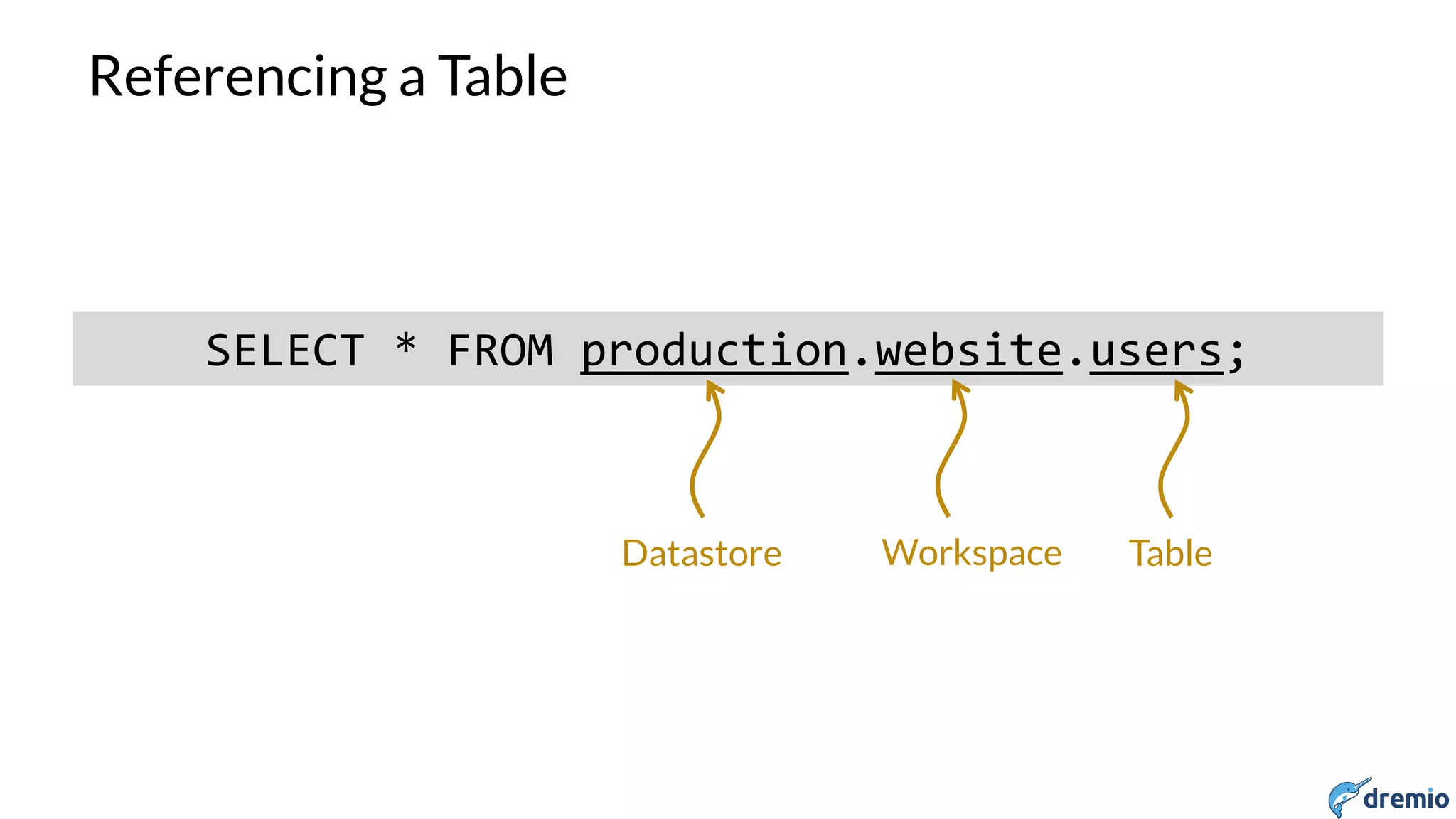
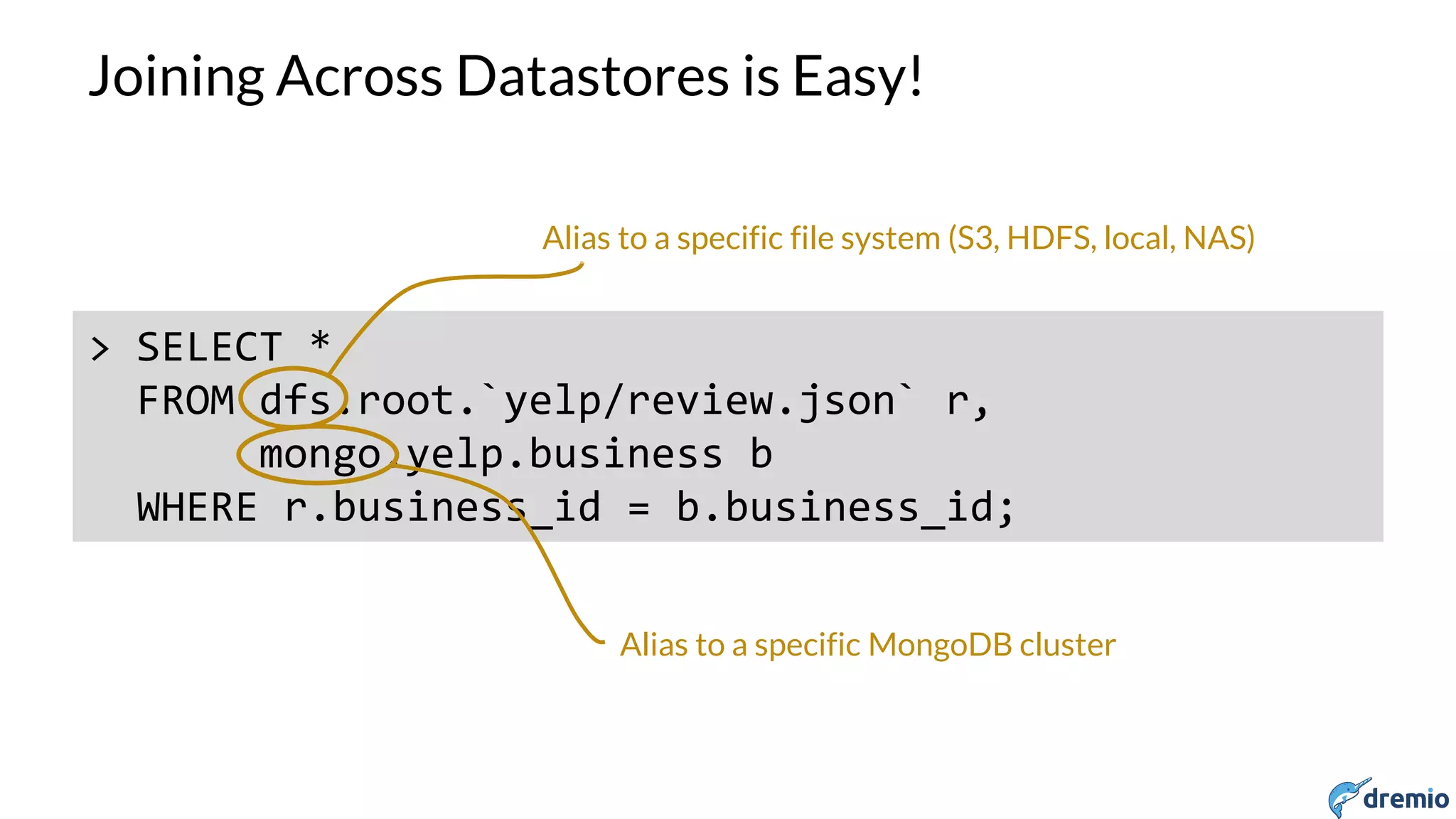
Dremio is a startup founded in 2015 by experts in big data and open source. It aims to provide a platform for interactive analysis across disparate data sources through a storage-agnostic and client-agnostic approach leveraging Apache Arrow for high performance in-memory columnar execution. Dremio uses Apache Drill as its query engine, allowing users to query data across different systems like HDFS, S3, MongoDB as if it was a single relational database through SQL. It has an extensible architecture that allows new data sources to be easily added via plugins.








































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


