Download as PDF, PPTX


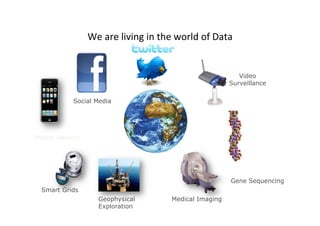



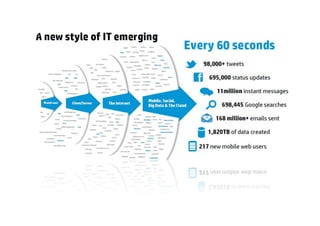

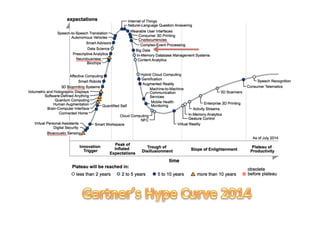
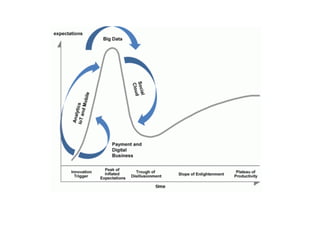



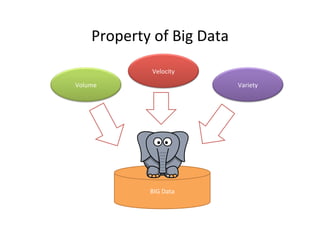


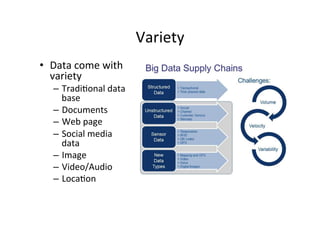

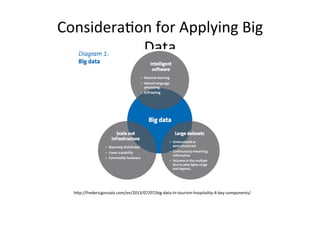








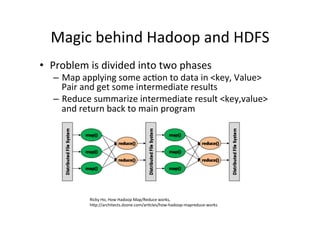




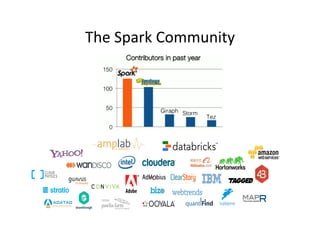
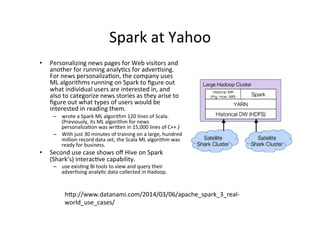


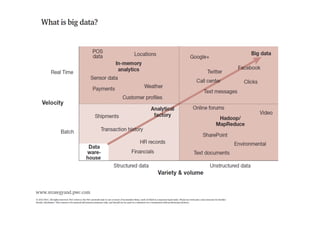

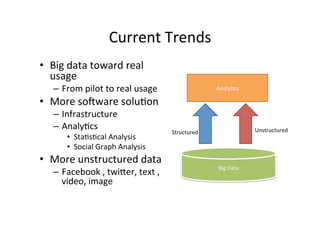











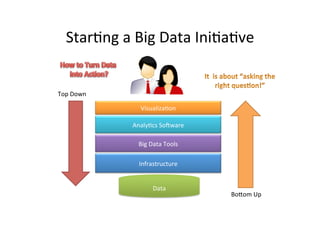

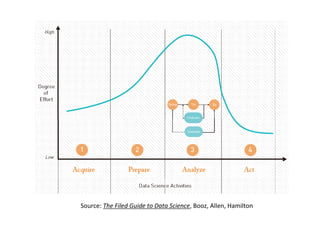



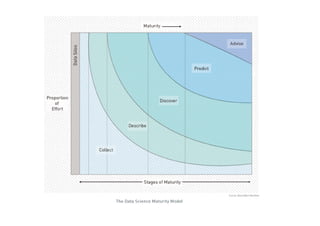







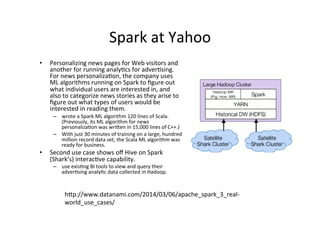
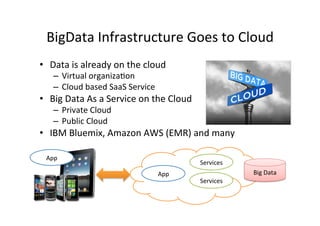

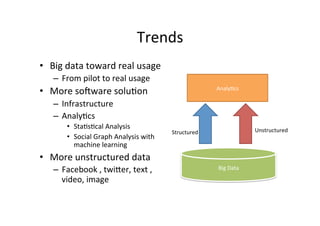









The document provides an overview of big data, defining its essential characteristics as high volume, velocity, and variety. It discusses the importance of big data for various sectors, including healthcare and e-commerce, and introduces key tools and technologies used for its storage and analysis, such as Hadoop and NoSQL databases. Additionally, it emphasizes the insights gained from big data analytics and the shift towards cloud-based solutions for managing vast amounts of data.











































































































