Download as PPSX, PPTX

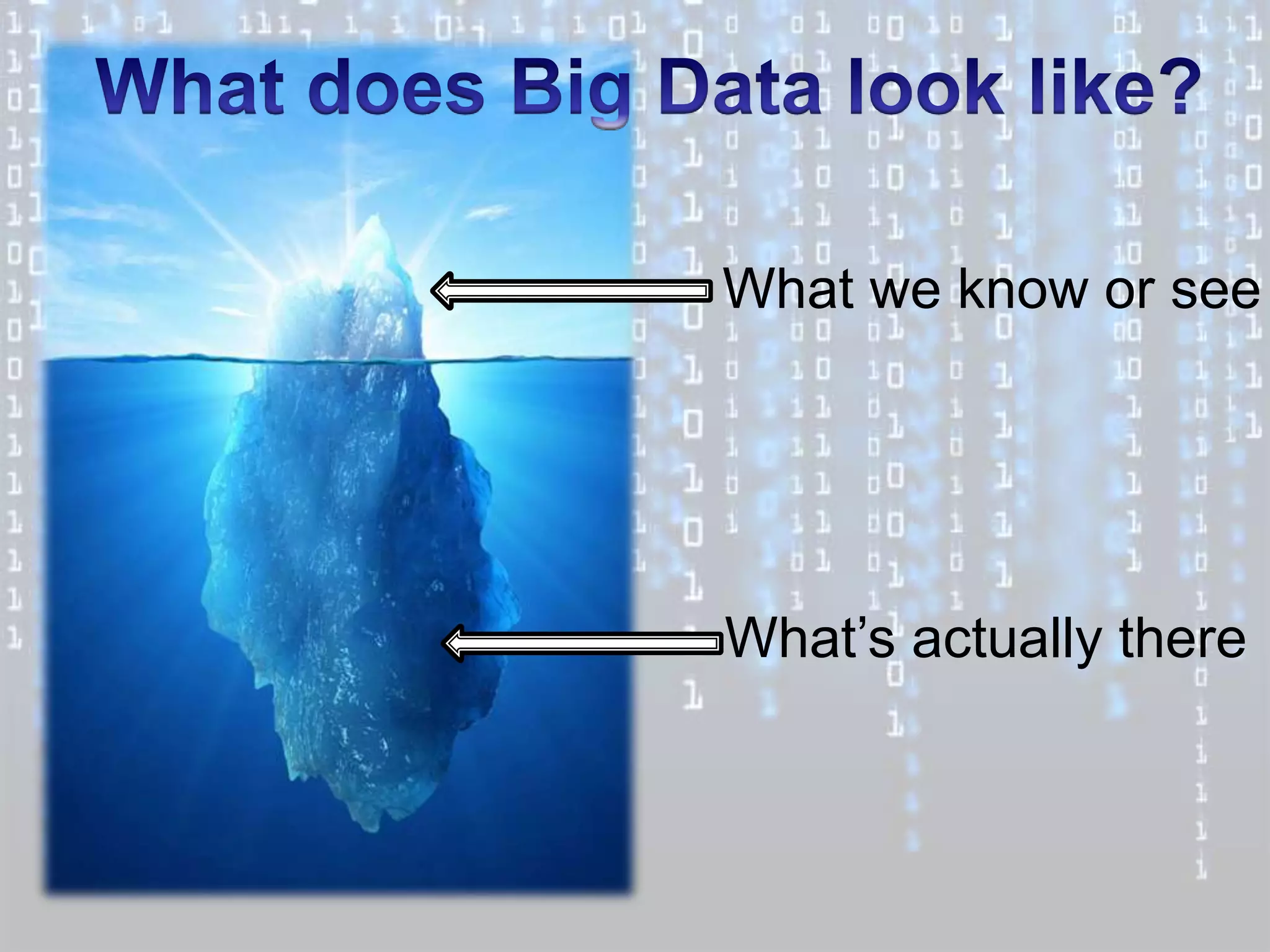








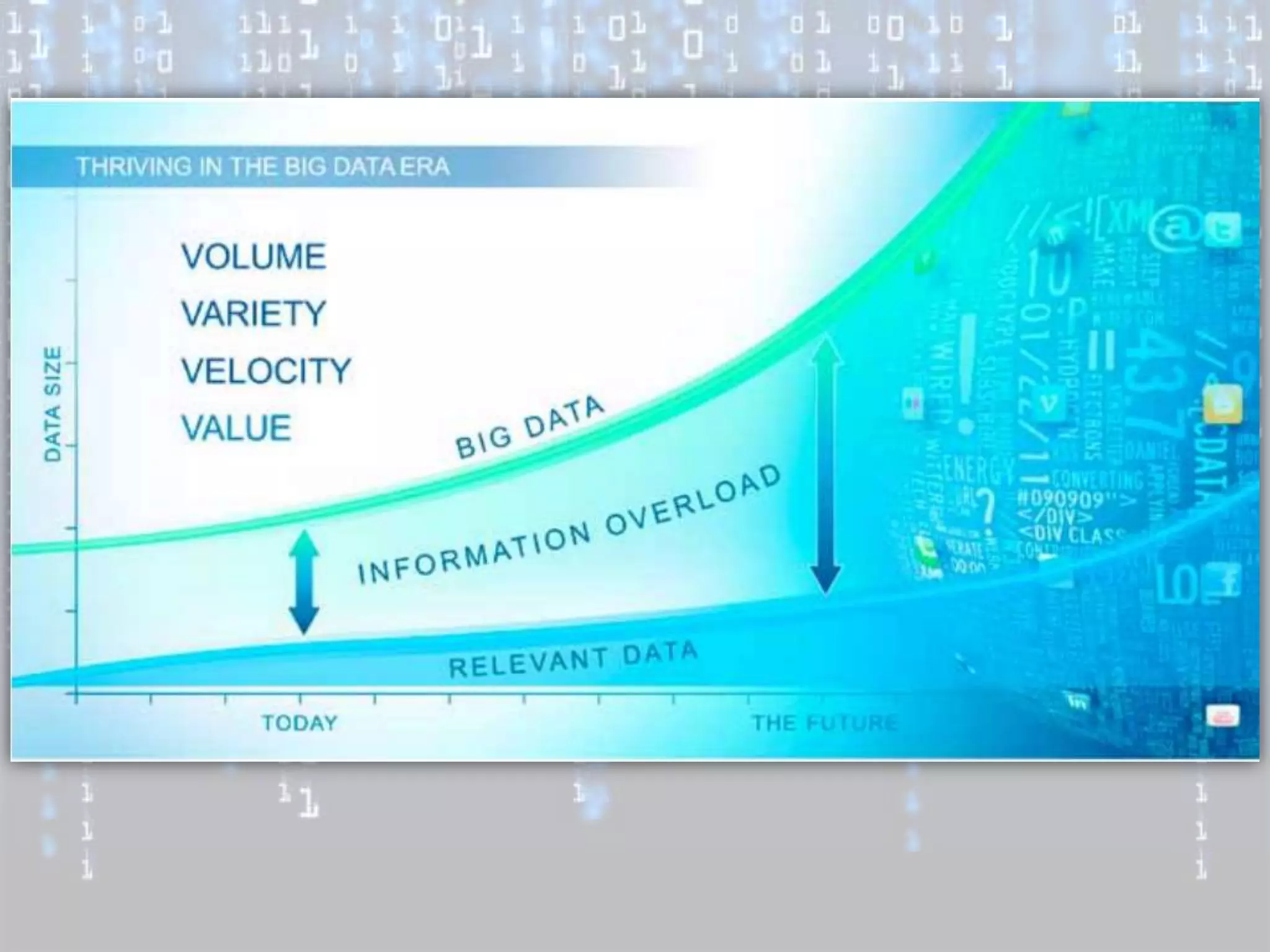
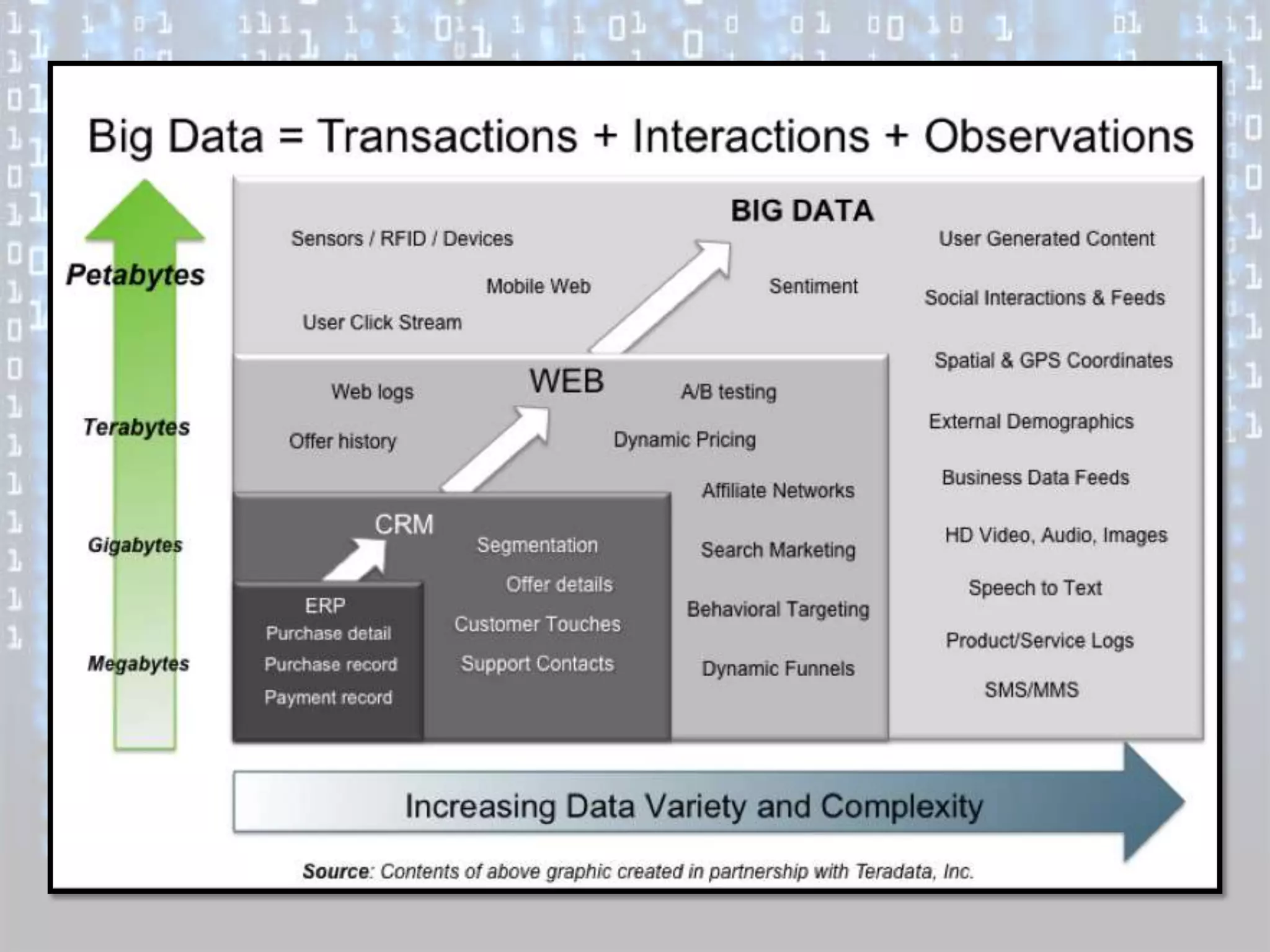
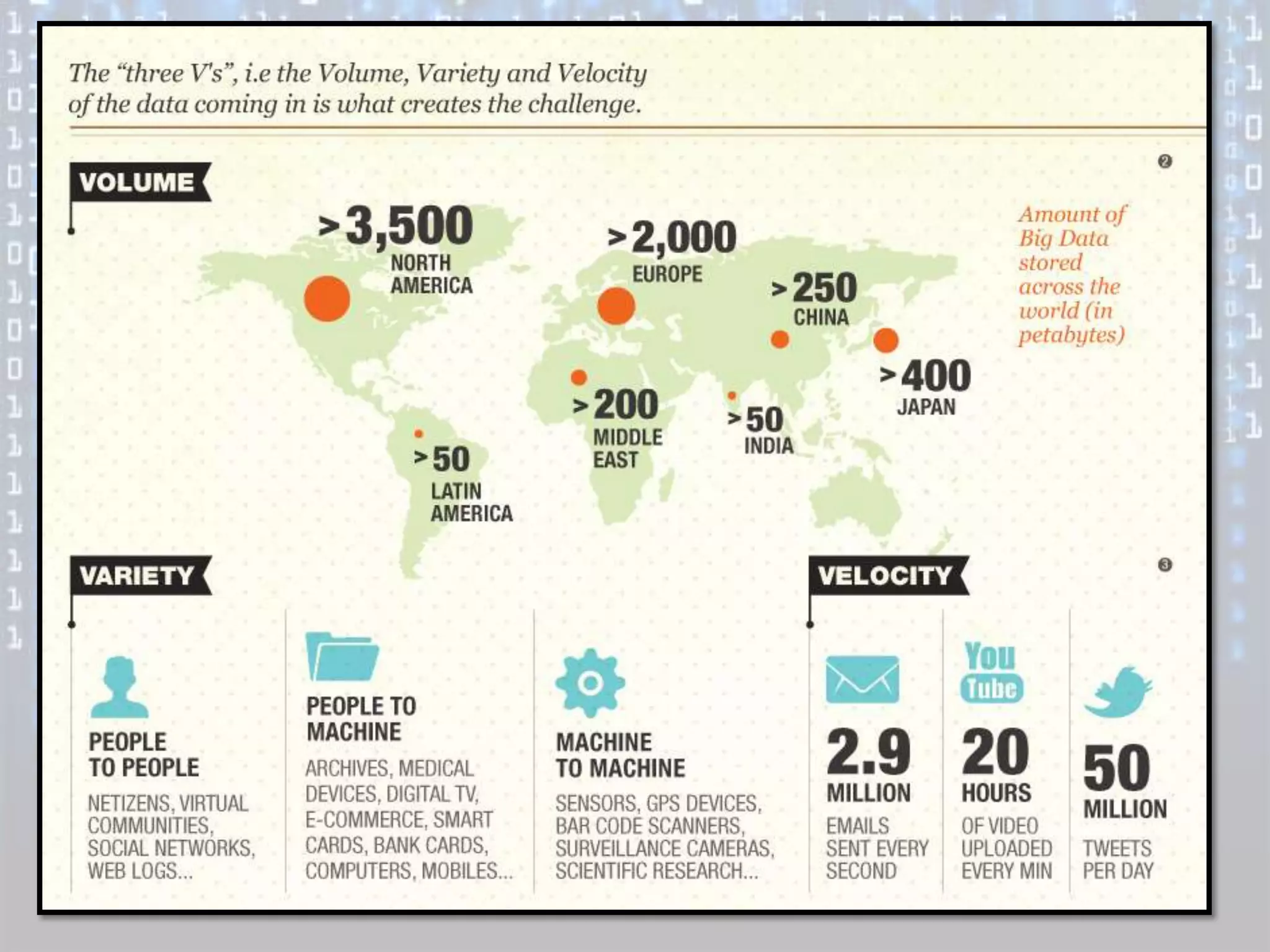

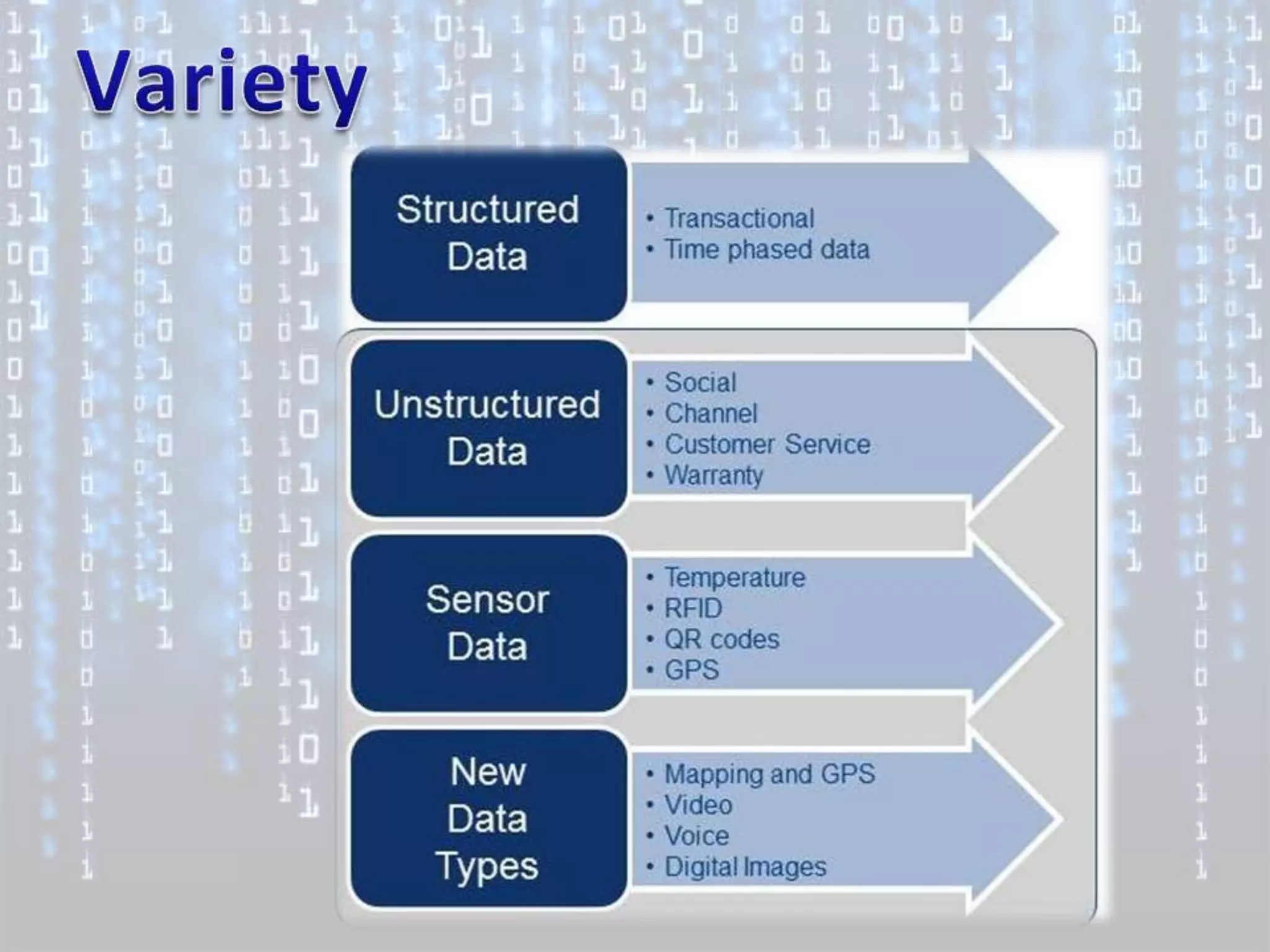

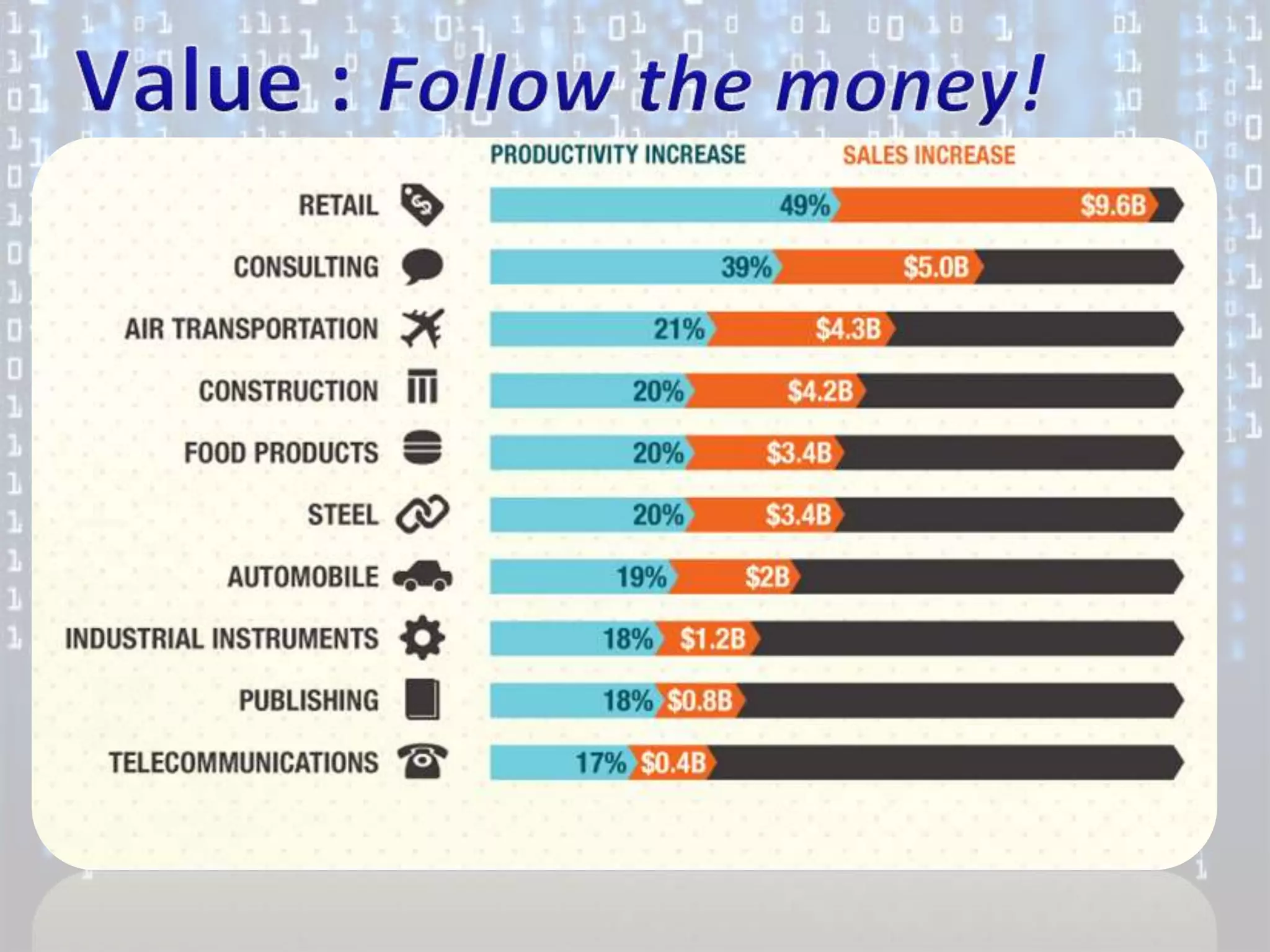
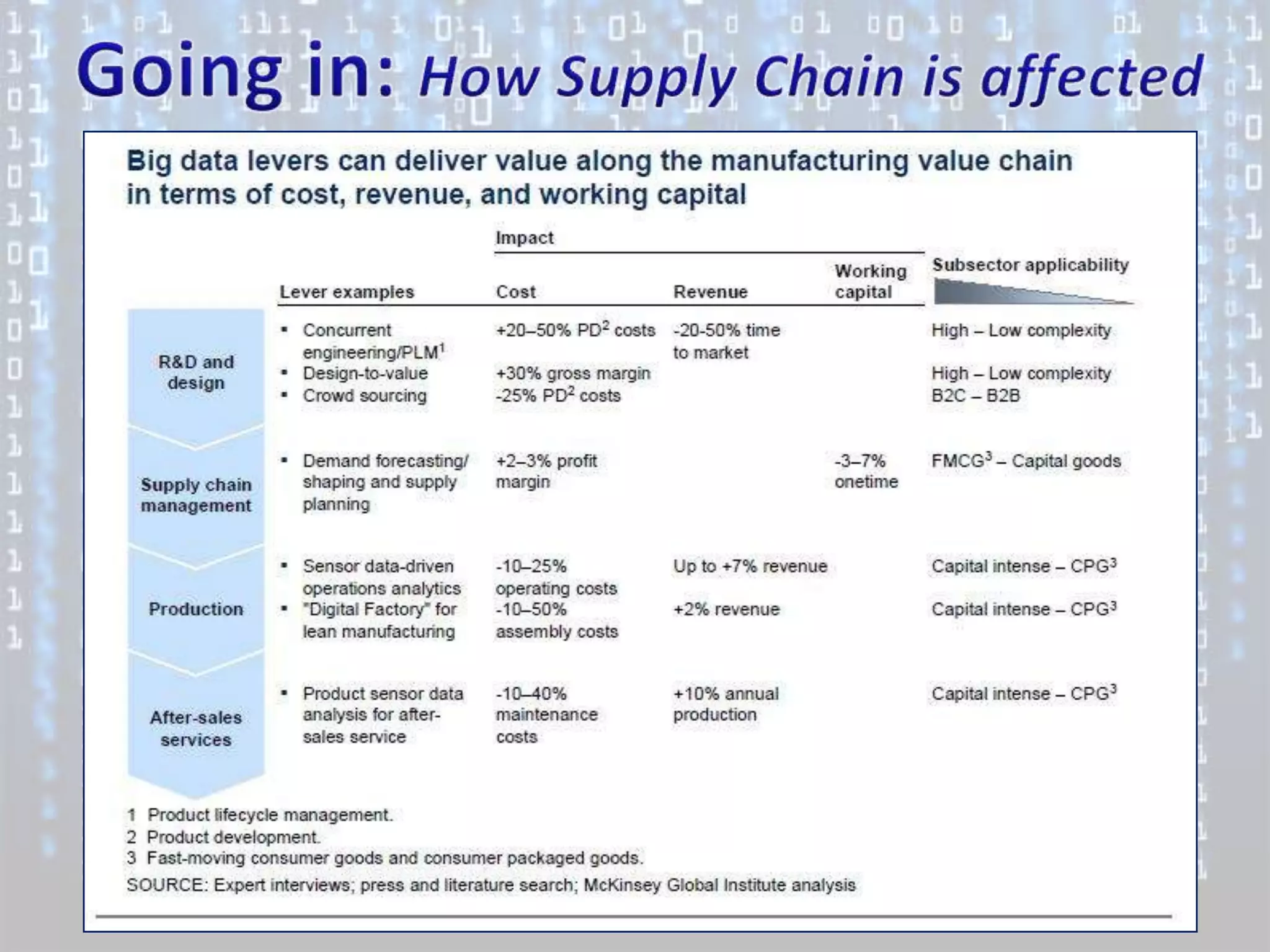


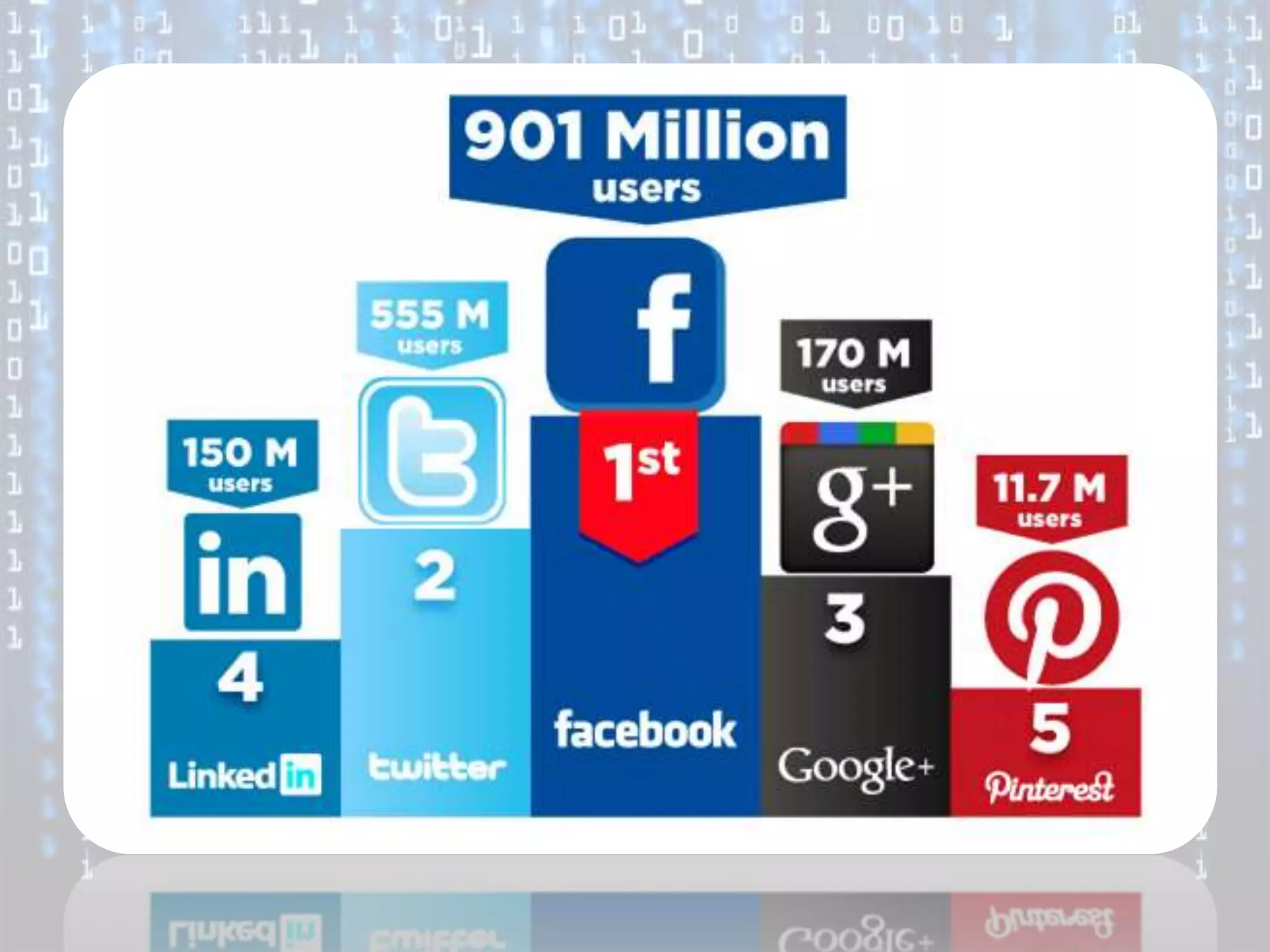

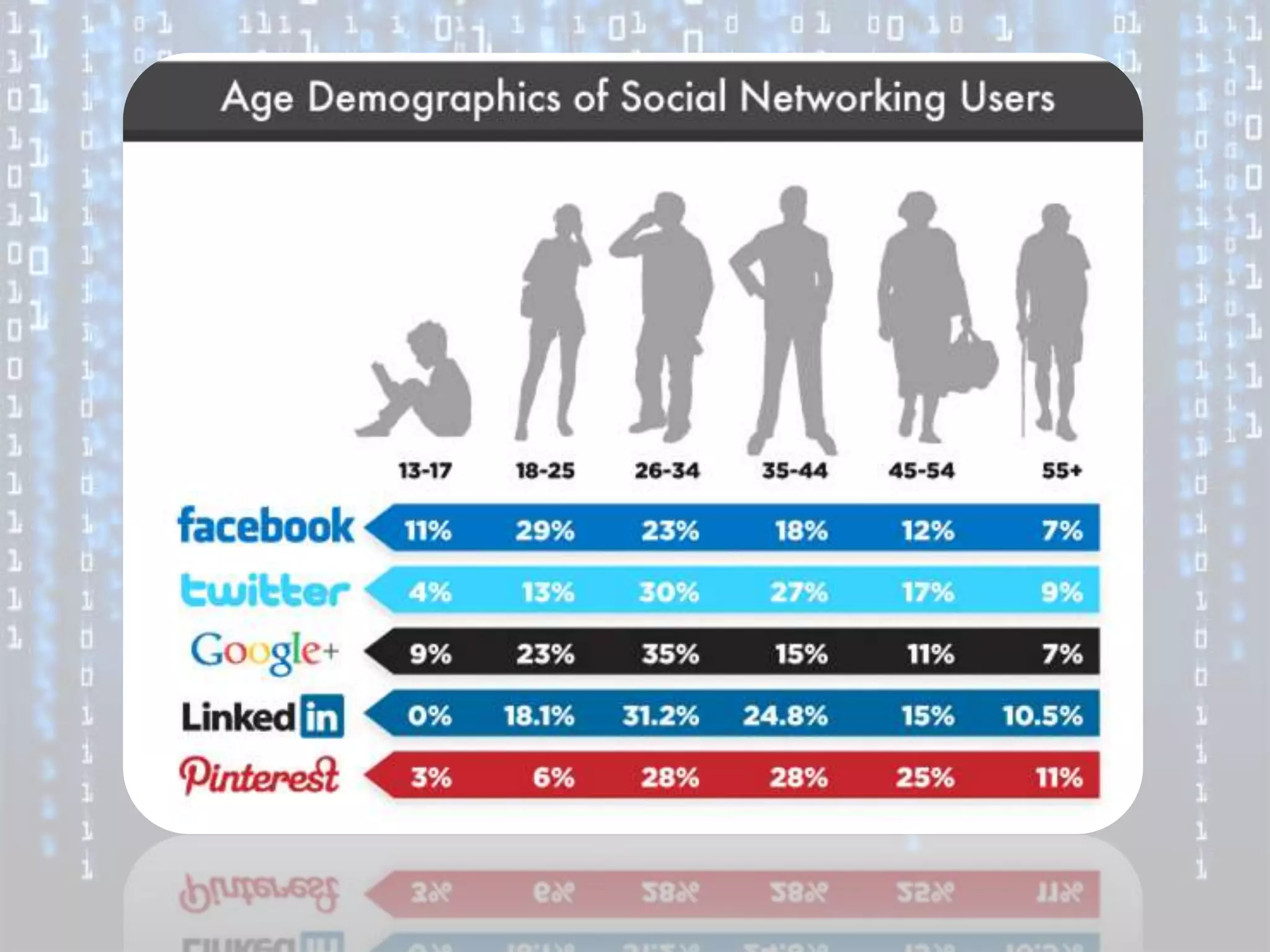
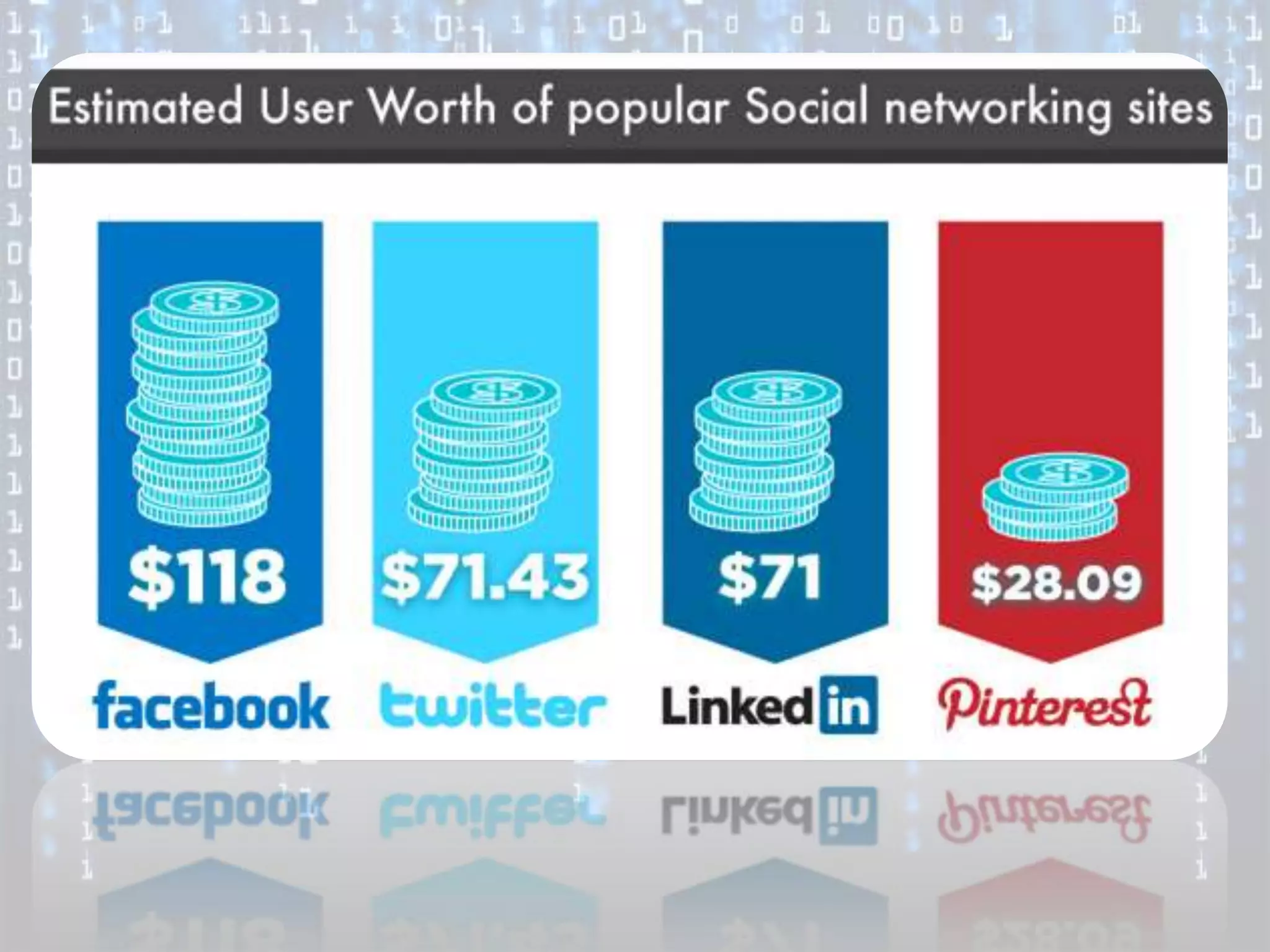
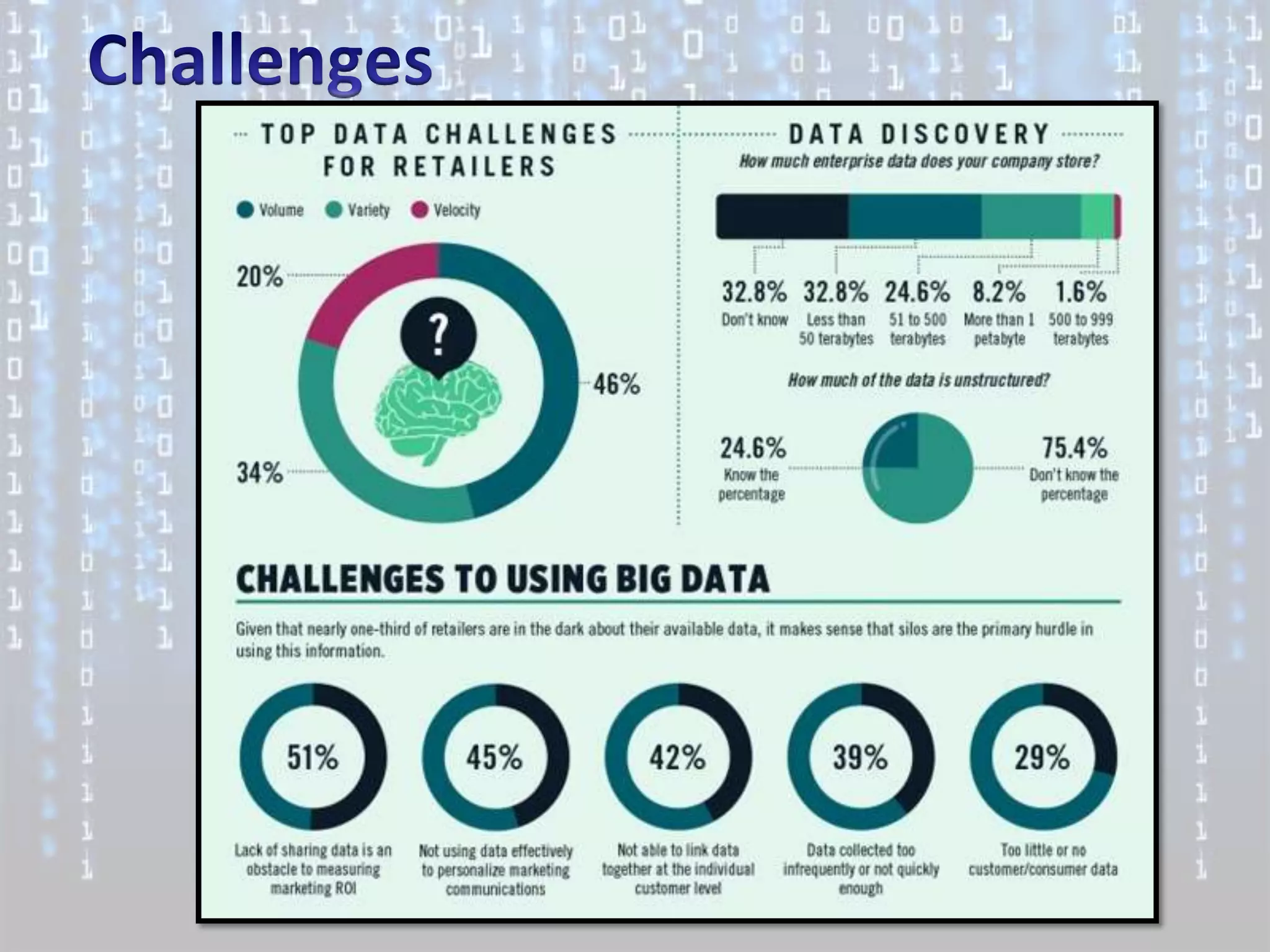
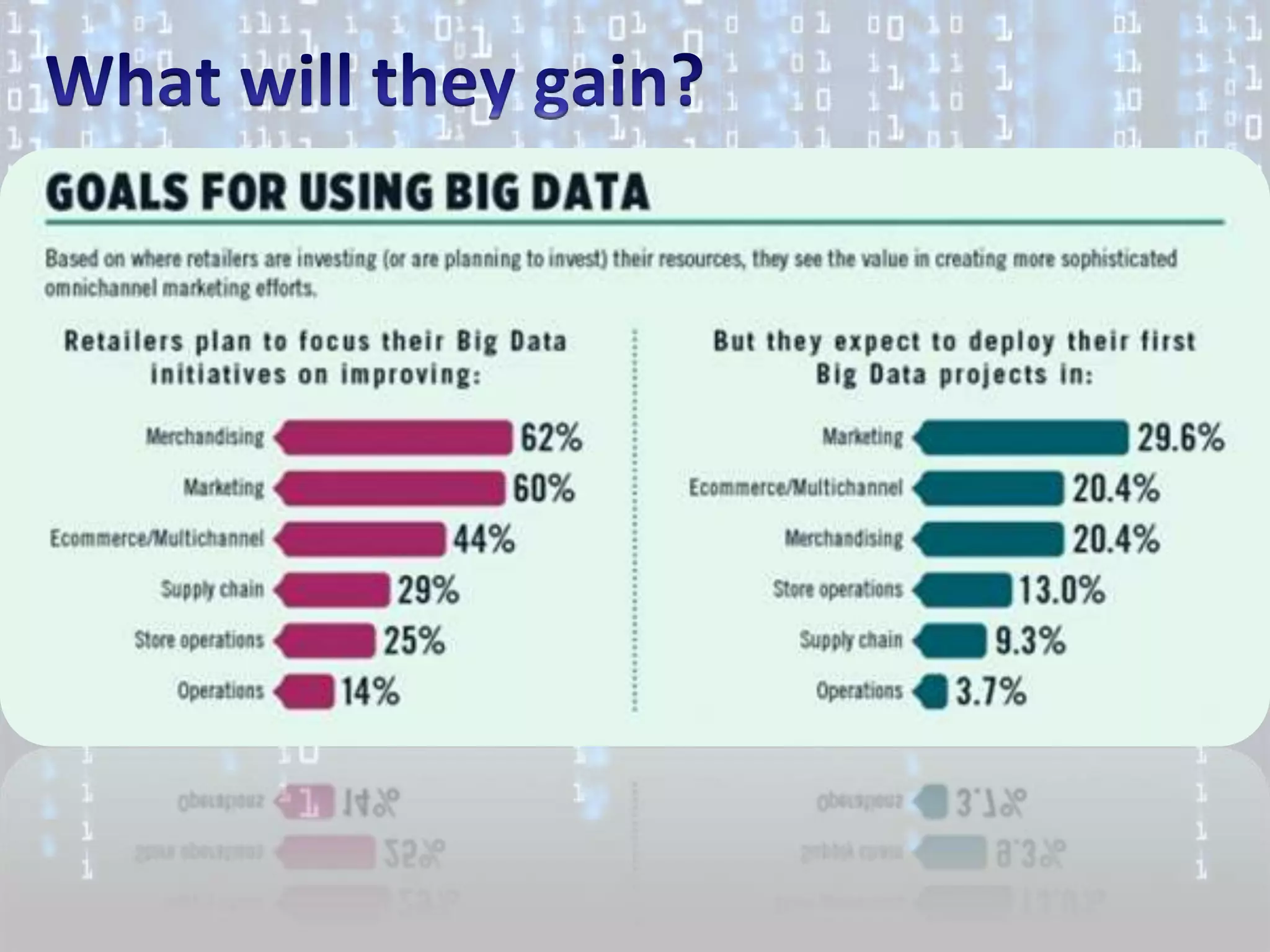



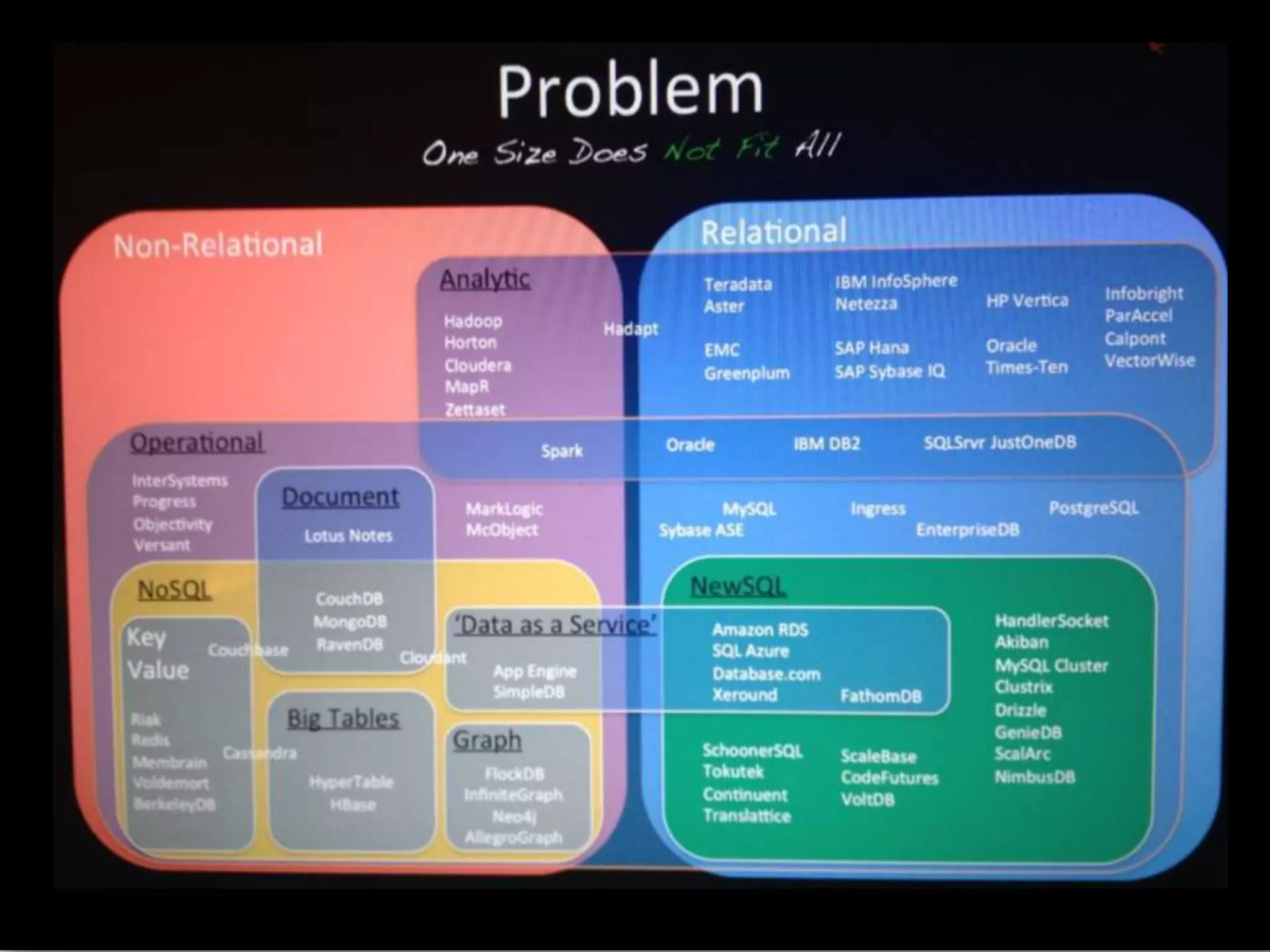




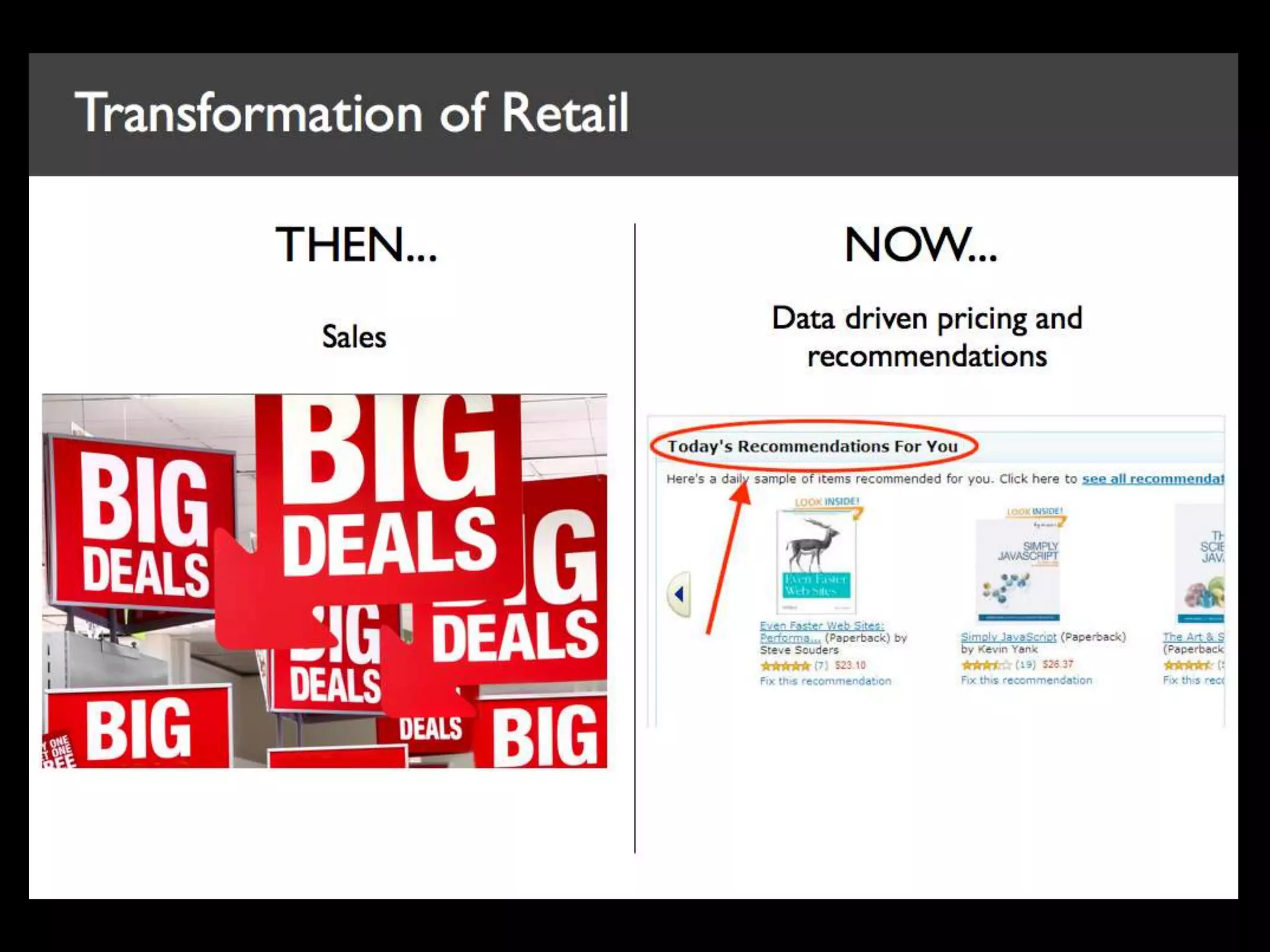


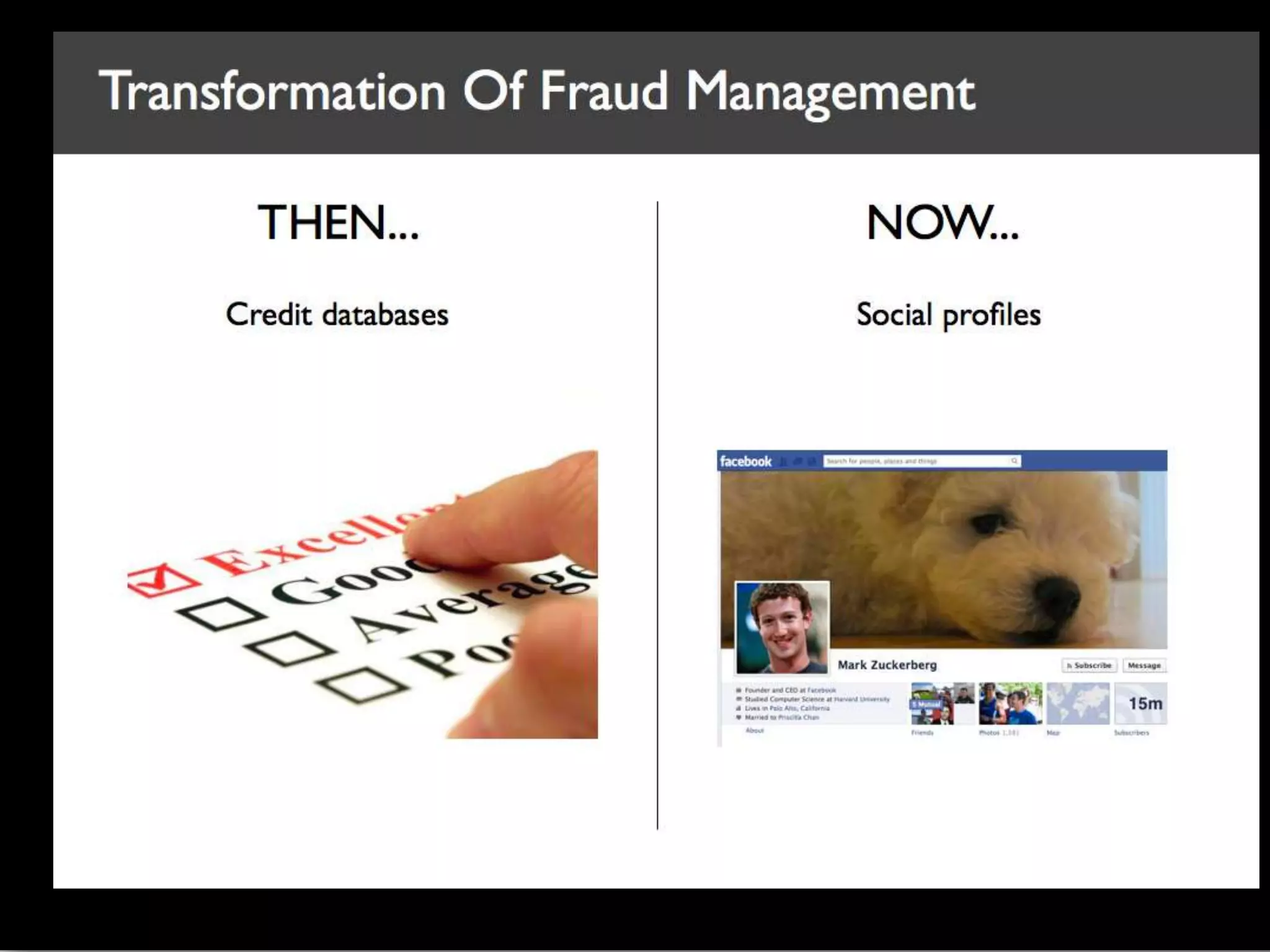






Big data is characterized by 3 V's - volume, velocity, and variety. It refers to large and complex datasets that are difficult to process using traditional database management tools. Key technologies to handle big data include distributed file systems, Apache Hadoop, data-intensive computing, and tools like MapReduce. Common tools used are infrastructure management tools like Chef and Puppet, monitoring tools like Nagios and Ganglia, and analytics platforms like Netezza and Greenplum.



































































