Downloaded 73 times








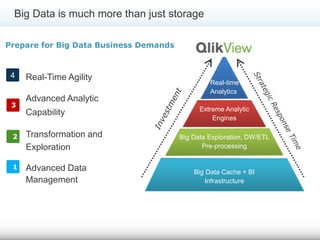

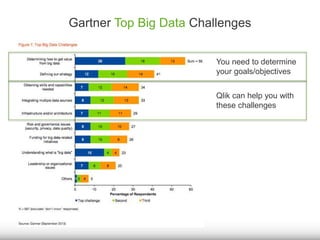

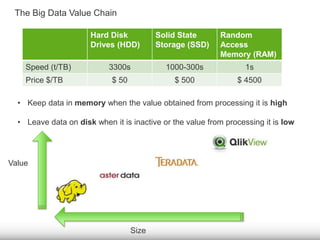




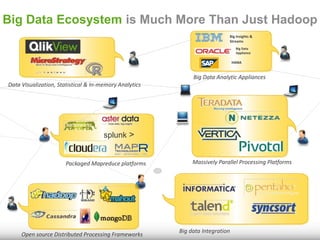

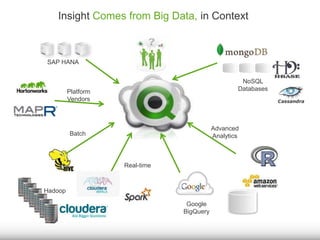

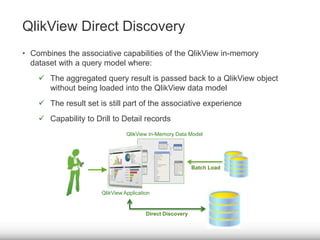
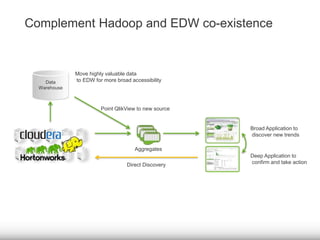
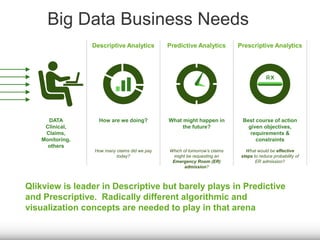
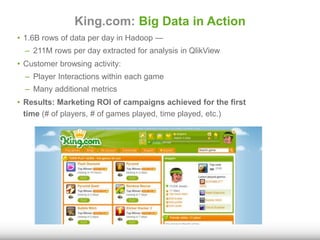


The document discusses the significance of big data for business users, emphasizing the challenges and solutions to effectively harness it. It outlines Qlik's approach to alleviating the big data bottleneck, enabling users to leverage insights without the need for extensive technical skills. Additionally, it highlights the evolution of big data technologies, potential use cases across various industries, and the importance of context and relevance in deriving value from data.
















![Competitive edgewithmongod bandpentaho_2014sep_v3[1]](https://cdn.slidesharecdn.com/ss_thumbnails/competitiveedgewithmongodbandpentaho2014sepv31-141022155232-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)

















































