Download as PPSX, PPTX




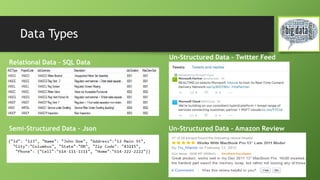

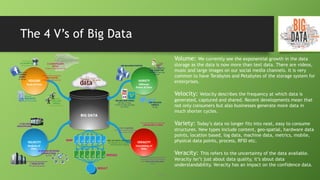









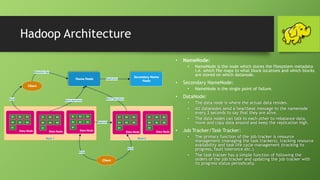

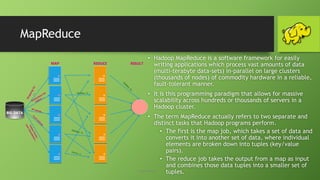








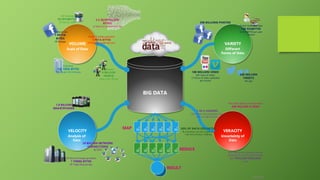



This document provides an overview of big data and Hadoop. It defines big data as large volumes of structured, semi-structured and unstructured data that is growing exponentially and is too large for traditional databases to handle. It discusses the 4 V's of big data - volume, velocity, variety and veracity. The document then describes Hadoop as an open-source framework for distributed storage and processing of big data across clusters of commodity hardware. It outlines the key components of Hadoop including HDFS, MapReduce, YARN and related modules. The document also discusses challenges of big data, use cases for Hadoop and provides a demo of configuring an HDInsight Hadoop cluster on Azure.



































































