Downloaded 13 times



![Why Big Data ?
• Growth of Big Data is needed because of
– Increase of storage capacities
– Increase of processing power
– Availability of data(different data types)
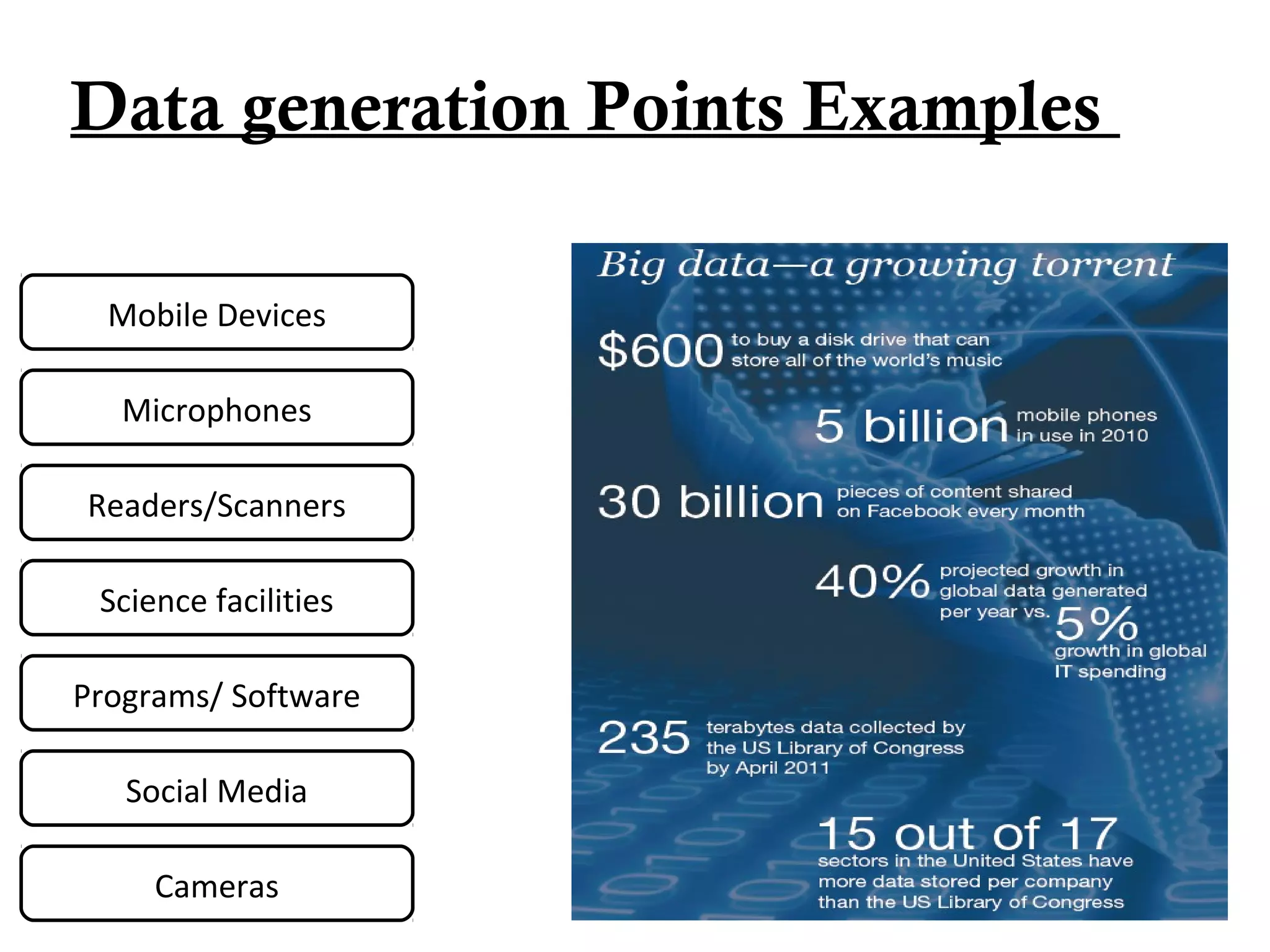
– Every day we create 2.5 Million TB[quintillion bytes(1
Quintillionbyte= 1 Exabyte=1000Petabytes where 1
Petabyte=1000 TB)] of data; 90% of the data in the
world today has been created in the last two years
alone.
• FB generates 10TB daily
• Twitter generates 7TB of data Daily
• IBM claims 90% of today’s stored data was generated in
just the last two years.](https://image.slidesharecdn.com/dataanalyticspresentationbydr-170117082653/75/Data-analytics-its-Trends-4-2048.jpg)

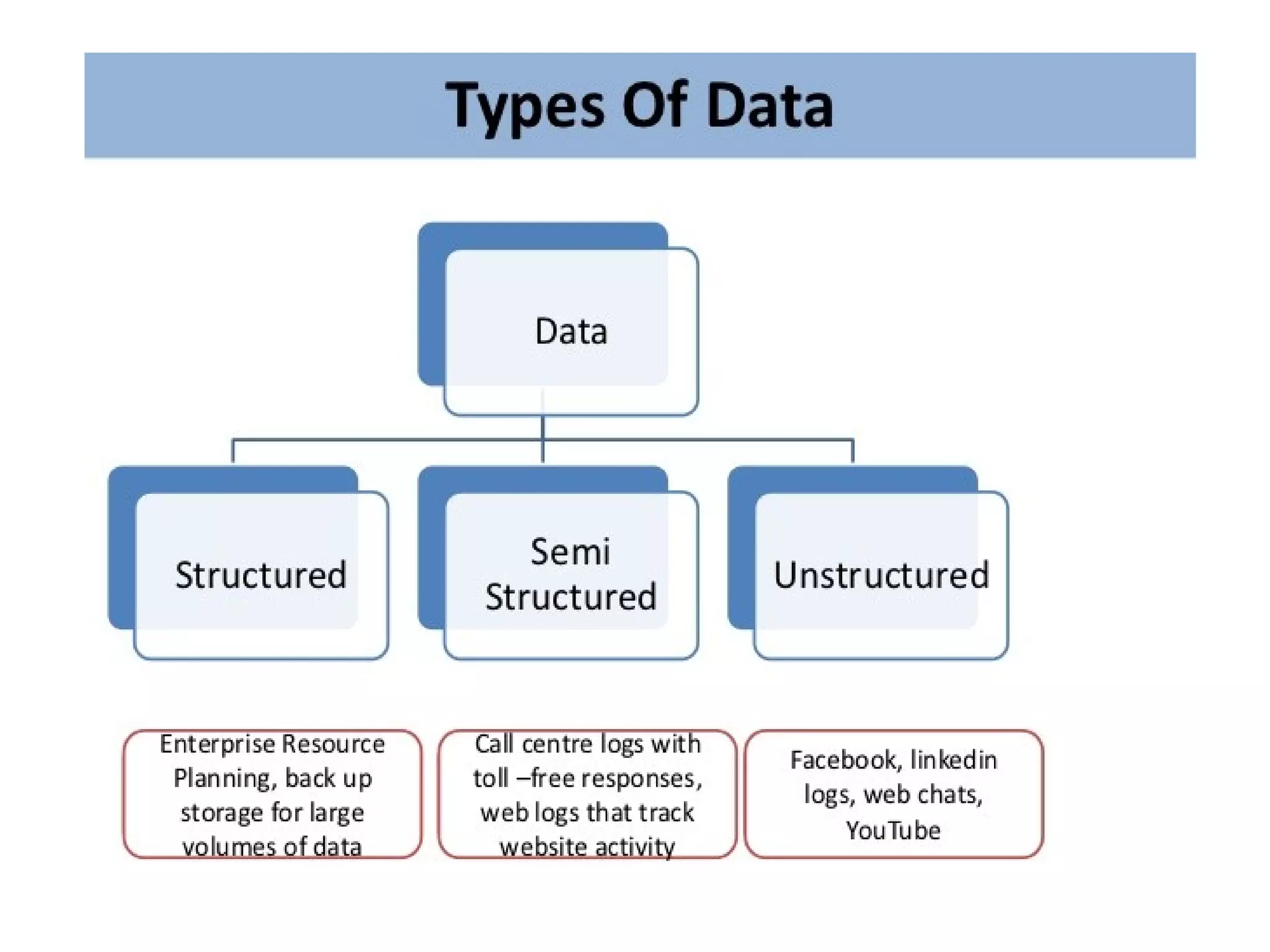
![Some Definitions
• Big data is an evolving term that describes any
voluminous amount of structured,
semi structured and unstructured data that
has the potential to be mined for information.
[Ref:
Strata + Hadoop World 2016: Hadoop and Spark in spotlight]](https://image.slidesharecdn.com/dataanalyticspresentationbydr-170117082653/75/Data-analytics-its-Trends-6-2048.jpg)




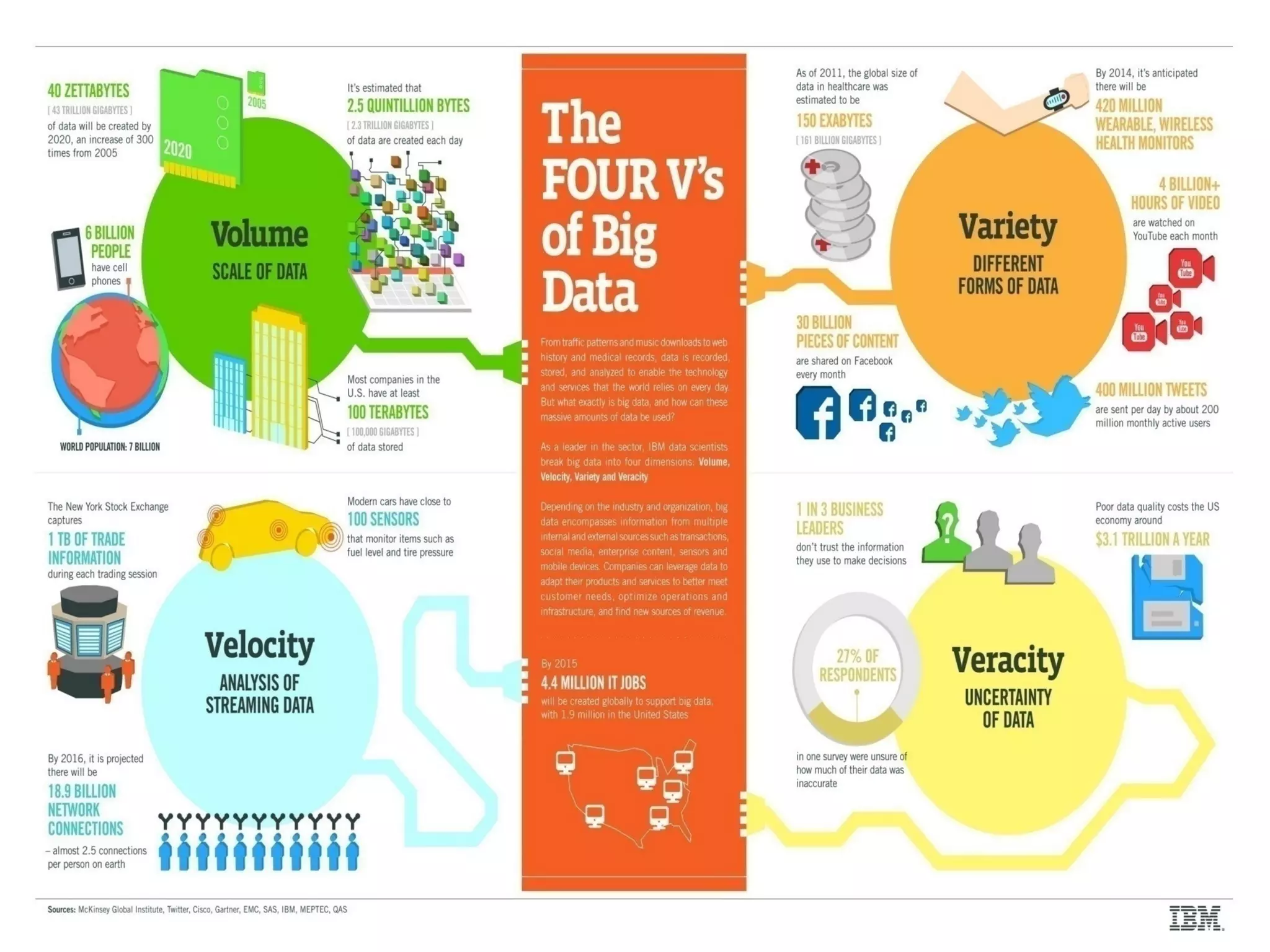
![Characteristics of Big data
Volume: (Data Quantity)
• Twitter generates about 80 MB per second.
• Facebook generates 10 TB data per day.
• Black box data: Single flight generates nearly 10 TB of data per
every ½ an hour.
• Twitter generates of about 80 MB every second.
Velocity: (Data Speed) ebay analyzes 5 million transactions per day.
• Finally, velocity refers to the speed at which big data must be
analyzed. Velocity is also meaningful, as big data analysis expands
into fields like machine learning and artificial intelligence, where
analytical processes mimic perception by finding and using patterns
in the collected data.
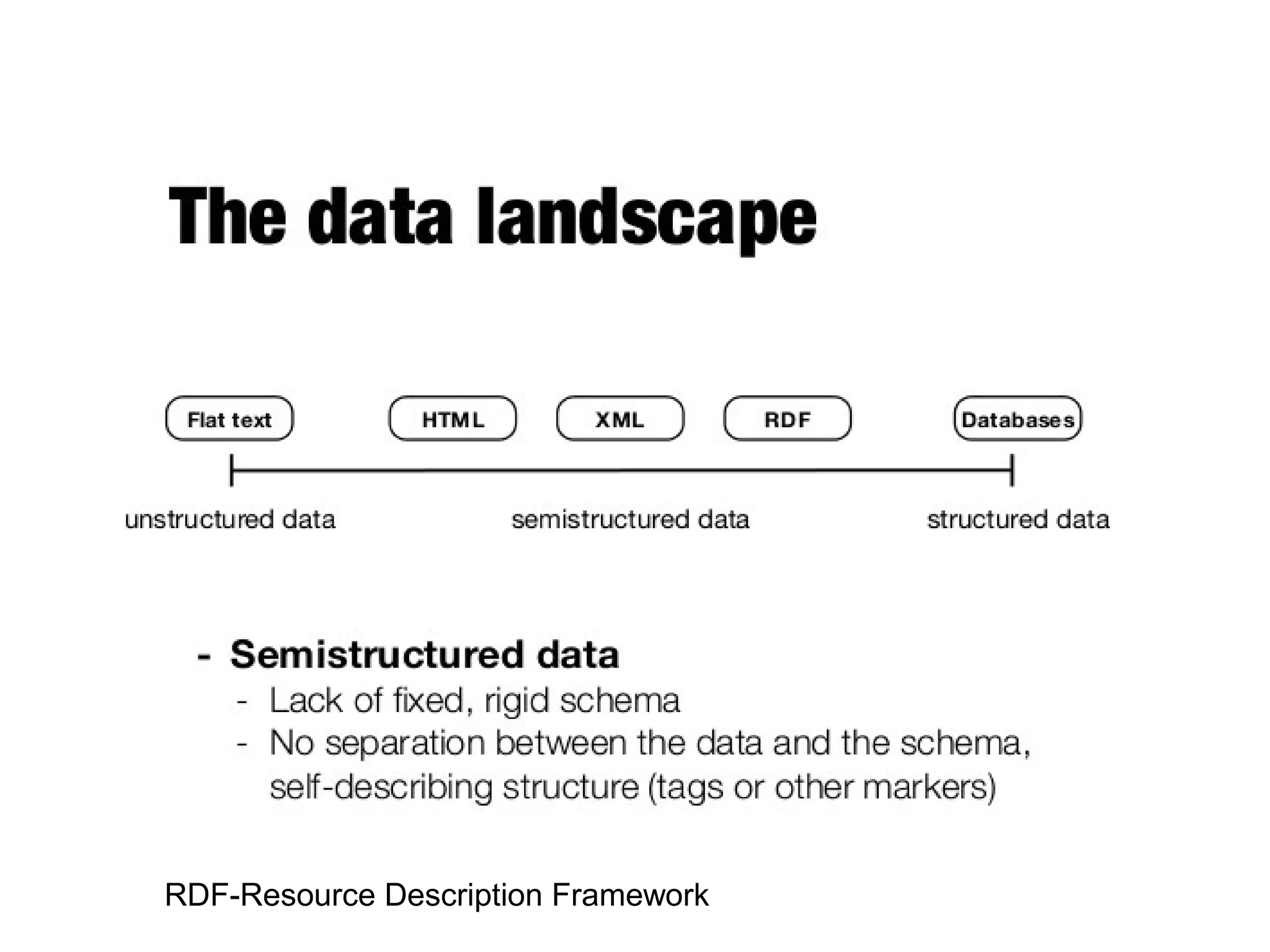
Variety: (Data Types) Bigdata includes data from e-commerce sites,
health care data, education, stock exchange, banking etc…..
Varying in Time:
• [http://searchcloudcomputing.techtarget.com/definition/big-data-Big-Data]](https://image.slidesharecdn.com/dataanalyticspresentationbydr-170117082653/75/Data-analytics-its-Trends-13-2048.jpg)












![Difference between Big data & Data Science.
• [http://www.kdnuggets.com/2015/07/data-science-big-data-different-beasts.html]
• Creating artifact from the ore requires the tools, craftmanship and science.
Same is the case of big data and data science, here we present the
distinguishing factors between the ore and the artifact.
• Data Science looks to create models that capture the
underlying patterns of complex systems, and codify those models into
working applications. Big Data looks to collect and manage large
amounts of varied data to serve large-scale web applications and vast
sensor networks.
Although both offer the
potential to produce value
from data, the fundamental
difference between Data
Science and Big Data can be
summarized in one
statement:
-Collecting Does Not
Mean Discovering](https://image.slidesharecdn.com/dataanalyticspresentationbydr-170117082653/75/Data-analytics-its-Trends-29-2048.jpg)


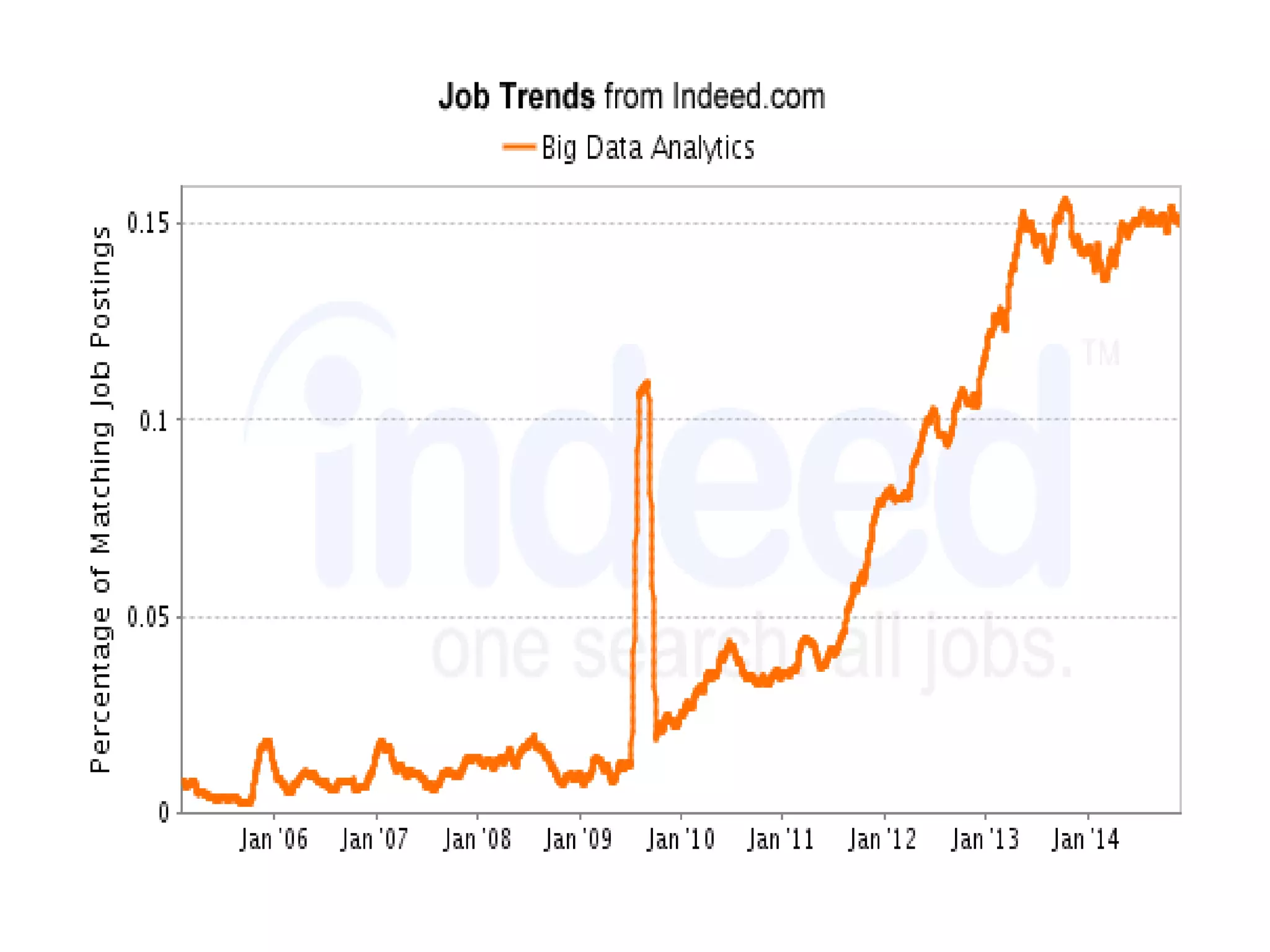
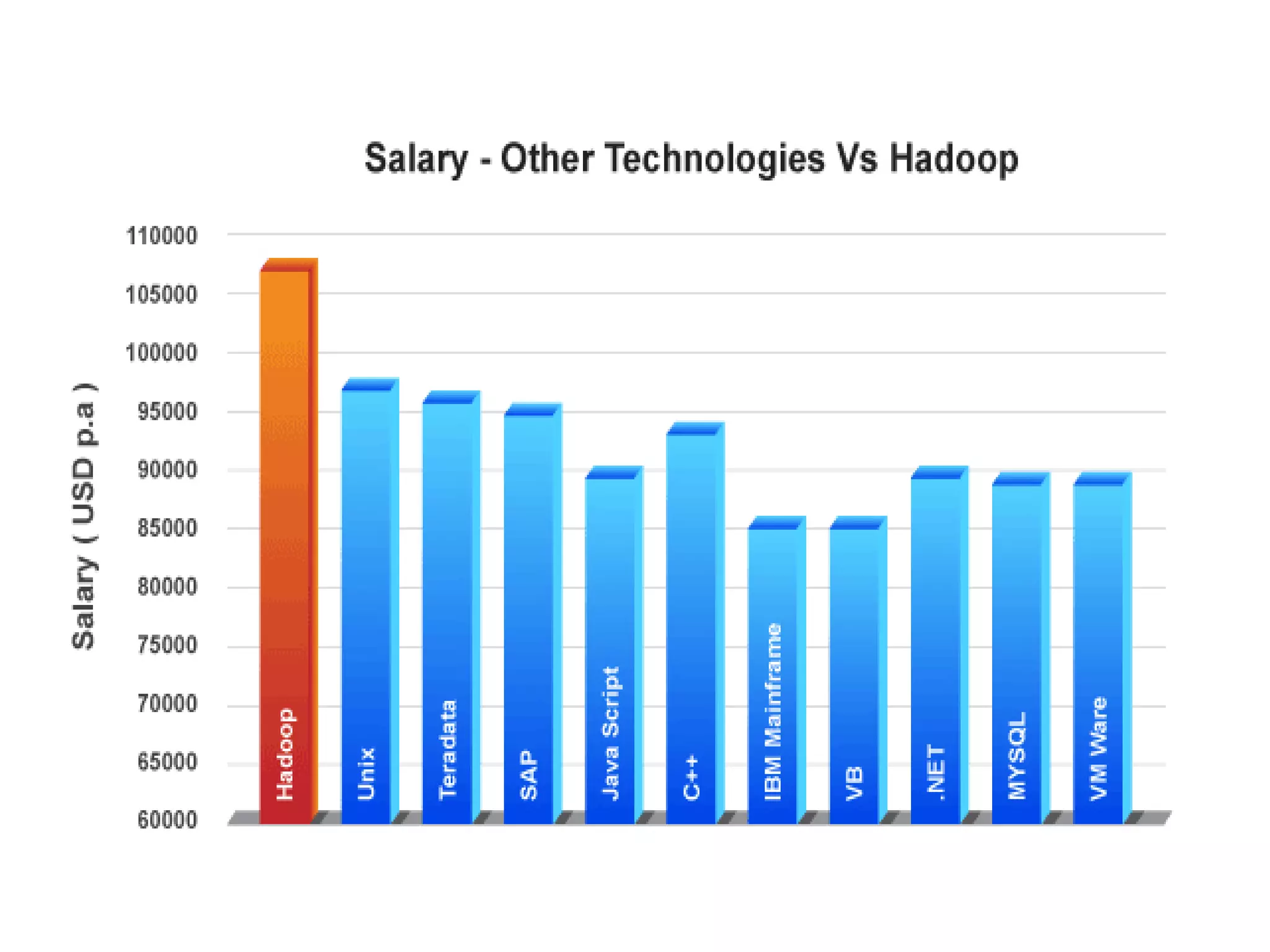



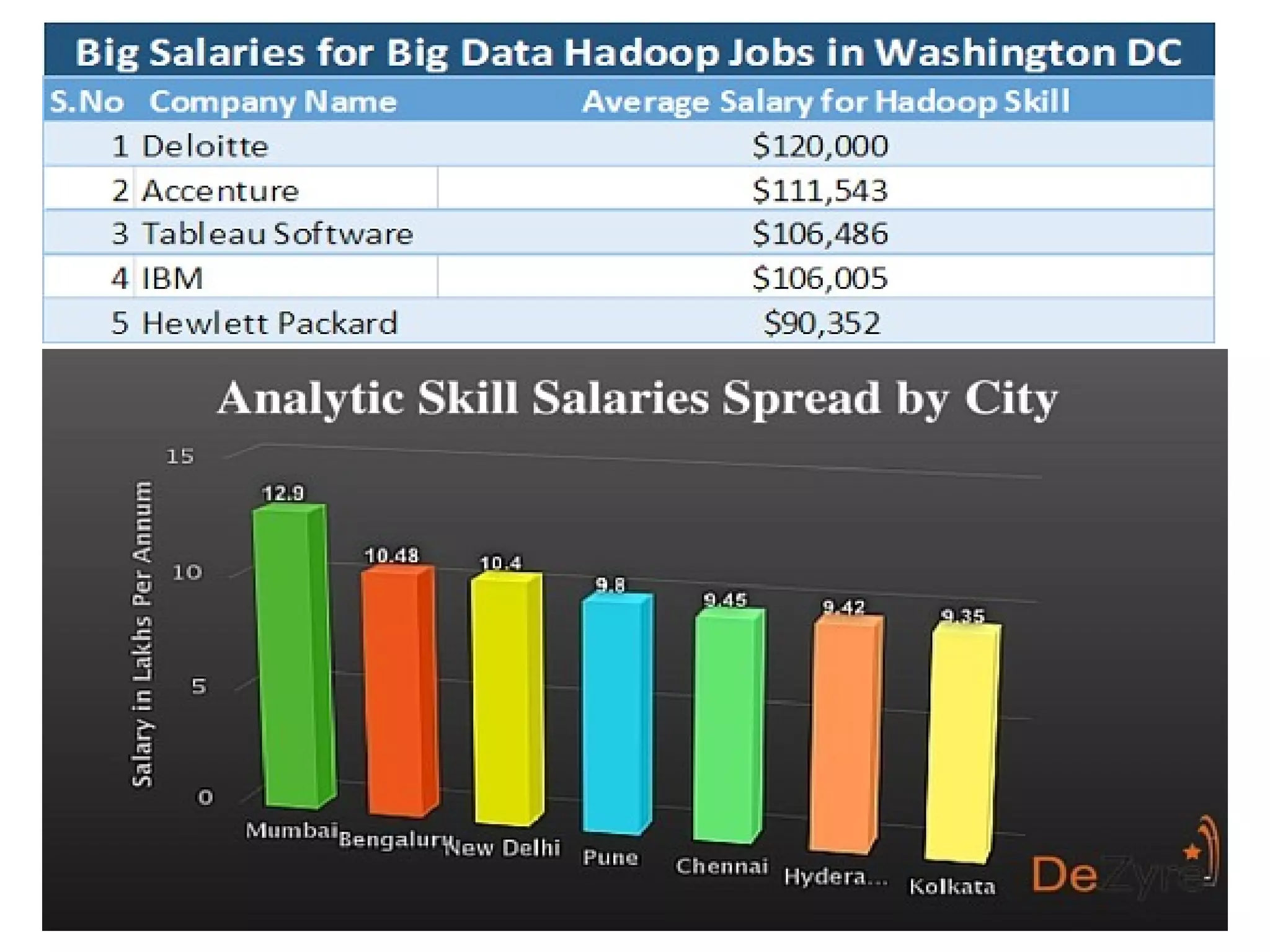

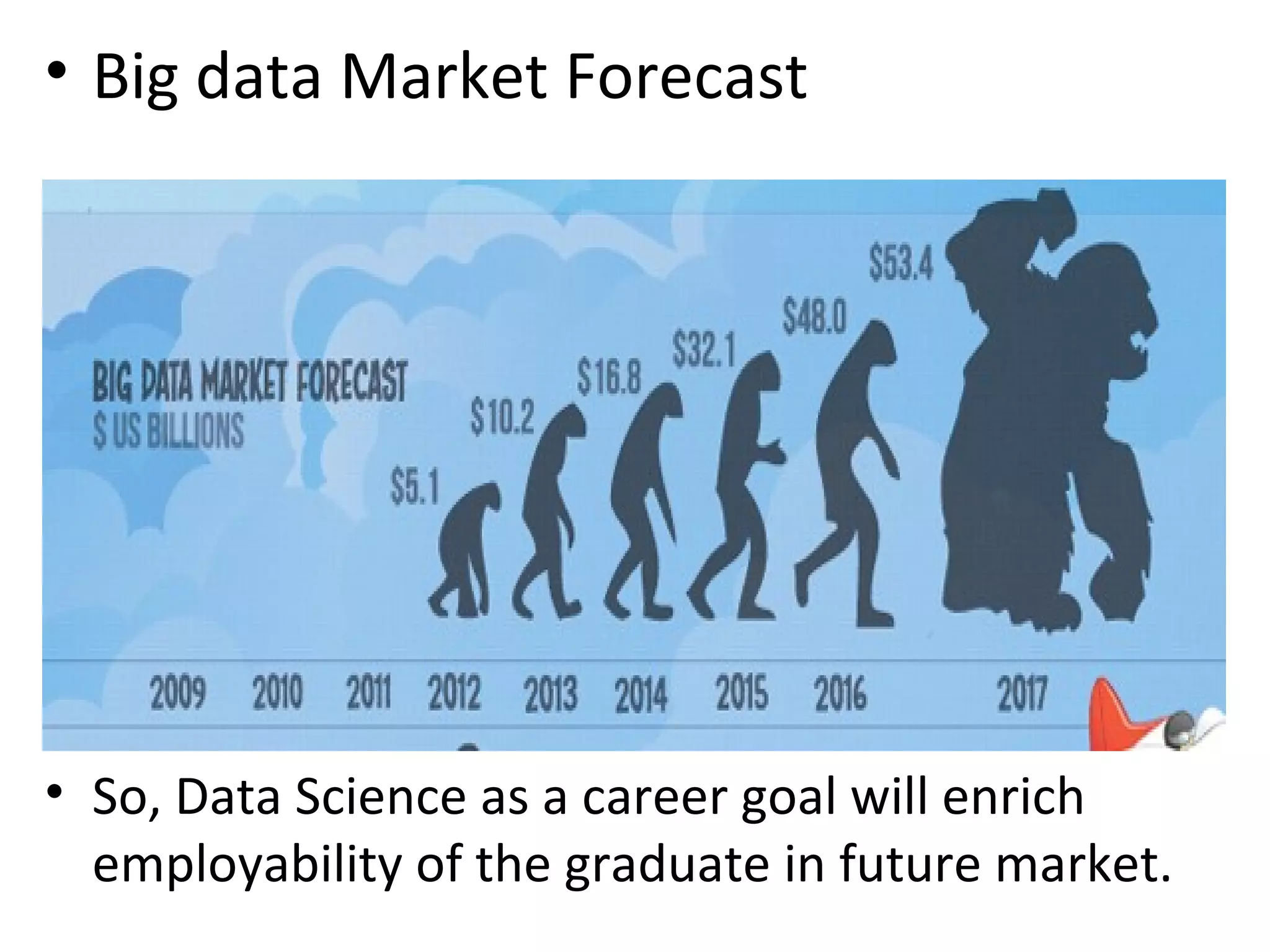



Big Data Analytics & Trends Presentation discusses what big data is, why it's important, definitions of big data, data types and landscape, characteristics of big data like volume, velocity and variety. It covers data generation points, big data analytics, example scenarios, challenges of big data like storage and processing speed, and Hadoop as a framework to solve these challenges. The presentation differentiates between big data and data science, discusses salary trends in Hadoop/big data, and future growth of the big data market.













![Data Analytics Life Cycle [EMC² - Data Science and Big data analytics]](https://cdn.slidesharecdn.com/ss_thumbnails/bdalifecycle-slideshare-211028070344-thumbnail.jpg?width=640&height=640&fit=bounds)





















































