Download as PDF, PPTX








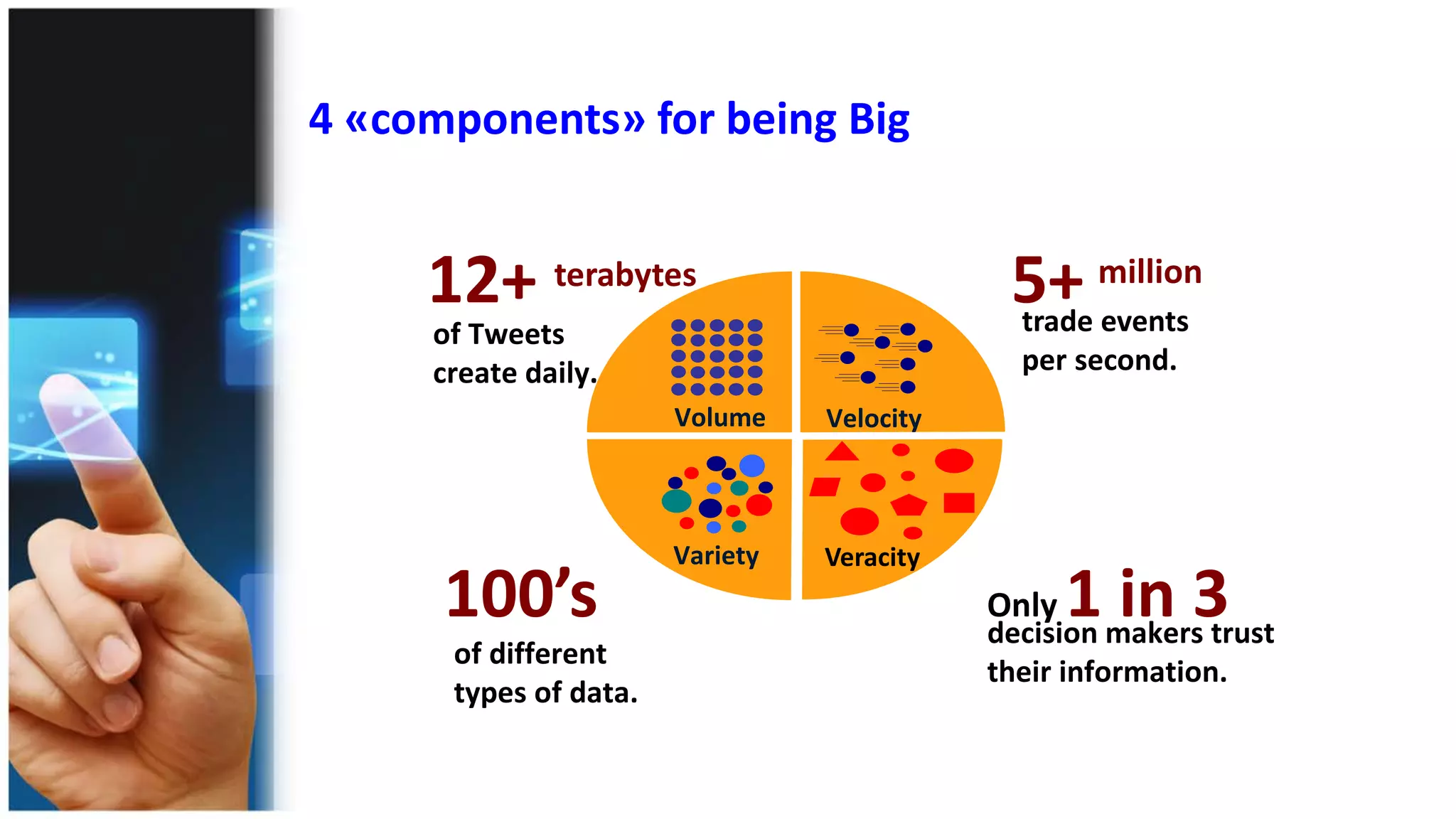


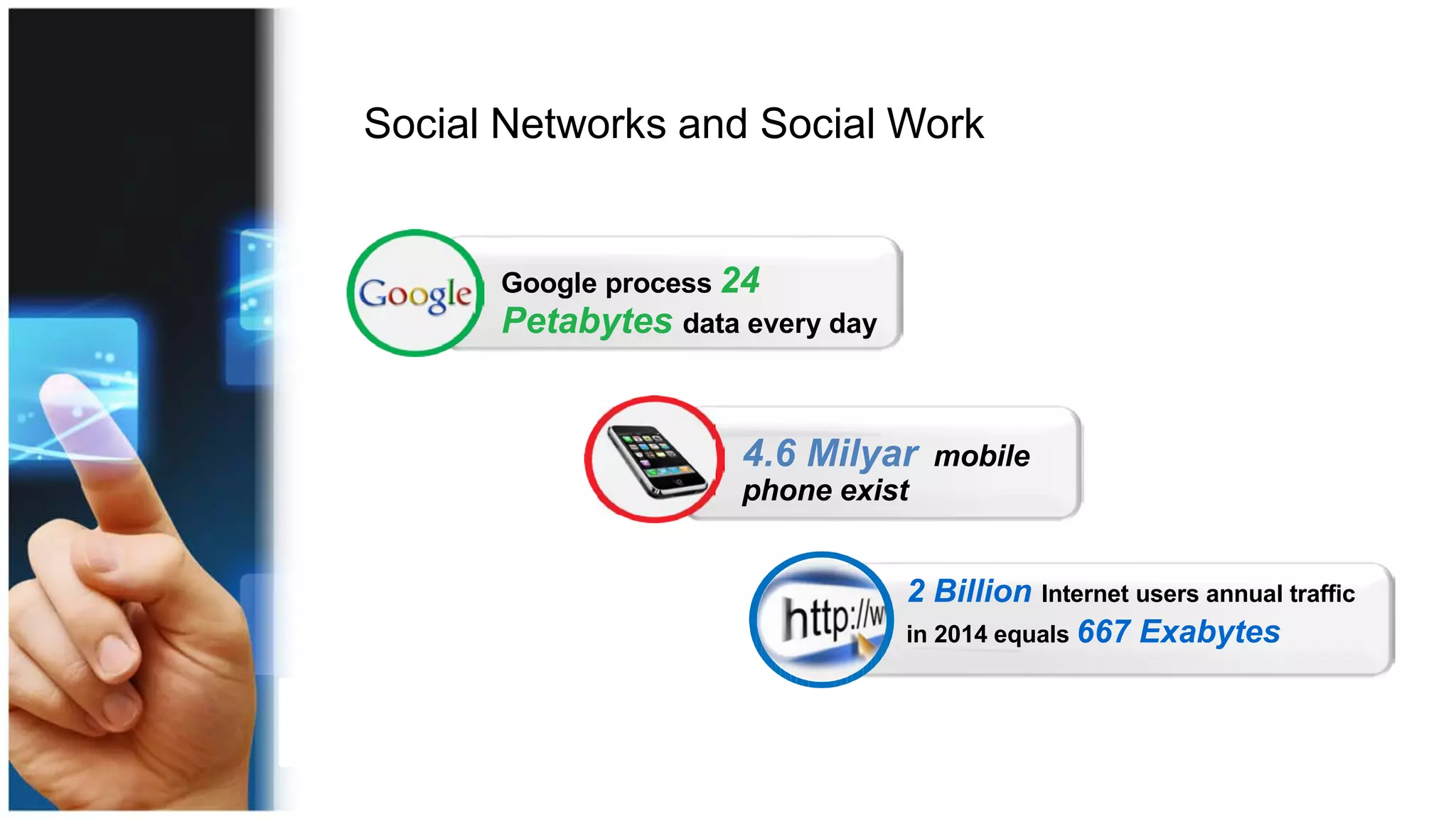





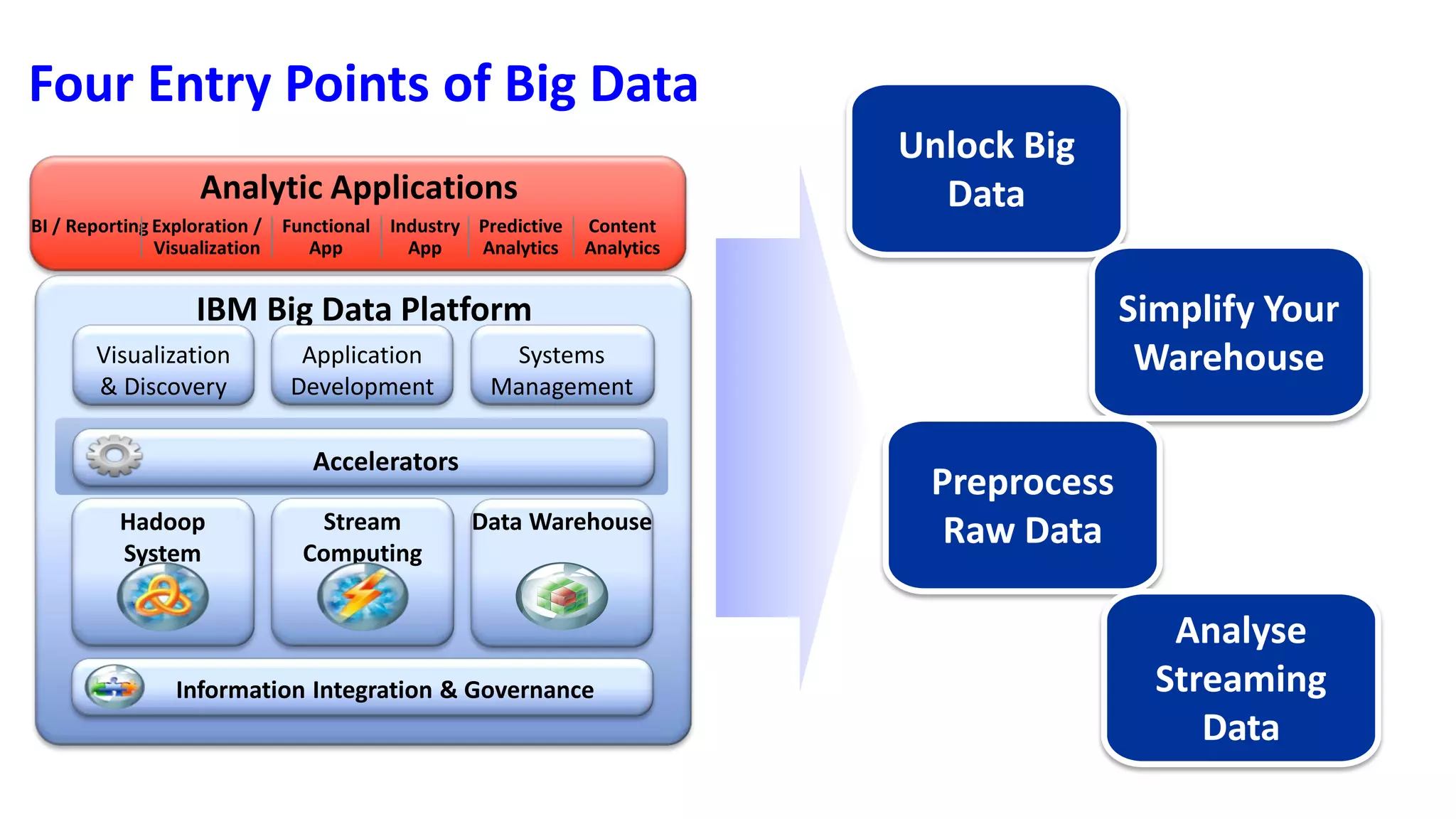









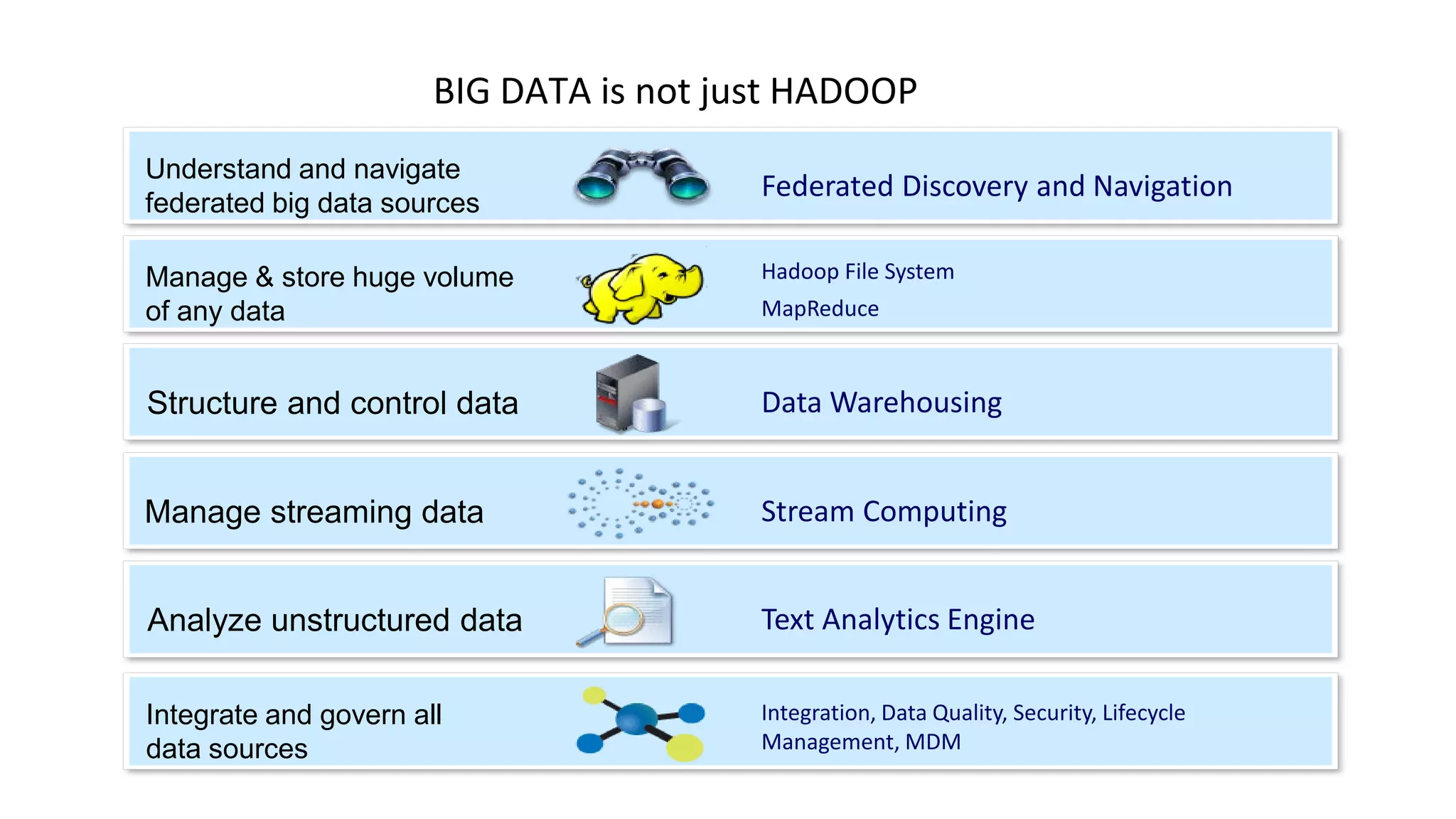



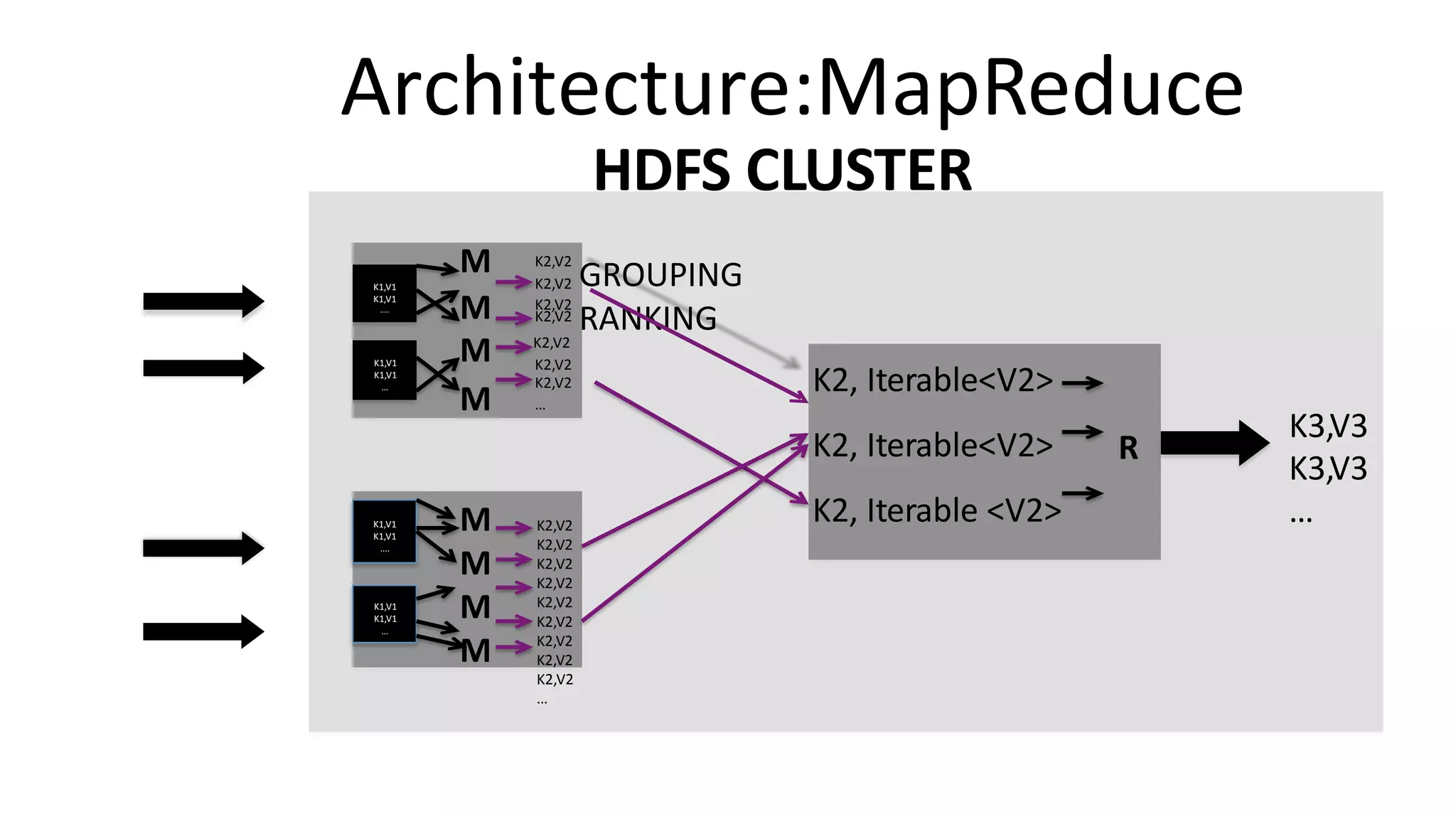










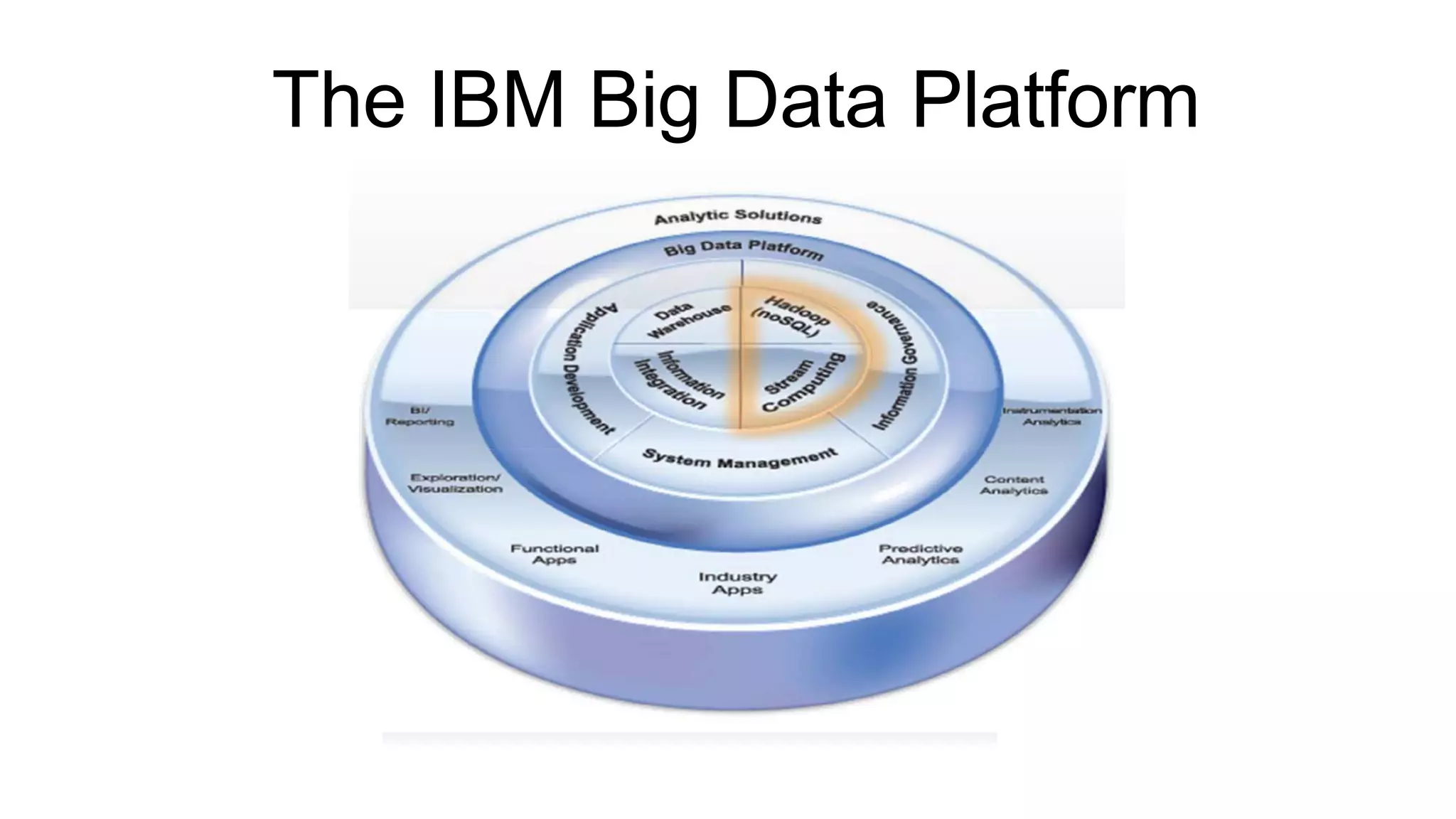
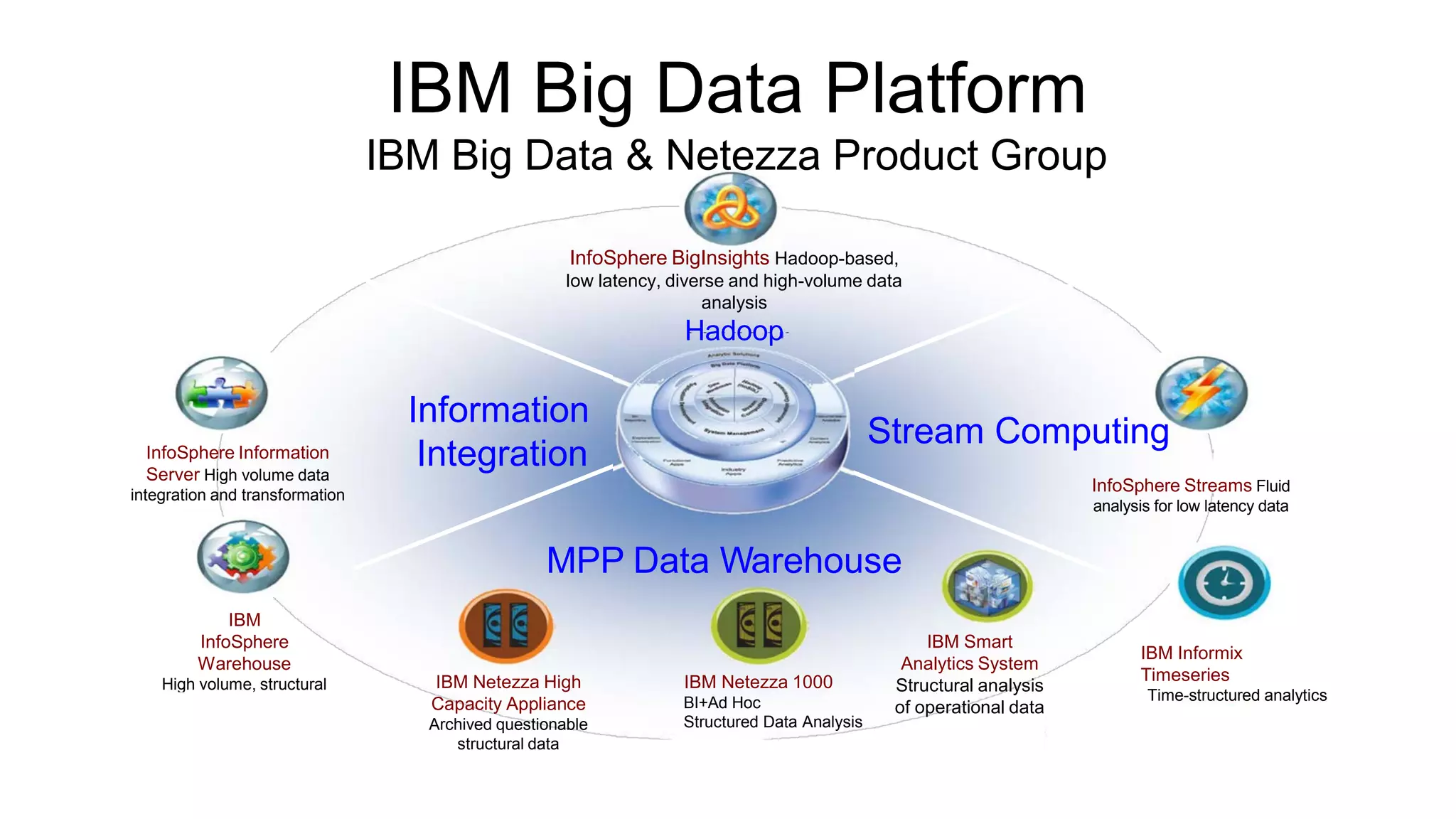
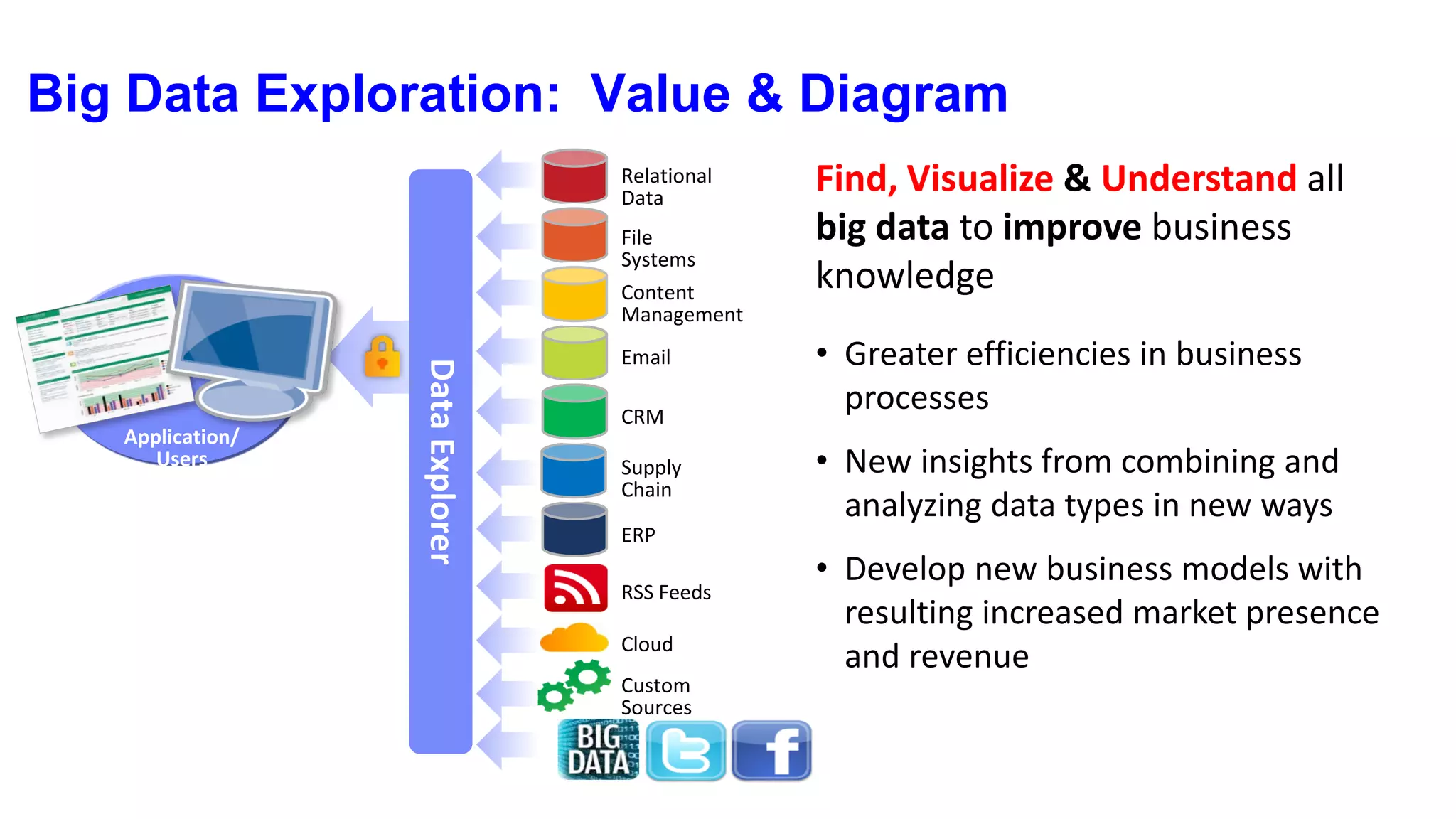
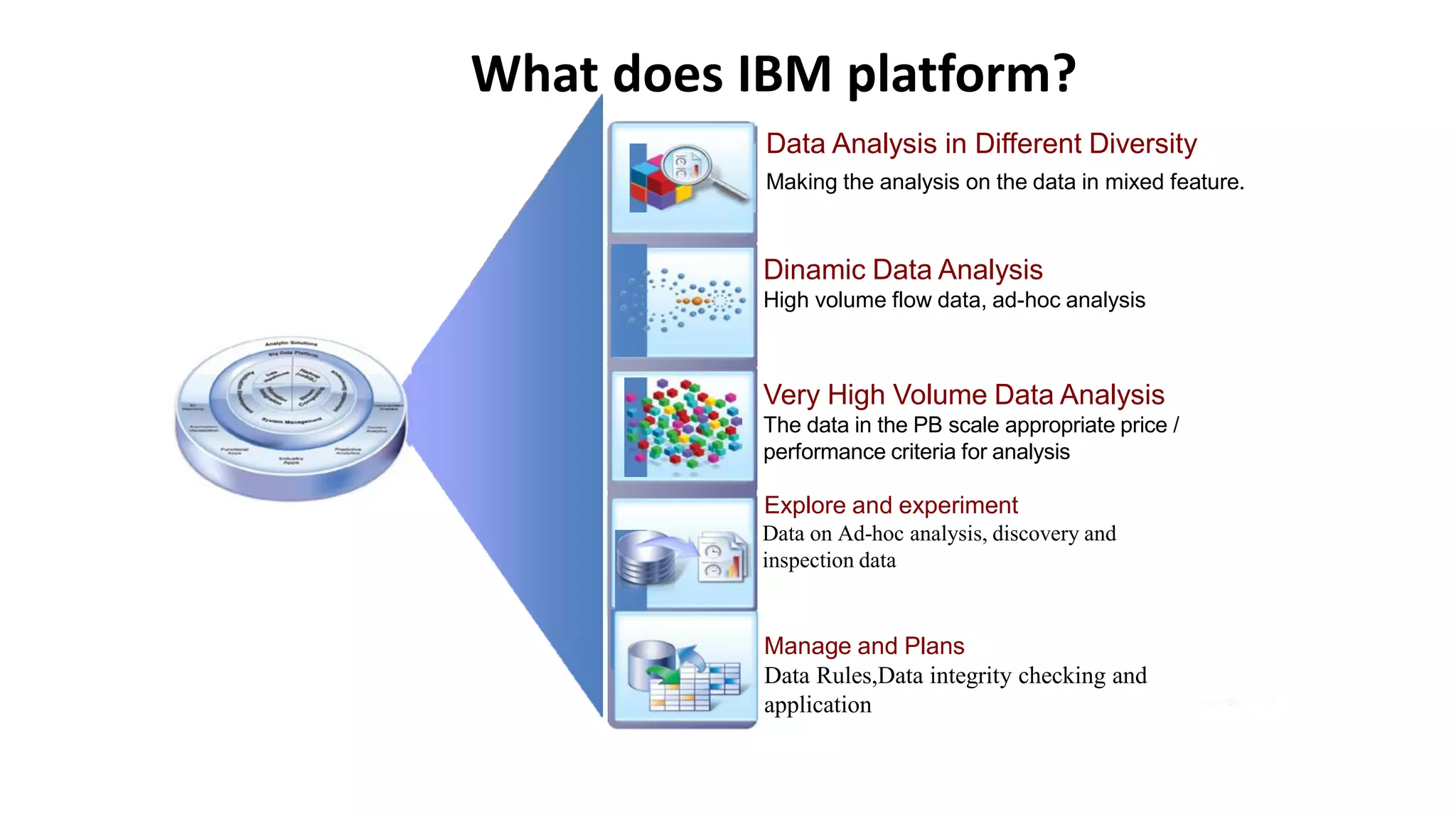


Understanding Big Data summarizes big data and popular big data technologies. It discusses how big data is generated from various sources and is too large to be processed by traditional databases. Popular technologies like Hadoop, HDFS, MapReduce, Hive, Pig, HBase, and Mahout are able to collect, store, process, and analyze big data. Companies are using big data to gain insights from customer data, optimize operations, prevent fraud, and make recommendations.






















































































