Downloaded 60 times




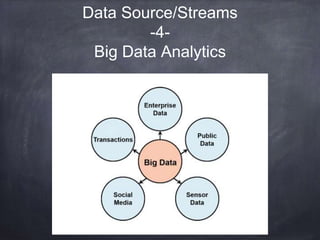







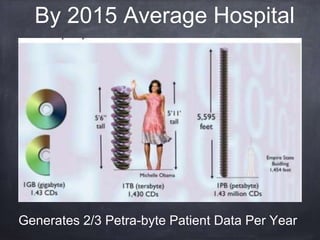


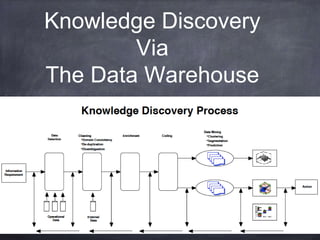


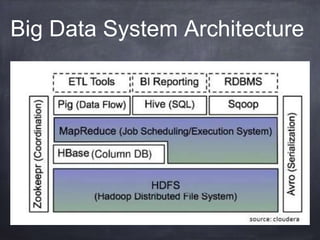

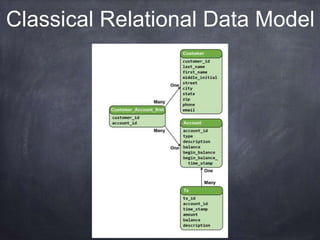
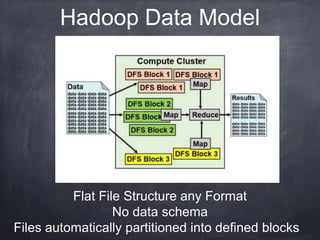
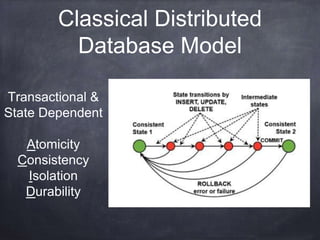
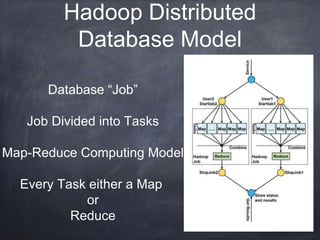

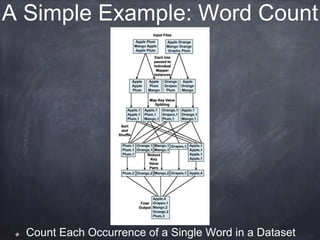
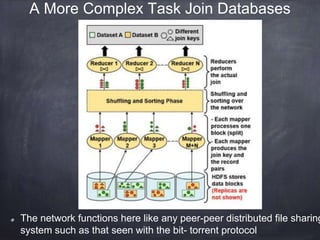
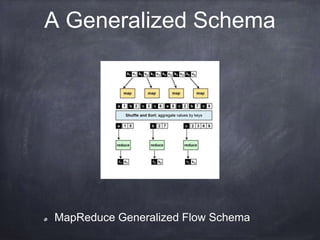
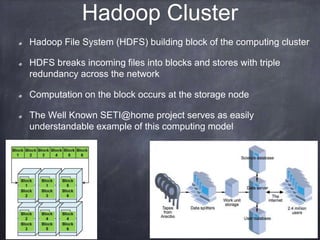

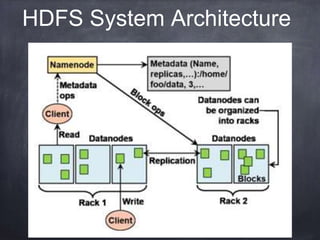

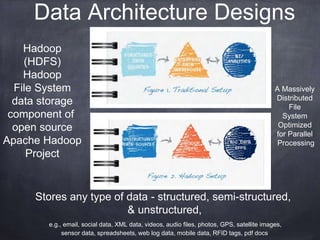
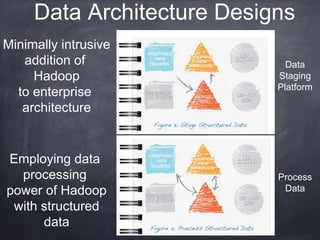
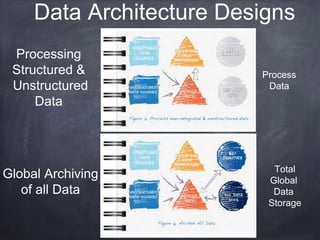
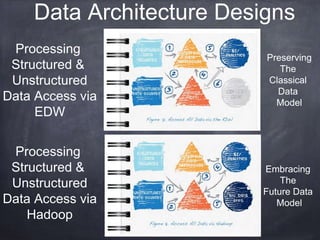




The document provides an introductory tutorial on 'big data' in medicine and healthcare, defining it as vast amounts of structured and unstructured data that can be analyzed for insights. It discusses the dimensions of big data, including volume, velocity, and variety, and contrasts traditional data warehouses with big data approaches using frameworks like Hadoop. Challenges and applications in the field are highlighted, as well as the need for new processing methods to gain meaningful insights from complex data sources.











































































































