Downloaded 30 times





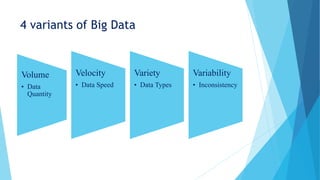












This presentation introduces big data and data mining. Big data refers to extremely large data sets that cannot be processed by traditional software. Data mining is the process of discovering patterns in large data sets using machine learning, statistics, and database systems. The presentation discusses key facts about the growth of data, examples of big data sources like Facebook and Google, challenges of big data like hardware limitations, and solutions like parallel computing. Common big data mining tools are also introduced, including Hadoop, Apache S4, and Storm. Applications of big data and data mining are highlighted in various domains like healthcare, public sector, and biology.






















































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)







