Download to read offline












![References
[1] S. Kaisler, F. Armour and J. A. Espinosa, "Big Data: Issues and Challenges Moving Forward," in 46th
Hawaii International Conference on System Sciences, Hawaii, 2013.
[2] " www.studymafia.org," [Online].
[3] D. J. S. Kiran, M. Sravanthi, K. Preethi and M. Anusha, "Recent Issues and Challenges on Big Data in
Cloud Computing," International Journal of Computer Science And Technology(IJCST), vol. Vol. 6, no.
Issue 2, April - June 2015.
[4] " (http://www.aip.org/fyi/2010/)," American Institute of Physics (AIP) College Park, MD , 2010.
[Online].
[5] D. Borthakur, The Hadoop Distributed File System Architecture and Design, 2007.
[6] A. Johnson , H. P.H, V. Paul and M. S. P.N, "Big Data Processing Using Hadoop MapReduce,"
International Journal of Computer Science and Information Technologies,(IJCSIT), vol. Vol. 6 (1), pp.
127-132, 2015.
[7] "Hadoop," ”http://wiki.apache.org/hadoop/PoweredBy, [Online]. Available:
http://wiki.apache.org/hadoop/PoweredBy.
[8] C. Ordonez, Algorithms and Optimizations for Big Data Analytics, University of Houston, USA.:
Cubes, Tech Talks.](https://image.slidesharecdn.com/seminarpresentation-160307190432/75/Seminar-presentation-15-2048.jpg)

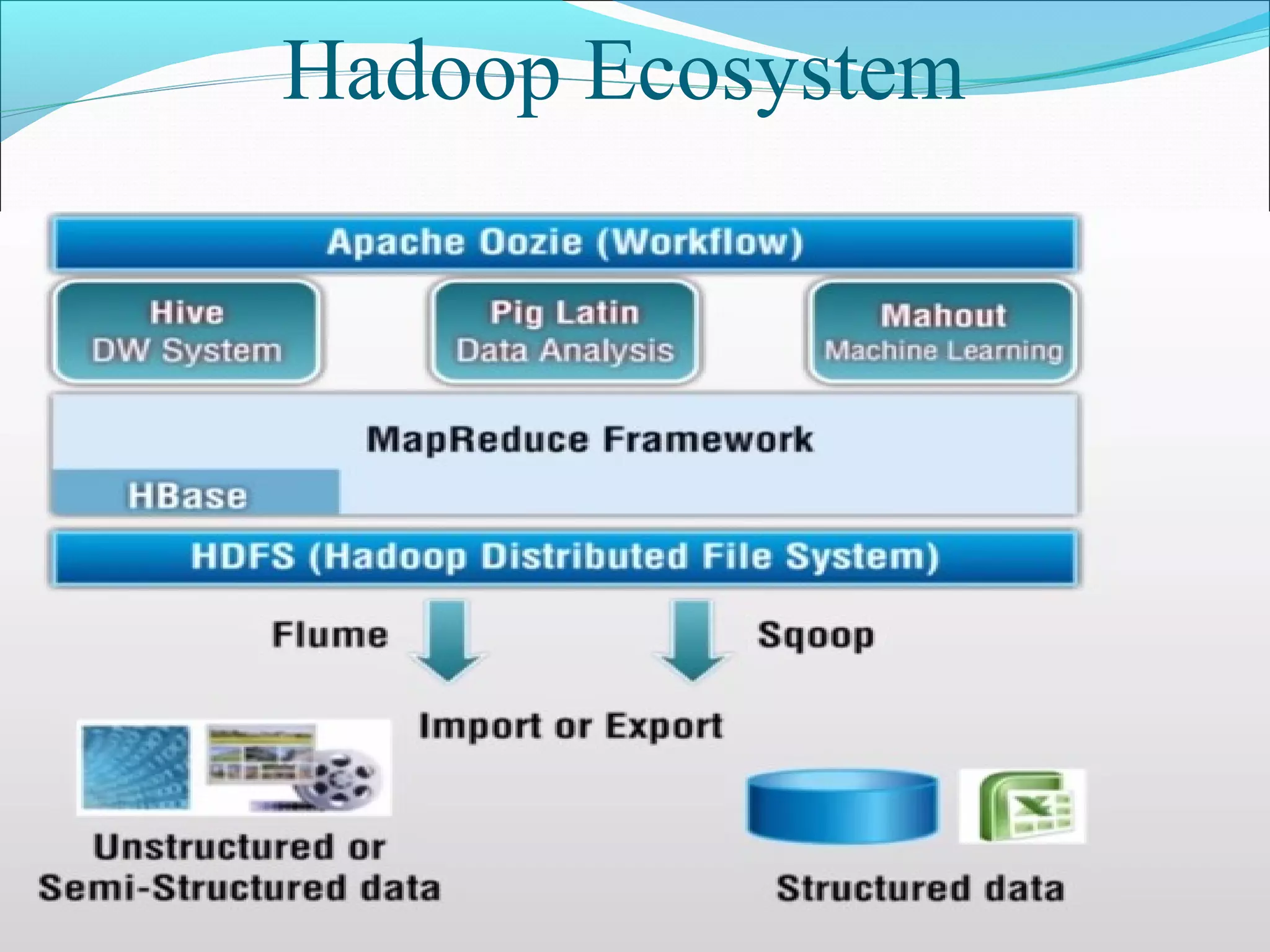
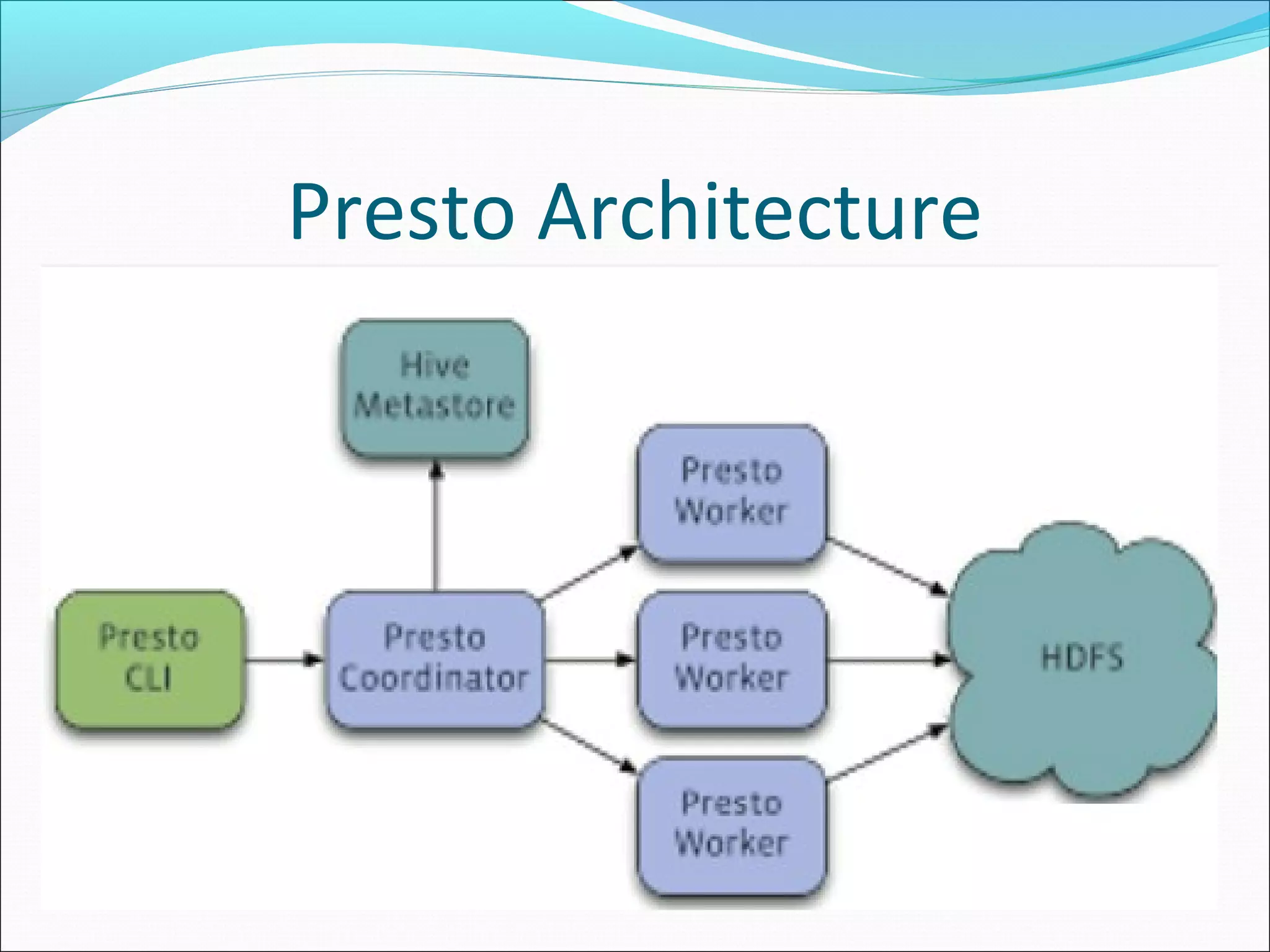
This document discusses issues, opportunities, and challenges related to big data. It provides an overview of big data characteristics like volume, variety, velocity, and veracity. It also describes Hadoop and HDFS for distributed storage and processing of big data. The document outlines issues in big data like storage, management, and processing challenges due to scale. Opportunities in big data analytics are also presented. Finally, challenges like heterogeneity, scale, timeliness, and ownership are discussed along with approaches like Hadoop, Spark, NoSQL databases, and Presto for tackling big data problems.






















































![[IJCT-V3I2P32] Authors: Amarbir Singh, Palwinder Singh](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p32-160609071950-thumbnail.jpg?width=640&height=640&fit=bounds)





















